机器学习实战python3 Logistic Regression
代码及数据:https://github.com/zle1992/MachineLearningInAction
logistic regression
优点:计算代价不高,易于理解实现,线性模型的一种。
缺点:容易欠拟合,分类精度不高。但是可以用于预测概率。
适用数据范围:数值型和标称型。
准备数据:
def loadDataSet():
dataMat,labelMat = [],[]
with open(filename,"r") as fr: #open file
for line in fr.readlines():
lineArr = line.split() #split each line
dataMat.append([1.0,float(lineArr[0]),float(lineArr[1])]) #创建2维list
labelMat.append(int(lineArr[2]))
return dataMat,labelMat
1 基于Logistic回归和Sigmoid函数的分类
Sigmoid函数:

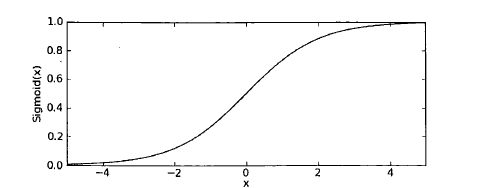

def sigmoid(inX):
return 1.0/(1+np.exp(-inX))
2基于最优化方法的最佳回归系数确定
梯度上升法:
梯度上升法的伪代码如下:
每个回归系数初始化为1
重复R次:
计算整个数据集的梯度
使用alpha x gradient更新回归系数的向量
返回回归系数
代码:
def sigmoid(inX):
return 1.0/(1+np.exp(-inX)) def gradAscent(dataMat,labelMat):
dataMatrix = np.mat(dataMat) #translate list to matrix
labelMatrix = np.mat(labelMat).transpose() #转置
m,n = np.shape(dataMatrix) #100 rows 3 coulums
alpha = 0.001 #步长 or 学习率
maxCyclse = 500
weight = np.ones((n,1)) #初始值随机更好吧
#weight = np.random.rand(n,1)
for k in range(maxCyclse):
h = sigmoid(dataMatrix * weight) # h 是向量
error = (labelMatrix - h) #error 向量
weight = weight + alpha * dataMatrix.transpose() *error #更新
# print(k," ",weight)
return weight
3分析数据:画出决策边界
def plotfit(wei):
import matplotlib.pyplot as plt
weight = np.array(wei) #???????? #return array
dataMat ,labelMat = loadDataSet()
dataArr = np.array(dataMat)
n = np.shape(dataArr)[0] #row
fig = plt.figure() #plot
ax = fig.add_subplot(111)
ax.scatter(dataArr[:,1],dataArr[:,2],s =50, c = np.array(labelMat)+5) #散点图 #参考KNN 的画图
x = np.arange(-3.0,3.0,0.1) #画拟合图像
y = (-weight[0] - weight[1] *x ) / weight[2]
ax.plot(x,y)
plt.xlabel("x1")
plt.ylabel("x2")
plt.show()
4训练算法:随机梯度上升
伪代码:
所有回归系数初始化为1
对数据集中每个样本
计算该样本的梯度
使用alpha x gradient更新回归系数值
返回回归系数值
原始梯度上升计算数据集的梯度,涉及的是矩阵运算。h,error都是向量
随机梯度算法计算的是数据集中每个样本的梯度,s计算量减小,h,error都是数值
ef stocGradAscent0(dataMatrix,labelMatrix):
m,n = np.shape(dataMatrix)
alpha = 0.1
weight = np.ones(n)
for i in range(m):
h = sigmoid(sum(dataMatrix * weight))
error = labelMatrix[i] - h
weight = weight + alpha * error * dataMatrix[i]
return weight
上面的算法是固定的步长,固定的步长,不稳定,会产生震荡,所以下面的算法采用不固定的步长。
距离目标值远的时候,步长大,距离目标值近的时候,步长小。
def stocGradAscent1(dataMat,labelMat,numIter = 150):
dataMatrix = np.mat(dataMat) #translate list to matrix
labelMatrix = np.mat(labelMat).transpose() #转置
m,n = np.shape(dataMat)
alpha = 0.1
weight = np.ones(n) #float
#weight = np.random.rand(n)
for j in range(numIter):
dataIndex = list(range(m)) #range 没有del 这个函数 所以转成list del 见本函数倒数第二行
for i in range(m):
alpha = 4/(1.0 +j + i) + 0.01
randIndex = int(np.random.uniform(0,len(dataIndex))) #random.uniform(0,5) 生成0-5之间的随机数
#生成随机的样本来更新权重。
h = sigmoid(sum(dataMat[randIndex] * weight))
error = labelMat[randIndex] - h
weight = weight + alpha * error * np.array(dataMat[randIndex]) #!!!!一定要转成array才行
#dataMat[randIndex] 原来是list list *2 是在原来的基础上长度变为原来2倍,
del(dataIndex[randIndex]) #从随机list中删除这个
return weight
5从病气病症预测病马的死亡率
def classifyVector(inX,weight): #输入测试带测试的向量 返回类别
prob = sigmoid(sum(inX * weight))
if prob > 0.5 :
return 1.0
else: return 0.0
def colicTest():
trainingSet ,trainingSetlabels =[],[]
with open("horseColicTraining.txt") as frTrain:
for lines in frTrain.readlines():
currtline = lines.strip().split('\t') # strip()remove the last string('/n') in everyline
linearr = [] #每行临时保存str 转换float的list
for i in range(21): #将读进来的每行的前21个str 转换为float
linearr.append(float(currtline[i]))
trainingSet.append(linearr) #tianset 是2维的list
trainingSetlabels.append(float(currtline[21]))#第22个是类别
trainWeights = stocGradAscent1(trainingSet,trainingSetlabels,500)
errorCount = 0
numTestVec = 0.0
with open("horseColicTest.txt") as frTrain:
for lines in frTrain.readlines():
numTestVec += 1.0
currtline = lines.strip().split('\t') # strip()remove the last string('/n') in everyline
linearr = [] #测试集的每一行
for i in range(21):
linearr.append(float(currtline[i]))#转换为float
if int(classifyVector(np.array(linearr),trainWeights)) != int(currtline[21]) :
errorCount += 1 #输入带分类的向量,输出类别,类别不对,errorCount ++
errorRate = float(errorCount)/numTestVec
print("the error rate of this test is : %f"%errorRate)
return errorRate
def multiTest(): #所有测试集的错误率
numTests = 10
errorSum = 0.0
for k in range(numTests):
errorSum +=colicTest()
print("after %d iterations the average error rate is : %f" %(numTests,errorSum/float(numTests)))
主函数:
if __name__ == '__main__':
filename = "testSet.txt"
dataMat,labelMat = loadDataSet()
#weight = gradAscent(dataMat,labelMat)
weight = stocGradAscent1(dataMat,labelMat)
print(weight)
plotfit(weight)#画分类图像在小数据集上
multiTest() #真实数据集上测试
机器学习实战python3 Logistic Regression的更多相关文章
- 机器学习实战python3 K近邻(KNN)算法实现
台大机器技法跟基石都看完了,但是没有编程一直,现在打算结合周志华的<机器学习>,撸一遍机器学习实战, 原书是python2 的,但是本人感觉python3更好用一些,所以打算用python ...
