python读取/创建XML文件
Python中定义了很多处理XML的函数,如xml.dom,它会在处理文件之前,将根据xml文件构建的树状数据存在内存。还有xml.sax,它实现了SAX API,这个模块牺牲了便捷性,换取了速度和减少内存占用。
本文将要说明的是xml.tree.ElementTree的使用。与DOM比较,它使用起来更快更方便,和SAX比较呢,性能相仿,但使用起来更快捷。
ET(ElementTree)提供了两个对象:ElementTree和Element
ElementTree:将整个XML转化为树,对整个XML文档进行操作(读取,写入,查找等)一般在ElementTree层面进行。
Element:代表树上单个节点,对单个XML元素及其子元素进行操作,则是在Element层面进行。
1)加载整个文档(demo.xml):
import xml.etree.ElementTree as ET
tree = ET.ElementTree(file="demo.xml")
2)获取根元素
root = tree.getroot()
根元素是一个Element对象,它具有以下属性:
root.tag:返回元素的标签名
root.attrib:以字典形式返回属性名和值
3)根元素本身就是一个可迭代对象,和其他Element对象一样,也具备直接遍历子元素的接口
for child in root:
print(child.tag, child.attrib)
也可以通过索引来访问特定的子元素 root[1].tag
4)查找需要的元素:find,findall, findText,iterfind等
find(tagName):总是返回第一个匹配的元素
findall(tagName):返回当前元素下一级所有匹配的元素列表
findtext:
iterfind(tagName):作用和findall一样,但是它返回的是一个生成器。
4)要想找到当前元素下所有元素,而不是只找到下一级元素
list(root.iter()) #列出根元素下所有子节点列表
list(root.iter(tagName)) # 列出所有标签名为tagName的子节点
5)正则表达式的使用:
*:所有 ---------> root.find("Menues/*") 查找路径Menus下面的所有子节点
.:当前元素---------->root.find(./*) 查找当前元素下的所有子节点
//:------------> root.findall(".//Menu"):查找当前目录下任意层级的标签名为Menu的子元素
..:------------>root.findall(".//Menu/.."):查找当前目录下任意层级的标签名为Menu的子元素的父元素
[@attrib]:根据指定的属性搜索元素
[@attrib='value']:根据给定属性名搜索元素--------->root.findall("Tab[@type='subabsent']"):找到所有type为subabsent的Tab标签
[tag]:----->root.findall("Tab[Menues]"):找到包含子元素为Menues的Tab标签
[tag='text']:---------->root.findall("Tab[Menues=5]"):找到包含Menues标签,且Menues标签中间text值为5的Tab元素
[position]:----->根据元素位置找相应的元素,从1开始: root.findall("Tab[1]") root.findall("Tab[last()-1]"):找到倒数第二个元素
写入XML文件:
调用ElementTree的write函数:ElementTree.write(file)
def pretty(e,level=0):
# 格式化xml文件
if len(e)>0:
e.text = "\n"+"\t"*(level+1)
for child in e:
pretty(child,level+1)
child.tail = child.tail[:-1]
e.tail = "\n"+"\t"*level
把如下CSV文件写入XML文件

---》
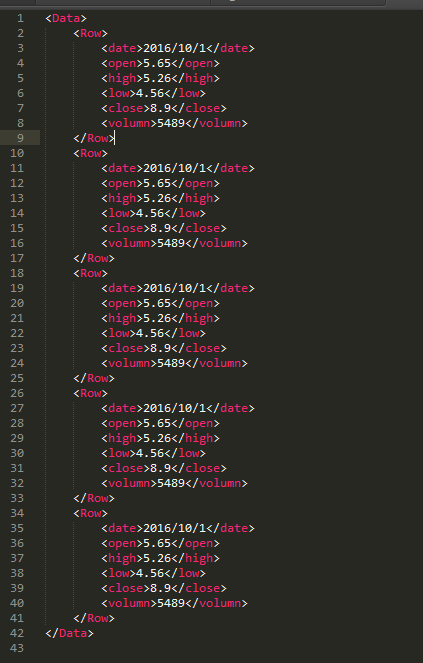
import xml.etree.ElementTree as ET
from xml.etree.ElementTree import ElementTree,Element
import csv
def WriteXML(csvfile):
# 把CSV文件写入到xml文件
with open(csvfile,"r") as rf:
reader = csv.reader(rf)
header = next(reader)
root = Element("Data")
for row in reader:
eRow = Element("Row")
root.append(eRow)
for tag, text in zip(header, row):
e = Element(tag.strip())
e.text = text.strip()
eRow.append(e)
pretty(root)
return ElementTree(root)
python读取/创建XML文件的更多相关文章
- TinyXML2读取和创建XML文件 分类: C/C++ 2015-03-14 13:29 94人阅读 评论(0) 收藏
TinyXML2是simple.small.efficient C++ XML文件解析库!方便易于使用,是对TinyXML的升级改写!源码见本人上传到CSDN的TinyXML2.rar资源:http: ...
