scrapy基础
scrapy
Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。
Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架。因此Scrapy使用了一种非阻塞(又名异步)的代码来实现并发。
安装
- Linux:
pip install scrapy
- Windows:
1. pip install wheel2. 下载twistedhttp://www.lfd.uci.edu/-gohlke/pythonlibs/#twisted3. 安装twisted进入到下载目录,pip install Twisted-xxx.whl4. pip install pywin325. pip install scrapy
Scrapy结构,执行流程
架构图
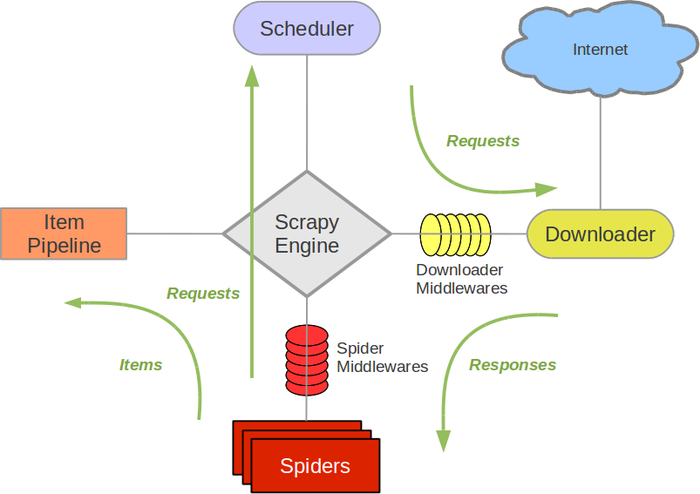
各部分作用
- Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
- Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器).
- Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
- Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
执行流程图
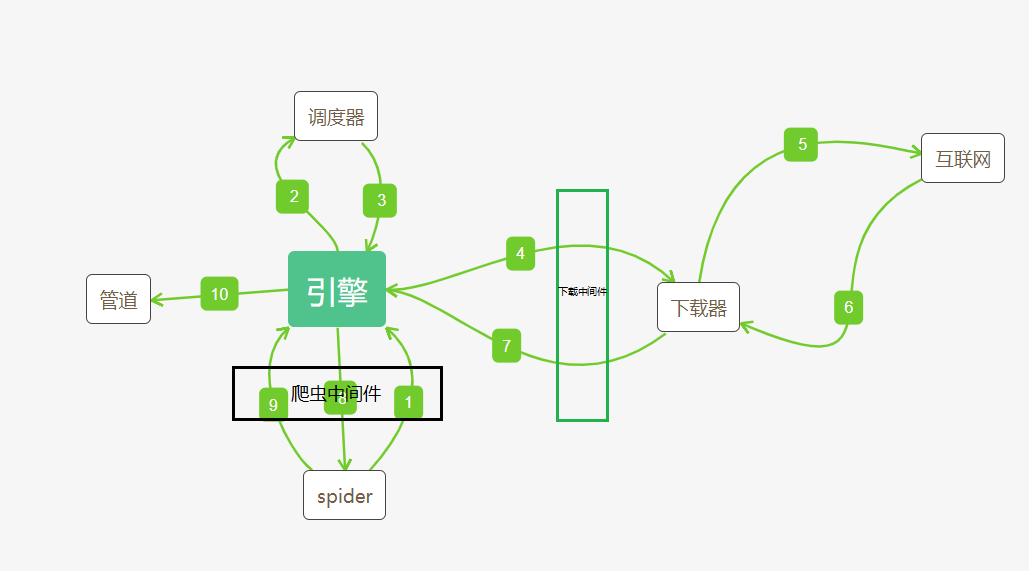
起始url被封装成request请求对象,经引擎传给调度器,存放在队列中且会对重复的请求对象进行过滤,之后经引擎传递给下载器去下载数据得到响应对象,响应对象经引擎返回给spider进行解析并封装到item对象中,用yield将item对象经引擎传给管道进行持久化处理,若spider中解析到新的url,重复上述操作。
请求传参
当爬取的数据不在同一页面中时,要进行请求传参,不然持久化的数据结果会出错。
- 使用meta进行传参,如下:
def parse(self, response):...yield scrapy.Request(url, callback=self.detail, meta={"item": item})def detail(self, response):item = response.meta['item']...
