Python开发第二篇
运算符
1、算术运算符
% 取余运算符,返回余数
** 幂运算符
//返回商的整数部分
2、逻辑运算符
and 与运算符 a and b 如果a为False是,表达式为False,如果a为True返回b的布尔值
or 或运算符 a or b ,如果a为True时,表达式为True,如果a为False则返回b的布尔值
not 非运算符,返回当前布尔值的相反值,如果a为False则返回True
逻辑运算符 顺序 not > and >or 真是坑啊
'''
逻辑运算符
and 同真则真
or 同假则假
not 取反
'''
name = "sunqi"
age = 19 '''
1、判断name == "sunqi"——》True继续进行判断
2、判断age == 19 ——》True继续进行判断
3、判断name == "sunq"——》False然后接下来是or操作
4、判断age==18——》False前后都为False则返回布尔值False
'''
a = (name =="sunqi" and age ==19 and name == 'sunq' or age ==18)
print(a)
基本数据类型
一、字符串(str)
#定义:在单引号\双引号\三引号内,由一串字符组成
name='sunqi' #1、按索引取值(正向取+反向取) :只能取
#2、切片(顾头不顾尾,步长)
#3、长度len
#4、成员运算in和not in
#5、移除空白strip
#6、切分split
#7、循环
基本方法
#1、strip,lstrip,rstrip
#2、lower,upper
#3、startswith,endswith
#4、format的三种方法
#5、split,rsplit
#6、join
#7、replace
#8、isdigit
举个栗子
#strip
name='*sunqi**'
print(name.strip('*'))#“sunqi”
print(name.lstrip('*'))#“sunqi**”
print(name.rstrip('*'))#“*sunqi” #lower,upper
name='sunqi'
print(name.lower())#转换为小写
print(name.upper())#转换为大写 #startswith,endswith
name='sunqi_good'
print(name.endswith('good'))#以xxx结尾
print(name.startswith('sunqi'))#以xxx开头 #format的三种方法
res='{} {} {}'.format('sunqi',18,'male')
res='{0} {1} {2}'.format('sunqi',18,'male')
res='{name} {age} {sex}'.format(sex='male',name='sunqi',age=18) #split
name='root:x:0:0::/root:/bin/bash'
print(name.split(':')) #默认分隔符为空格
name='C:/a/b/c/d.txt' #只想拿到顶级目录
print(name.split('/',1)) name='a|b|c'
print(name.rsplit('|',1)) #从右开始切分,没有从左侧开始的方法 #join
tag=' '
print(tag.join(['sunqi','say','hello','world'])) #可迭代对象必须都是字符串 #replace
name='sunqi say :i have one computer,my name is sunqi'
print(name.replace('sunqi','tony',1)) #isdigit:可以判断bytes和unicode类型,是最常用的用于于判断字符是否为"数字"的方法
age=input('>>: ')
print(age.isdigit())#判断是否只包含十进制数字,有小数点也不行 #is数字系列
#在python3中
num1=b'' #bytes
num2=u'' #unicode,python3中无需加u就是unicode
num3='四' #中文数字
num4='Ⅳ' #罗马数字 #isdigt:bytes,unicode #判断是否只包含十进制数字,有小数点也不行
print(num1.isdigit()) #True
print(num2.isdigit()) #True
print(num3.isdigit()) #False
print(num4.isdigit()) #False #isdecimal:uncicode 判断是否只含有十进制字符
