Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容:
1、RDD依赖关系的本质内幕
2、依赖关系下的数据流视图
3、经典的RDD依赖关系解析
4、RDD依赖关系源码内幕
1、RDD依赖关系的本质内幕
由于RDD是粗粒度的操作数据集,每个Transformation操作都会生成一个新的RDD,所以RDD之间就会形成类似流水线的前后依赖关系;在spark中,RDD之间存在两种类型的依赖关系:窄依赖(Narrow Dependency)和宽依赖(Wide Dependency 或者是 Narrow Dependency);如图1所示显示了RDD之间的依赖关系。
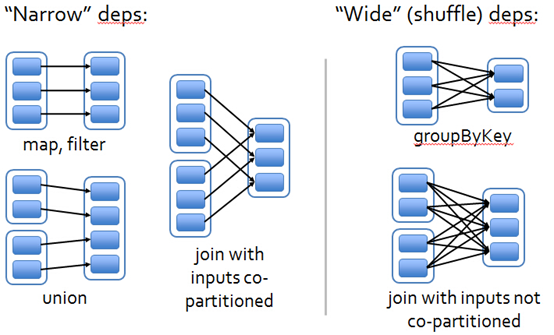
图1
从图1中可知:
窄依赖是指每个父RDD的一个Partition最多被子RDD的一个Partition所使用,例如map、filter、union等操作都会产生窄依赖;
宽依赖是指一个父RDD的Partition会被多个子RDD的Partition所使用,例如groupByKey、reduceByKey、sortByKey等操作都会产生宽依赖;
需要特别说明的是对join操作有两种情况:如果两个RDD在进行join操作时,一个RDD的partition仅仅和另一个RDD中已知个数的Partition进行join,那么这种类型的join操作就是窄依赖,例如图1中左半部分的join操作(join with inputs co-partitioned);其它情况的join操作就是宽依赖,例如图1中右半部分的join操作(join with inputs not co-partitioned),由于是需要父RDD的所有partition进行join的转换,这就涉及到了shuffle,因此这种类型的join操作也是宽依赖。
总结:在这里我们是从父RDD的partition被使用的个数来定义窄依赖和宽依赖,因此可以用一句话概括下:如果父RDD的一个Partition被子RDD的一个Partition所使用就是窄依赖,否则的话就是宽依赖。因为是确定的partition数量的依赖关系,所以RDD之间的依赖关系就是窄依赖;由此我们可以得出一个推论:即窄依赖不仅包含一对一的窄依赖,还包含一对固定个数的窄依赖。
一对固定个数的窄依赖的理解:即子RDD的partition对父RDD依赖的Partition的数量不会随着RDD数据规模的改变而改变;换句话说,无论是有100T的数据量还是1P的数据量,在窄依赖中,子RDD所依赖的父RDD的partition的个数是确定的,而宽依赖是shuffle级别的,数据量越大,那么子RDD所依赖的父RDD的个数就越多,从而子RDD所依赖的父RDD的partition的个数也会变得越来越多。
2、依赖关系下的数据流视图
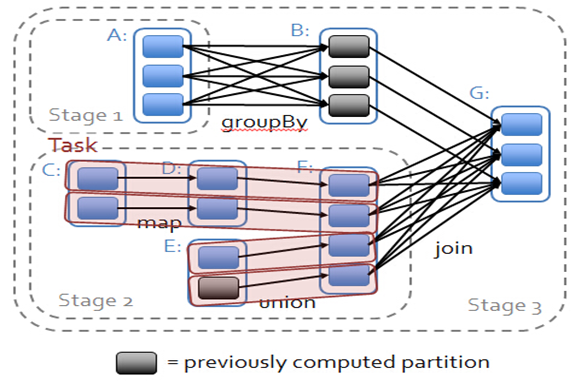
在spark中,会根据RDD之间的依赖关系将DAG图划分为不同的阶段,对于窄依赖,由于partition依赖关系的确定性,partition的转换处理就可以在同一个线程里完成,窄依赖就被spark划分到同一个stage中,而对于宽依赖,只能等父RDD shuffle处理完成后,下一个stage才能开始接下来的计算。
因此spark划分stage的整体思路是:从后往前推,遇到宽依赖就断开,划分为一个stage;遇到窄依赖就将这个RDD加入该stage中。因此在图2中RDD C,RDD D,RDD E,RDDF被构建在一个stage中,RDD A被构建在一个单独的Stage中,而RDD B和RDD G又被构建在同一个stage中。
