Digester库使用总结
1、Digester是Apache软件基金会的Jakarta项目下的子Commons项目下的一个开源项目,Digester API包含3个包:org.apache.commons.digester,提供了基于规则的、可处理任意XML文档的类,org.apache.commons.digester.rss包含了一些可以用来解析与很多新闻源使用的RSS格式兼容的XML文档的例子,org.apache.commons.digester.xmlrules为Digester库提供了一些规则基于XML的定义;
2、比如在tomcat中要实例话一个Context对象,可以用下面的代码:
Context ctx = new StandardContext();
ctx.setPath("/myApp");
ctx.setDocBase("/myApp");
但是如果所有的tomcat组件都这样硬编码,调整组件配置或属性值都必须要重新编译,采用digester库解析XML配置文件,xml文件中的每个元素都会转换为一个java对象,元素的属性用于设置java对象的属性,这样就可以通过编辑xml文件来修改tomcat配置而不用去重新编译项目代码;比如上面的代码可以转换为下面的配置:
<context docBase="/myApp" path="/myApp" />
基本用法:
1、digester库解析XML时定义了pattern和Rule,XML文档的根元素的pattern为元素名称,子元素的pattern为父元素的pattern + “/” + 子元素的名称;一条Rule(规则)指定了当Digester遇到这个pattern时要执行的一个或多个动作,Rule都存储在由Rules接口表示的一类存储器中;另外Digester解析XML文档时,遇到pattern匹配的开始标签时,他会调用Rule对象的begin方法,而当遇到pattern的结束标签时,他会调用Rule对象的end方法;
如下面的XML文档:

Employee节点的pattern为“employee”,office节点的pattern为“employee/office”,address节点的pattern为“employee/office/address”;
2、创建对象:
若想要Digester在遇到某个pattern时创建对象,则需要调用addObjectCreate()方法,如:
digester.addObjectCreate("employee",cn.com.digesterTest.Employee.class);
或者digester.addObjectCreate("employee", "cn.com.digesterTest.Employee");
或者digester.addObjectCreate("employee", "cn.com.digesterTest.Employee", "className");
其定义原型为:

3、设置属性:
addSetProperties可以使Digester对象为创建的对象设置属性,会将XML文档中的属性名称与对象中的对应属性对应起来,分别调用其对应的set方法设置属性值,如果对象中没有XML文档中定义的属性名称则会发生错误,addSetProperties定义原型如下:

使用示例如下:
digester.addSetProperties("employee");
这个Rule会将xml文档的employee节点的属性值都设置到内部栈最顶端对象的对应属性值里面去;
4、调用方法:
Digester类的addCallMethod方法能添加一条Rule,使得Digester在遇到与该Rule相关联的模式时调用内部栈最顶端对象的某个方法,定义原型如下:

5、创建对象之间的关系:
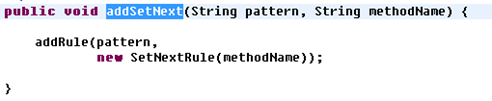
Digester每根据XML元素创建一个对象都会压入一个内部栈中,如果想将后面一个对象作为参数传入第一个对象的某个方法时,可以调用addSetNext方法来指定这个对象之间的关系,定义原型如下:

Pattern参数是后面一个对象的pattern路径,应该具有下面的格式:
firstObject/secondObject
methodName参数是前面一个对象要调用的方法名称;
digester.addObjectCreate("employee","cn.com.digesterTest.Employee");
digester.addObjectCreate("employee/office","cn.com.digesterTest.Office");
digester.addSetNext("employee/office", "addOffice");
其中addOffice定义于Employee类中,该方法接收一个Office对象作为参数;
6、验证XML文档:
Digester对象的validating属性指明了是否要对XML文档进行有效性验证,默认值为false,可以通过setValidating来设置是否要对xml文档进行有效性验证:

7、使用RuleSet:
Rule对象集合是RuleSet接口的实例,在创建了Digester对象后,可以创建一个RuleSet对象,并调用addRuleSet方法将其添加到Digester对象中。该接口定义了两个方法:
public String getNamespaceURI();
public void addRuleInstances(Digester digester);
getNamespaceURI方法返回将要应用在RuleSet中所有Rule对象的命名空间的URI,addRuleInstances方法将在当前RuleSet中的Rule对象的集合作为该方法的参数添加到digester实例中。
RuleSetBase类是实现RuleSet接口的一个抽象类,提供了getNamespaceURI的默认实现,自定义的RuleSet只需要从RuleSetBase派生过来并实现addRuleInstances方法即可。
比如实现自定义的RuleSet如下:

然后可以调用Digester.addRuleSet(new EmployeeRuleSet())来指定Rule集合;
8、Tomcat中Catalina.java中对Digester的一个用法:
- 首先在创建Digester对象时将Catalina对象压入堆栈:

- 然后在解析顶层元素时,将顶层元素创建的对象与Catalina对象关联:

第一条规则表明在遇到server元素时要创建Standardserver类的实例并压入内部堆栈,第二条规则指明要对Server对象的指定属性名设置同名的属性值;第三条规则将Server对象与内部栈中的栈底元素相关联,刚才看到已经Catalina对象压入栈底,因此第三条规则会将Server对象通过调用Catalina.setServer方法设置为Catalina对象的Server属性;
UML图:
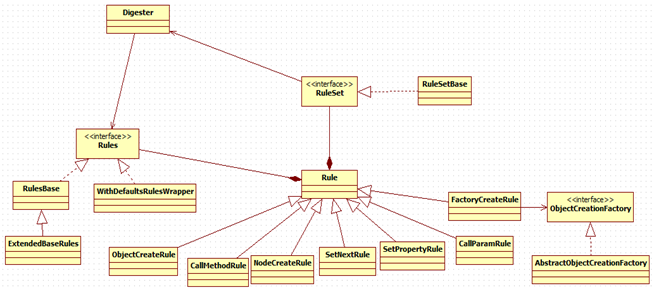
1、Digester的实现基于了SAX,SAX是一个比较有名的xml解析器,但是SAX提供的功能比较底层,我们在平时写代码如果xml配置文件写错了,经常会抛SAXParseException,SAX是基于事件驱动的,当读到一个xml配置文件的起始标签或者结束标签的时候就会触发一个事件,然后调用一个 Handler回调函数。Digester就是扩展了这一点。Digester继承了SAX的DefaultHandler类,重写了这个Handler的一些回调方法。

Digester的通用性就是靠用户在解析自定义xml文件时指定自定义rule来完成的。这个rule就是当SAX解析到一些标签的时候触发Digester 的handler函数所用到的一些处理规则,在handler函数里会去扫描到相应的规则来完成对象的构建工作。
2、Rule类作为所有规则的抽象基类,不同的规则类从Rule类派生过来,如果要实现自定义规则,也需要从Rule类派生过来;上面讲的addObjectCreate、addCallMethod、addSetNext等方法均是先创建Rule实例并添加到Rules中,如下:


Rule类有两个重要方法,begin和end,在解析到XML文档的pattern标签开始处时,调用begin方法,解析到pattern标签的结束处时,调用end方法,ObjectCreateRule类的begin和end方法代码如下:

begin方法根据默认的类名和指定要读取XML属性的类名获取最终的类名realClassName,根据类名生成实例对象并压入内部栈中;

end方法时只是将实例对象从内部栈中弹出,表示XML已经解析到标签的结束处,此时该对象不再使用了,可以从内部栈中弹出;
3、Rules接口表示Rule的集合,当在Digester中调用addRule时,其实是将Rule对象添加到Rules集合中了:


可以看出Rules对象是Digester类的一个成员变量,并且是在第一次访问时才创建的RulesBase实例;
4、为了代码简洁性,可以将添加规则Rule的代码集中到RuleSet对象中,然后将RuleSet对象通过addRuleSet方法添加到Digester的Rules集合中,实现自定义RuleSet时需要先从RuleSetBase类派生过来,然后重新实现他的addRuleInstances方法;
Digester库使用总结的更多相关文章
- How tomcat works 读书笔记十五 Digester库 下
在这一节里我们说说ContextConfig这个类. 这个类在很早的时候我们就已经使用了(之前那个叫SimpleContextConfig),但是在之前它干的事情都很简单,就是吧context里的co ...
- How tomcat works 读书笔记十五 Digester库 上
Digester库 在前面的几个章节里,我们对tomcat里各个组件的配置完全是使用写硬编码的形式完成的. 如 Context context = new StandardContext(); Loa ...
- Digester库
在之前所学习关于启动简单的Tomcat部分实现的代码中,我们使用一个启动类Bootstrap类 来实例化连接器.servlet容器.wrapper实例.和其他组件,然后调用各个对象的set方法将他们关 ...
- How Tomcat Works(十八)
在前面的文章中,如果我们要启动tomcat容器,我们需要使用Bootstrap类来实例化连接器.servlet容器.Wrapper实例和其他组件,然后调用各个对象的set方法将它们关联起来:这种配置应 ...
- Struts2技术内幕 读书笔记三 表示层的困惑
表示层能有什么疑惑?很简单,我们暂时忘记所有的框架,就写一个注册的servlet来看看. index.jsp <form id="form1" name="form ...
- tomcat源码阅读之集群
一. 配置: 在tomcat目录下的conf/Server.xml配置文件中增加如下配置: <!-- Cluster(集群,族) 节点,如果你要配置tomcat集群,则需要使用此节点. clas ...
- Tomcat 源码分析(转)
本文转自:http://blog.csdn.net/haitao111313/article/category/1179996 Tomcat源码分析(一)--服务启动 1. Tomcat主要有两个组件 ...
- 常用Java开源库(新手必看)
Jakarta common: Commons LoggingJakarta Commons Logging (JCL)提供的是一个日志(Log)接口(interface),同时兼顾轻量级和不依赖于具 ...
- Tomcat组件梳理—Digester的使用
Tomcat组件梳理-Digester的使用 再吐槽一下,本来以为可以不用再开一个篇章来梳理Digester了,但是发现在研究Service的创建时,还是对Digester的很多接口或者机制不熟悉,简 ...
随机推荐
- python-day34--并发编程之多线程
理论部分 一.什么是线程: 1.线程:一条流水线的工作过程 2.一个进程里至少有一个线程,这个线程叫主线程 进程里真正干活的就是线程 3.进程只是用来把资源集中到一起(进程只是一个资源单位,或者说资 ...
- html选择器
1.标签选择器:针对的是元素. <html><head><style type="text/css">p{font:"宋体" ...
- POJ-2096 Collecting Bugs (概率DP求期望)
题目大意:有n种bug,m个程序,小明每天能找到一个bug.每次bug出现的种类和所在程序都是等机会均等的,并且默认为bug的数目无限多.如果要使每种bug都至少找到一个并且每个程序中都至少找到一个b ...
- 12个有趣的 XSS Vector
XSS Vector #1 <script src=/〱20.rs></script> URL中第二个斜杠在Internet Explorer下(测试于IE11)可被U+303 ...
- Linux:SSH服务配置文件详解
SSH服务配置文件详解 SSH客户端配置文件 /etc/ssh/ssh——config 配置文件概要 Host * #选项“Host”只对能够匹配后面字串的计算机有效.“*”表示所有的计算机. For ...
- ubuntu16 intellij idea install lombok plugin
项目中用到lombok,idea会出现类似编译报错的红色,但并不影响运行.所以为了没有类似警告,就在idea上安装lombok插件.file-settings 安装完成之后,按照提示重启idea,问题 ...
- oo面向对象--规格化设计
oo面向对象--规格化设计 规格化设计与抽象 要了解规格化设计首先要了解抽象化的程序设计,两者是密不可分的. 抽象化(Abstraction) 抽象化是将数据与程序,用语义呈现他们的外观,但是隐藏起它 ...
- 【转】C# Socket通信编程
https://www.cnblogs.com/dotnet261010/p/6211900.html#undefined 一:什么是SOCKET socket的英文原义是“孔”或“插座”.作为进程通 ...
- Java快速排序和归并排序详解
快速排序 概述 快速排序算法借鉴的是二叉树前序遍历的思想,最终对数组进行排序. 优点: 对于数据量比较大的数组排序,由于采用的具有二叉树二分的思想,故排序速度比较快 局限 只适用于顺序存储结构的数据排 ...
- mac 搭建Vue开发环境
1: 使用的各个工具的版本为: Homebrew 1node.js npm webpack Vue 2: 安装brew 打开终端运行一下命令 /usr/bin/ruby -e "$(cur ...