#bytes类型无isdecimal方法
print(num2.isdecimal()) #True
print(num3.isdecimal()) #False
print(num4.isdecimal()) #False #isnumberic:unicode,中文数字,罗马数字
#bytes类型无isnumberic方法
print(num2.isnumeric()) #True
print(num3.isnumeric()) #True
print(num4.isnumeric()) #True #三者不能判断浮点数
num5='4.3'
print(num5.isdigit()) #False
print(num5.isdecimal()) #False
print(num5.isnumeric()) #False #is其他 name='sunqi123'
print(name.isalnum()) #字符串由字母或数字组成
print(name.isalpha()) #字符串只由字母组成 print(name.isidentifier())#是否首字母是字母
print(name.islower())#是否是小写
print(name.isupper())#是否是大写
print(name.isspace())#是否只由空格组成。
print(name.istitle())#是否是标题,每个单词首字母都要大写
字符串作业:
1、实现整型加法计算器:例如:5+9,5 + 9, 5+9。
x = input(">>:")
v = x.split("+")
sum = 0
for i in v:
sum = int(i.strip()) + sum
print(sum)
2、计算用户输入的内容有多少个十进制数字,有多少个字母。
x = input(">>:")
d_count = 0
l_count = 0
for i in x:
if i.isdecimal():
d_count = d_count + 1
elif i.isalpha():
l_count = l_count + 1
else:
pass
print("十进制数字的个数为:",d_count)
print("字母的个数为:",l_count)
二、列表
列表是实例化list类创建的数据类型
li = list({11,22,33,44})
li_1 = [11,22,33,44]
print("li->",li)
print("li_1->",li_1)
列表元素的嵌套:字符串,数字,列表,还有接下来的元组,字典,……
li_1 = [11,"",[55,66,88,[99,10,"qeqwre"]]]
通过索引查找到列表的元素,也正因此列表是有序的
列表也可以通过元素查找索引值,如果元素不存在就会报错
li = [1,2,3,"sunqi","tony"]
# print(li.index("sun"))
try:
print(li.index("tony"))
print(li.index("suq"))
except Exception as e:
print("未找到") 4
未找到
li_1[0] = 11
li_1[1][1] = "2"
li_1[2][3][1] = 10
可以通过列表的索引对列表的元素进行修改
li_1 = [11,"",[55,66,88,[99,10,"qeqwre"]]]
li_1[2][3][1] = 1011 li_1-> [11, '', [55, 66, 88, [99, 1011, 'qeqwre']]]
列表支持索引切片替换
li_1 = [11,"",[55,66,88,[99,10,"qeqwre"]]]
li_1[0:2] = [99,20] print("li_1->",li_1) li_1-> [99, 20, [55, 66, 88, [99, 10, 'qeqwre']]]
支持切片删除(del)
li_1 = [11,"",[55,66,88,[99,10,"qeqwre"]]]
del li_1[0:2]
print(li_1) [[55, 66, 88, [99, 10, 'qeqwre']]]
列表反转
li_1[ : : -1]
支持成员运算符in,但是in 只能查询一层的而不能查询嵌套的。
做嵌套成员查询时需要指定索引
li_1 = [11,"",[55,66,88,[99,10,"qeqwre"]]]
print(11 in li_1)
print(55 in li_1)
print(55 in li_1[2]) True
False
True
如何将字符串转换成列表?
v= list("abcdefg")
被list转换的对象要求是可迭代的,最简单的理解就是支持for循环的
列表如何转换为字符串?
