RFS 理解

/*
* The rps_sock_flow_table contains mappings of flows to the last CPU
* on which they were processed by the application (set in recvmsg).
*/
struct rps_sock_flow_table {
unsigned int mask;
u16 ents[];
};
#define RPS_SOCK_FLOW_TABLE_SIZE(_num) (sizeof(struct rps_sock_flow_table) + \
((_num) * sizeof(u16)))
/*
* The rps_dev_flow structure contains the mapping of a flow to a CPU, the
* tail pointer for that CPU's input queue at the time of last enqueue, and
* a hardware filter index.
*/
struct rps_dev_flow {
u16 cpu; //此链路上次使用的cpu
u16 filter;
unsigned int last_qtail; //此设备队列入队的sk_buff的个数
};
#define RPS_NO_FILTER 0xffff /*
* The rps_dev_flow_table structure contains a table of flow mappings.
*/
struct rps_dev_flow_table {
unsigned int mask;
struct rcu_head rcu;
struct rps_dev_flow flows[]; //实现hash表
};
#define RPS_DEV_FLOW_TABLE_SIZE(_num) (sizeof(struct rps_dev_flow_table) + \
((_num) * sizeof(struct rps_dev_flow)))
int inet_recvmsg(struct kiocb *iocb, struct socket *sock, struct msghdr *msg,
size_t size, int flags)
{
struct sock *sk = sock->sk;
int addr_len = ;
int err; sock_rps_record_flow(sk); //设置CPU id err = sk->sk_prot->recvmsg(iocb, sk, msg, size, flags & MSG_DONTWAIT,
flags & ~MSG_DONTWAIT, &addr_len);
if (err >= )
msg->msg_namelen = addr_len;
return err;
}
EXPORT_SYMBOL(inet_recvmsg);
hash = skb_get_hash(skb);
if (!hash)
goto done; flow_table = rcu_dereference(rxqueue->rps_flow_table); //设备队列的hash表
sock_flow_table = rcu_dereference(rps_sock_flow_table); //全局的hash表
if (flow_table && sock_flow_table) {
u16 next_cpu;
struct rps_dev_flow *rflow; rflow = &flow_table->flows[hash & flow_table->mask];
tcpu = rflow->cpu; next_cpu = sock_flow_table->ents[hash & sock_flow_table->mask]; //得到用户程序运行的CPU id /*
3133 * If the desired CPU (where last recvmsg was done) is
3134 * different from current CPU (one in the rx-queue flow
3135 * table entry), switch if one of the following holds:
3136 * - Current CPU is unset (equal to RPS_NO_CPU).
3137 * - Current CPU is offline.
3138 * - The current CPU's queue tail has advanced beyond the
3139 * last packet that was enqueued using this table entry.
3140 * This guarantees that all previous packets for the flow
3141 * have been dequeued, thus preserving in order delivery.
3142 */
if (unlikely(tcpu != next_cpu) &&
(tcpu == RPS_NO_CPU || !cpu_online(tcpu) ||
((int)(per_cpu(softnet_data, tcpu).input_queue_head -
rflow->last_qtail)) >= )) {
tcpu = next_cpu;
rflow = set_rps_cpu(dev, skb, rflow, next_cpu);
} if (tcpu != RPS_NO_CPU && cpu_online(tcpu)) {
*rflowp = rflow;
cpu = tcpu;
goto done;
}
}
#ifdef CONFIG_RPS
/* Elements below can be accessed between CPUs for RPS */
struct call_single_data csd ____cacheline_aligned_in_smp;
struct softnet_data *rps_ipi_next;
unsigned int cpu;
unsigned int input_queue_head; //队列头,也可以理解为出队的位置
unsigned int input_queue_tail; //队列尾,也可以理解为入队的位置
#endif
RFS 理解的更多相关文章
- RFS一些基本概念
1. Project.Directory.TestSuit.TestCase.Resource的区别? Project:项目名称 Directory:对项目进行分层 TestSuit:测试 ...
- RFS的web自动化验收测试——第14讲 万能的evaluate
引言:什么是RFS——RobotFramework+Selenium2library,本系列主要介绍web自动化验收测试方面. ( @齐涛-道长 新浪微博) 这一讲我们重点来介绍一下一个常用的关键字e ...
- 为什么使能RPS/RFS, 或者RSS/网卡多队列后,QPS反而下降?
