Cloudera Manager安装之利用parcels方式(在线或离线)安装3或4节点集群(包含最新稳定版本或指定版本的安装)(添加服务)(Ubuntu14.04)(五)
前期博客
Cloudera Manager安装之Cloudera Manager 5.6.X安装(tar方式、rpm方式和yum方式) (Ubuntu14.04) (三)
如果大家,在启动的时候,比如遇到如下问题,则
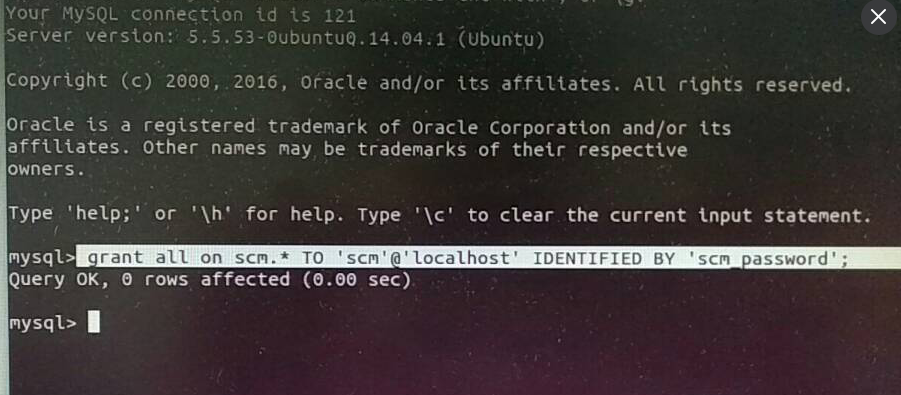
明明已经授权了啊,怎么被拒绝,纳尼???
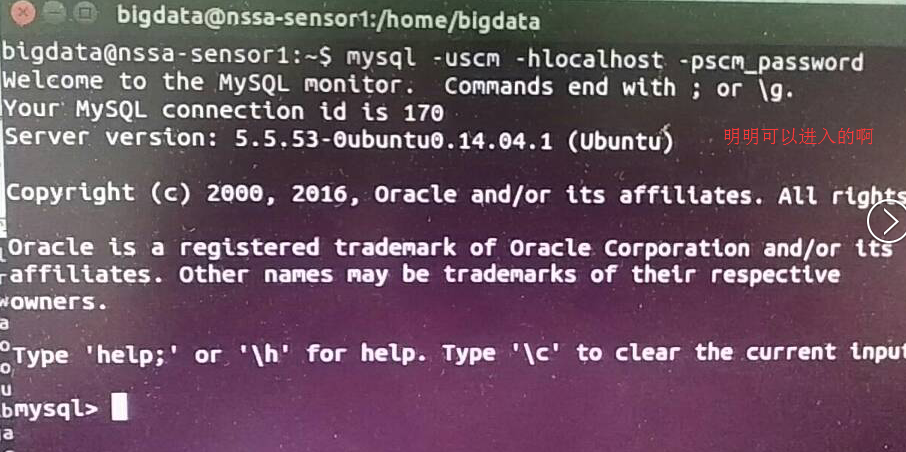
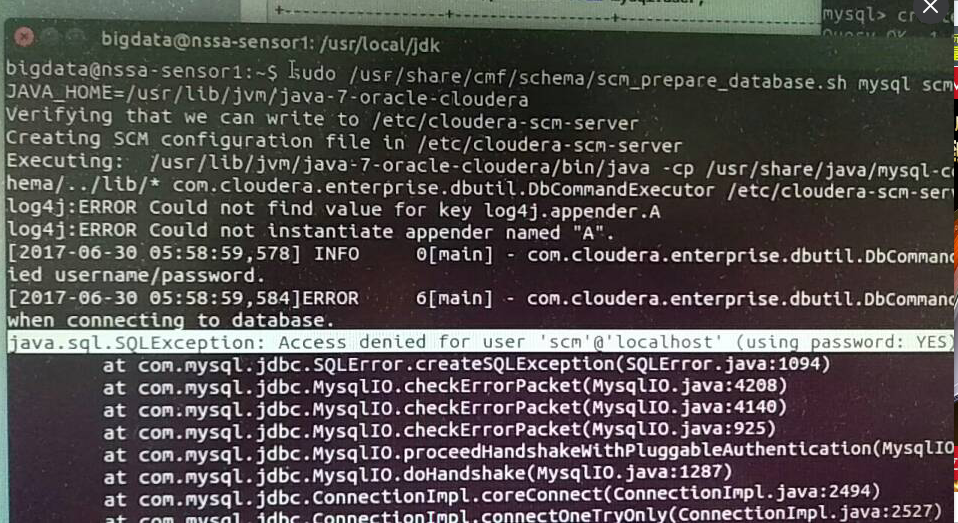
解决办法
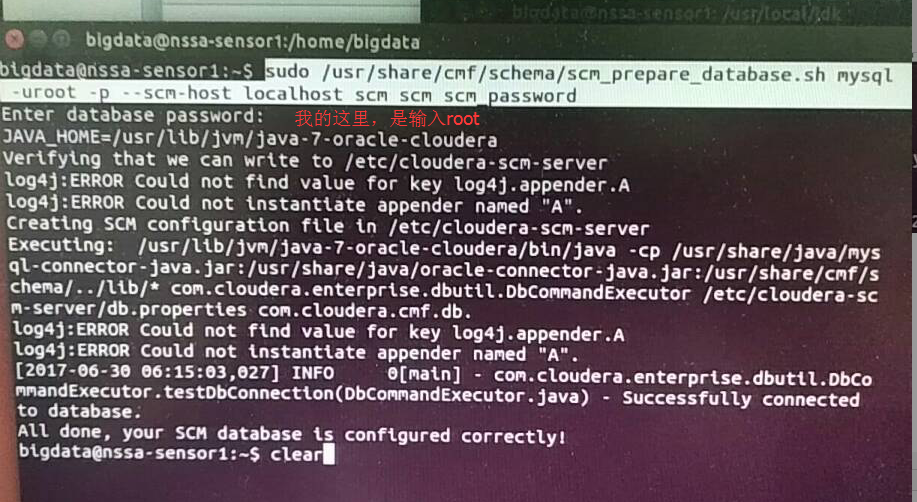
然后,再来这样,就可以了。
注意,在此之前。
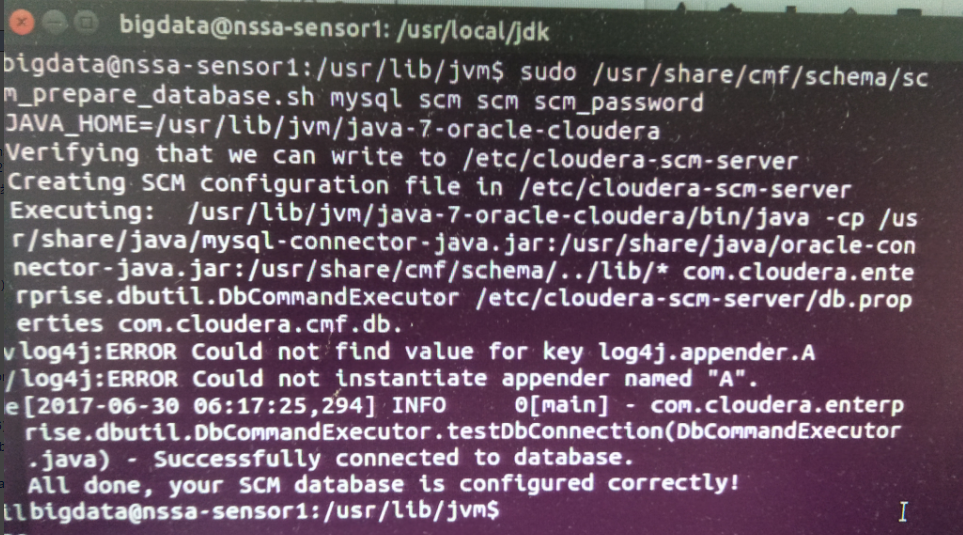
ubuntucmbigdata1机器上,则需要执行
bigdata@ubuntucmbigdata1:~$ sudo /usr/share/cmf/schema/scm_prepare_database.sh mysql scm scm scm_password [sudo] password for bigdata:
Sorry, try again.
[sudo] password for bigdata:
JAVA_HOME=/usr/java/jdk1..0_80
Verifying that we can write to /etc/cloudera-scm-server
Creating SCM configuration file in /etc/cloudera-scm-server
Executing: /usr/java/jdk1..0_80/bin/java -cp /usr/share/java/mysql-connector-java.jar:/usr/share/java/oracle-connector-java.jar:/usr/share/cmf/schema/../lib/* com.cloudera.enterprise.dbutil.DbCommandExecutor /etc/cloudera-scm-server/db.properties com.cloudera.cmf.db.
[ main] DbCommandExecutor INFO Successfully connected to database.
All done, your SCM database is configured correctly!
bigdata@ubuntucmbigdata1:~$ sudo service cloudera-scm-server start
[sudo] password for bigdata:
Starting cloudera-scm-server: * cloudera-scm-server started
bigdata@ubuntucmbigdata1:~$
bigdata@ubuntucmbigdata1:~$ sudo service cloudera-scm-agent start
[sudo] password for bigdata:
Starting cloudera-scm-agent: * cloudera-scm-agent started
bigdata@ubuntucmbigdata1:~$
然后,在ubuntucmbigdata2、ubuntucmbigdata3、ubuntucmbigdata4上
bigdata@ubuntucmbigdata2:~$ sudo service cloudera-scm-agent start
[sudo] password for bigdata:
Starting cloudera-scm-agent: * cloudera-scm-agent started
