第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用
第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用
xpath表达式
//x 表示向下查找n层指定标签,如://div 表示查找所有div标签
/x 表示向下查找一层指定的标签
/@x 表示查找指定属性的值,可以连缀如:@id @src
[@属性名称="属性值"]表示查找指定属性等于指定值的标签,可以连缀 ,如查找class名称等于指定名称的标签
/text() 获取标签文本类容
[x] 通过索引获取集合里的指定一个元素
1、将xpath表达式过滤出来的结果进行正则匹配,用正则取最终内容
最后.re('正则')
xpath('//div[@class="showlist"]/li//img')[0].re('alt="(\w+)')
2、在选择器规则里应用正则进行过滤
[re:正则规则]
xpath('//div[re:test(@class, "showlist")]').extract()
实战使用Scrapy获取一个电商网站的、商品标题、商品链接、和评论数

分析源码
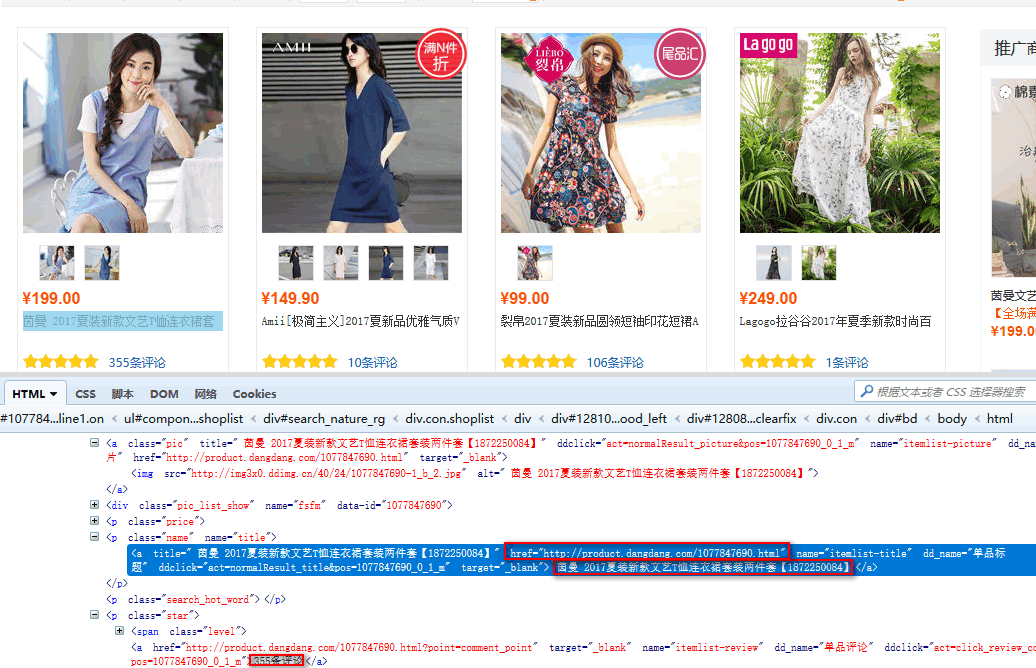
第一步、编写items.py容器文件
我们已经知道了我们要获取的是、商品标题、商品链接、和评论数
在items.py创建容器接收爬虫获取到的数据
设置爬虫获取到的信息容器类,必须继承scrapy.Item类
scrapy.Field()方法,定义变量用scrapy.Field()方法接收爬虫指定字段的信息
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy #items.py,文件是专门用于,接收爬虫获取到的数据信息的,就相当于是容器文件 class AdcItem(scrapy.Item): #设置爬虫获取到的信息容器类
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() #接收爬虫获取到的title信息
link = scrapy.Field() #接收爬虫获取到的连接信息
comment = scrapy.Field() #接收爬虫获取到的商品评论数
第二步、编写pach.py爬虫文件
定义爬虫类,必须继承scrapy.Spider
name设置爬虫名称
allowed_domains设置爬取域名
start_urls设置爬取网址
parse(response)爬虫回调函数,接收response,response里是获取到的html数据对象
xpath()过滤器,参数是xpath表达式
extract()获取html数据对象里的数据
yield item 接收了数据的容器对象,返回给pipelies.py
# -*- coding: utf-8 -*-
import scrapy
from adc.items import AdcItem #导入items.py里的AdcItem类,容器类 class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider
name = 'pach' #设置爬虫名称
allowed_domains = ['search.dangdang.com'] #爬取域名
start_urls = ['http://category.dangdang.com/pg1-cid4008149.html'] #爬取网址 def parse(self, response): #parse回调函数
item = AdcItem() #实例化容器对象
item['title'] = response.xpath('//p[@class="name"]/a/text()').extract() #表达式过滤获取到数据赋值给,容器类里的title变量
# print(rqi['title'])
item['link'] = response.xpath('//p[@class="name"]/a/@href').extract() #表达式过滤获取到数据赋值给,容器类里的link变量
# print(rqi['link'])
item['comment'] = response.xpath('//p[@class="star"]//a/text()').extract() #表达式过滤获取到数据赋值给,容器类里的comment变量
# print(rqi['comment'])
yield item #接收了数据的容器对象,返回给pipelies.py
robots协议
注意:如果获取的网站在robots.txt文件里设置了,禁止爬虫爬取协议,那么将无法爬取,因为scrapy默认是遵守这个robots这个国际协议的,如果想不遵守这个协议,需要在settings.py设置
到settings.py文件里找到ROBOTSTXT_OBEY变量,这个变量等于False不遵守robots协议,等于True遵守robots协议
# Obey robots.txt rules
ROBOTSTXT_OBEY = False #不遵循robots协议
第三步、编写pipelines.py数据处理文件
如果需要pipelines.py里的数据处理类能工作,需在settings.py设置文件里的ITEM_PIPELINES变量里注册数据处理类
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'adc.pipelines.AdcPipeline': 300, #注册adc.pipelines.AdcPipeline类,后面一个数字参数表示执行等级,数值越大越先执行
}
注册后pipelines.py里的数据处理类就能工作
定义数据处理类,必须继承object
process_item(item)为数据处理函数,接收一个item,item里就是爬虫最后yield item 来的数据对象
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html class AdcPipeline(object): #定义数据处理类,必须继承object