如何提高scrapy爬取效率
- 增大并发数
默认情况下scrapy没有开启线程并发,需在settings.py中手动开启。CONCURRENT_REQUESTS=32,但是并不是只能设置不超过32,可以适度增加并发数。 - 降低日志等级
减少日志信息的输出会降低CPU的使用率。
如:LOG_LEVEL = 'INFO'
LOG_FILE = 'path' 将日志输出到指定文件中 - 禁用cookie
除非真的需要cookie,否则请关闭以提升爬取效率。
COOKIES_ENABLED = False - 限制重试
重新请求爬取失败的url会减慢爬取速度。
RETRY_ENABLED= False - 缩减下载超时
放弃请求响应慢的url,可以提高爬取效率。
DOWNLOAD_TIMEOUT = 10 (单位是秒)
如何设置代理池和UA池
ua_list = []ip_list = []# 在下载中间件中import randomdef process_request(self, request, spider):request.meta['proxy'] = random.choice(ip_list)request.headers['User-Agent'] = random.choice(ua_list)...
使用管道进行持久化存储的流程
- 在items中定义字段
- 获取解析后的数据值
- 将解析后的数据值存储到item对象中
- 通过yield将item对象提交到管道
- 管道中持久化存储代码的编写
- settings.py中开启管道, 并设置优先级
在scrapy中使用selenium
- 在spider的__init__方法中实现浏览器
- 在spider的closed方法中关闭浏览器
- 在下载中间件的响应中使用spider.browser获取浏览器对象,并得到需要的网页源码,实例化一个新的响应对象,之后将浏览器获取的页面源码加载到该对象中,返回这个新的响应对象。
# spider.pydef __init__(self):self.browser = webdriver.Firefox()def closed(self,spider):print("spider closed")self.browser.close()# middlewares.pydef process_request(self, request, spider):if spider.name == 'xxx':try:spider.browser.get(request.url)spider.browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')except TimeoutException as e:print('超时')spider.browser.execute_script('window.stop()')time.sleep(2)return HtmlResponse(url=spider.browser.current_url, body=spider.browser.page_source,encoding="utf-8", request=request)
其他知识点
- scrapy为什么要把持久化操作放到管道中, 而不是在爬虫文件中?
- 放到管道中进行持久化操作的效率会更高
- spider参数是干嘛用的?
- 用来传递除了item对象之外的其他属性等
- 管道文件中return item的作用?
- 为了让优先级低于本管道类的能拿到item对象
- 在scrapy框架中不需要考虑cookie
- 原始的scrapy为啥不能进行分布式爬虫?
- 原生scrapy的调度器、管道不能共享。
scrapy基础的更多相关文章
- 0.Python 爬虫之Scrapy入门实践指南(Scrapy基础知识)
目录 0.0.Scrapy基础 0.1.Scrapy 框架图 0.2.Scrapy主要包括了以下组件: 0.3.Scrapy简单示例如下: 0.4.Scrapy运行流程如下: 0.5.还有什么? 0. ...
- Learning Scrapy笔记(三)- Scrapy基础
摘要:本文介绍了Scrapy的基础爬取流程,也是最重要的部分 Scrapy的爬取流程 Scrapy的爬取流程可以概括为一个方程式:UR2IM,其含义如下图所示 URL:Scrapy的运行就从那个你想要 ...
- scrapy 基础
安装略过 创建一个项目 scrapy startproject MySpider #或者创建时存储日志scrapy startproject --logfile='../logf.log' MySpi ...