bigdata@ubuntucmbigdata2:~$
bigdata@ubuntucmbigdata3:~$ sudo service cloudera-scm-agent start
[sudo] password for bigdata:
Starting cloudera-scm-agent: * cloudera-scm-agent started
bigdata@ubuntucmbigdata3:~$
bigdata@ubuntucmbigdata4:~$ sudo service cloudera-scm-agent start
[sudo] password for bigdata:
Starting cloudera-scm-agent: * cloudera-scm-agent started
bigdata@ubuntucmbigdata4:~$
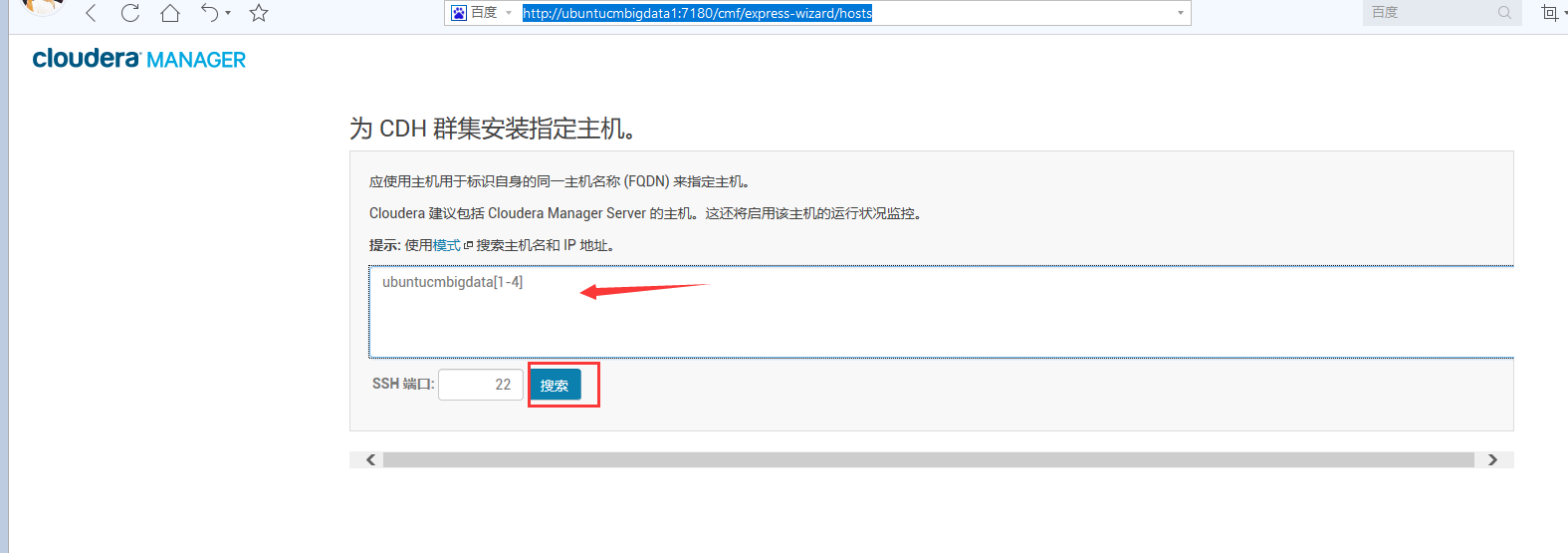
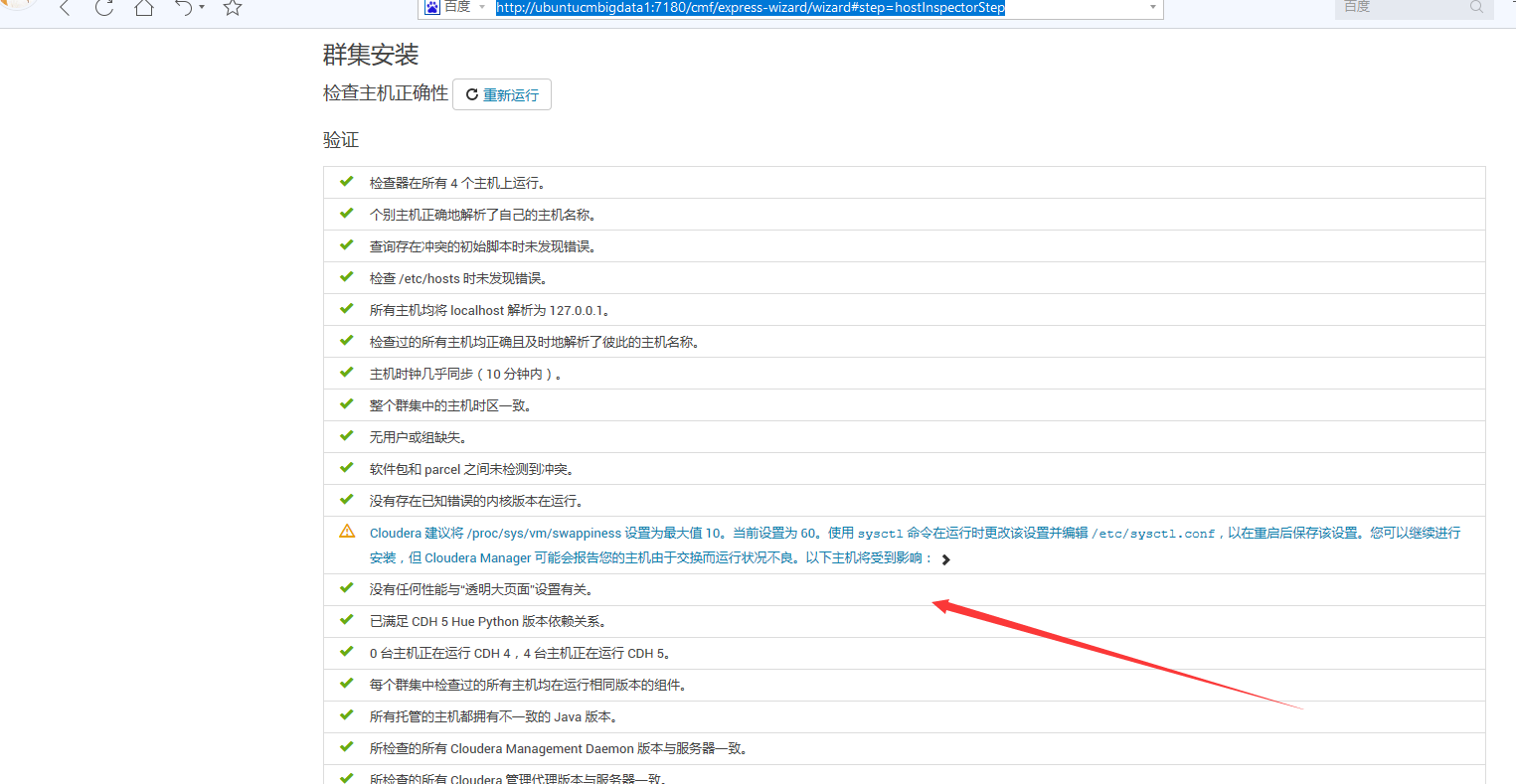
这是,因为。我之前前面4台机器都没有启动服务,所以会是如下。四个自动会勾选。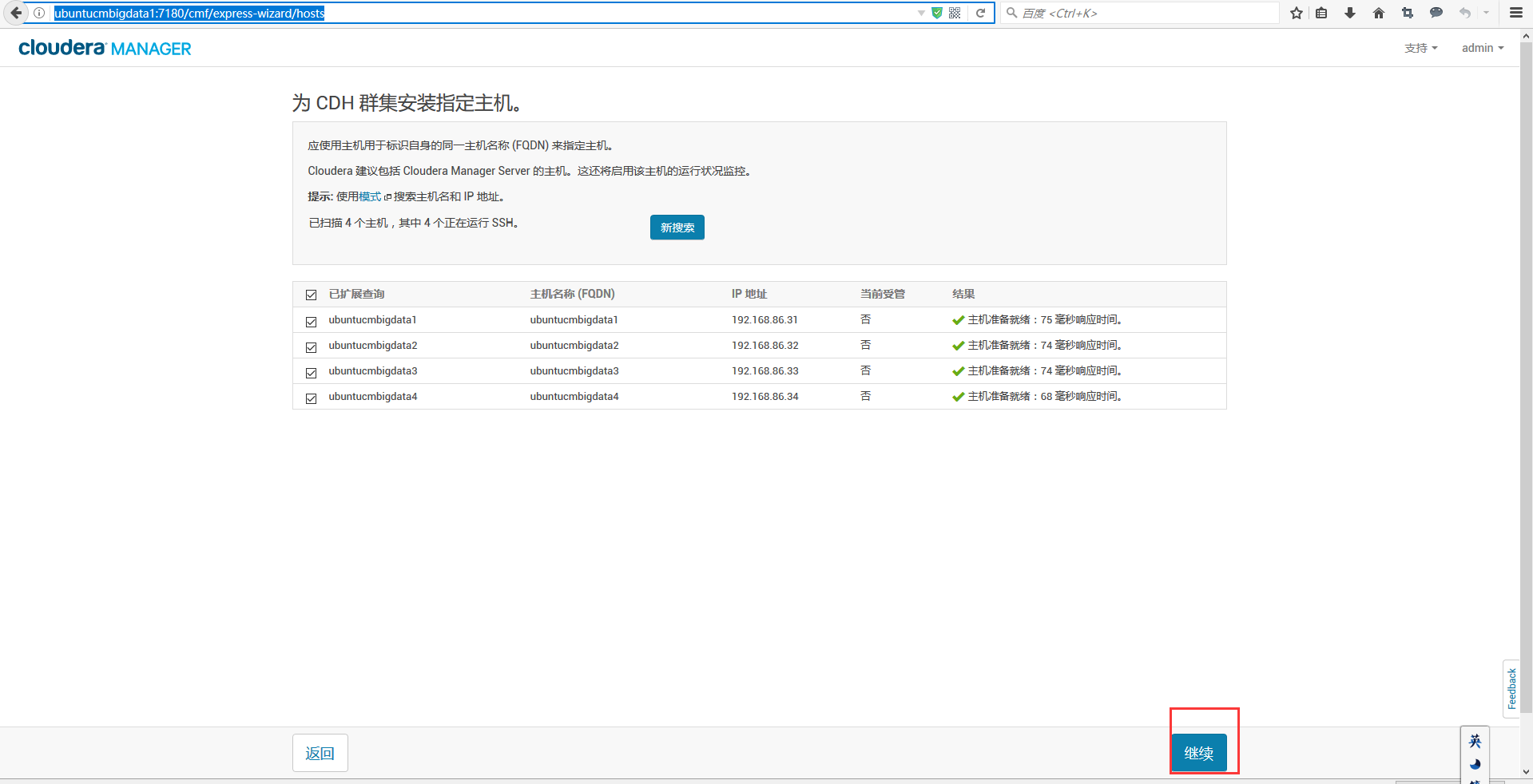
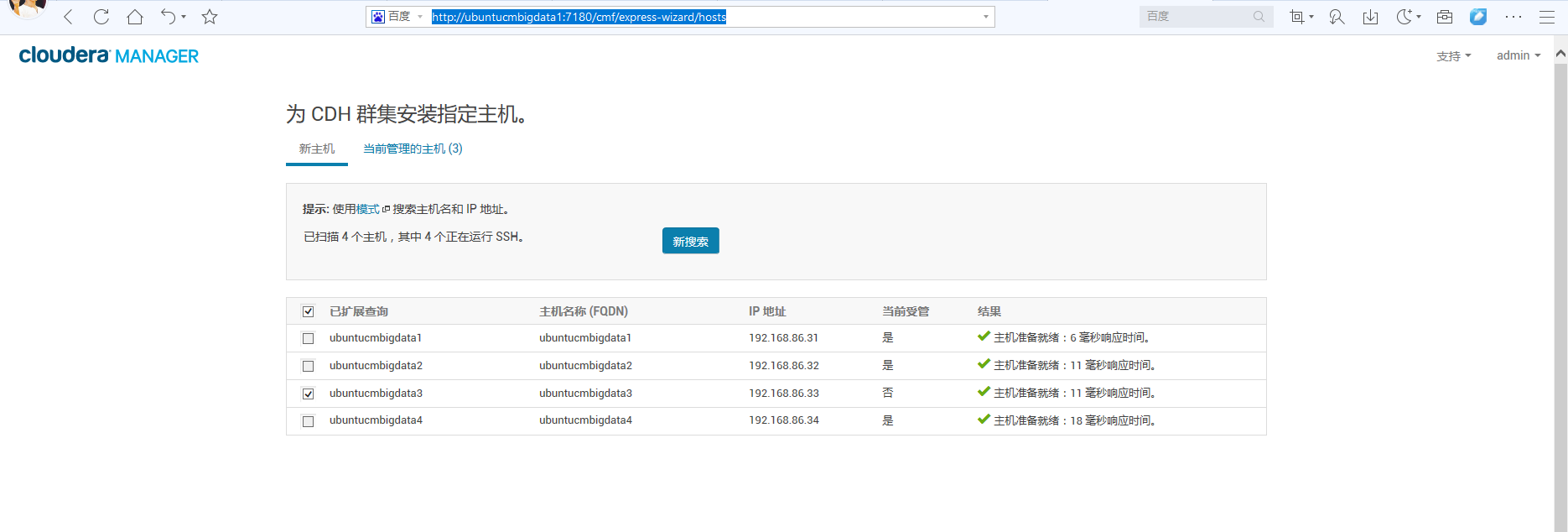
有时候会是如下,
那是因为,ubuntucmbigdata3这台的服务没启动。
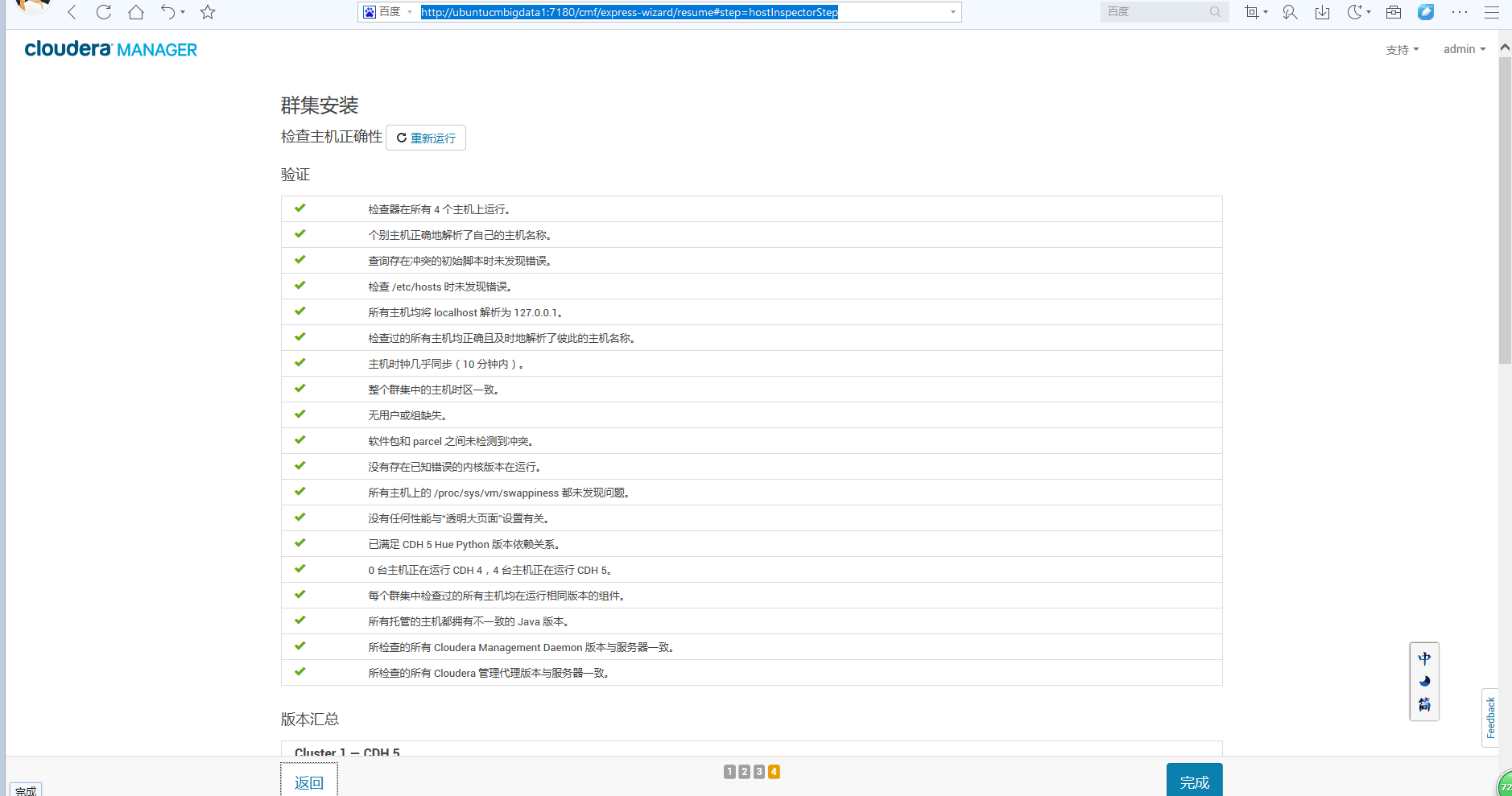
一般,若大家按照我本博文的顶部,把每台机器相应的服务,都启动起来了的话,则是如下(是最好的)

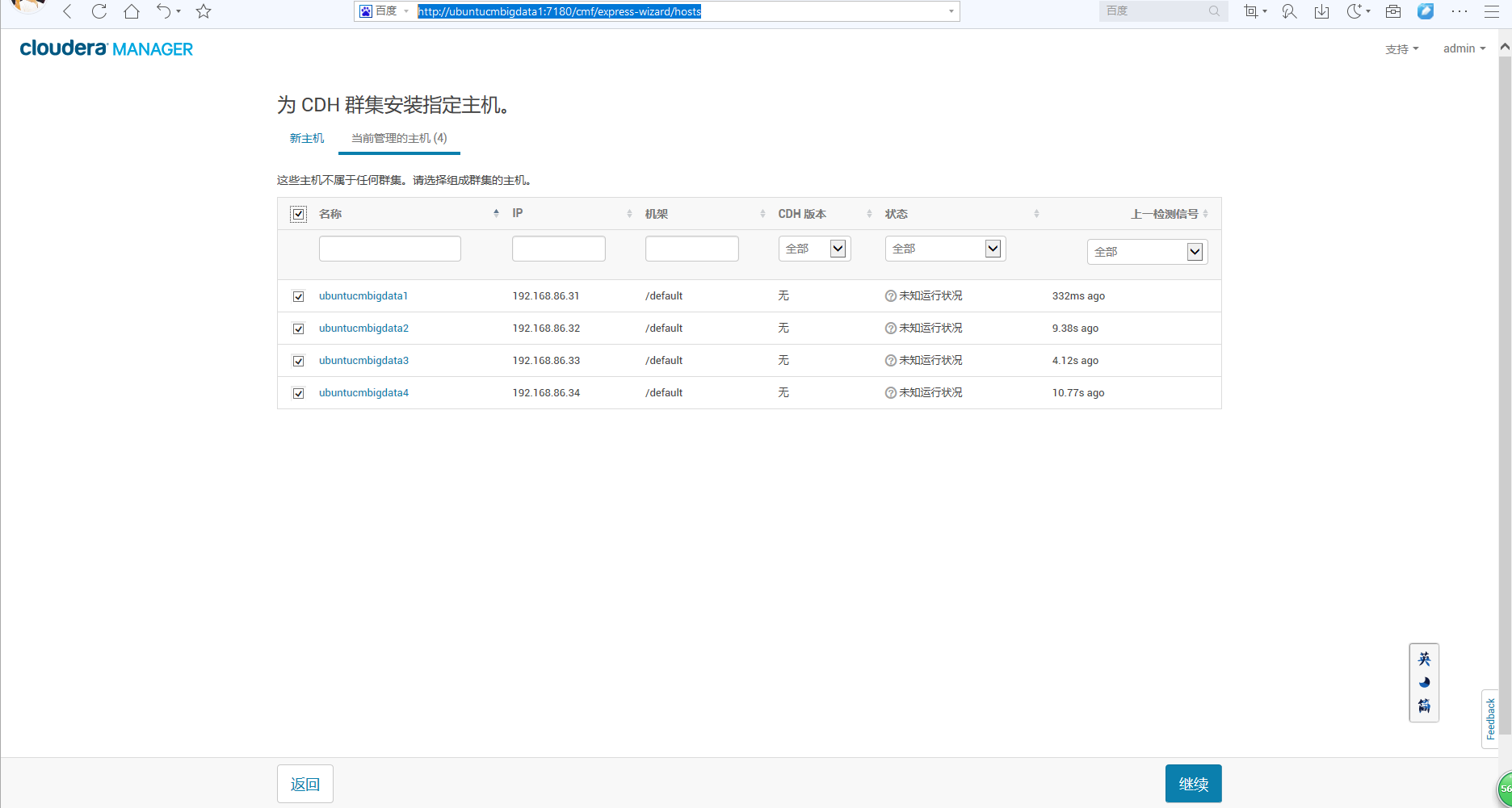
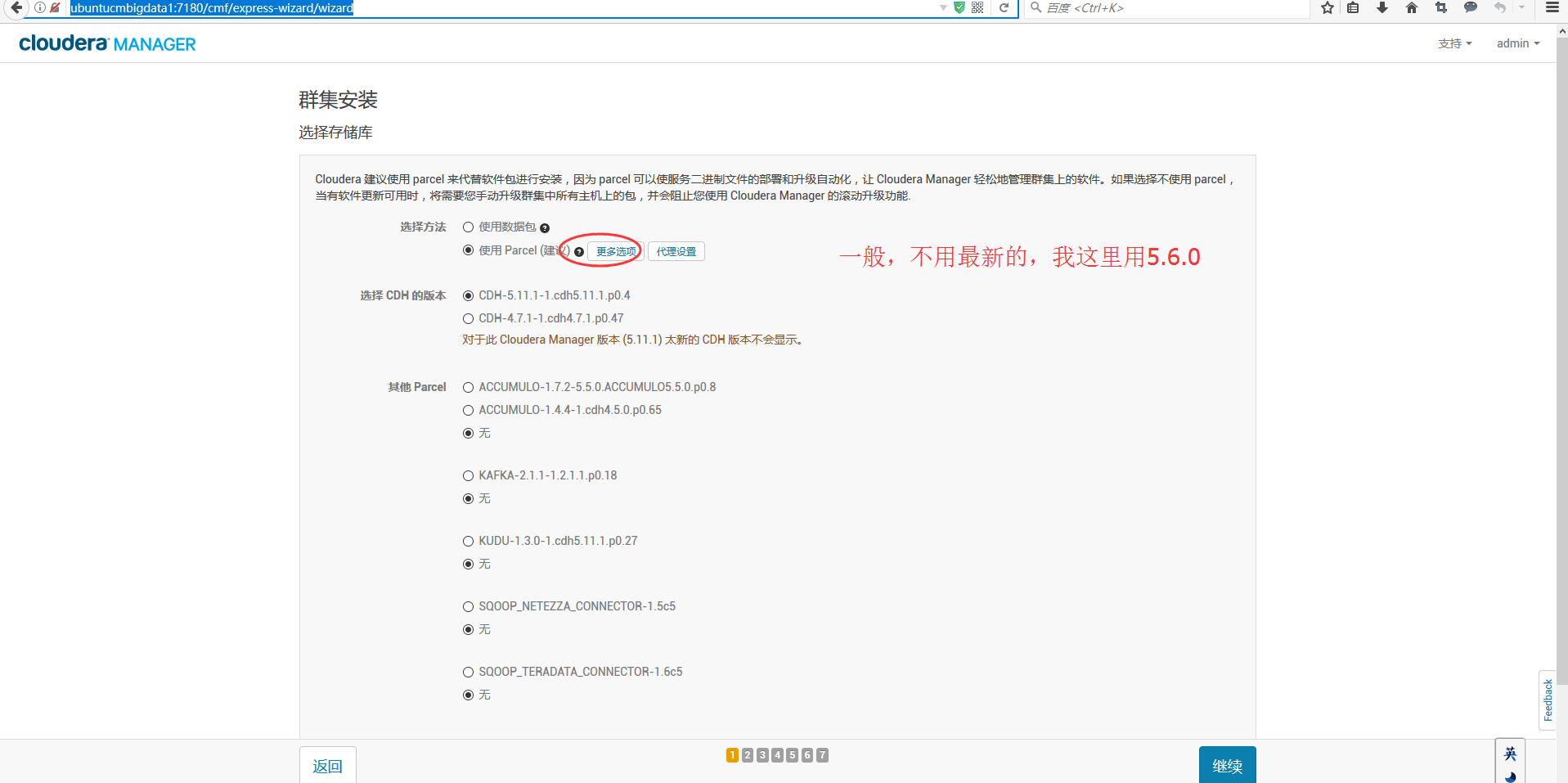
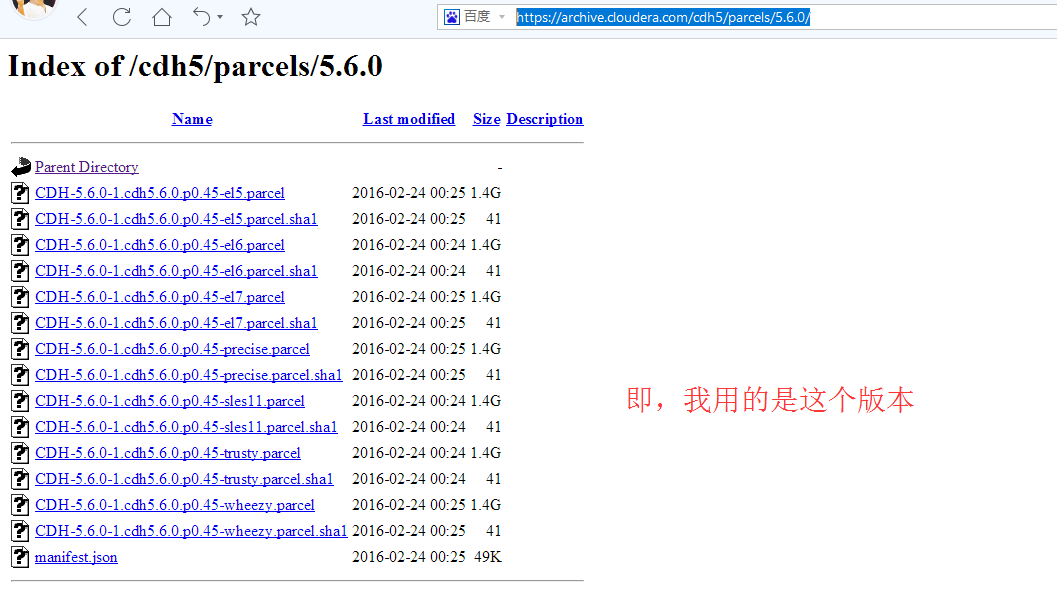
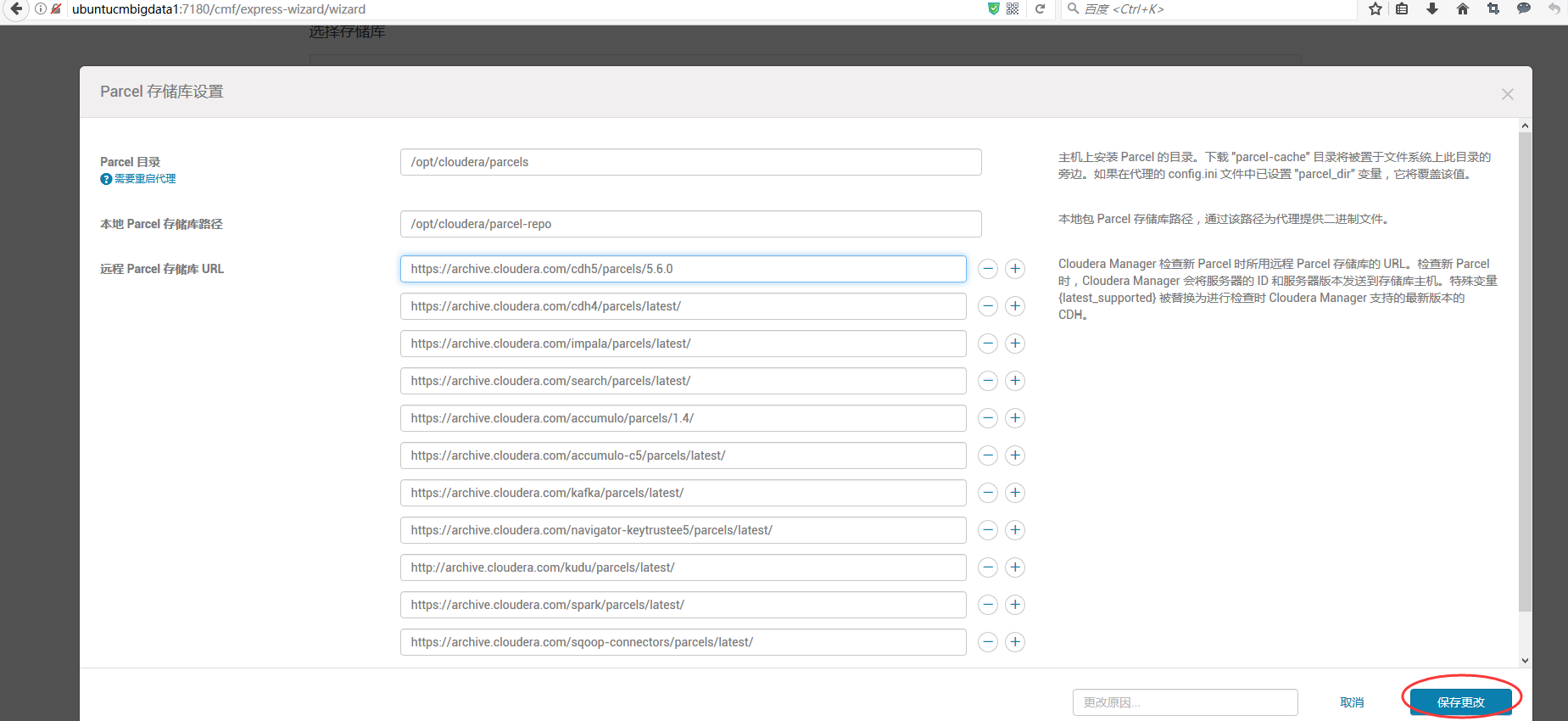
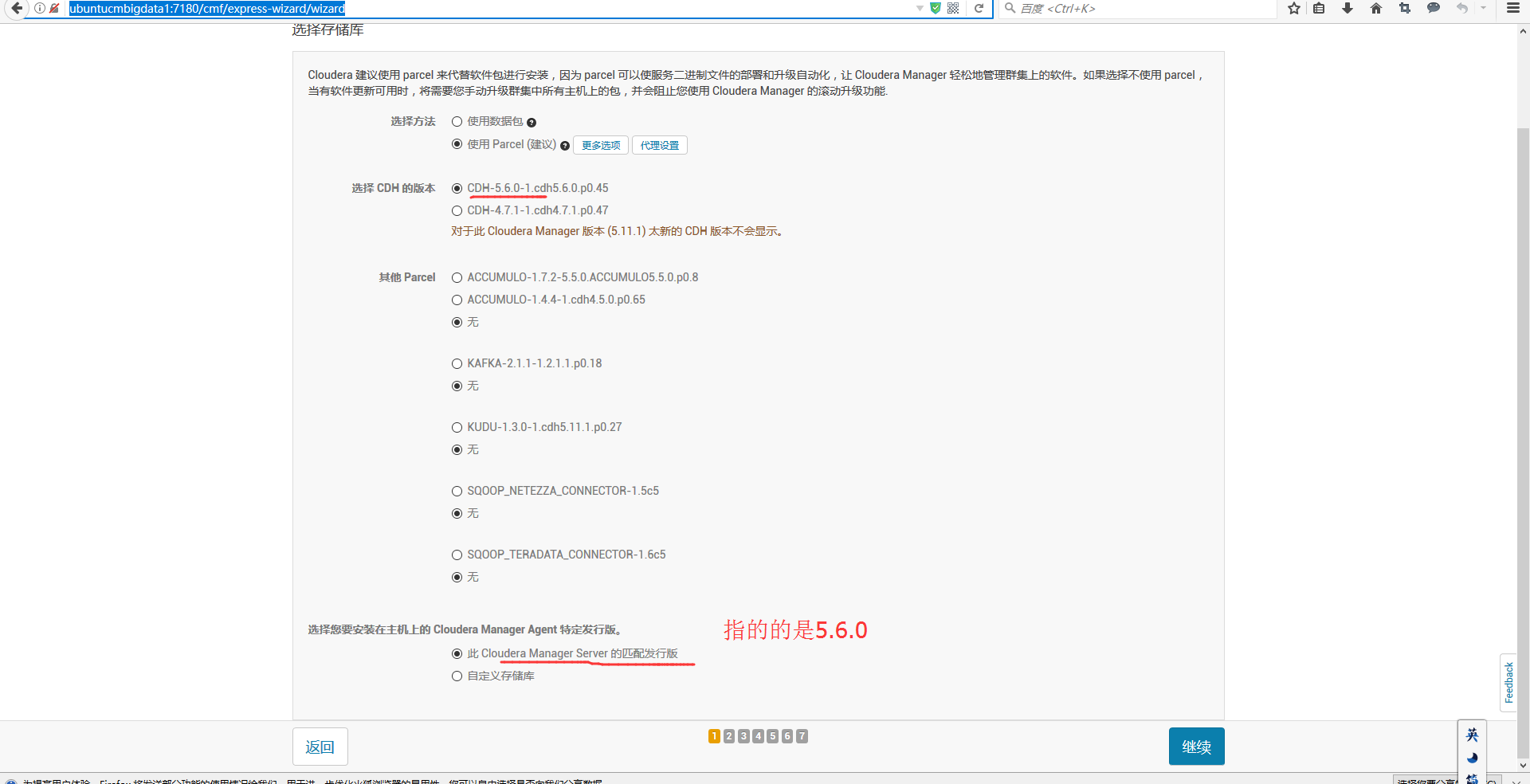
或者

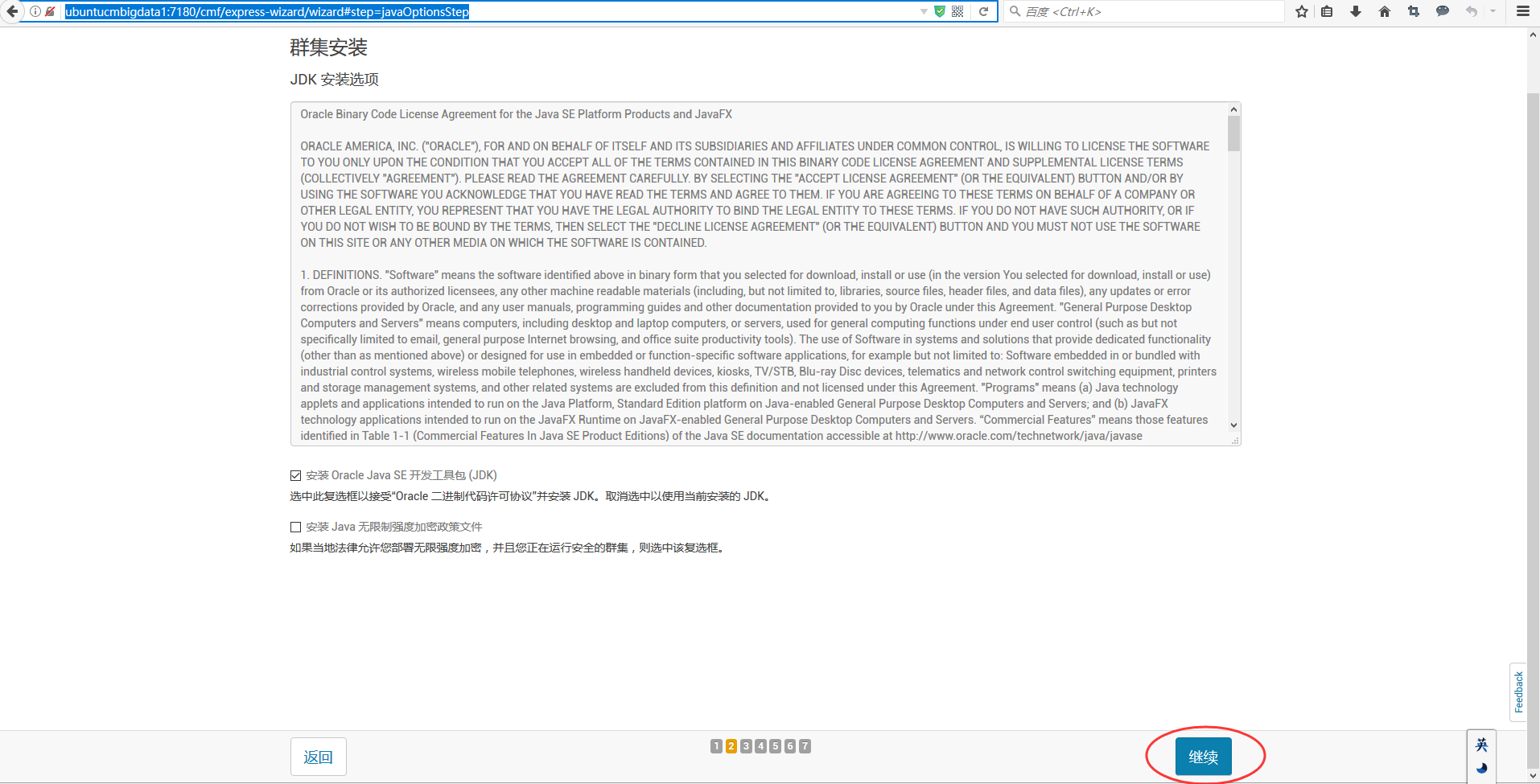
如果你的本地里,已经安装好了,比如我这里的jdk1.7,则这里就不需要勾选,不然会报错后面 (但是,若大家通过我的bin方式来安装的话,是直接没有安装任何jdk的,直接是上面一样,勾选,它会自动好jdk)
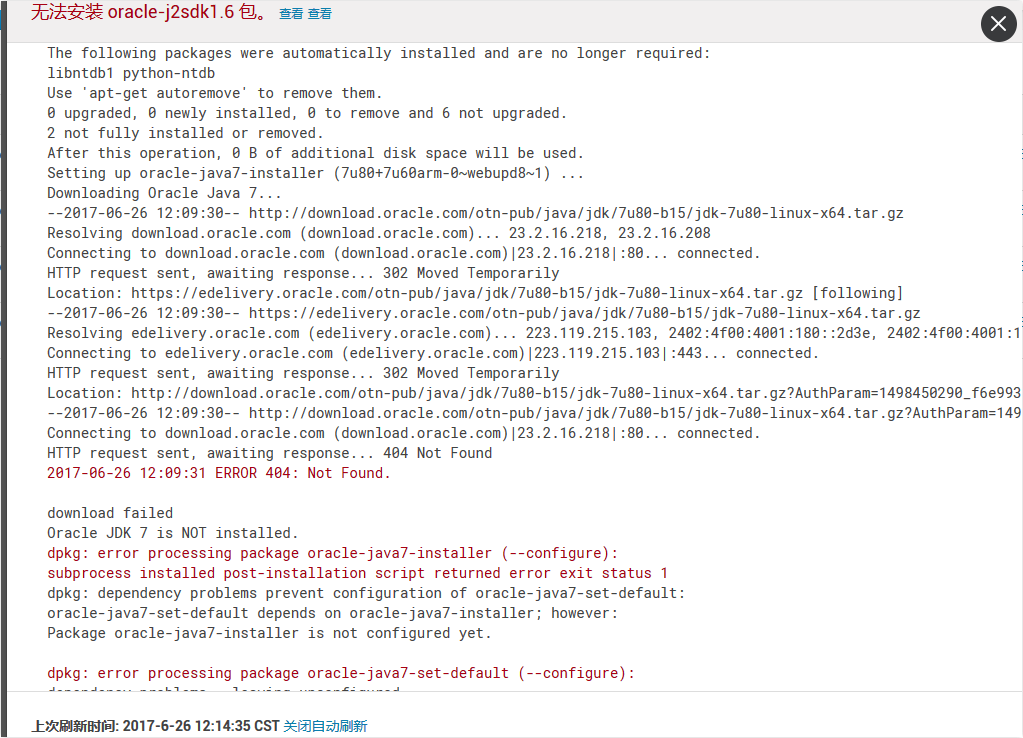
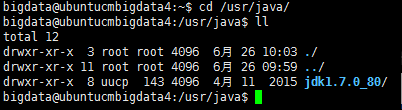

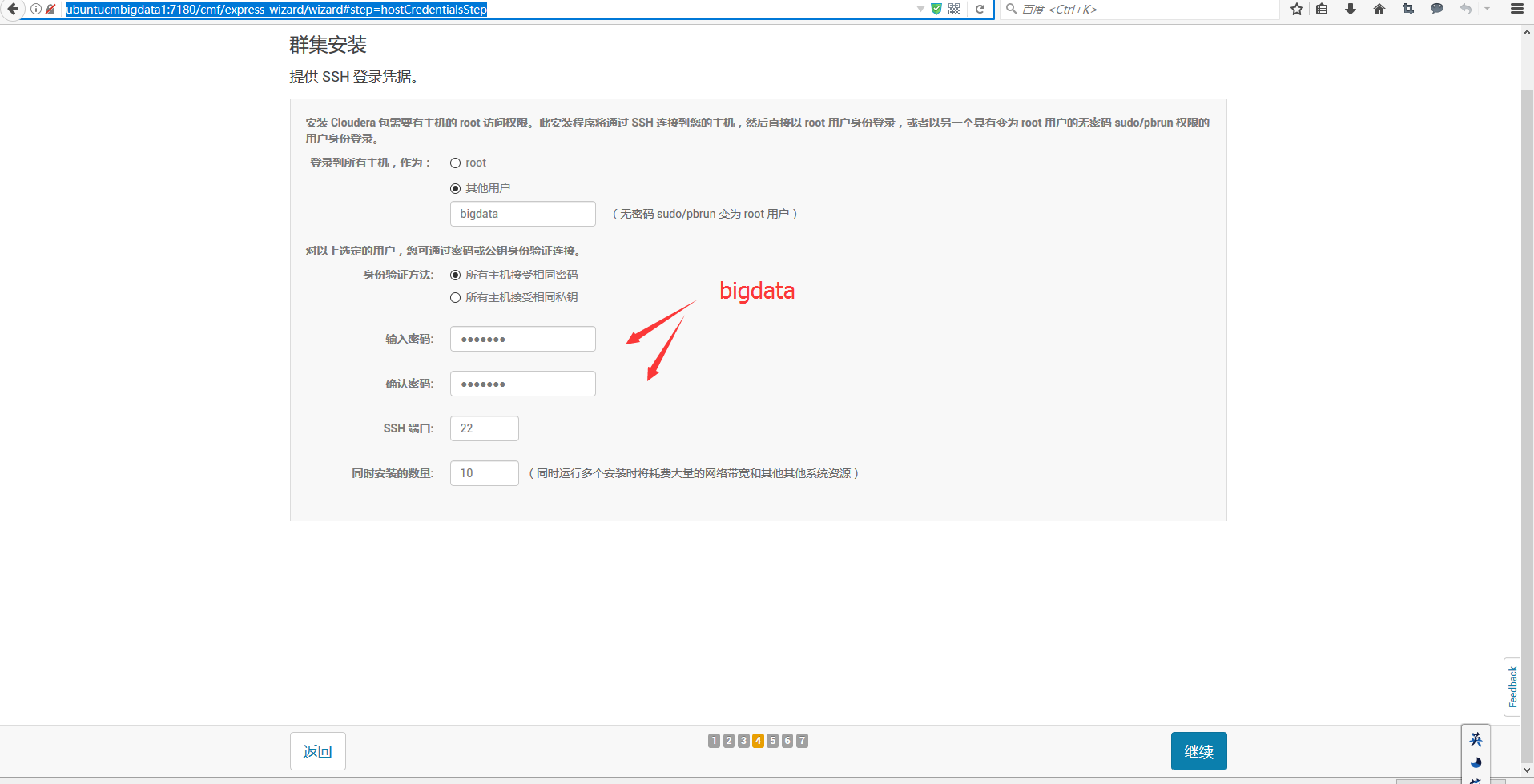
http://ubuntucmbigdata1:7180/cmf/express-wizard/wizard#step=hostCredentialsStep
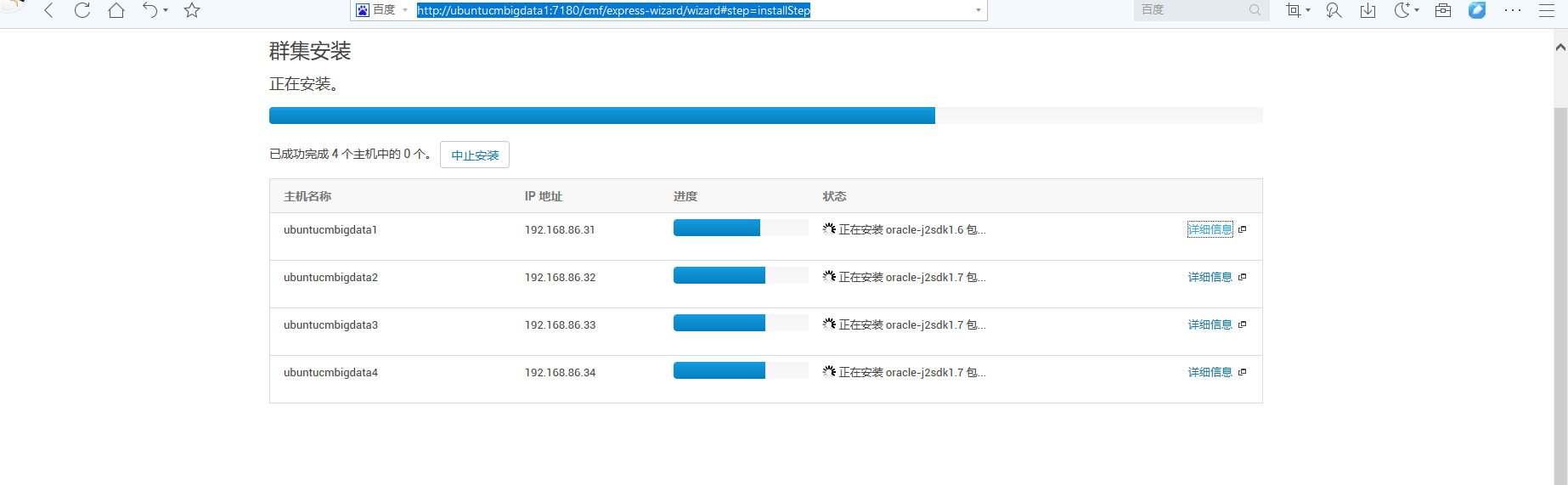

由此可见,我的ubuntucmbigdata2、ubuntucmbigdata3和ubuntucmbigdata4,是clouder manager agent。
如下的界面,是因为,我提前没有安装好,所以是在线此刻安装的。
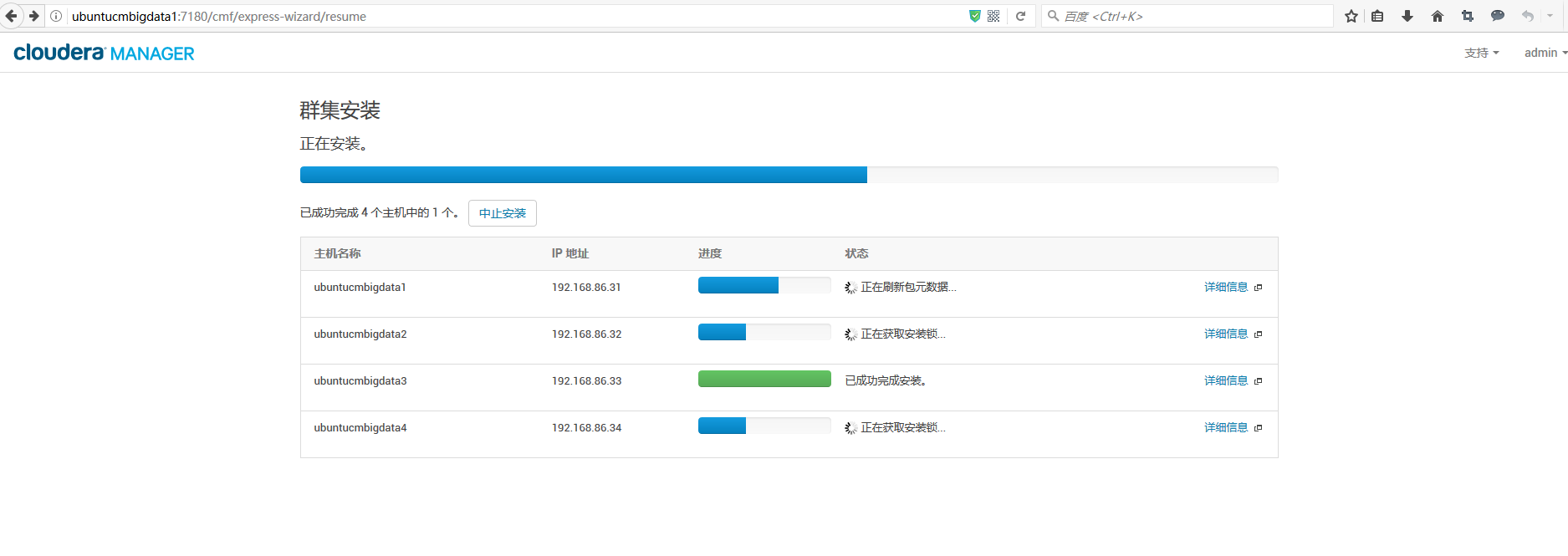
两种方式都可以
或者(以下,是因为,我已经先提前在这一步安装好了,所以是如下的界面)



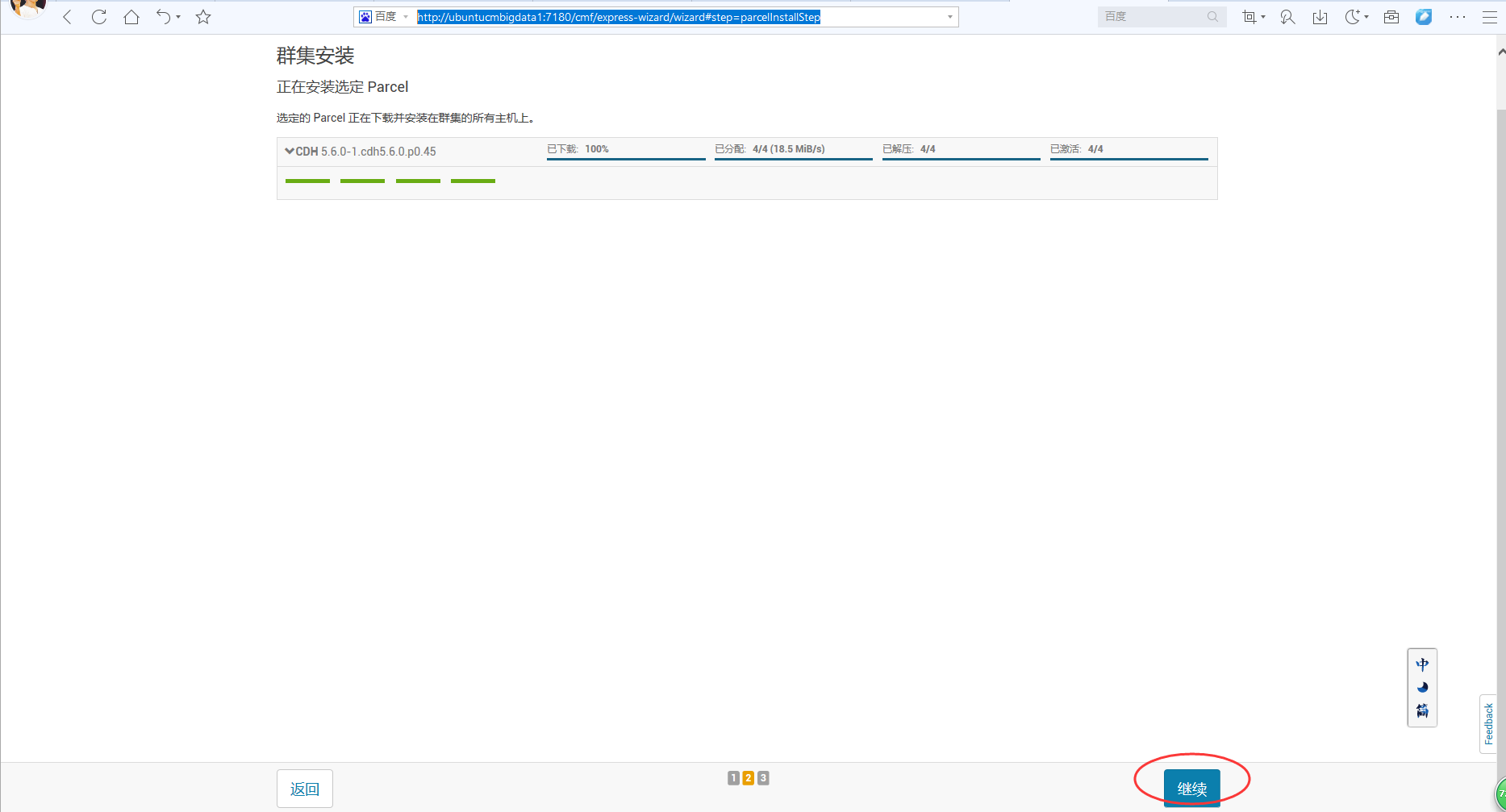
若出现如下问题,则
bigdata@ubuntucmbigdata1:~$ sudo echo > /proc/sys/vm/swappiness
-bash: /proc/sys/vm/swappiness: Permission denied
bigdata@ubuntucmbigdata1:~$ su root