def process_item(self, item, spider): #process_item(item)为数据处理函数,接收一个item,item里就是爬虫最后yield item 来的数据对象
for i in range(0,len(item['title'])): #可以通过item['容器名称']来获取对应的数据列表
title = item['title'][i]
print(title)
link = item['link'][i]
print(link)
comment = item['comment'][i]
print(comment)
return item
最后执行
执行爬虫文件,scrapy crawl pach --nolog

可以看到我们需要的数据已经拿到了
第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用的更多相关文章
- 第三百三十七节,web爬虫讲解2—PhantomJS虚拟浏览器+selenium模块操作PhantomJS
第三百三十七节,web爬虫讲解2—PhantomJS虚拟浏览器+selenium模块操作PhantomJS PhantomJS虚拟浏览器 phantomjs 是一个基于js的webkit内核无头浏览器 ...
- 第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础 在urllib中,我们一样可以使用xpath表达式进行信息提取,此时,你需要首先安装lxml模块 ...
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码 打码接口文件 # -*- coding: cp936 -*- import sys import os ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- 第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录 模拟浏览器登录 start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于star ...
- 第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令 Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --u ...
- 第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解 封装模块 #!/usr/bin/env python # -*- coding: utf- ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术.设置用户代理 如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执 ...
随机推荐
- CCAction、CCFiniteTimeAction、CCSpeed、CCFollow
/**************************************************************************** Copyright (c) 2010-201 ...
- 采用Oracle的dbms_obfuscation_toolkit的加密
create or replace function MD5 (vpassword in varchar2) return varchar2 is retval varchar2(32); begin ...
- DIOCP3-关于TIOCPConsole和编码解码器
TIOCPConsole是继承至TIocpTcpServer,做了管理和调用编码和解码器器的功能.可以通过向他注册编码和解码器可以忽略粘包的问题. 这样如果TIOCPConsole客户端必须按照一 ...
- C#数组 添加元素
例1: string[] a = new string[] { "1", "2", "3" }; 给a追加一个 "4" ...
- 对Inductive Bias(归纳偏置)的理解
参考资料: https://en.wikipedia.org/wiki/Inductive_bias http://blog.sina.com.cn/s/blog_616684a90100emkd.h ...
- 使用 libvirt创建和管理KVM虚拟机
1. libvirt介绍 Libvirt是一个软件集合,便于使用者管理虚拟机和其他虚拟化功能,比如存储和网络接口管理等等.Libvirt概括起来包括一个API库.一个 daemon(libv ...
- linux下保护视力、定时强制锁定软件: Workrave
超负荷地工作会累坏身体的,而且效率也不高,所以工作一段时间就应该休息一下.长时间在电脑前一动不动,很容易患上“重复性劳损”,即 Repetitive Strain Injury (RSI).具体现象大 ...
- C#学习笔记(29)——Linq的实现,Lambda求偶数和水仙花数
说明(2017-11-22 18:15:48): 1. Lambda表达式里面用了匿名委托,感觉理解起来还是挺难的.求偶数的例子模拟了Linq查询里的一个where方法. 2. 蒋坤说求水仙花数那个例 ...
- 基于jQuery点击缩略图右侧滑出大图特效
基于jQuery点击缩略图右侧滑出大图特效是一款基于strip.pkgd插件实现的点击左侧缩略图右侧滑出大图切换代码.效果图如下: 在线预览 源码下载 实现的代码. html代码: <div ...
- 【Unity】使用AssetDatabase编辑器资源管理
最近参考了各位大神的资源,初步学习了Unity的资源管理模式,包括在编辑器管理(使用AssetDatabase)和在运行时管理(使用Resources和AssetBundle).在此简单总结编辑器模式 ...