转 Join的实现原理及优化思路
前言
前面我们已经了解了MySQLQueryOptimizer的工作原理,学习了Query优化的基本原则和思路,理解了索引选择的技巧,这一节我们将围绕Query语句中使用非常频繁,且随时可能存在性能隐患的Join语句,继续我们的Query优化之旅。
Join 的实现原理
在寻找Join语句的优化思路之前,我们首先要理解在MySQL中是如何来实现Join的,只要理解了实现原理之后,优化就比较简单了。下面我们先分析一下MySQL中Join的实现原理。
在MySQL中,只有一种Join算法,就是大名鼎鼎的NestedLoopJoin,他没有其他很多数据库所提供的HashJoin,也没有SortMergeJoin。顾名思义,NestedLoopJoin实际上就是通过驱动表的结果集作为循环基础数据,然后一条一条的通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。如果还有第三个参与Join,则再通过前两个表的Join结果集作为循环基础数据,再一次通过循环查询条件到第三个表中查询数据,如此往复。
下面我们将通过一个三表Join语句示例来说明MySQL的NestedLoopJoin实现方式。
注意:由于要展示Explain中的一个在MySQL5.1.18才开始出现的输出信息(在之前版本中只是没有输出信息,实际执行过程并没有变化),所以下面的示例环境是MySQL5.1.26。
Query 如下:
select m.subject msg_subject, c.content msg_content
from user_group g,group_message m,group_message_content c
where g.user_id = 1 and m.group_id = g.group_id
and c.group_msg_id = m.id
为了便于示例,我们通过如下操作为group_message表增加了一个group_id的索引:
create index idx_group_message_gid_uid on group_message(group_id);
然后看看我们的Query的执行计划:

sky@localhost : example 11:17:04> explain select m.subject msg_subject, c.content msg_content -> from user_group g,group_message m,group_message_content c -> where g.user_id = 1 -> and m.group_id = g.group_id -> and c.group_msg_id = m.id\G *************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: g
type: ref
possible_keys: user_group_gid_ind,user_group_uid_ind,user_group_gid_uid_ind
key: user_group_uid_ind
key_len: 4
ref: const rows: 2
Extra:
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: m
type: ref
possible_keys: PRIMARY,idx_group_message_gid_uid
key: idx_group_message_gid_uid
key_len: 4
ref: example.g.group_id
rows: 3
Extra:
*************************** 3. row ***************************
id: 1
select_type: SIMPLE
table: c
type: ref
possible_keys: idx_group_message_content_msg_id
key: idx_group_message_content_msg_id
key_len: 4
ref: example.m.id
rows: 2
Extra:
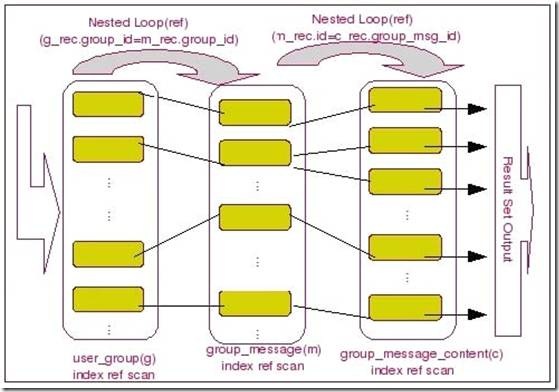
我们可以看出,MySQLQueryOptimizer选择了user_group作为驱动表,首先利用我们传入的条件user_id通过该表上面的索引user_group_uid_ind来进行const条件的索引ref查找,然后以user_group表中过滤出来的结果集的group_id字段作为查询条件,对group_message循环查询,然后再通过user_group和group_message两个表的结果集中的group_message的id作为条件与group_message_content的group_msg_id比较进行循环查询,才得到最终的结果。
这个过程可以通过如下表达式来表示:
for each record g_rec in table user_group that g_rec.user_id=1{
for each record m_rec in group_message that m_rec.group_id=g_rec.group_id{
for each record c_rec in group_message_content that c_rec.group_msg_id=m_rec.id
pass the (g_rec.user_id, m_rec.subject, c_rec.content) row
combination to output;
} }
下图可以更清晰的标识出实际的执行情况:
假设我们去掉group_message_content表上面的group_msg_id字段的索引,然后再看看执行计划会变成怎样:
sky@localhost : example 11:25:36> drop index idx_group_message_content_msg_id on
group_message_content;
Query OK, 96 rows affected (0.11 sec) sky@localhost : example 10:21:06> explain -> select m.subject msg_subject, c.content msg_content -> from user_group g,group_message m,group_message_content c -> where g.user_id = 1 -> and m.group_id = g.group_id -> and c.group_msg_id = m.id\G *************************** 1. row *************************** id: 1
select_type: SIMPLE
table: g
type: ref
possible_keys: idx_user_group_uid
key: idx_user_group_uid
key_len: 4
ref: const
rows: 2 Extra: *************************** 2. row *************************** id: 1
select_type: SIMPLE
table: m
type: ref
possible_keys: PRIMARY,idx_group_message_gid_uid
key: idx_group_message_gid_uid
key_len: 4
ref: example.g.group_id
rows: 3
Extra: *************************** 3. row *************************** id: 1
select_type: SIMPLE
table: c
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 96
Extra: Using where; Using join buffer
我们看到不仅仅user_group表的访问从ref变成了ALL,此外,在最后一行的Extra信息从没有任何内容变成为Usingwhere;Usingjoinbuffer,也就是说,对于从ref变成ALL很容易理解,没有可以使用的索引的索引了嘛,当然得进行全表扫描了,Usingwhere也是因为变成全表扫描之后,我们需要取得的content字段只能通过对表中的数据进行where过滤才能取得,但是后面出现的Usingjoinbuffer是一个啥呢?