Password:
root@ubuntucmbigdata1:/home/bigdata# sudo echo > /proc/sys/vm/swappiness
root@ubuntucmbigdata1:/home/bigdata# bigdata@ubuntucmbigdata2:~$ sudo echo > /proc/sys/vm/swappiness
-bash: /proc/sys/vm/swappiness: Permission denied
bigdata@ubuntucmbigdata2:~$ su root
Password:
root@ubuntucmbigdata2:/home/bigdata# sudo echo > /proc/sys/vm/swappiness
root@ubuntucmbigdata2:/home/bigdata# bigdata@ubuntucmbigdata3:~$ sudo echo > /proc/sys/vm/swappiness
-bash: /proc/sys/vm/swappiness: Permission denied
bigdata@ubuntucmbigdata3:~$ su root
Password:
root@ubuntucmbigdata3:/home/bigdata# sudo echo > /proc/sys/vm/swappiness
root@ubuntucmbigdata3:/home/bigdata# bigdata@ubuntucmbigdata4:~$ sudo echo > /proc/sys/vm/swappiness
-bash: /proc/sys/vm/swappiness: Permission denied
bigdata@ubuntucmbigdata4:~$ su root
Password:
root@ubuntucmbigdata4:/home/bigdata# sudo echo > /proc/sys/vm/swappiness
root@ubuntucmbigdata4:/home/bigdata#


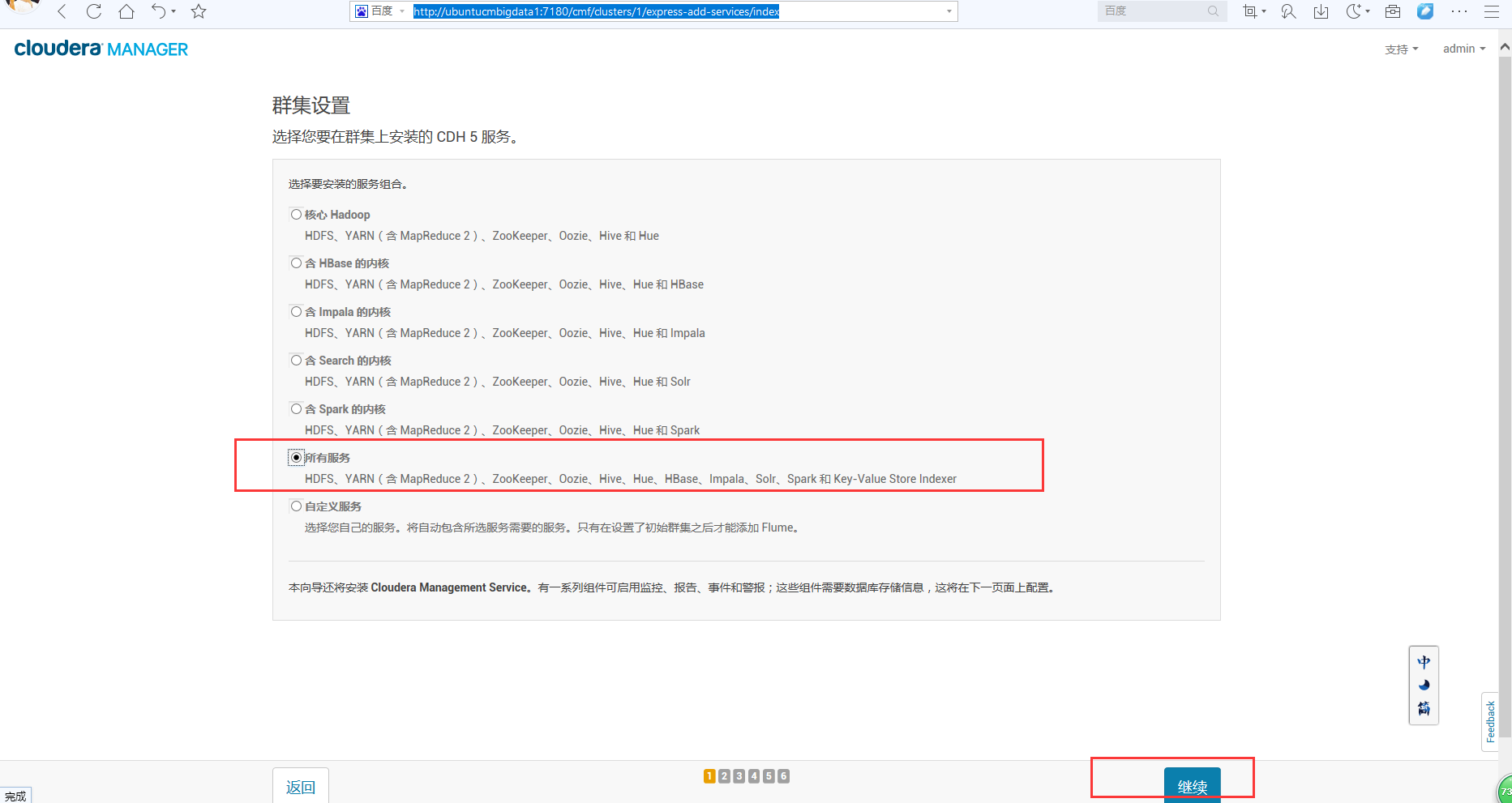
然后,接下来,这一步,其实跟我另外写的一篇用ambari是一样的。
Ambari安装之部署3个节点的HA分布式集群
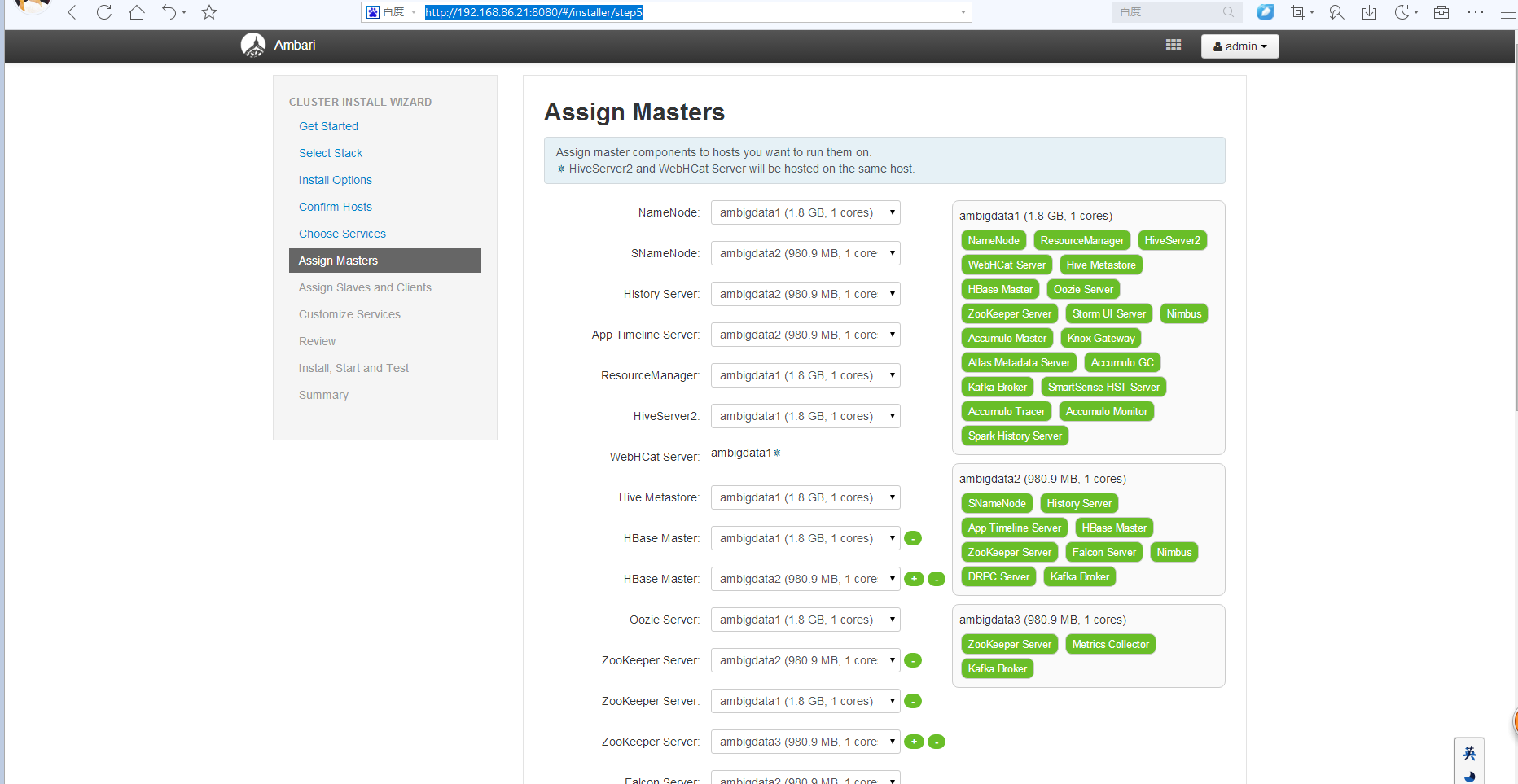
最后,我的初步安装是
其实,也跟我写的这篇博客也类似
Cloudera Manager安装之利用parcels方式安装3或4节点集群(包含最新稳定版本或指定版本的安装)(添加服务)(CentOS6.5)(五)

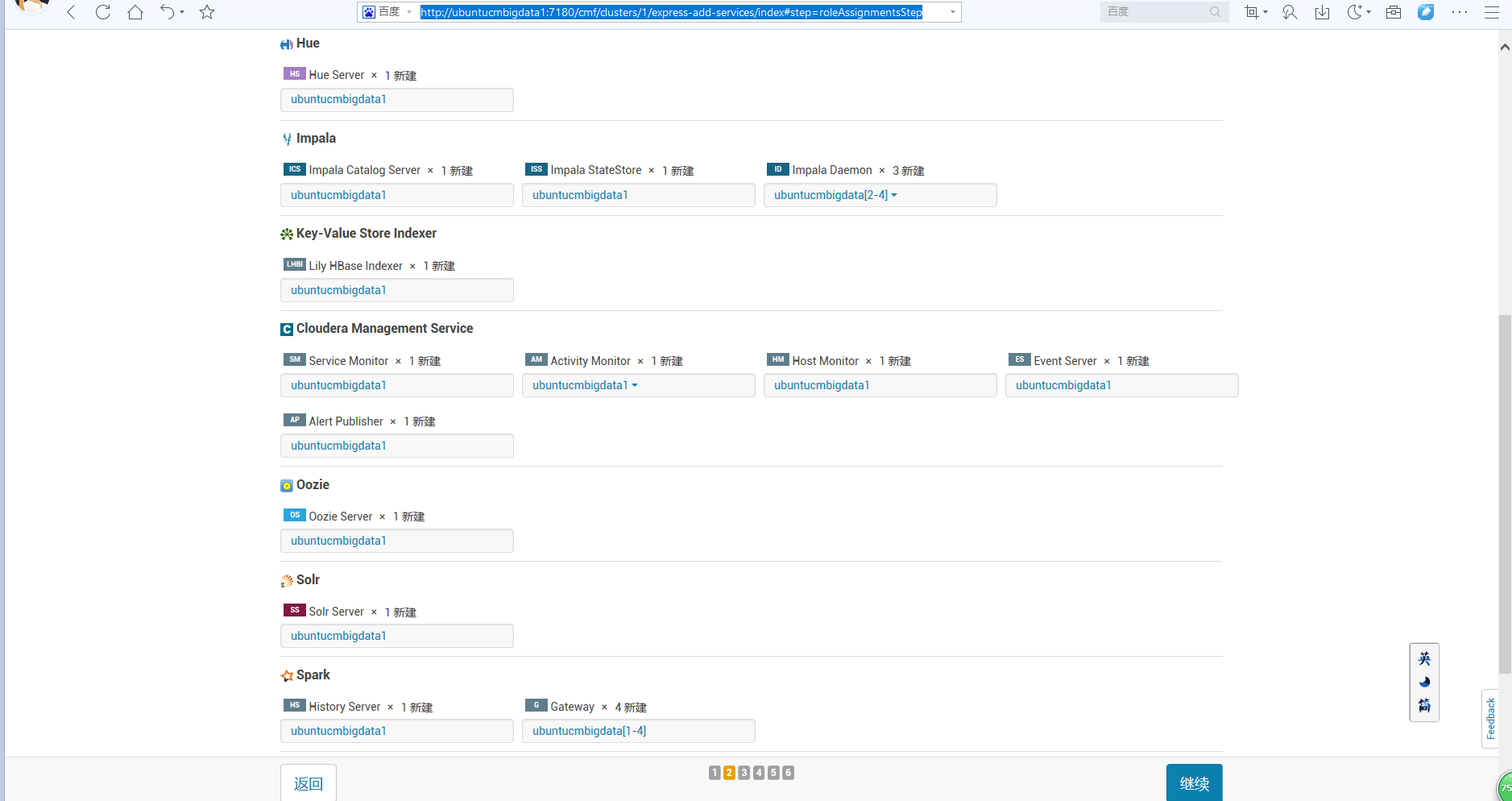
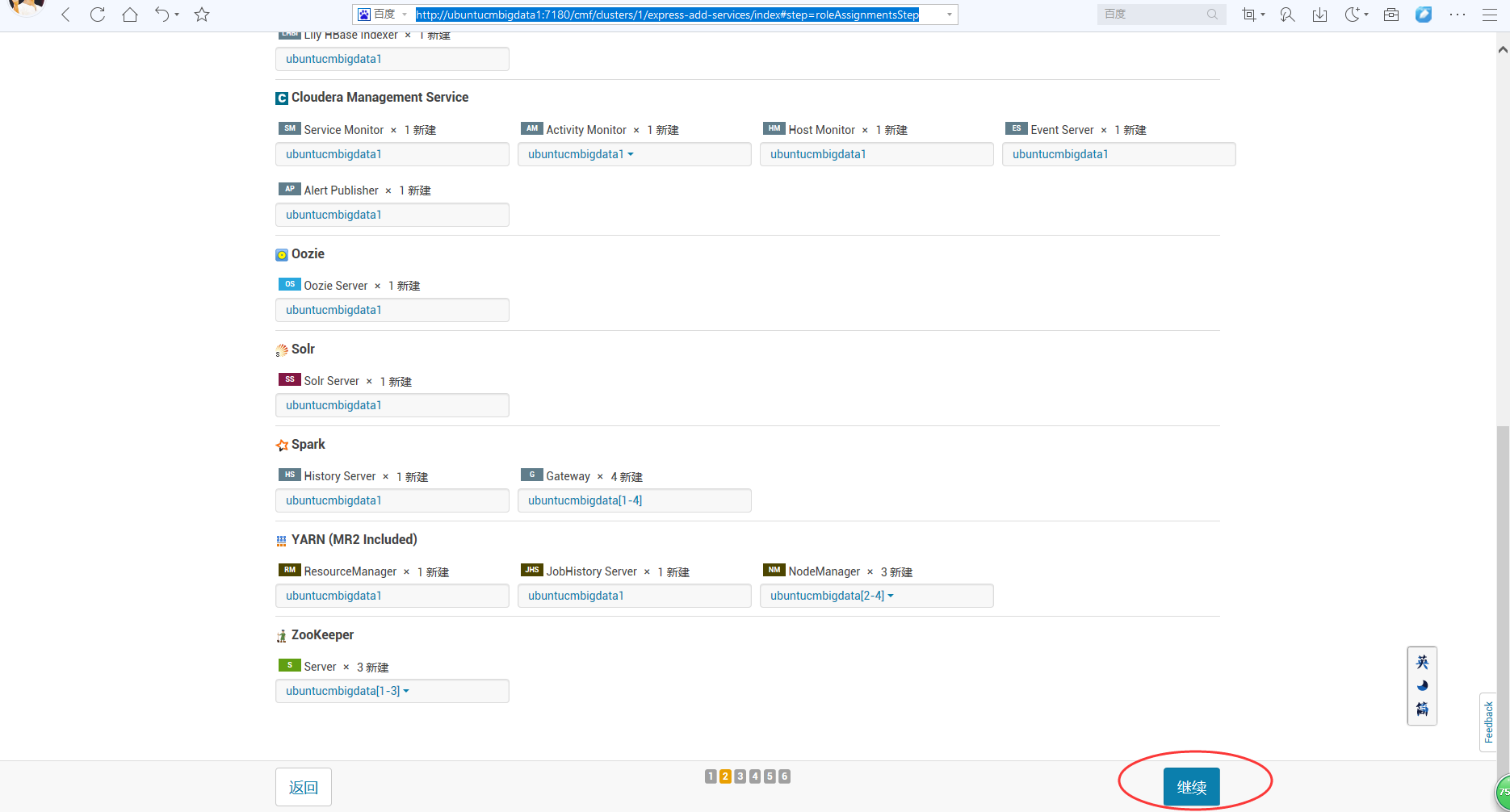

这里,我的数据库设置是在下面的博客就已经设置好了的。
Ubuntu14.04下完美安装cloudermanage多种方式(图文详解)(博主推荐)
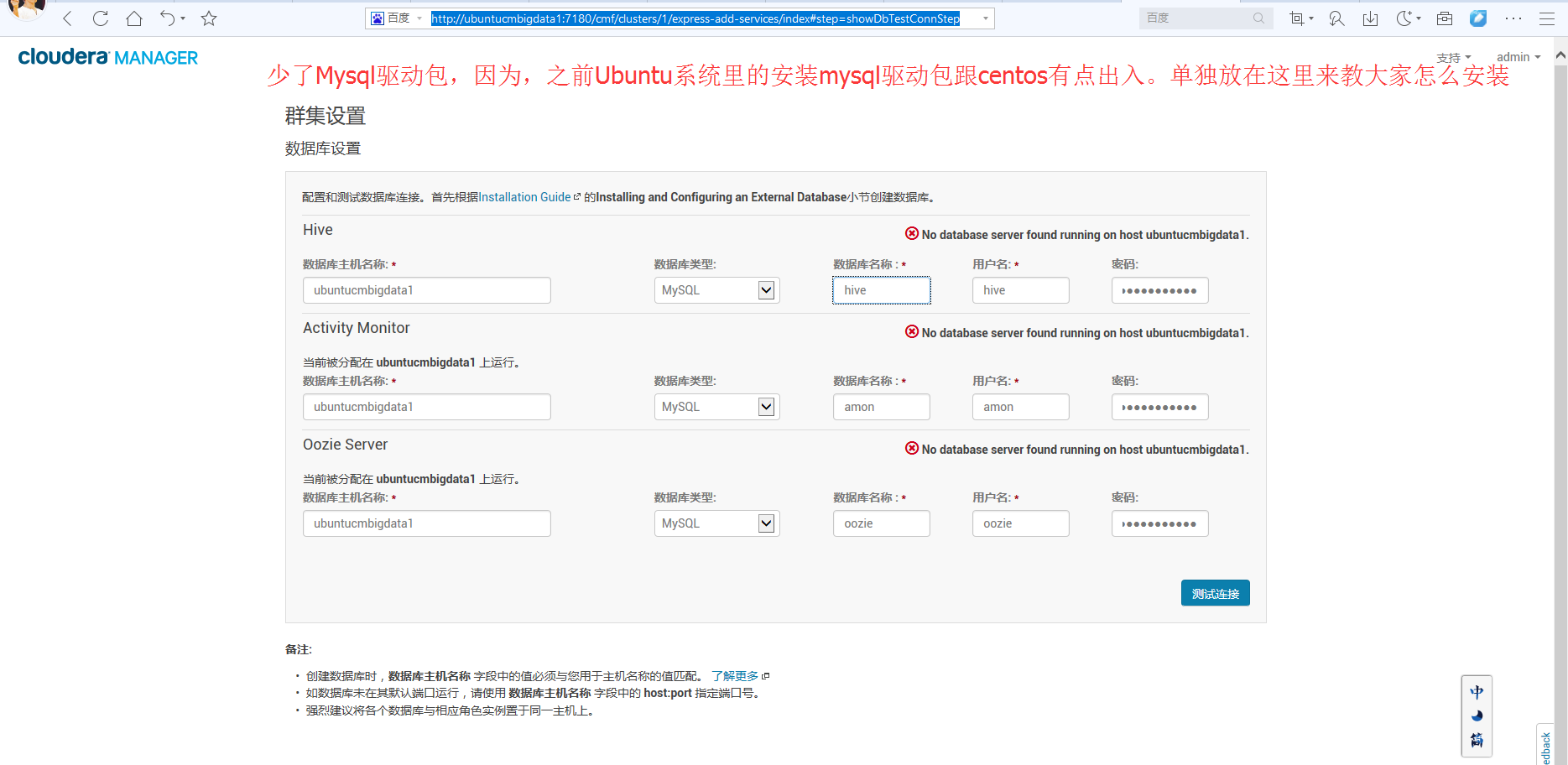
若是centos系统,则是可以直接
[root@cmbigdata1 ~]# yum install mysql-connector-java
Is this ok [y/N]: y
就好了。
但是,在ubuntu系统里,
root@ubuntucmbigdata1:/home/bigdata# apt-get install libmysql-java
则会失败。
解决办法1
root@ubuntucmbigdata1:~# sudo /etc/init.d/mysql start
查看你的mysql服务启动没。
解决办法2
root@ubuntucmbigdata1:/usr/share/java# pwd
/usr/share/java
root@ubuntucmbigdata1:/usr/share/java# ls