(1)如果列表为纯字符串列表,则可以使用字符串的 join 方法
"".join(list)
(2)如果列表既含有数字,又含有字符串,则需要手动编写for循环
列表常用方法:
li = [11,22,33,44]
li.append(“55”)追加到最后,返回值为none,直接将传入的参数作为一个整体加入列表
li.clear()清空列表
b = li.copy()浅拷贝只拷贝一层
li.count("")统计规定元素的个数
li.extend(iterable)扩展原来的列表,必须传递可迭代对象的参数li.extend([9898,"不得了"])
li.index("")获取当前值的索引
li.insert(位置,值)指定位置插入指定值
li.pop(0)删除指定的位置的值并返回删除的值,如果不指定位置则是最后一个并返回删除的值
li.remove("")删除指定的值,若有多个则删除第一个,也就是左边优先
li.reverse()反转列表
li.sort()排序:默认从小到大, reverse = True从大到小
三、元组
元组是实例化tuple类创建的数据类型
元组也可以嵌套任意数据类型
元组也是有序的
tu = (11,22,33,[44,55,"77"])
tu = (11,22,33,[44,55,""])
tu[0] = ""
print(tu) 修改元组的第一层元素会报错
TypeError: 'tuple' object does not support item assignment
元组与列表的最大区别是元组是不可修改的
这种不可修改性体现在元组的第一层元素是不可以被修改的。
可以修改第二层前提是第二层元素是可修改的。
四、字典
字典是通过实例化dict类创建的数据类型
字典的存储方式是键值对 的形式:key: value
字典的键可以是数字,字符串,布尔值,但是不允许是列表,和字典
字典的value可以是任意类型的值
dic = {
11:11,
"":"",
True :"adada",
"test":[11,22,33],
}
print(dic)
{11: 11, '': '', True: 'adada', 'test': [11, 22, 33]}
字典是无序的,没有索引值,不能通过索引值访问字典的元素
访问字典元素的方式:
1、for循环遍历字典
dic = {
11:11,
"":"",
True :"adada",
"test":[11,22,33],
}
for i in dic:
print(i)
11
22
True
test#默认循环字典的键
2、dic.keys()
循环输出字典的键
3、dic.values()
循环输出字典值
dic = {
11:11,
"":"",
True :"adada",
"test":[11,22,33],
}
for i in dic.values():
print(i)
4、dic.items()
遍历数值字典的键和值
dic = {
11:11,
"":"",
True :"adada",
"test":[11,22,33],
}
for k,v in dic.items():
print(k,v)
11 11
22 22
True adada
test [11, 22, 33]
5、dic.get("key")
取出指定key的值,如果key不存在,则返回默认值none
dic = {
11:11,
"":"",
True :"adada",
"test":[11,22,33],
}
v = dic.get("")
print(v)
b = dic.get("")
print(b)
22
None
6、删除字典的键值对
(1)pop()删除指定的key,并返回删除的key的value
v = dic.pop("test")
print(v)
[11,22,33]
(2)popitem删除最后一个元素,并返回删除的键和值组成的元组
v = dic.popitem()
print(v) ('test', [11, 22, 33])
(3)dic.setdefault(k,value=None)
设置字典的键值对,如果指定的键已经存在,则返回存在的value,如果不存在,则添加键值对。
a = dic.setdefault("","")
v = dic.setdefault(11,"")
print(a,v)
print(dic)
789 11
{11: 11, '': '', True: 'adada', 'test': [11, 22, 33], '': ''}
(4)dic.update(**kwargs)
更新字典,如果键存在,则替换值,不存在则添加,返回值为none
a = dic.update({"k1":"v1",11:"dhqih"})