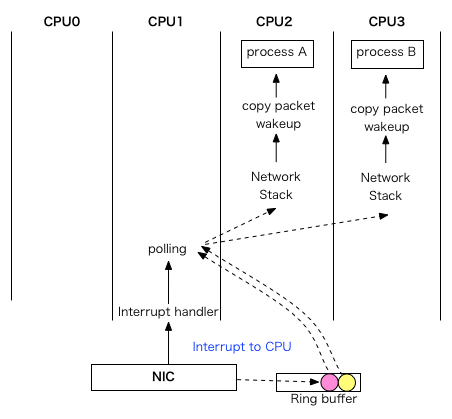
http://laoar.github.io/blog/2017/05/07/rps/ TL;DR RPS 即receive side steering,利用网卡的多队列特性,将每个核分别跟网卡的一个 ...
- Face alignment at 3000FPS via Regressing Local Binrary features 理解
这篇是Ren Shaoqing发表在cvpr2014上的paper,论文是在CPR框架下做的,想了解CPR的同学可以参见我之前的博客,网上有同学给出了code,该code部分实现了LBF,链接为htt ...
- 理解CSS视觉格式化
前面的话 CSS视觉格式化这个词可能比较陌生,但说起盒模型可能就恍然大悟了.实际上,盒模型只是CSS视觉格式化的一部分.视觉格式化分为块级和行内两种处理方式.理解视觉格式化,可以确定得到的效果是应 ...
- 彻底理解AC多模式匹配算法
(本文尤其适合遍览网上的讲解而仍百思不得姐的同学) 一.原理 AC自动机首先将模式组记录为Trie字典树的形式,以节点表示不同状态,边上标以字母表中的字符,表示状态的转移.根节点状态记为0状态,表示起 ...
- 理解加密算法(三)——创建CA机构,签发证书并开始TLS通信
接理解加密算法(一)--加密算法分类.理解加密算法(二)--TLS/SSL 1 不安全的TCP通信 普通的TCP通信数据是明文传输的,所以存在数据泄露和被篡改的风险,我们可以写一段测试代码试验一下. ...
- node.js学习(三)简单的node程序&&模块简单使用&&commonJS规范&&深入理解模块原理
一.一个简单的node程序 1.新建一个txt文件 2.修改后缀 修改之后会弹出这个,点击"是" 3.运行test.js 源文件 使用node.js运行之后的. 如果该路径下没有该 ...
- 如何一步一步用DDD设计一个电商网站(一)—— 先理解核心概念
一.前言 DDD(领域驱动设计)的一些介绍网上资料很多,这里就不继续描述了.自己使用领域驱动设计摸滚打爬也有2年多的时间,出于对知识的总结和分享,也是对自我理解的一个公开检验,介于博客园这个平 ...
随机推荐
- yum 和 apt-get
yum 和apt-get 一般来说著名的linux系统基本上分两大类: 1.RedHat系列:Redhat.Centos.Fedora等 2.Debian系列:Debian.Ubuntu等 RedHa ...
- 支持 XML 序列化的 Dictionary
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.X ...
- NOIP2011提高组
D1T1.铺地毯 for循环 #include<iostream> #include<cstdio> #include<algorithm> using names ...
- V++ MFC CEdit输出数组 UNICODE TO ASCII码
MFC怎么在静态编辑框中输出数组 //字符转ASCII码void CUTF8Dlg::OnBnClickedButtonCharAscii(){ // TODO: 在此添加控件通知处理程序代码 Upd ...
- 【leetcode】500. Keyboard Row
问题描述: Given a List of words, return the words that can be typed using letters of alphabet on only on ...
- python中函数和生成器的运行原理
#!/usr/bin/env python # -*- coding:utf-8 -*- # author:love_cat # python的函数是如何工作的 # 比方说我们定义了两个函数 def ...
- appium+python自动化24-滑动方法封装(swipe)【转载】
swipe介绍 1.查看源码语法,起点和终点四个坐标参数,duration是滑动屏幕持续的时间,时间越短速度越快.默认为None可不填,一般设置500-1000毫秒比较合适. swipe(self, ...
- array数据初始化
#include <iostream> int main() { ]={}; std::cout<<array[]<<]; } 试了试上面的代码发现,数组在用{}赋 ...
- J.U.C并发框架源码阅读(十五)CopyOnWriteArrayList
基于版本jdk1.7.0_80 java.util.concurrent.CopyOnWriteArrayList 代码如下 /* * Copyright (c) 2003, 2011, Oracle ...
- linux文件名匹配
* 匹配文件名中的任何字符串,包括空字符串. ? 匹配文件名中的任何单个字符. [...] 匹配[ ]中所包含的任何字符. [!...] 匹配[ ]中非感叹号!之后的字符. 如: s* ...