gettext.jar java_defaults.mk java_uno.jar juh-4.2..jar juh.jar jurt-4.2..jar jurt.jar libintl.jar mysql-connector-java-5.1..jar mysql-connector-java.jar mysql.jar ridl-4.2..jar ridl.jar unoloader.jar
root@ubuntucmbigdata1:/usr/share/java# sudo cp /usr/share/java/mysql-connector-java-5.1..jar /var/lib/oozie
root@ubuntucmbigdata1:/usr/share/java# cd /var/lib//oozie/
root@ubuntucmbigdata1:/var/lib/oozie# ls
examples.desktop mysql-connector-java-5.1..jar
root@ubuntucmbigdata1:/var/lib/oozie#
sudo cp /usr/share/java/mysql-connector-java-5.1.28.jar /var/lib/oozie
bigdata@ubuntucmbigdata1:/opt/cloudera/parcels/CDH-5.6.-.cdh5.6.0.p0./lib$ pwd
/opt/cloudera/parcels/CDH-5.6.-.cdh5.6.0.p0./lib
bigdata@ubuntucmbigdata1:/opt/cloudera/parcels/CDH-5.6.-.cdh5.6.0.p0./lib$ ls
avro debug hadoop-hdfs hadoop-yarn hive-hcatalog kite libImpalaUdf-retail.a libzookeeper_mt.so. libzookeeper_st.so mahout search sqoop zookeeper-native
bigtop-tomcat flume-ng hadoop-httpfs hbase hue libhdfs.so libzookeeper_mt.a libzookeeper_mt.so.2.0. libzookeeper_st.so. oozie sentry sqoop2
bigtop-utils hadoop hadoop-kms hbase-solr impala libhdfs.so.0.0. libzookeeper_mt.la libzookeeper_st.a libzookeeper_st.so.2.0. parquet solr whirr
crunch hadoop-0.20-mapreduce hadoop-mapreduce hive impala-shell libImpalaUdf-debug.a libzookeeper_mt.so libzookeeper_st.la llama pig spark zookeeper
bigdata@ubuntucmbigdata1:/opt/cloudera/parcels/CDH-5.6.-.cdh5.6.0.p0./lib$ cd hive
bigdata@ubuntucmbigdata1:/opt/cloudera/parcels/CDH-5.6.-.cdh5.6.0.p0./lib/hive$ ls
bin cloudera conf lib LICENSE NOTICE scripts sentry
bigdata@ubuntucmbigdata1:/opt/cloudera/parcels/CDH-5.6.-.cdh5.6.0.p0./lib/hive$ cd lib/
bigdata@ubuntucmbigdata1:/opt/cloudera/parcels/CDH-5.6.-.cdh5.6.0.p0./lib/hive/lib$ ls
