机器学习:衡量线性回归法的指标(MSE、RMSE、MAE、R Squared)
一、MSE、RMSE、MAE
- 思路:测试数据集中的点,距离模型的平均距离越小,该模型越精确
- # 注:使用平均距离,而不是所有测试样本的距离和,因为距离和受样本数量的影响
1)公式:
- MSE:均方误差

- RMSE:均方根误差

- MAE:平均绝对误差

二、具体实现
1)自己的代码
import numpy as np
from sklearn.metrics import r2_score class SimpleLinearRegression: def __init__(self):
"""初始化Simple Linear Regression模型"""
self.a_ = None
self.b_ = None def fit(self, x_train, y_train):
"""根据训练数据集x_train, y_train训练Simple Linear Regression模型"""
assert x_train.ndim == 1, \
"Simple Linear Regressor can only solve single feature training data."
assert len(x_train) == len(y_train), \
"the size of x_train must be equal to the size of y_train" x_mean = np.mean(x_train)
y_mean = np.mean(y_train) self.a_ = (x_train - x_mean).dot(y_train - y_mean) / (x_train - x_mean).dot(x_train - x_mean)
self.b_ = y_mean - self.a_ * x_mean return self def predict(self, x_predict):
"""给定待预测数据集x_predict,返回表示x_predict的结果向量"""
assert x_predict.ndim == 1, \
"Simple Linear Regressor can only solve single feature training data."
assert self.a_ is not None and self.b_ is not None, \
"must fit before predict!" return np.array([self._predict(x) for x in x_predict]) def _predict(self, x_single):
"""给定单个待预测数据x,返回x的预测结果值"""
return self.a_ * x_single + self.b_ def score(self, x_test, y_test):
"""根据测试数据集 x_test 和 y_test 确定当前模型的准确度:R^2""" y_predict = self.predict(x_test)
return r2_score(y_test, y_predict) def __repr__(self):
return "SimpleLinearRegression()"
2)调用scikit-learn中的算法
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error # MSE
mse_predict = mean_squared_error(y_test, y_predict) # MAE
mae_predict = mean_absolute_error(y_test, y_predict) # y_test:测试数据集中的真实值
# y_predict:根据测试集中的x所预测到的数值
3)RMSE和MAE的比较
- 量纲一样:都是原始数据中y对应的量纲
- RMSE > MAE:
# 这是一个数学规律,一组正数的平均数的平方,小于每个数的平方和的平均数;
四、最好的衡量线性回归法的指标:R Squared
- 准确度:[0, 1],即使分类的问题不同,也可以比较模型应用在不同问题上所体现的优劣;
- RMSE和MAE有局限性:同一个算法模型,解决不同的问题,不能体现此模型针对不同问题所表现的优劣。因为不同实际应用中,数据的量纲不同,无法直接比较预测值,因此无法判断模型更适合预测哪个问题。
- 方案:将预测结果转换为准确度,结果都在[0, 1]之间,针对不同问题的预测准确度,可以比较并来判断此模型更适合预测哪个问题;
1)计算方法

