python编码问题 decode与encode
参考:
http://www.jb51.net/article/17560.htm
如果要在python2的py文件里面写中文,则必须要添加一行声明文件编码的注释,否则python2会默认使用ASCII编码。
# -*- coding:utf-8 -*-
字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转换成unicode编码。
encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode('gb2312'),表示将unicode编码的字符串str2转换成gb2312编码。
因此,转码的时候一定要先搞明白,字符串str是什么编码,然后decode成unicode,然后再encode成其他编码
代码中字符串的默认编码与代码文件本身的编码一致。
如:s='中文'
如果是在utf8的文件中,该字符串就是utf8编码,如果是在gb2312的文件中,则其编码为gb2312。这种情况下,要进行编码转换,都需要先用decode方法将其转换成unicode编码,再使用encode方法将其转换成其他编码。通常,在没有指定特定的编码方式时,都是使用的系统默认编码创建的代码文件。
如果字符串是这样定义:s=u'中文'
则该字符串的编码就被指定为unicode了,即python的内部编码,而与代码文件本身的编码无关。因此,对于这种情况做编码转换,只需要直接使用encode方法将其转换成指定编码即可。
如果一个字符串已经是unicode了,再进行解码则将出错,因此通常要对其编码方式是否为unicode进行判断:
isinstance(s, unicode) #用来判断是否为unicode
用非unicode编码形式的str来encode会报错
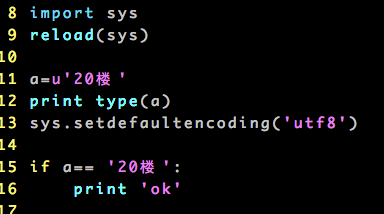
#coding=utf8a='20楼'
print type(a)
print sys.getdefaultencoding()
aa = a.decode('utf8')
if aa.find(u'楼'):
print 'ok'
else:
print 'no'
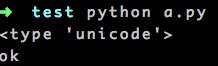
输出:
<type 'str'> ascii ok
参数ignore作用
比如,若要将某个String对象s从gbk内码转换为UTF-8,可以如下操作 s.decode('gbk').encode('utf-8′) 可是,在实际开发中,我发现,这种办法经常会出现异常: UnicodeDecodeError: ‘gbk' codec can't decode bytes in position 30664-30665: illegal multibyte sequence 这 是因为遇到了非法字符——尤其是在某些用C/C++编写的程序中,全角空格往往有多种不同的实现方式,比如\xa3\xa0,或者\xa4\x57,这些 字符,看起来都是全角空格,但它们并不是“合法”的全角空格(真正的全角空格是\xa1\xa1),因此在转码的过程中出现了异常。 这样的问题很让人头疼,因为只要字符串中出现了一个非法字符,整个字符串——有时候,就是整篇文章——就都无法转码。
解决办法: s.decode('gbk', ‘ignore').encode('utf-8′) 因为decode的函数原型是decode([encoding], [errors='strict']),可以用第二个参数控制错误处理的策略,默认的参数就是strict,代表遇到非法字符时抛出异常; 如果设置为ignore,则会忽略非法字符; 如果设置为replace,则会用?取代非法字符; 如果设置为xmlcharrefreplace,则使用XML的字符引用。
python文档
decode( [encoding[, errors]]) Decodes the string using the codec registered for encoding. encoding defaults to the default string encoding. errors may be given to set a different error handling scheme. The default is 'strict', meaning that encoding errors raise UnicodeError. Other possible values are 'ignore', 'replace' and any other name registered via codecs.register_error, see section 4.8.1.
python编码问题 decode与encode的更多相关文章
- Python—编码与解码(encode()和decode())
编码与解码 decode英文意思是解码,encode英文原意是编码. Python 里面的编码和解码也就是 unicode 和 str 这两种形式的相互转化.编码是 unicode -> str ...
- python之分析decode、encode、unicode编码转换
decode()方法使用注册编码的编解码器的字符串进行解码.它默认为默认的字符串编码.decode函数可以将一个普通字符串转换为unicode对象.decode是将普通字符串按照参数中的编码格式进行解 ...
- pyhton字符编码问题--decode和encode方法
1 decode和encode方法 字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成uni ...
- 【Python】关于decode和encode
#-*-coding:utf-8 import sys ''' *首先要搞清楚,字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码, 即先将 ...
- Python 编码错误的本质原因
转载自:https://foofish.net/python-unicode-error.html 不论你是有着多年经验的 Python 老司机还是刚入门 Python 不久的新贵,你一定遇到过Uni ...
- python编码encode和decode
计算机里面,编码方法有很多种,英文的一般用ascii,而中文有unicode,utf-8,gbk,utf-16等等. unicode是 utf-8,gbk,utf-16这些的父编码,这些子编码都能转换 ...
- Python编码介绍——encode和decode
在 python 源代码文件中,如果你有用到非ASCII字符,则需要在文件头部进行字符编码的声明,声明如下: # code: UTF-8 因为python 只检查 #.coding 和编码字符串,所以 ...
- python编码encode decode(解惑)
关于python 字符串编码一直没有搞清楚,今天总结了一下. Python 字符串类型 Python有两种字符串类型:str 与 unicode. 字符串实例 # -*- coding: utf-8 ...
- Python中解码decode()与编码encode()与错误处理UnicodeDecodeError: 'gbk' codec can't decode byte 0xab
编码方法encoding() 描述 encode() 方法以指定的编码格式编码字符串,默认编码为 'utf-8'.将字符串由string类型变成bytes类型. 对应的解码方法:bytes decod ...
随机推荐
- English trip -- VC(情景课) 6 D
Read 阅读 Teresa‘s Day Treesa's is busy today. he meeting with her friend Joan is at 10:00. Her docto ...
- 20170728xlVBA改转置一例
Sub 导出() Dim Sht As Worksheet, ShtName As String Dim NextRow As Long, NextRow2 As Long Dim iRow As L ...
- Android开发中需要注意哪些坑
作为一个有两.三年Android应用开发经验的码农,自然会遇到很多坑,下面是我能够想起的一些坑(实践证明不记笔记可不是个好习惯),后面有想到其它坑会陆续补上. 1.在Android library中不 ...
- CentOS7 install apache
1. yum install httpd 2. config /etc/httpd/conf/httpd.conf <VirtualHost *:80> ServerName www.l ...
- 『OpenCV3』Harris角点特征_API调用及python手动实现
一.OpenCV接口调用示意 介绍了OpenCV3中提取图像角点特征的函数: # coding=utf- import cv2 import numpy as np '''Harris算法角点特征提取 ...
- bzoj2595: [Wc2008]游览计划 斯坦纳树
斯坦纳树是在一个图中选取某些特定点使其联通(可以选取额外的点),要求花费最小,最小生成树是斯坦纳树的一种特殊情况 我们用dp[i][j]来表示以i为根,和j状态是否和i联通,那么有 转移方程: dp[ ...
- java plsql 调用oracle数组类型
首先当然是在oracle中建立type CREATE OR REPLACE TYPE cux_proxy_bid_award_rec IS OBJECT ( trading_partner_id NU ...
- IOS-整体框架类图
Cocoa框架是iOS应用程序的基础,了解Cocoa框架,对开发iOS应用有很大的帮助. 1.Cocoa是什么? Cocoa是OS X和 iOS操作系统的程序的运行环境. 是什么因素使一个程序成为Co ...
- string logo online customization
url: http://www.asciiarts.net/ example : hello
- mobilebone.js-mobile移动web APP单页切换骨架
昨天看到张鑫旭前辈发了一条微博,便互动了下,是他的一个开源移动端框架,没事看看,这是效果