accumulo-core-1.6..jar commons-compress-1.4..jar hbase-client.jar hive-jdbc-1.1.-cdh5.6.0.jar jackson-databind-2.2..jar metrics-jvm-3.0..jar
accumulo-fate-1.6..jar commons-configuration-1.6.jar hbase-common.jar hive-jdbc-1.1.-cdh5.6.0-standalone.jar jackson-jaxrs-1.9..jar opencsv-2.3.jar
accumulo-start-1.6..jar commons-dbcp-1.4.jar hbase-hadoop2-compat.jar hive-jdbc.jar jackson-xc-1.9..jar oro-2.0..jar
accumulo-trace-1.6..jar commons-digester-1.8.jar hbase-hadoop-compat.jar hive-jdbc-standalone.jar janino-2.7..jar paranamer-2.3.jar
activation-1.1.jar commons-httpclient-3.0..jar hbase-protocol.jar hive-metastore-1.1.-cdh5.6.0.jar jcommander-1.32.jar parquet-hadoop-bundle.jar
ant-1.9..jar commons-io-2.4.jar hbase-server.jar hive-metastore.jar jdo-api-3.0..jar pentaho-aggdesigner-algorithm-5.1.-jhyde.jar
ant-launcher-1.9..jar commons-lang-2.6.jar high-scale-lib-1.1..jar hive-serde-1.1.-cdh5.6.0.jar jersey-server-1.14.jar php
antlr-2.7..jar commons-logging-1.1..jar hive-accumulo-handler-1.1.-cdh5.6.0.jar hive-serde.jar jersey-servlet-1.14.jar plexus-utils-1.5..jar
antlr-runtime-3.4.jar commons-math-2.1.jar hive-accumulo-handler.jar hive-service-1.1.-cdh5.6.0.jar jetty-all-7.6..v20120127.jar py
apache-curator-2.6..pom commons-pool-1.5..jar hive-ant-1.1.-cdh5.6.0.jar hive-service.jar jetty-all-server-7.6..v20120127.jar regexp-1.3.jar
apache-log4j-extras-1.2..jar commons-vfs2-2.0.jar hive-ant.jar hive-shims-0.23-1.1.-cdh5.6.0.jar jline-2.12.jar servlet-api-2.5.jar
asm-3.2.jar curator-client-2.6..jar hive-beeline-1.1.-cdh5.6.0.jar hive-shims-0.23.jar jpam-1.1.jar snappy-java-1.0.4.1.jar
asm-commons-3.1.jar curator-framework-2.6..jar hive-beeline.jar hive-shims-1.1.-cdh5.6.0.jar jsr305-3.0..jar ST4-4.0..jar
