Hadoop2.0的基本构成总览
Hadoop1.x和Hadoop2.0构成图对比
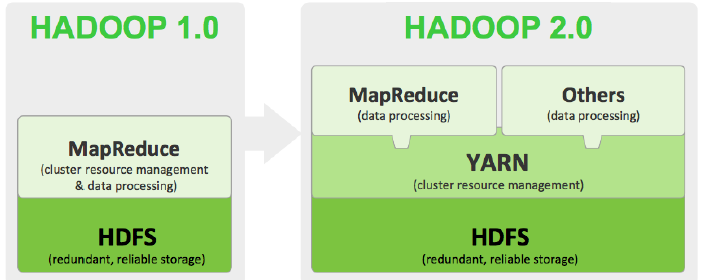
Hadoop1.x构成: HDFS、MapReduce(资源管理和任务调度);运行时环境为JobTracker和TaskTracker;
Hadoop2.0构成:HDFS、MapReduce/其他计算框架、YARN; 运行时环境为YARN
1、HDFS:HA、NameNode Federation
2、MapReduce/其他计算框架:运行在YARN之上的MapReduce通常称之为MapReduce2.0(MRv2)
3、YARN:资源管理系统(Yet Another Resource Negotiator),在其之上可以运行各种计算框架,如:MapReduce、Storm、Spark等;
HDFS2.0
解决HDFS1.0中单点故障和内存受限问题
解决单点故障: HDFS HA(High Available)
通过主备NameNode,当主NameNode发生故障时则切换到备NameNode;
解决内存受限问题: HDFS Federation
水平扩展,支持多个NameNode;
每个NameNode分管一部分目录;不同的NameNode可以分管不同的应用;
所有NameNode共享所有DataNode存储的资源;
HDFS2.0和HDFS1.0相比、仅是架构上发生了变化,使用方式不变,对HDFS使用者来说是透明的。比如说hdfs shell命令:
hadoop fs -ls /luogankun
hadoop fs -mkdir /luogankun/data
在HDFS1.0和HDFS2.0中用法是一致的。
YARN
Hadoop2.0新引入的资源管理系统
YARN核心思想:将MRv1中JobTracker的资源管理和任务调度分开,分别由ResourceManager和ApplicationMaster进程实现;
ResourceManager:负责整个集群的资源管理;整个集群只有一个;
ApplicationMaster:负责应用程序相关的事务,比如:任务调度、任务监控和任务容错;一个应用程序对应一个ApplicationMaster;
YARN引入的好处:使得多个计算框架可以运行在一个集群中,比如:MapReduce、Spark、Storm等;
MapReduce On YARN
运行在YARN之上的MapReduce称为MRv2;
将MapReduce作业直接运行在YARN上,而不是运行在由JobTracker和TaskTracker构建的MRv1之上;在Hadoop2.0中并不存在JobTracker和TaskTracker;
MRv2的模块基本功能:
1、YARN:负责资源管理和调度;
2、MRAppMaster:负责一个应用程序/作业的任务切分、任务调度、任务监控和容错;
3、Map/Reduce Task:任务驱动引擎,与MRv1一致;
每个应用程序/作业对应一个MRAppMaster,所以:
1、单个应用程序/作业运行失败,不会影响其他应用程序/作业;
2、负责应用程序/作业相关的事务,包括将从YARN分配得到的资源二次分配给内部的任务、任务切分、任务健康和容错等;

Hadoop2.0的基本构成总览的更多相关文章
- hadoop入门(3)——hadoop2.0理论基础:安装部署方法
一.hadoop2.0安装部署流程 1.自动安装部署:Ambari.Minos(小米).Cloudera Manager(收费) 2.使用RPM包安装部署:Apache ...
- Hadoop2.0(HDFS2)以及YARN设计的亮点
YARN总体上仍然是Master/Slave结构,在整个资源管理框架中,ResourceManager为Master,NodeManager为Slave,ResouceManager负责对各个Node ...