- XML解析之sax解析案例(一)读取contact.xml文件,完整输出文档内容
一.新建Demo2类: import java.io.File; import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXPar ...
- 创建xml文件、解析xml文件
1.创建XML文件: import codecs import xml.dom.minidom doc=xml.dom.minidom.Document() print doc root=do ...
- C#中如何创建xml文件 增、删、改、查 xml节点信息
XML:Extensible Markup Language(可扩展标记语言)的缩写,是用来定义其它语言的一种元语言,其前身是SGML(Standard Generalized Markup Lang ...
- python读取Excel表格文件
python读取Excel表格文件,例如获取这个文件的数据 python读取Excel表格文件,需要如下步骤: 1.安装Excel读取数据的库-----xlrd 直接pip install xlrd安 ...
- .net中创建xml文件的两种方法
.net中创建xml文件的两种方法 方法1:根据xml结构一步一步构建xml文档,保存文件(动态方式) 方法2:直接加载xml结构,保存文件(固定方式) 方法1:动态创建xml文档 根据传递的值,构建 ...
- C#操作XML学习之创建XML文件的同时新建根节点和子节点(多级子节点)
最近工作中遇到一个问题,要求创建一个XML文件,在创建的时候要初始化该XML文档,同时该文档打开后是XML形式,但是后缀名不是.在网上找了好些资料没找到,只能自己试着弄了一下,没想到成功了,把它记下来 ...
- Java 创建xml文件和操作xml数据
java中的代码 import java.io.File; import java.io.StringWriter; import javax.xml.parsers.DocumentBuilder; ...
- XML文件操作类--创建XML文件
这个类是在微软XML操作类库上进行的封装,只是为了更加简单使用,包括XML类创建节点的示例. using System; using System.Collections; using System. ...
随机推荐
- 使用VSTS的Git进行版本控制(一)——复制现有仓库
使用VSTS的Git进行版本控制(一)--复制现有仓库 概述 Team Services支持两种类型的版本控制Git和Team Foundation Version Control (TFVC).以下 ...
- 【Apache运维基础(6)】Apache的日志管理与分析
简述 Apache 访问日志在实际工作中非常有用,比较典型的例子是进行网站流量统计,查看用户访问时间.地理位置分布.页面点击率等.Apache 的访问日志具有如下4个方面的作用: 记录访问服务器的远程 ...
- 设计模式java----单例模式
一.懒汉式单例 在第一次调用的时候实例化自己,Singleton的唯一实例只能通过getInstance()方法访问.线程不安全 /** * Created by Admin on 2017/3/19 ...
- c/c++ 线性栈
c/c++ 线性栈 线性栈 下面的代码实现了以下功能 函数 功能描述 push 压入 pop 弹出 show_list 打印 clear 移动top指针到栈底 destroy 释放所有内存空间 seq ...
- Can We Make Operating Systems Reliable and Secure?
Andrew S. Tanenbaum, Jorrit N. Herder, and Herbert Bos Vrije Universiteit, Amsterdam Microkernels-lo ...
- Python爬虫-01:爬虫的概念及分类
目录 # 1. 为什么要爬虫? 2. 什么是爬虫? 3. 爬虫如何抓取网页数据? # 4. Python爬虫的优势? 5. 学习路线 6. 爬虫的分类 6.1 通用爬虫: 6.2 聚焦爬虫: # 1. ...
- JDK版本更换,Eclipse中所有的项目报错
我将JDK10切换成JDK8版本以后,原先在eclipse中写的项目全部都报错了.解决方案如下: 1.设置eclipse中的JDK版本和JRE环境:window-preference-java-Com ...
- 微信小程序本地引用iconfont(阿里巴巴矢量图标库)
好,忙,我懂..... 首先把图标放进项目里(废话): 接下来把这些图标下载到本地(这里不介绍网络途径了,下载就完事了) 然后利用一个网站将这个ttf文件转成base64文件https://trans ...
- 学习RabbitMQ(三):AMQP事务机制
本文转自:http://m.blog.csdn.net/article/details?id=54315940 在使用RabbitMQ的时候,我们可以通过消息持久化操作来解决因为服务器的异常奔溃导致的 ...
- Vue生命周期(转)
https://segmentfault.com/a/1190000011381906