实际上,这里的Join正是利用到了我们在之前“MySQLServer性能优化”一章中所提到的一个Cache参数相关的内容,也就是我们通过join_buffer_size参数所设置的JoinBuffer。
实际上,JoinBuffer只有当我们的Join类型为ALL(如示例中),index,rang或者是index_merge的时候才能够使用,所以,在我们去掉group_message_content表的group_msg_id字段的索引之前,由于Join是ref类型的,所以我们的执行计划中并没有看到有使用JoinBuffer。
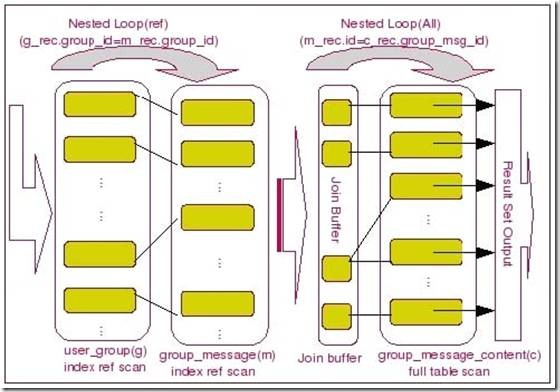
当我们使用了JoinBuffer之后,我们可以通过下面的这个表达式描述出示例中我们的Join完成过程:
for each record g_rec in table user_group{
for each record m_rec in group_message that m_rec.group_id=g_rec.group_id
{
put (g_rec, m_rec) into the buffer if (buffer is full) flush_buffer();
}
}
flush_buffer(){
for each record c_rec in group_message_content that c_rec.group_msg_id = c_rec.id{
for each record in the buffer
pass (g_rec.user_id, m_rec.subject, c_rec.content) row combination to output; }
empty the buffer;
}
当然,如果通过类似于上面的图片来展现或许大家会觉得更容易理解一些,如下:
通过上面的示例,我想大家应该对MySQL中NestedJoin的实现原理有了一个了解了,也应该清楚MySQL使用JoinBuffer的方法了。当然,这里并没有涉及到外连接的内容,实际对于外连接来说,可能存在的区别主要是连接顺序以及组合空值记录方面。
Join 语句的优化
在明白了MySQL中Join的实现原理之后,我们就比较清楚的知道该如何去优化一个一个Join语句了。
1.尽可能减少Join语句中的NestedLoop的循环总次数;如何减少NestedLoop的循环总次数?最有效的办法只有一个,那就是让驱动表的结果集尽可能的小,这也正是在本章第二节中的优化基本原则之一“永远用小结果集驱动大的结果集”。
为什么?因为驱动结果集越大,意味着需要循环的次数越多,也就是说在被驱动结果集上面所需要执行的查询检索次数会越多。比如,当两个表(表A和表B)Join的时候,如果表A通过WHERE条件过滤后有10条记录,而表B有20条记录。如果我们选择表A作为驱动表,也就是被驱动表的结果集为20,那么我们通过Join条件对被驱动表(表B)的比较过滤就会有10次。反之,如果我们选择表B作为驱动表,则需要有20次对表A的比较过滤。
当然,此优化的前提条件是通过Join条件对各个表的每次访问的资源消耗差别不是太大。如果访问存在较大的差别的时候(一般都是因为索引的区别),我们就不能简单的通过结果集的大小来判断需要Join语句的驱动顺序,而是要通过比较循环次数和每次循环所需要的消耗的乘积的大小来得到如何驱动更优化。
2.优先优化NestedLoop的内层循环;
不仅仅是在数据库的Join中应该做的,实际上在我们优化程序语言的时候也有类似的优化原则。内层循环是循环中执行次数最多的,每次循环节约很小的资源,在整个循环中就能节约很大的资源。
3.保证Join语句中被驱动表上Join条件字段已经被索引;
保证被驱动表上Join条件字段已经被索引的目的,正是针对上面两点的考虑,只有让被驱动表的Join条件字段被索引了,才能保证循环中每次查询都能够消耗较少的资源,这也正是优化内层循环的实际优化方法。
4.当无法保证被驱动表的Join条件字段被索引且内存资源充足的前提下,不要太吝惜JoinBuffer的设置;
当在某些特殊的环境中,我们的Join必须是All,Index,range或者是index_merge类型的时候,JoinBuffer就会派上用场了。在这种情况下,JoinBuffer的大小将对整个Join语句的消耗起到非常关键的作用。
转 Join的实现原理及优化思路的更多相关文章
- MySQL join的实现原理及优化思路
Join 的实现原理 在MySQL 中,只有一种Join 算法,也就是Nested Loop Join,没有其他很多数据库所提供的Hash Join,也没有Sort Merge Join.顾名思义,N ...