在spark中,Task的类型分为2种:ShuffleMapTask和ResultTask;
简单来说,DAG的最后一个阶段会为每个结果的partition生成一个ResultTask,即每个Stage里面的Task的数量是由该Stage中最后一个RDD的Partition的数量所决定的!而其余所有阶段都会生成ShuffleMapTask;之所以称之为ShuffleMapTask是因为它需要将自己的计算结果通过shuffle到下一个stage中;也就是说图2中的stage1和stage2相当于mapreduce中的Mapper,而ResultTask所代表的stage3就相当于mapreduce中的reducer。
需要补充说明的是,在前面的课程中,我们实际动手操作了一个wordcount程序,因此可知,Hadoop中MapReduce操作中的Mapper和Reducer在spark中的基本等量算子是map和reduceByKey;不过区别在于:Hadoop中的MapReduce天生就是排序的;而reduceByKey只是根据Key进行reduce,但spark除了这两个算子还有其他的算子;因此从这个意义上来说,Spark比Hadoop的计算算子更为丰富。

3、Stage中任务执行的内幕思考
在一个stage内部,从表面上看是数据在不断流动,然后经过相应的算子处理后再流向下一个算子,但实质是算子在流动;我们可以从如下两个方面来理解:
(1) 数据不动代码动;这点从算法构建和逻辑上来说,是算子作用于数据上,而算子处理数据一般有多个步骤,所以这里说数据不动代码动;
(2) 在一个stage内部,算子之所以会流动(pipeline)首先是因为算子合并,也就是所谓的函数式编程在执行的时候最终进行函数的展开,从而把一个stage内部的多个算子合并成为一个大算子(其内部包含了当前stage中所有算子对数据的所有计算逻辑);其次是由于Transformation操作的Lazy特性。因为这些转换操作是Lazy的,所以才可以将这些算子合并;如果我们直接使用scala语言是不可以的,即使可以在算子前面加上一个Lazy关键字,但是它每次操作的时候都会产生中间结果。同时在具体算子交给集群的executor计算之前首先会通过Spark Framework(DAGScheduler)进行算子的优化(即基于数据本地性的pipeline)。

4、RDD依赖关系源码内幕
源码初探
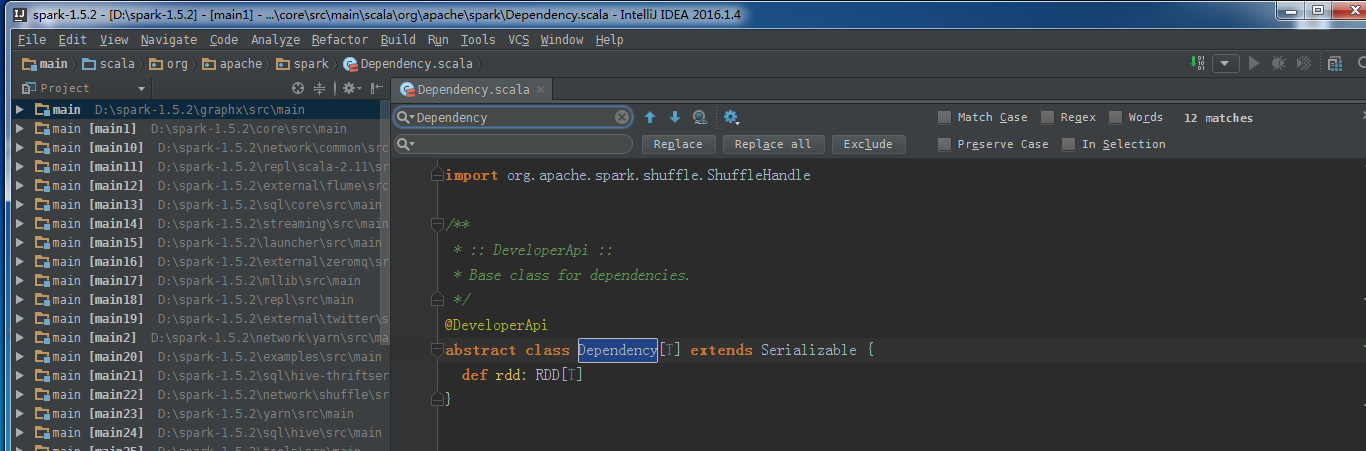
在IDEA中打开源码,找到org.apache.spark.Dependency.scala这个类,首先我们可以看到如下的代码:

图3
在抽象类Dependency中,rdd就是子RDD所依赖的父RDD,同时所有的依赖都要实现Dependency[T],这点我们可以查看宽依赖和窄依赖的实现源代码。
Dependency源码
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/ package org.apache.spark import org.apache.spark.annotation.DeveloperApi
import org.apache.spark.rdd.RDD
import org.apache.spark.serializer.Serializer
import org.apache.spark.shuffle.ShuffleHandle /**
* :: DeveloperApi ::
* Base class for dependencies.