- 实战:ADFS3.0单点登录系列-总览
本系列将以一个实际项目为背景,介绍如何使用ADFS3.0实现SSO.其中包括SharePoint,MVC,Exchange等应用程序的SSO集成. 整个系列将会由如下几个部分构成: 实战:ADFS3. ...
- hadoop2.0 和1.0的区别
1. Hadoop 1.0中的资源管理方案Hadoop 1.0指的是版本为Apache Hadoop 0.20.x.1.x或者CDH3系列的Hadoop,内核主要由HDFS和MapReduce两个系统 ...
- Hadoop2.0重启脚本
Hadoop2.0重启脚本 方便重启带ha的集群,写了这个脚本 #/bin/bash sh /opt/zookeeper-3.4.5-cdh4.4.0/bin/zkServer.sh restart ...
- ganglia监控hadoop2.0配置方法
ganglia监控hadoop2.0配置方法前提:hadoop2.0集群已安装ganglia监控工具第一步:Hadoop用户登录集群每一个节点,修改文件:vi /opt/hadoop-2.0.0-cd ...
- hadoop-2.0.0-mr1-cdh4.2.0源码编译总结
准备编译hadoop-2.0.0-mr1-cdh4.2.0的同学们要谨慎了.首先看一下这篇文章: Hadoop作业提交多种方案 http://www.blogjava.net/dragonHadoop ...
- hadoop-2.0.0-cdh4.2.1源码编译总结
经过一个星期多的努力,这两个包的编译工作总算告一段落. 首先看一下这一篇文章: 在eclipse下编译hadoop2.0源码 http://www.cnblogs.com/meibenjin/arch ...
- hadoop2.0 eclipse 源码编译
在eclipse下编译hadoop2.0源码 http://www.cnblogs.com/meibenjin/archive/2013/07/05/3172889.html hadoop cdh4编 ...
随机推荐
- dir matlab
%file=dir('D:\dataset\temp');file=dir('D:\dataset\INRIAPerson\test_64x128_H96\pos');for i=3:length(f ...
- JS禁止用F5键
//禁止用F5键 function document.onkeydown() { if ( event.keyCode==116) { event.keyCode = 0; event.cancelB ...
- 【c++基础】多个txt文件合并到一个文件的几种方式
参考 1.windows命令: 2.linux-command; 完
- OpenCV Error: Insufficient memory问题解析
前言 项目程序运行两个月之久之后突然挂了,出现OpenCV Error: Insufficient memory的错误,在此分析一下该问题. 问题的表现形式: 程序内存使用情况: 问题: OpenCV ...
- DoTween用法教程
DoTween用法攻略 本文提供全流程,中文翻译. Chinar 坚持将简单的生活方式,带给世人!(拥有更好的阅读体验 -- 高分辨率用户请根据需求调整网页缩放比例) Chinar -- 心分享.心创 ...
- IO练习--按字节截取字符串
* 在Java中字符串“abcd”和字符串“ab你好”都是4个字符, * 但是字节数不同,因为GBK中一个汉字占两个字节 * 定义一个方法用来按字节数截取字符串. * 如:对于“ab你好”,取3个字节 ...
- Struts2重新学习1
一:框架 1:框架的意义在于可以大大提高我们的开发效率.框架时一种主动设计,使用框架必须遵守框架指定好的开发流程. 2:框架的强大之处不是源自它能让你做什么,而是它不能让你做什么.有规有矩,方可成方圆 ...
- 2、let 和 const 命令
let 命令 块级作用域 const 命令 顶层对象的属性 global 对象 let 命令 基本用法 ES6 新增了let命令,用来声明变量.它的用法类似于var,但是所声明的变量,只在let命令所 ...
- restheart 基本使用
restheart 是一个方便基于mongodb的restapi 开发框架 参考项目 https://github.com/rongfengliang/restheart-docker-compose ...
- 用cmd加密文件夹
随着电脑的广泛应用,个人电脑的私人空间越来越大,很多人喜欢把个人的一些私隐的文件存放在电脑上,私隐文件当然是不想别人看到的,为了防止别人看不见自己的文件,可以有很多的方法,今天在网上看了一些文档,学会 ...