Spark机器配置计算
● Based on the recommendations mentioned above, Let's assign 5 core per executors => --executor-cores = 5 (for good HDFS throughput)
● Leave 1 core per node for Hadoop/Yarn daemons => Num cores available per node = 16-1 = 15
● So, Total available of cores in cluster = 15 x 10 = 150
● Number of available executors = (total cores/num-cores-per-executor) = 150/5 = 30
● Leaving 1 executor for ApplicationManager => --num-executors = 29
● Number of executors per node = 30/10 = 3
● Memory per executor = 64GB/3 = 21GB
● Counting off heap overhead = 7% of 21GB = 3GB. So, actual --executor-memory = 21 - 3 = 18GB
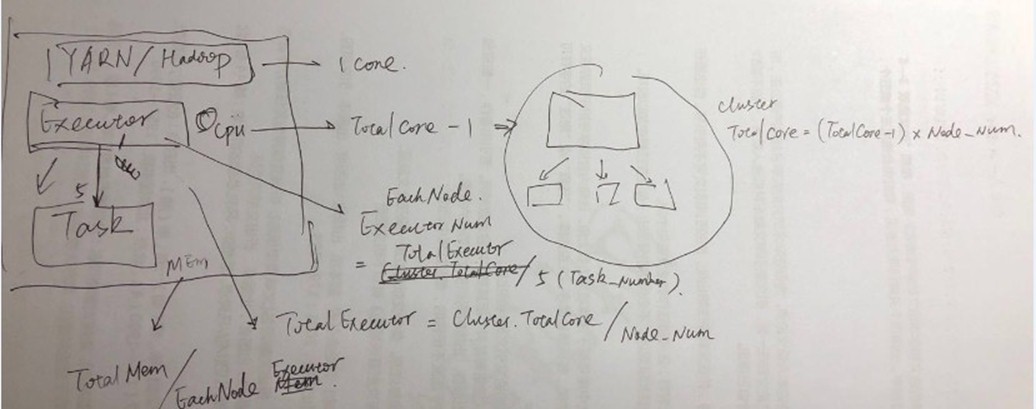
基本思路就是要明确经验值,一个executor跑5个task,因为spark需要和hdfs client交互实现对于hdfs的读写;所以多个客户端可以实现并行,效果比较好;
然后就是首先计算core的数量,
接着计算executor数量,包括总数量以及单节点数量;首先求出总数量,然后是单个节点的数量;注意这里需要把AM的executor数量考虑进去(一个)
最后是计算内存;内存都是计算单机内存;但是内存不可能都分配给JVM;
Spark机器配置计算的更多相关文章
- spark streaming 实时计算
spark streaming 开发实例 本文将分以下几部分 spark 开发环境配置 如何创建spark项目 编写streaming代码示例 如何调试 环境配置: spark 原生语言是scala, ...
- ubuntu下spark安装配置
一.安装vmware虚拟机 二.在虚拟机上安装ubuntu12.04操作系统 三.安装jdk1.8.0_25 http://www.oracle.com/technetwork/java/javase ...
- Spark Configuration配置
Spark可以通过三种方式配置系统: 通过SparkConf对象, 或者Java系统属性配置Spark的应用参数 通过每个节点上的conf/spark-env.sh脚本为每台机器配置环境变量 通过lo ...
- 贯通Spark Streaming流计算框架的运行源码
本章节内容: 一.在线动态计算分类最热门商品案例回顾 二.基于案例贯通Spark Streaming的运行源码 先看代码(源码场景:用户.用户的商品.商品的点击量排名,按商品.其点击量排名前三): p ...
- Spark 属性配置
1.Spark1.x 属性配置方式 Spark属性提供了大部分应用程序的控制项,并且可以单独为每个应用程序进行配置. 在Spark1.0.0提供了3种方式的属性配置: SparkConf方式 Spar ...
- 基于案例贯通 Spark Streaming 流计算框架的运行源码
本期内容 : Spark Streaming+Spark SQL案例展示 基于案例贯穿Spark Streaming的运行源码 一. 案例代码阐述 : 在线动态计算电商中不同类别中最热门的商品排名,例 ...
- 大数据开发实战:Spark Streaming流计算开发
1.背景介绍 Storm以及离线数据平台的MapReduce和Hive构成了Hadoop生态对实时和离线数据处理的一套完整处理解决方案.除了此套解决方案之外,还有一种非常流行的而且完整的离线和 实时数 ...
- 【转】Spark Streaming 实时计算在甜橙金融监控系统中的应用及优化
系统架构介绍 整个实时监控系统的架构是先由 Flume 收集服务器产生的日志 Log 和前端埋点数据, 然后实时把这些信息发送到 Kafka 分布式发布订阅消息系统,接着由 Spark Streami ...
- JVM调优 jdk版本 机器配置 建议jvm参数 备注
https://juejin.im/post/5b091ee35188253892389683 大型跨境电商JVM调优经历 前提:某大型跨境电商业务发展非常快,线上机器扩容也很频繁,但是对于线上机器的 ...
随机推荐
- bootstrap modal关闭滚动条自动会跳回最顶端问题记录
原因:使用了a标签当按钮触发modal关闭的时候就会自动跳回浏览器最顶端 解决方案: 不要使用a标签就行了
- iOS UI-文本视图(UITextView)
#import "ViewController.h" @interface ViewController ()<UITextViewDelegate> @propert ...
- json格式化
jar包:gson-xxx.jar import com.google.gson.Gson; import com.google.gson.GsonBuilder; import com.goog ...
- Tarjan 算法求强联通分量
转载自:http://blog.csdn.net/xinghongduo/article/details/6195337 还是没懂Tarjan算法的原理.但是感觉.讲的很有道理. 说到以Tarjan命 ...
- HDU 1940
//比赛的时候卡了三个点.今天卡了两个点.真心不愿意再看了. // 自己按照直线相交的思路的敲得.题意里说了不是按照final rank 给的.但是.这样就和标程输出不同. //就是觉得AC突然就不那 ...
- cas AuthenticationFilter
AuthenticationFilter *** 这个类的作用:判断是否已经登录,如果没有登录则根据配置的信息来决定将跳转到什么地方 *** casServerLoginUrl:定义cas 服务器的登 ...
- cocos2d-x安装教程
cocos2d-x安装教程 cocos的安装方法有多种,今天讲的是其中一种,使用cocos的源代码直接进行编译. 下载cocos2d-x的源代码,提供两种方式给大家 -- 中文官网下载 -- 英文官网 ...
- bzoj1084&&洛谷2331[SCOI2005]最大子矩阵
题解: 分类讨论 当m=1的时候,很简单的dp,这里就不再复述了 当m=2的时候,设dp[i][j][k]表示有k个子矩阵,第一列有i个,第二列有j个 然后枚举一下当前子矩阵,状态转移 代码: #in ...
- noip2005循环
题解: 迭代,一次次k累加计算 代码: #include<bits/stdc++.h> using namespace std; ; ][N],ans[N]; char s[N]; boo ...
- DevExpress v17.2—WinForms篇(六)
用户界面套包DevExpress v17.2终于正式发布,本站将以连载的形式为大家介绍各版本新增内容.开篇介绍了DevExpress WinForms v17.2 Data Grid Control ...