- Scrapy基础(十三)————ItemLoader的简单使用
ItemLoader的简单使用:目的是解决在爬虫文件中代码结构杂乱,无序,可读性差的缺点 经过之前的基础,我们可以爬取一些不用登录,没有Ajax的,等等其他的简单的爬虫回顾我们的代码,是不是有点冗长, ...
- Scrapy基础(一) ------学习Scrapy之前所要了解的
技术选型: Scrapy vs requsts+beautifulsoup 1,reqests,beautifulsoup都是库,Scrapy是框架 2,Scrapy中可以加入reques ...
- scrapy基础教程
1. 安装Scrapy包 pip install scrapy, 安装教程 Mac下可能会出现:OSError: [Errno 13] Permission denied: '/Library/Pyt ...
- python scrapy 基础
scrapy是用python写的一个库,使用它可以方便的抓取网页. 主页地址http://scrapy.org/ 文档 http://doc.scrapy.org/en/latest/index.ht ...
- Scrapy基础(十四)————Scrapy实现知乎模拟登陆
模拟登陆大体思路见此博文,本篇文章只是将登陆在scrapy中实现而已 之前介绍过通过requests的session 会话模拟登陆:必须是session,涉及到验证码和xsrf的写入cookie验证的 ...
- 【Python】Scrapy基础
一.Scrapy 架构 Engine(引擎):负责 Spider(爬虫).Item Pipeline(管道).Downloader(下载器).Scheduler(调度器)中的通讯和数据传递. Sche ...
- scrapy基础二
应对反爬虫机制 ①.禁止cookie :有的网站会通过用户的cookie信息对用户进行识别和分析,此时可以通过禁用本地cookies信息让对方网站无法识别我们的会话信息 settings.py里开启禁 ...
随机推荐
- php中ip转int 并存储在mysql数据库
遇到一个问题,于是百度一下. 得到最佳答案 http://blog.163.com/metlive@126/blog/static/1026327120104232330131/ 如何将四个字 ...
- 购物车redis存储结构
- 闭包&执行环境和作用域
闭包 执行环境和作用域参考:<javascript高级程序设计(第3版)>4.2节
- Recursive functions and algorithms
http://en.wikipedia.org/wiki/Recursion_(computer_science)#Recursive_functions_and_algorithms A commo ...
- Excel VBA开发
一.Excel添加treeview控件 如果是以VBA中为窗体添加,菜单:工具->附加控件,从中选择“Microsoft TreeView Control”: 在控件工具箱中点击其它控件,从中选 ...
- php时间函数大锦集
PHP中的时间函数有这么些:(1)date用法: date(格式,[时间]);如果没有时间参数,则使用当前时间. 格式是一个字符串,其中以下字符有特殊意义:U 替换成从一个起始时间(好象是1970年1 ...
- Office Online Server 2016 部署和配置
Office Online Server 2016 部署和配置https://wenku.baidu.com/view/65faf8de846a561252d380eb6294dd88d1d23d45 ...
- CSMA/CD 3
一.二进制指数类型退避算法 (truncated binary exponential type) 发生碰撞的站在停止发送数据后,要推迟(退避)一个随机时间才能再发送数据. 目的:重传时再次发生碰撞的 ...
- C#3.0新特性:隐式类型、扩展方法、自动实现属性,对象/集合初始值设定、匿名类型、Lambda,Linq,表达式树、可选参数与命名参数
一.隐式类型var 从 Visual C# 3.0 开始,在方法范围中声明的变量可以具有隐式类型var.隐式类型可以替代任何类型,编译器自动推断类型. 1.var类型的局部变量必须赋予初始值,包括匿名 ...
- VNC Viewer
首先需要明确,什么事VNC , Virtual Network Computing ,VNC允许Linux系统可以类似实现像Windows中的远程桌面访问那样访问Linux桌面. 首先试试服务器装了V ...