print(a)
print(dic)
None
{11: 'dhqih', '': '', True: 'adada', 'test': [11, 22, 33], 'k1': 'v1'}
列表嵌套字典排序
有如下列表,请按照年龄排序(涉及到匿名函数)
l=[
{'name':'sunqi','age':24},
{'name':'tony','age':3},
{'name':'su','age':18},
] l.sort(key=lambda item:item["age"])
五、布尔值
布尔值只有两种
(1)True 在计算机中存为1
(2)False 在计算机中存为0,常见的False类型:空列表,空字典,空字符串,空元组,0,none
可以调用bool()函数进行布尔值的判断
六、集合
集合是通过实例化set类创建的数据类型
集合特点:
(1)集合的每个元素都不相同
(2)集合是无序的
(3)集合的元素必须是不可变的(不能是列表,字典……)
s = {1,3,3,4,(2,3,4)}
print(s)
{1, (2, 3, 4), 3, 4}
集合的元素是无序的
集合方法:
1、set.add()
向集合中添加元素
s = {1,3,3,4,(2,3,4)}
s.add("sunqi")
print(s)
{1, 3, 4, 'sunqi', (2, 3, 4)}
2、set.remove()
删除集合的指定元素,如果元素不存在就会报错
s = {1,3,3,4,(2,3,4)}
s.remove(1)
print(s)
3、set.pop()
删除集合中的随机一个元素并返回删除的元素
s = {"suqni",1,3,3,4,(2,3,4)}
a = s.pop()
print(s)
print(a)
{3, 4, 'suqni', (2, 3, 4)}
1
4、set.clear()
清空集合
5、set.discard()
移除指定的元素,如果元素不存在,do nothing 不会报错
6、union方法
求出两个集合的并集
s1 = {"sunqi",1,3,4,(2,3,4)}
s2 = {"abc",1,3,7,8,(2,3,4)}
a = s1.union(s2)
print(a)
{1, 'sunqi', 3, 4, 'abc', 7, 8, (2, 3, 4)}
7、intersection方法
求出两个集合的交集
s1 = {"sunqi",1,3,4,(2,3,4)}
s2 = {"abc",1,3,7,8,(2,3,4)}
a = s1.intersection(s2)
print(a)
{1, (2, 3, 4), 3}
8、difference方法
找出第一个集合与第二个集合的差集,就是第一个集合减去与第二个集合相同的元素
s1 = {"sunqi",1,3,4,(2,3,4)}
s2 = {"abc",1,3,7,8,(2,3,4)}
a = s1.difference(s2)
s1.difference_update(s2)#得出差集并将差集更新到s1
print(s1)
print(a)
9、symmetric_difference方法
symmetric_difference_update()求补集并更新s1
补集
s1 = {"sunqi",1,3,4,(2,3,4)}
s2 = {"abc",1,3,7,8,(2,3,4)}
b = s1.intersection(s2)
a = s1.symmetric_difference(s2)
c = s1.union(s2)
print("交集",b)
print("补集",a)
print("并集",c)
交集 {1, (2, 3, 4), 3}
补集 {'sunqi', 4, 'abc', 7, 8}
并集 {'sunqi', 1, 3, 4, 'abc', 7, 8, (2, 3, 4)}
10、issubset 和 issuperset 方法
判断子集和父集
s1 = {1,3,(2,3,4)}
s2 = {"abc",1,3,7,8,(2,3,4)}
a = s1.issubset(s2)#s1是s2的子集
b = s1.issuperset(s2)
print(a)#True
print(b)#False
11、isdisjoint方法
判断两个集合是否有交集,有则返回True
数据类型总结
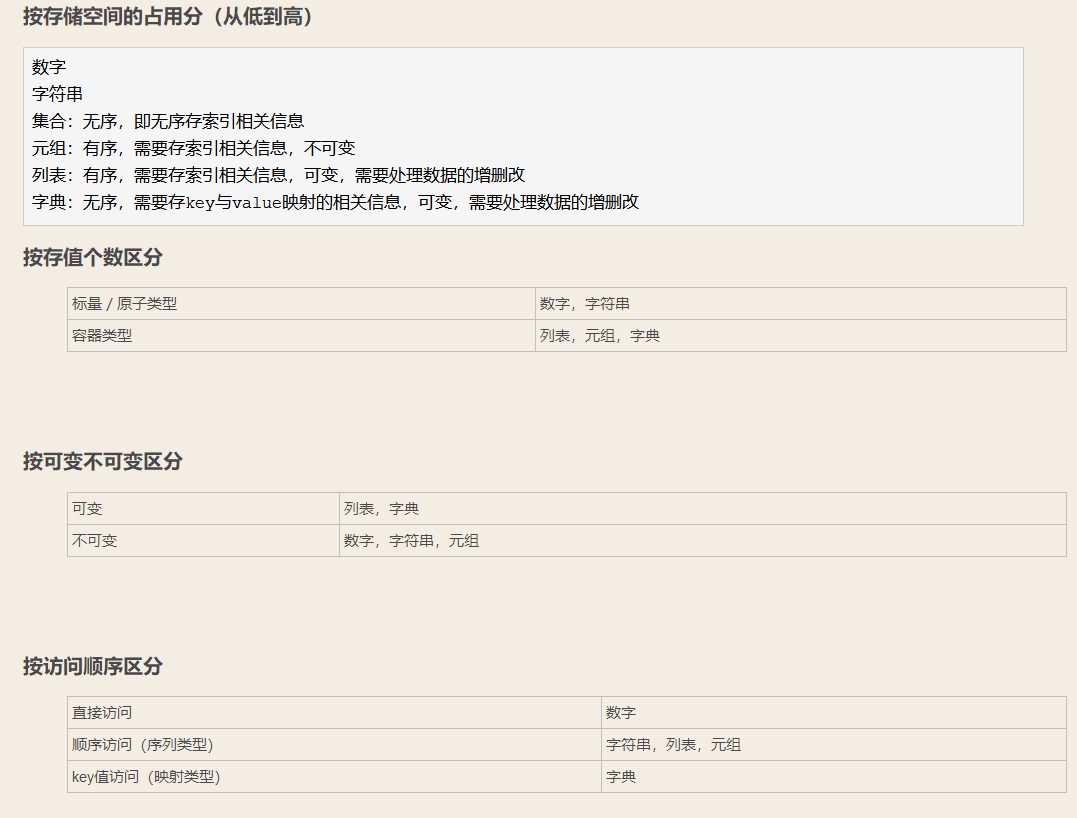
Python开发第二篇的更多相关文章
- python开发第二篇 :python基础
python基础a.Python基础 -基础1. 第一句python -python后缀名可以任意? -导入模块时如果不是.py文件,以后的文件后缀名是.py.2.两种 ...