asm-tree-3.1.jar datanucleus-api-jdo-3.2..jar hive-cli-1.1.-cdh5.6.0.jar hive-shims-common-1.1.-cdh5.6.0.jar jta-1.1.jar stax-api-1.0..jar
avro.jar datanucleus-core-3.2..jar hive-cli.jar hive-shims-common.jar junit-4.11.jar stringtemplate-3.2..jar
bonecp-0.8..RELEASE.jar datanucleus-rdbms-3.2..jar hive-common-1.1.-cdh5.6.0.jar hive-shims.jar libfb303-0.9..jar super-csv-2.2..jar
calcite-avatica-1.0.-incubating.jar derby-10.11.1.1.jar hive-common.jar hive-shims-scheduler-1.1.-cdh5.6.0.jar libthrift-0.9..jar tempus-fugit-1.1.jar
calcite-core-1.0.-incubating.jar eigenbase-properties-1.1..jar hive-contrib-1.1.-cdh5.6.0.jar hive-shims-scheduler.jar log4j-1.2..jar velocity-1.5.jar
calcite-linq4j-1.0.-incubating.jar geronimo-annotation_1.0_spec-1.1..jar hive-contrib.jar hive-testutils-1.1.-cdh5.6.0.jar logredactor-1.0..jar xz-1.0.jar
commons-beanutils-1.7..jar geronimo-jaspic_1.0_spec-1.0.jar hive-exec-1.1.-cdh5.6.0.jar hive-testutils.jar mail-1.4..jar zookeeper.jar
commons-beanutils-core-1.8..jar geronimo-jta_1.1_spec-1.1..jar hive-exec.jar htrace-core.jar maven-scm-api-1.4.jar
commons-cli-1.2.jar groovy-all-2.4..jar hive-hbase-handler-1.1.-cdh5.6.0.jar httpclient-4.2..jar maven-scm-provider-svn-commons-1.4.jar
commons-codec-1.4.jar gson-2.2..jar hive-hbase-handler.jar httpcore-4.2..jar maven-scm-provider-svnexe-1.4.jar
commons-collections-3.2..jar guava-14.0..jar hive-hwi-1.1.-cdh5.6.0.jar jackson-annotations-2.2..jar metrics-core-3.0..jar
commons-compiler-2.7..jar hamcrest-core-1.1.jar hive-hwi.jar jackson-core-2.2..jar metrics-json-3.0..jar
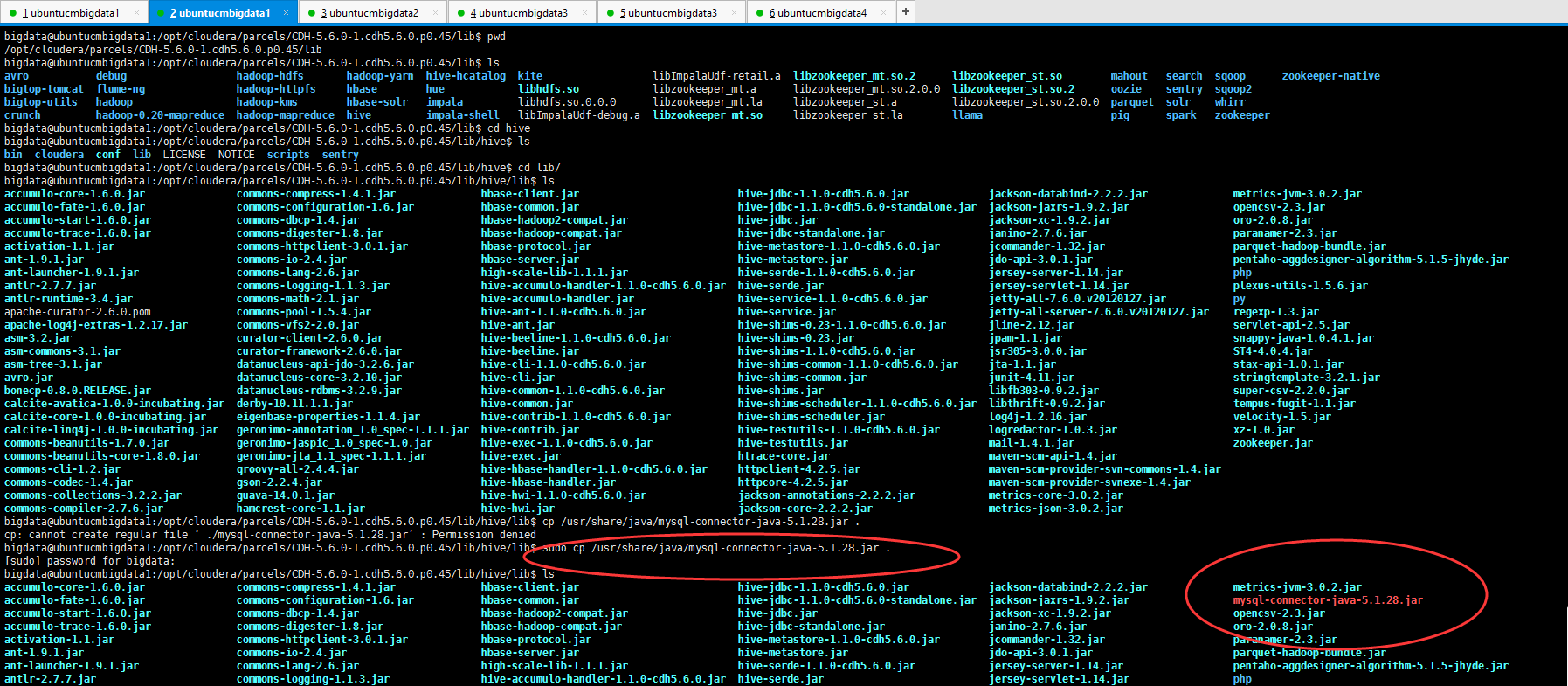
bigdata@ubuntucmbigdata1:/opt/cloudera/parcels/CDH-5.6.-.cdh5.6.0.p0./lib/hive/lib$ cp /usr/share/java/mysql-connector-java-5.1..jar .