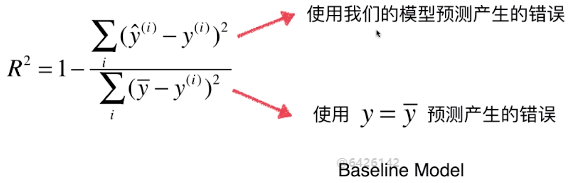
2)对公式的理解
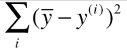 :公式样式与MSE类似,可以理解为一个预测模型,只是该模型与x无关,在机器学习领域称这种模型为基准模型(Baseline Model),适用于所有的线型回归算法;
:公式样式与MSE类似,可以理解为一个预测模型,只是该模型与x无关,在机器学习领域称这种模型为基准模型(Baseline Model),适用于所有的线型回归算法;- 基准模型问题:因为其没有考虑x的取值,只是很生硬的以为所有的预测样本,其预测结果都是样本均值
A)因此对公式可以这样理解:
- 分子是我们的模型预测产生的错误,分母是使用y等于y的均值这个模型所产生的错误
- 自己的模型预测产生的错误 / 基础模型预测生产的错误,表示自己的模型没有拟合住的数据,因此R2可以理解为,自己的模型拟合住的数据
B)公式推理结论:
- R2 <= 1
- R2越大越好,当自己的预测模型不犯任何错误时:R2 = 1
- 当我们的模型等于基准模型时:R2 = 0
- 如果R2 < 0,说明学习到的模型还不如基准模型。 # 注:很可能数据不存在任何线性关系
3)公式变形
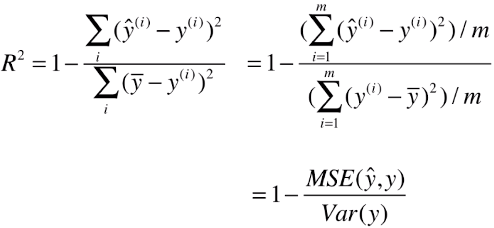
- R2背后具有其它统计意思
4)R2的代码实现及使用
具体代码:
1 - mean_squared_error(y_true, y_predict) / np.var(y_true) # mean_squared_error()函数就是MSE
# np.var(array):求向量的方差- 调用scikit-learn中的r2_score()函数:
from sklearn.metrics import r2_score r2_score(y_test, y_predict) # y_test :测试数据集中的真实值
# y_predict:预测到的数据
机器学习:衡量线性回归法的指标(MSE、RMSE、MAE、R Squared)的更多相关文章
- 衡量线性回归法的指标MSE, RMSE,MAE和R Square
衡量线性回归法的指标:MSE, RMSE和MAE 举个栗子: 对于简单线性回归,目标是找到a,b 使得尽可能小 其实相当于是对训练数据集而言的,即 当我们找到a,b后,对于测试数据集而言 ,理所当然, ...
- 【笔记】衡量线性回归法的指标 MSE,RMS,MAE以及评价回归算法 R Square
衡量线性回归法的指标 MSE,RMS,MAE以及评价回归算法 R Square 衡量线性回归法的指标 对于分类问题来说,我们将原始数据分成了训练数据集和测试数据集两部分,我们使用训练数据集得到模型以后 ...
- 机器学习:线性回归法(Linear Regression)
# 注:使用线性回归算法的前提是,假设数据存在线性关系,如果最后求得的准确度R < 0,则说明很可能数据间不存在任何线性关系(也可能是算法中间出现错误),此时就要检查算法或者考虑使用其它算法: ...
- 线性回归中常见的一些统计学术语(RSE RSS TSS ESS MSE RMSE R2 Pearson's r)
TSS: Total Sum of Squares(总离差平方和) --- 因变量的方差 RSS: Residual Sum of Squares (残差平方和) --- 由误差导致的真实值和估计值 ...
- 机器学习之线性回归(纯python实现)][转]
本文转载自:https://juejin.im/post/5a924df16fb9a0634514d6e1 机器学习之线性回归(纯python实现) 线性回归是机器学习中最基本的一个算法,大部分算法都 ...
- 可决系数R^2和MSE,MAE,SMSE
波士顿房价预测 首先这个问题非常好其实要完整的回答这个问题很有难度,我也没有找到一个完整叙述这个东西的资料,所以下面主要是结合我自己的理解和一些资料谈一下r^2,mean square error 和 ...
- 机器学习算法的基本知识(使用Python和R代码)
本篇文章是原文的译文,然后自己对其中做了一些修改和添加内容(随机森林和降维算法).文章简洁地介绍了机器学习的主要算法和一些伪代码,对于初学者有很大帮助,是一篇不错的总结文章,后期可以通过文中提到的算法 ...
- 第3章 衡量线性回归的指标:MSE,RMSE,MAE
, , ,, , , ,
- C / C ++ 基于梯度下降法的线性回归法(适用于机器学习)
写在前面的话: 在第一学期做项目的时候用到过相应的知识,觉得挺有趣的,就记录整理了下来,基于C/C++语言 原贴地址:https://helloacm.com/cc-linear-regression ...
随机推荐
- INSPIRED启示录 读书笔记 - 第30章 在大公司施展拳脚
十大秘诀 1.了解公司制定决策的方式:知道决策权在谁手里,了解他制定决策的方式,只需要说服他就行了 2.建立人脉网络:主动帮助他人,积累人脉关系 3.臭鼬工程:在工作之余做出产品原型来,产品原型具有超 ...
- INSPIRED启示录 读书笔记 - 第14章 产品评审团
制定更及时.更可靠的产品决策 制定决策通常是既耗时又费力的,产品公司需要一套机制让决策者和相关人员及时作出明智的产品决策.成立产品评审团是最好的解决途径 组织产品评审团的难点在于既要为高管制定产品决策 ...
- Vue.js学习笔记 第二篇 样式绑定
Class绑定的对象语法 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> ...
- Python 循环的综合应用
# 循环综合应用1. # str = "hello,world" 把字符串给反转显示 str = "hello,world" temp = "&quo ...
- Adroid真机调试
几次想学Android,都因为启动模拟器调试时太慢而放弃. 今天终于搞通了真机调试,记录一下: 1)USB线把手机和电脑连接. 2)Adroid手机启用USB调试. 3)命令行运行 adb devic ...
- poj 1330 【最近公共祖先问题+fa[]数组+ 节点层次搜索标记】
题目地址:http://poj.org/problem?id=1330 Sample Input 2 16 1 14 8 5 10 16 5 9 4 6 8 4 4 10 1 13 6 15 10 1 ...
- 8.14比赛j题 http://acm.hust.edu.cn/vjudge/contest/view.action?cid=87813#overview
就我个人来说我觉得这道题其实不用写题解,只是因为做的时候错了一次,如果不是队友细心,我根本会错下去,所以我感觉自己必须强大#include<stdio.h> #include<str ...
- 让外界可以访问电脑上的网站的几种方式——花生壳,域名,IIS(待)
前话: 每次“养大“一个网站,都有种骄傲地想秀给朋友们看的冲动. 之前可能是困于电脑,实在不方便. 现在,不用克制了! 该秀就秀,能装逼就装逼. 养大孩子就该拉出来秀秀,见见世面. 正题:这次实习,我 ...
- HDU 6096 AC自动机
n个字符串 m个询问 每个询问给出前后缀 并且不重合 问有多少个满足 m挺大 如果在线只能考虑logn的算法 官方题解:对n个串分别存正序倒序 分别按照字典序sort 每一个串就可以被化作一个点 那么 ...
- 命令行下载Baiduyun files
源码 步骤1:先拿到一个插件插件地址1,插件地址2 步骤2:解压并保存 下载的文件中,包含了一个Baidu-PCS的文件夹.然后打开我们的资源管理器.将Baidu-PCS随意移动到一个文件目录下,但文 ...