- python开发[第二篇]------str的7个必须掌握的方法以及五个常用方法
在Python中 基本数据类型有 str int boolean list dict tuple等 其中str的相关方法有30多个 但是常用的就以下7个 join # split # find # ...
- 《python开发技术详解》|百度网盘免费下载|Python开发入门篇
<python开发技术详解>|百度网盘免费下载|Python开发入门篇 提取码:2sby 内容简介 Python是目前最流行的动态脚本语言之一.本书共27章,由浅入深.全面系统地介绍了利 ...
- iOS开发——高级技术精选&底层开发之越狱开发第二篇
底层开发之越狱开发第二篇 今天项目中要用到检查iPhone是否越狱的方法. Umeng统计的Mobclick.h里面已经包含了越狱检测的代码,可以直接使用 /*方法名: * isJailbroken ...
- Python人工智能第二篇:人脸检测和图像识别
Python人工智能第二篇:人脸检测和图像识别 人脸检测 详细内容请看技术文档:https://ai.baidu.com/docs#/Face-Python-SDK/top from aip impo ...
- Python人工智能第二篇
Python人工智能之路 - 第二篇 : 现成的技术 预备资料: 1.FFmpeg: 链接:https://pan.baidu.com/s/1jonSAa_TG2XuaJEy3iTmHg 密码:w ...
- python开发第一篇:初识python
一. Python介绍 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为AB ...
- android 串口开发第二篇:利用jni实现android和串口通信
一:串口通信简介 由于串口开发涉及到jni,所以开发环境需要支持ndk开发,如果未配置ndk配置的朋友,或者对jni不熟悉的朋友,请查看上一篇文章,android 串口开发第一篇:搭建ndk开发环境以 ...
- 微信支付之JSAPI开发-第二篇:业务流程详解与方案设计
微信支付流程 流程: 上图的网址为:https://pay.weixin.qq.com/wiki/doc/api/jsapi.php?chapter=7_4 如上图所示,微信网页支付的具体流程大致分为 ...
随机推荐
- Unity中限制轴向移动范围Mathf.Clamp
Mathf.Clamp 在游戏中,为了限制玩家的某一轴向的移动不超过一定的范围,可以用Mathf.Clamp来解决 Mathf.Clamp(float value,float min,float ...
- Boost Python学习笔记(一)
开发环境搭建 下载源码 boost_1_66_0.tar.gz 生成编译工具 # tar axf boost_1_66_0.tar.gz # cd boost_1_66_0 # yum install ...
- CentOS6.5内核升级FATAL: Module scsi_wait_scan not found
系统为CentOS6.5的虚拟机内核升级至版本4.6.0-1,重启后,报以下错误: Module scsi_wait_scan not found. 无法进入系统. 问题描述详见:Known Issu ...
- Go入门基础手记
1. 配置环境变量(临时) export GOPATH=yourpath 2. 跨平台交叉编译 env GOOS=linux GOARCH=amd64 go build 3. test写法 // 首先 ...
- 原生JS实现雪花特效
今天在校园招聘上被问到的问题,用JS写出雪花的效果.我打算使用多种方法来试试如何实现雪花. 这是目前按照网上某种思路模仿的第一种雪花,不太好看,但是大致意思清楚. 思路1:该思路直接由JS实现. 雪花 ...
- spring /* 和 /** 的 区别。
例如 /** 拦截 /index/1 和 /index /* 代表 /index/1 而 /index 则不会被拦截
- 积分图像的应用(二):非局部均值去噪(NL-means)
非局部均值去噪(NL-means)一文介绍了NL-means基本算法,同时指出了该算法效率低的问题,本文将使用积分图像技术对该算法进行加速. 假设图像共像个素点,搜索窗口大小,领域窗口大小, 计算两个 ...
- 转 用Oracle自带脚本 重建WMSYS用户的WMSYS.WM_CONCAT函数
https://blog.csdn.net/huaishuming/article/details/41726659?locationNum=1
- URAL 2080 Wallet
找规律发现只要找到两个相同数字之间,有多少个不同的数字,即为答案. 可以用树状数组离线处理. 坑点是卡有很多张,没用完的情况,后面的卡直接放在哪里, 就是 10 5 1 2 3 4 5 这样 开始数据 ...
- CONCAT substr group_concat find_in_set
(SELECT p.*,(SELECT CONCAT(m.name,m.id) FROM service_fastfix_category m WHERE m.id=SUBSTR(p.id,1,4)) ...