- Andrew Ng机器学习编程作业:Logistic Regression
编程作业文件: machine-learning-ex2 1. Logistic Regression (逻辑回归) 有之前学生的数据,建立逻辑回归模型预测,根据两次考试结果预测一个学生是否有资格被大 ...
- 机器学习实战之Logistic回归
Logistic回归一.概述 1. Logistic Regression 1.1 线性回归 1.2 Sigmoid函数 1.3 逻辑回归 1.4 LR 与线性回归的区别 2. LR的损失函数 3. ...
- Stanford机器学习笔记-2.Logistic Regression
Content: 2 Logistic Regression. 2.1 Classification. 2.2 Hypothesis representation. 2.2.1 Interpretin ...
- Andrew Ng机器学习 二: Logistic Regression
一:逻辑回归(Logistic Regression) 背景:假设你是一所大学招生办的领导,你依据学生的成绩,给与他入学的资格.现在有这样一组以前的数据集ex2data1.txt,第一列表示第一次测验 ...
- 【笔记】机器学习 - 李宏毅 - 6 - Logistic Regression
Logistic Regression 逻辑回归 逻辑回归与线性回归有很多相似的地方.后面会做对比,先将逻辑回归函数可视化一下. 与其所对应的损失函数如下,并将求max转换为min,并转换为求指数形式 ...
- 机器学习实战 - python3 学习笔记(一) - k近邻算法
一. 使用k近邻算法改进约会网站的配对效果 k-近邻算法的一般流程: 收集数据:可以使用爬虫进行数据的收集,也可以使用第三方提供的免费或收费的数据.一般来讲,数据放在txt文本文件中,按照一定的格式进 ...
- 05机器学习实战之Logistic 回归scikit-learn实现
https://blog.csdn.net/zengxiantao1994/article/details/72787849似然函数 原理:极大似然估计是建立在极大似然原理的基础上的一个统计方法,是概 ...
- 05机器学习实战之Logistic 回归
Logistic 回归 概述 Logistic 回归 或者叫逻辑回归 虽然名字有回归,但是它是用来做分类的.其主要思想是: 根据现有数据对分类边界线(Decision Boundary)建立回归公式, ...
随机推荐
- Extjs学习笔记--(二)
1.配置实用Extjs <link href="Extjs/resources/css/ext-all.css" rel="stylesheet" /&g ...
- ios 6以后,UILabel全属性
一.初始化 1 UILabel *myLabel = [[UILabel alloc] initWithFrame:CGRectMake(40, 40, 120, 44)]; 2 3 [s ...
- Hadoop学习之路
Hadoop是谷歌的集群系统的开源实现: -google集群系统:GFS.MapReduce.BigTable -Hadoop主要由HDFS(hadoop distrubuted file syste ...
- c++11——可变参数模板
在c++11之前,类模板和函数模板只能含有固定数量的模板参数,c++11增加了可变模板参数特性:允许模板定义中包含0到任意个模板参数.声明可变参数模板时,需要在typename或class后面加上省略 ...
- Java中迭代器实现的原理
一. 引言 迭代这个名词对于熟悉Java的人来说绝对不陌生.我们常常使用JDK提供的迭代接口进行java collection的遍历: Iterator it = list.iterator();wh ...
- SenchaTouch 的一些问题记录
1 : textfield 的 focus事件在手机上会被触发很多次,原因不明,在pc上测试无问题
- 【BZOJ4764】弹飞大爷 LCT
[BZOJ4764]弹飞大爷 Description 自从WC退役以来,大爷是越来越懒惰了.为了帮助他活动筋骨,也是受到了弹飞绵羊一题的启发,机房的小伙伴们决定齐心合力构造一个下面这样的序列.这个序列 ...
- LCA在线算法(hdu2586)
hdu2586 How far away ? Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/O ...
- Spring----学习参考博客书单链接
[References] 1.IOC之基于Java类的配置Bean 2.IOC之基于注解的配置bean(上) 3.Spring之IOC的注入方式总结 4.Spring之IOC自动装配解析 5.Spri ...
- log4j 设置将生成的日志进行gz压缩并删除过期日志
1.准备jar :log4j-1.2.17.jar,commons-logging-1.2.jar,这2个就可以了,其他关于日志的jar包就不要加进来了,在优先级上会有冲突. 2.定义一个类,继承R ...