- MySQL Join 的实现原理
在寻找Join 语句的优化思路之前,我们首先要理解在MySQL 中是如何来实现Join 的,只要理解了实现原理之后,优化就比较简单了.下面我们先分析一下MySQL 中Join 的实现原理.在MySQL ...
- sql索引优化思路
[开发]SQL优化思路(以oracle为例) powered by wanglifeng https://www.cnblogs.com/wanglifeng717 单表查询的优化思路 单表查询是最简 ...
- MySQL-join的实现原理、优化及NLJ算法
案例分析: select c.* from hotel_info_original c left join hotel_info_collection h on c.hotel_type=h.hote ...
- MySQL order by的一个优化思路
最近遇到一条SQL线上执行超过5s,这显然无法忍受了,必须要优化了. 首先看眼库表结构和SQL语句. CREATE TABLE `xxxxx` ( `id` ) NOT NULL AUTO_INCRE ...
- 0709关于mysql优化思路【何登成】
转自 http://isky000.com/database/mysql-performance-tuning-sql 优化目标 减少 IO 次数IO永远是数据库最容易瓶颈的地方,这是由数据库的职责所 ...
- mysql简单优化思路
mysql简单优化思路 作为开发人员,数据库知识掌握的可能不是很深入,但是一些基本的技能还是要有时间学习一下的.作为一个数据库菜鸟,厚着脸皮来总结一下 mysql 的基本的不能再基本的优化方法. 为了 ...
- IM开发基础知识补课(七):主流移动端账号登录方式的原理及设计思路
1.引言 在即时通讯网经常能看到各种高大上的高并发.分布式.高性能架构设计方面的文章,平时大家参加的众多开发者大会,主题也都是各种高大上的话题——什么5G啦.AI人工智能啦.什么阿里双11分分钟多少万 ...
- extjs 动态加载列表,优化思路
功能截图 之前做法,先查询每一行的前4个字段,然后动态拼接出其他的字段,效率极低,以下是优化后的代码,供参考,只提供一个优化思路,授人以鱼不如授人以渔 后台Sql语句优化(语法仅支持Oracle) S ...
随机推荐
- [Codeforces947D]Riverside Curio(思维)
Description 题目链接 Solution 设S[i]表示到第i天总共S[i]几个标记, 那么满足S[i]=m[i]+d[i]+1 m[i]表示水位上的标记数,d[i]表示水位下的标记数 那么 ...
- 15.5,centos下redis安全相关
博文背景: 由于发现众多同学,在使用云服务器时,安装的redis3.0+版本都关闭了protected-mode,因而都遭遇了挖矿病毒的攻击,使得服务器99%的占用率!! 因此我们在使用redis ...
- android stadio 打开别人的工程 一直在编译中
这是因为,他工程的gradle 配置,在你本地找不到,所以,会去网上下.然后解压,使用.这是一个很漫长的过程. *那么怎么做呢 修改项目工程的gradle/wrapper/gradle-wrapper ...
- Kafka写入流程和副本策略
Kafka写入流程: 1.producer 先从 zookeeper 的 "/brokers/.../state" 节点找到该 partition 的 leader 2. prod ...
- Hyper-V中的Linux无法配置网络地址的解决办法
一周碰到2次在Hyper-V 2012中安装了Linux,也安装了IC 3.4.但是却无法配置IP地址的问题.因此造成很多不便,因此找机会把这个原因和解决办法进行了尝试. 这过程中感谢同事的提示,让我 ...
- 腾讯QQ空间穿越时光轴3D特效
<DOCTYPE html> <html> <head> <title>腾讯QQ空间穿越光轴3D特效</title> <style&g ...
- javaWEB简单商城项目
javaWEB简单商城项目(一) 项目中使用到了上一篇博文的分页框架,还有mybatis,重点是学习mybatis.现在有些小迷茫,不知道该干啥,唉,不想那么多了,学就对了 一.项目功能结构 1.功能 ...
- 为什么工具类App,都要做一个社区?
非著名程序员涩郎 非著名程序员,字耿左直右,号涩郎,爱搞机,爱编程,是爬行在移动互联网中的一名码匠!个人微信号:loonggg,微博:涩郎,专注于移动互联网的开发和研究,本号致力于分享IT技术和程序猿 ...
- C# 6.0/7.0 的新特性
转眼C#语言都已经迭代到7.0版本了,很多小伙伴都已经把C# 7.0 的新特性应用到代码中了,想想自己连6.0的新特性都还很少使用,今天特意搜集了一下6.0和7.0的一些新特性,记录一下,方便查阅. ...
- java日期格式化(util包下转成sql包下)
package test; import java.text.SimpleDateFormat;import java.util.Date;import java.util.Scanner; publ ...