cp: cannot create regular file ‘./mysql-connector-java-5.1..jar’: Permission denied
bigdata@ubuntucmbigdata1:/opt/cloudera/parcels/CDH-5.6.-.cdh5.6.0.p0./lib/hive/lib$ sudo cp /usr/share/java/mysql-connector-java-5.1..jar .
[sudo] password for bigdata:
bigdata@ubuntucmbigdata1:/opt/cloudera/parcels/CDH-5.6.-.cdh5.6.0.p0./lib/hive/lib$ ls
accumulo-core-1.6..jar commons-compress-1.4..jar hbase-client.jar hive-jdbc-1.1.-cdh5.6.0.jar jackson-databind-2.2..jar metrics-jvm-3.0..jar
accumulo-fate-1.6..jar commons-configuration-1.6.jar hbase-common.jar hive-jdbc-1.1.-cdh5.6.0-standalone.jar jackson-jaxrs-1.9..jar mysql-connector-java-5.1..jar
accumulo-start-1.6..jar commons-dbcp-1.4.jar hbase-hadoop2-compat.jar hive-jdbc.jar jackson-xc-1.9..jar opencsv-2.3.jar
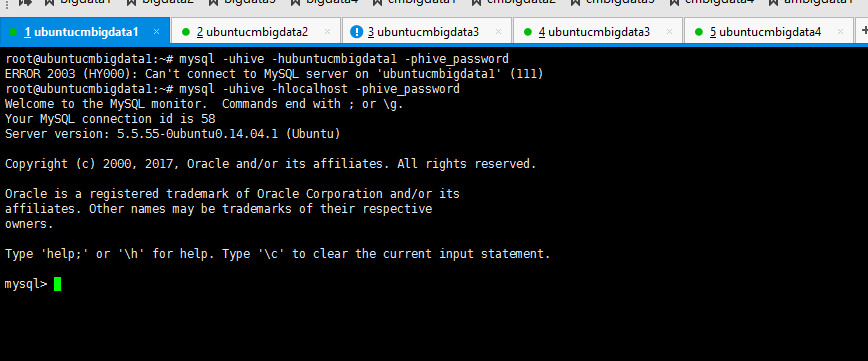
root@ubuntucmbigdata1:~# mysql -uhive -hubuntucmbigdata1 -phive_password
ERROR (HY000): Can't connect to MySQL server on 'ubuntucmbigdata1' (111)
root@ubuntucmbigdata1:~# mysql -uhive -hlocalhost -phive_password
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is
Server version: 5.5.-0ubuntu0.14.04. (Ubuntu) Copyright (c) , , Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> exit;
断定不是授权的问题。
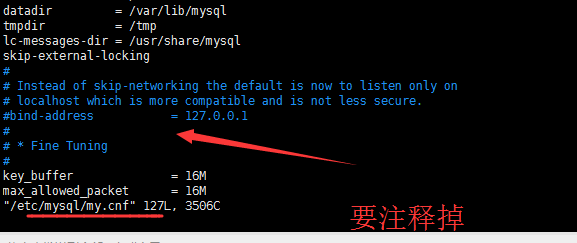
#bind-address = 127.0.0.1
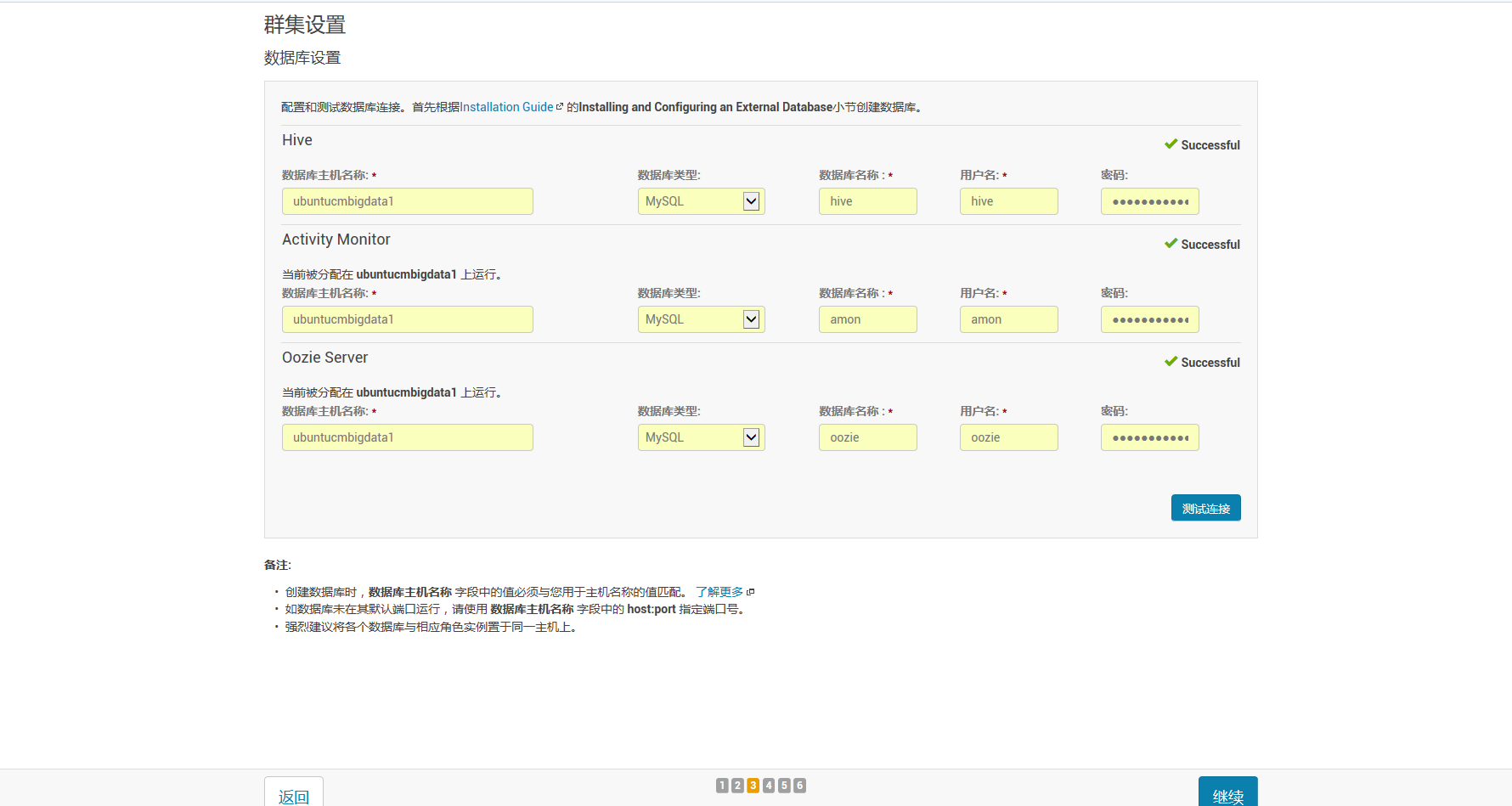
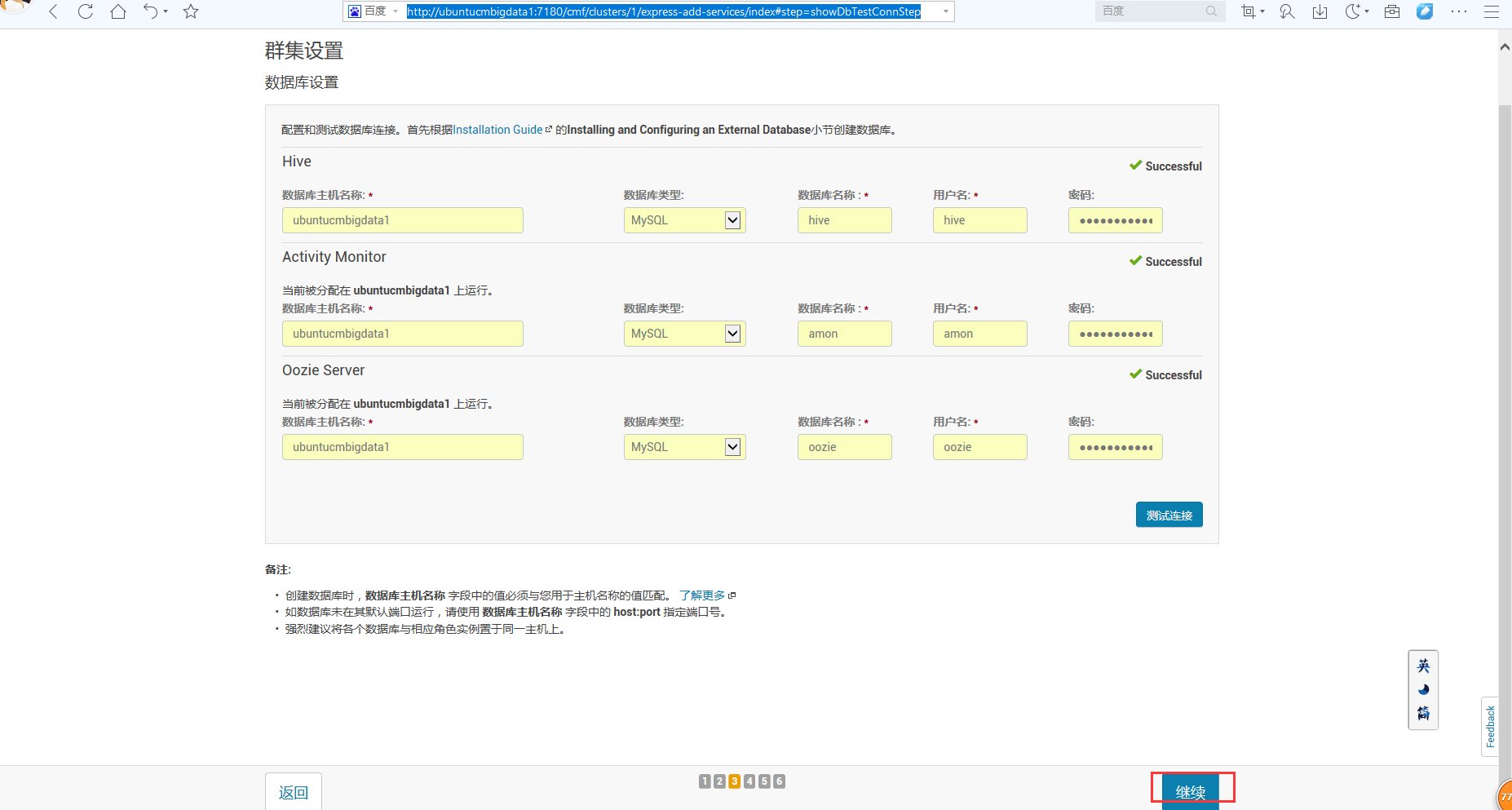
下面这里,大家看看就好,以后是可以更改的。
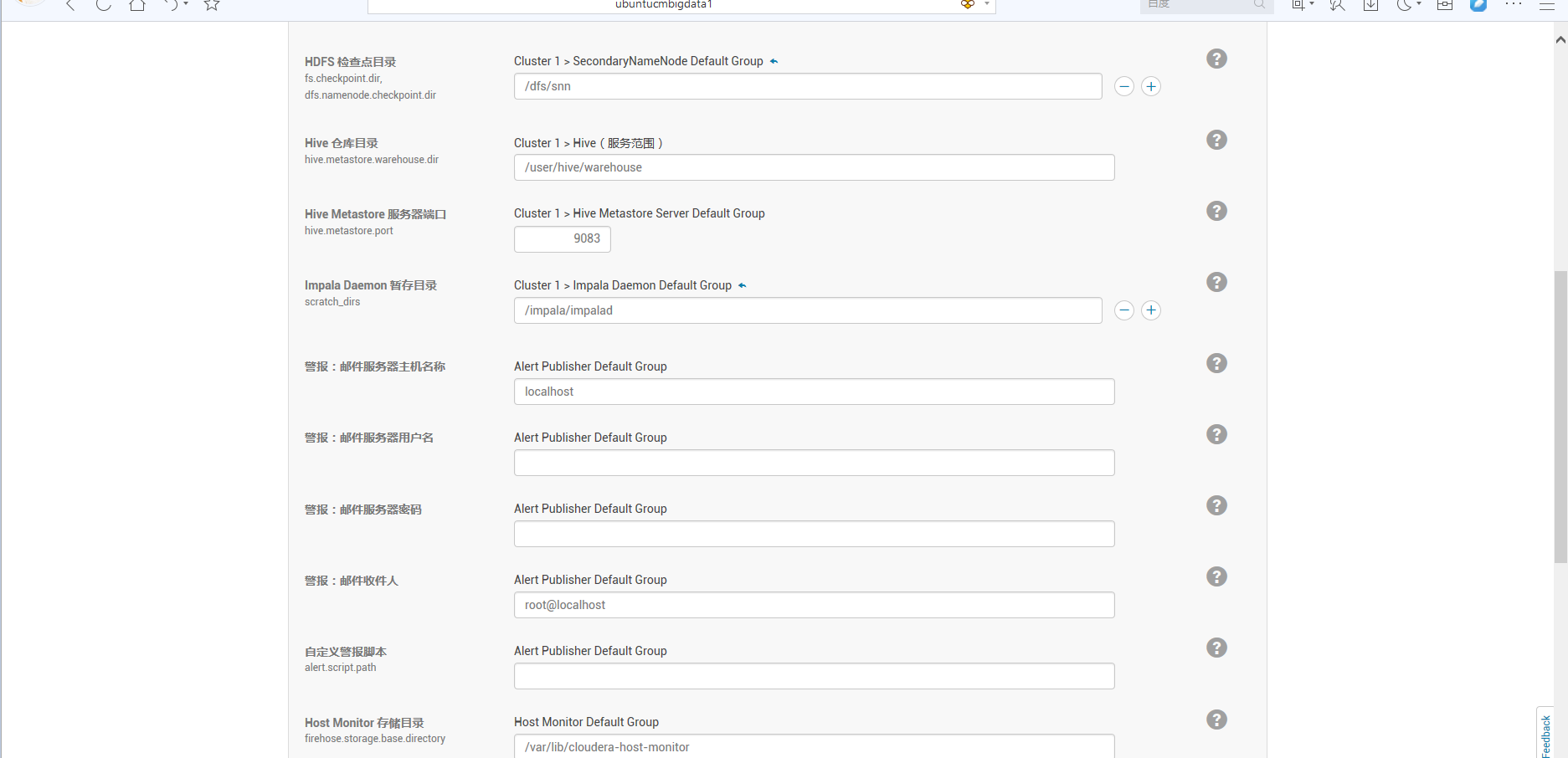
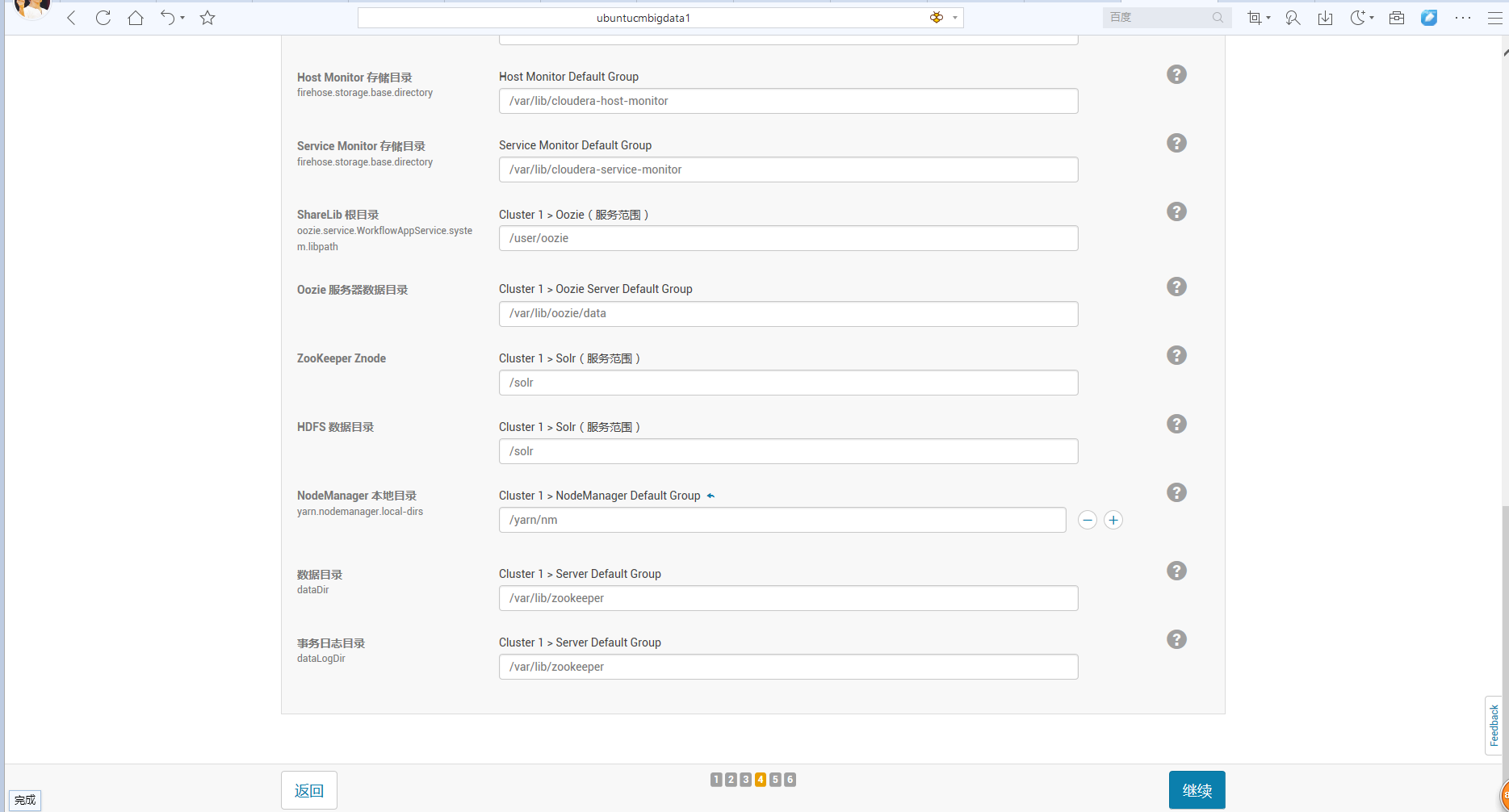
说白了,这里是启动的总界面,但是呢,我们若这里没启动成功,没关系,可以在后面,单独来启动!(具体如下的详细步骤)
http://ubuntucmbigdata1:7180/cmf/clusters/2/express-add-services/index#step=commandDetailsStep
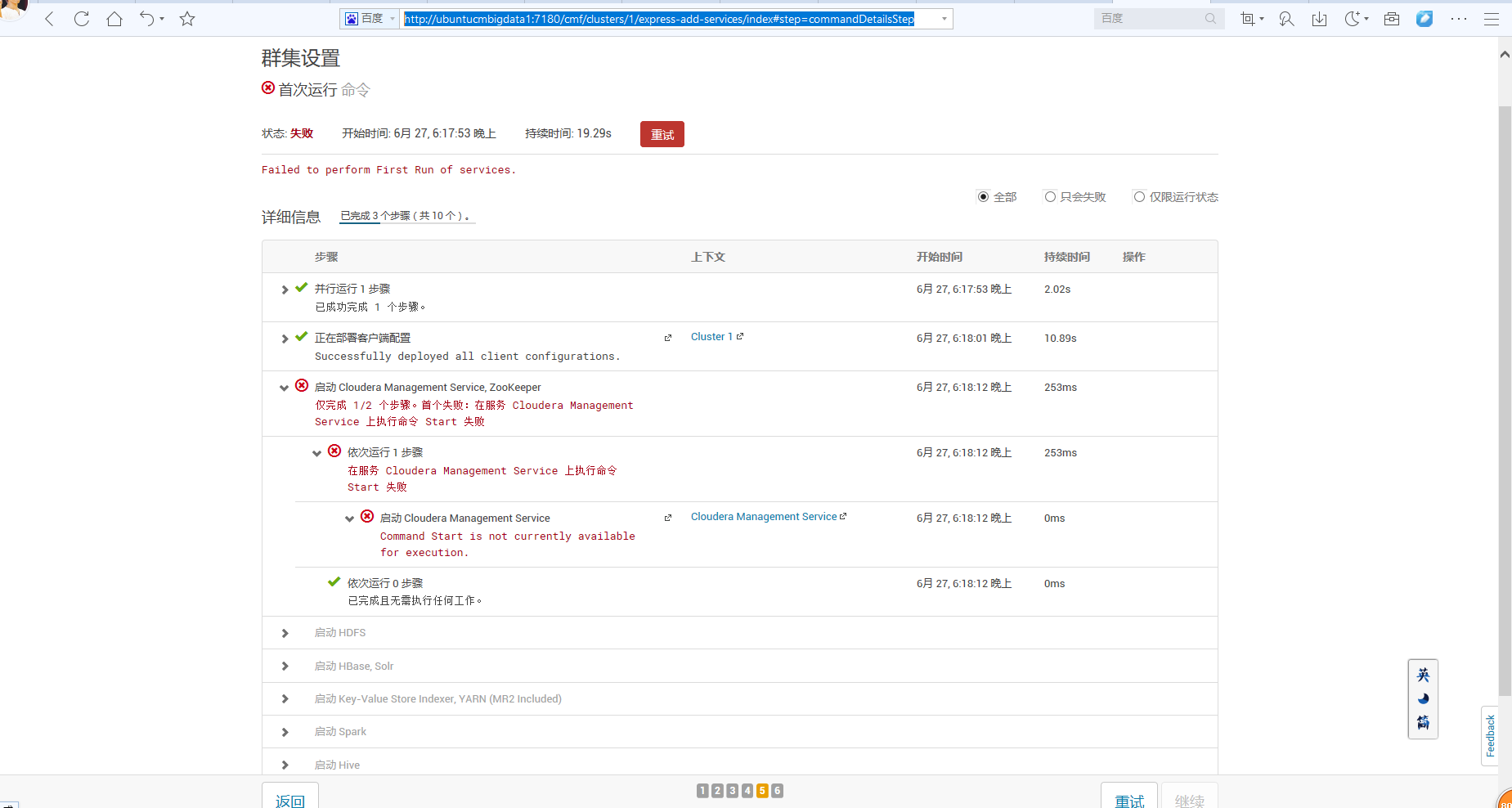
参考
Ubuntu Server 14.04 安装部署 CDH5.7.2
https://www.zybuluo.com/ncepuwanghui/note/474966
Ubuntu14.04用apt在线/离线安装CDH5.1.2[Apache Hadoop 2.3.0]
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
以及对应本平台的QQ群:161156071(大数据躺过的坑)


Cloudera Manager安装之利用parcels方式(在线或离线)安装3或4节点集群(包含最新稳定版本或指定版本的安装)(添加服务)(Ubuntu14.04)(五)的更多相关文章
- Cloudera Manager安装之利用parcels方式安装3或4节点集群(包含最新稳定版本或指定版本的安装)(添加服务)(CentOS6.5)(五)
参考博客 Cloudera Manager安装之利用parcels方式安装单节点集群 Cloudera Manager安装之Cloudera Manager 5.3.X安装(三)(tar方式.rpm ...
- Cloudera Manager安装之利用parcels方式安装单节点集群(包含最新稳定版本或指定版本的安装)(添加服务)(CentOS6.5)(四)
不多说,直接上干货! 福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 ...
- Cloudera Manager安装之利用parcels方式(在线或离线)安装单节点集群(包含最新稳定版本或指定版本的安装)(添加服务)(Ubuntu14.04)(四)
.. 欢迎大家,加入我的微信公众号:大数据躺过的坑 免费给分享 同时,大家可以关注我的个人博客: http://www.cnblogs.com/zlslch/ 和 http ...
- 一步步教你Hadoop多节点集群安装配置
1.集群部署介绍 1.1 Hadoop简介 Hadoop是Apache软件基金会旗下的一个开源分布式计算平台.以Hadoop分布式文件系统HDFS(Hadoop Distributed Filesys ...
- Hadoop多节点集群安装配置
目录: 1.集群部署介绍 1.1 Hadoop简介 1.2 环境说明 1.3 环境配置 1.4 所需软件 2.SSH无密码验证配置 2.1 SSH基本原理和用法 2.2 配置Master无密码登录所有 ...
- 『GreenPlum系列』GreenPlum 4节点集群安装(图文教程)
目标架构如上图 一.硬件评估 cpu主频,核数推荐CPU核数与磁盘数的比例在12:12以上Instance上执行时只能利用一个CPU核资源进行计算,推荐高主频 内存容量 网络带宽重分布操作 R ...
- kafka_2.10-0.8.1.1.tgz的1或3节点集群的下载、安装和配置(图文详细教程)绝对干货
运行kafka ,需要依赖 zookeeper,你可以使用已有的 zookeeper 集群或者利用 kafka自带的zookeeper. 单机模式,用的是kafka自带的zookeeper, 分布式模 ...
- kafka_2.11-0.8.2.2.tgz的3节点集群的下载、安装和配置(图文详解)
kafka_2.10-0.8.1.1.tgz的1或3节点集群的下载.安装和配置(图文详细教程)绝对干货 一.安装前准备 1.1 示例机器 二. JDK7 安装 1.1 下载地址 下载地址: http: ...
- Dubbo入门到精通学习笔记(十四):ActiveMQ集群的安装、配置、高可用测试,ActiveMQ高可用+负载均衡集群的安装、配置、高可用测试
文章目录 ActiveMQ 高可用集群安装.配置.高可用测试( ZooKeeper + LevelDB) ActiveMQ高可用+负载均衡集群的安装.配置.高可用测试 准备 正式开始 ActiveMQ ...
随机推荐
- [leetcode] 13. Remove Duplicates from Sorted List
这个题目其实不难的,主要是我C++的水平太差了,链表那里绊了好久,但是又不像用python,所以还是强行上了. 题目如下: Given a sorted linked list, delete all ...
- yum初识
yum仓库中的元数据文件: primary.xml.gz 所有RPM包的列表: 依赖关系: 每个RPM安装生成的文件列表: filelists.xml.gz 当前仓库中所有RPM包的所有文件列表: o ...
- Android实现表单提交,webapi接收
1.服务端采用的是.net的WEBAPI接口. 2.android多文件上传. 以下为核心代码: package com.example.my.androidupload; import androi ...
- .Net Core使用HttpClient请求Web API注意事项
HttpClient 使用HttpClient可以很方便的请求Web API,但在使用时有一些需要注意的地方,不然会给你的程序带来毁灭性的问题. HttpClient是一个继承了IDisposable ...
- ASP.NET基于NPOI导出数据
using System; using System.Collections; using System.Collections.Generic; using System.IO; using Sys ...
- ASP.NET WebApi总结之自定义权限验证
在.NET中有两个AuthorizeAttribute类, 一个定义在System.Web.Http命名空间下 #region 程序集 System.Web.Http, Version=5.2.3.0 ...
- DS作业01--日期抽象数据类型设计与实现
第六次作业 1.思维导图及学习体会 1.1 思维导图 1.2 学习体会 因为假期里面代码的练习量很小,所以开学来上学期的知识遗忘了很多,刚刚开始写大作业的时候很困难,完全没有思路,后来看了几位同学的代 ...
- django系列5.3--ORM数据库的多表操作
首先来创建一个模型,数据库的关系就清楚了 models.py from django.db import models # Create your models here. class Author( ...
- 和我一起学python
近来python越来越火,很多人都出了教程,我也来出一个凑凑热闹吧. pycharm激活 http://idea.lanyus.com/ https://blog.csdn.net/u01404481 ...
- ssh 使用密钥无法登入Linux系统
今天测试密钥登入linux系统时 出现如下问题: root@compute01:~# ssh alicxxx@xxx.com -p -i alickicxxxxxxx.key @@@@@@@@@@@@ ...