*/
@DeveloperApi
abstract class Dependency[T] extends Serializable {
def rdd: RDD[T]
} /**
* :: DeveloperApi ::
* Base class for dependencies where each partition of the child RDD depends on a small number
* of partitions of the parent RDD. Narrow dependencies allow for pipelined execution.
*/
@DeveloperApi
abstract class NarrowDependency[T](_rdd: RDD[T]) extends Dependency[T] {
/**
* Get the parent partitions for a child partition.
* @param partitionId a partition of the child RDD
* @return the partitions of the parent RDD that the child partition depends upon
*/
def getParents(partitionId: Int): Seq[Int] override def rdd: RDD[T] = _rdd
} /**
* :: DeveloperApi ::
* Represents a dependency on the output of a shuffle stage. Note that in the case of shuffle,
* the RDD is transient since we don't need it on the executor side.
*
* @param _rdd the parent RDD
* @param partitioner partitioner used to partition the shuffle output
* @param serializer [[org.apache.spark.serializer.Serializer Serializer]] to use. If set to None,
* the default serializer, as specified by `spark.serializer` config option, will
* be used.
* @param keyOrdering key ordering for RDD's shuffles
* @param aggregator map/reduce-side aggregator for RDD's shuffle
* @param mapSideCombine whether to perform partial aggregation (also known as map-side combine)
*/
@DeveloperApi
class ShuffleDependency[K, V, C](
@transient _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Option[Serializer] = None,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]] { override def rdd: RDD[Product2[K, V]] = _rdd.asInstanceOf[RDD[Product2[K, V]]] val shuffleId: Int = _rdd.context.newShuffleId() val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle(
shuffleId, _rdd.partitions.size, this) _rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
} /**
* :: DeveloperApi ::
* Represents a one-to-one dependency between partitions of the parent and child RDDs.
*/
@DeveloperApi
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = List(partitionId)
} /**
* :: DeveloperApi ::
* Represents a one-to-one dependency between ranges of partitions in the parent and child RDDs.
* @param rdd the parent RDD
* @param inStart the start of the range in the parent RDD
* @param outStart the start of the range in the child RDD
* @param length the length of the range
*/
@DeveloperApi
class RangeDependency[T](rdd: RDD[T], inStart: Int, outStart: Int, length: Int)
extends NarrowDependency[T](rdd) { override def getParents(partitionId: Int): List[Int] = {
if (partitionId >= outStart && partitionId < outStart + length) {
List(partitionId - outStart + inStart)
} else {
Nil
}
}
}
4.1窄依赖源代码分析:
接着我们可以看到NarrowDependency这个抽象类源码:
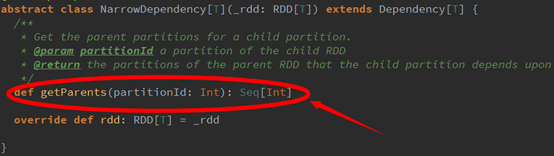
图4
其中getParents这个函数的作用是返回子RDD的partitioneId依赖的所有的父RDD的partitions;
我们在上面说过,窄依赖有两种情况:一种是一对一的依赖,另一种是一对确定个数的依赖,我们可以从源代码中找到这两种窄依赖的具体实现;第一种即为OneToOneDependency:

图5
从getParents的实现可知,子RDD仅仅依赖于父RDD相同ID的Partition;
那么第二种类型的窄依赖即为:RangeDependency,它只被org.apache.spark.rdd.UnionRDD所使用;我们可以在UnionRDD中看下相应的使用情况:
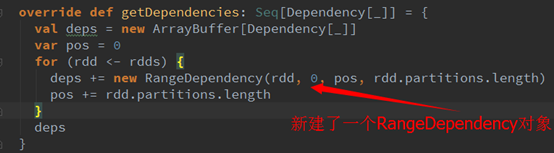
图6
UnionRDD是将多个RDD合并成一个RDD,这些RDD是被拼接起来的,即每个父RDD的partition的相对顺序不变,只是每个父RDD在UnionRDD中的Partition的起始位置不同,具体我们可以看看RangeDependency中getParents方法的实现:
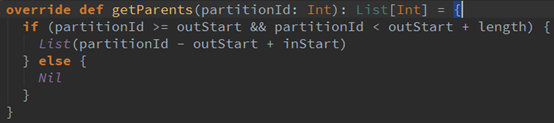
图7
其中,inStart是父RDD中Partition的起始位置,outStart是在UnionRDD中的起始位置,length是父RDD中Partition的数量。
4.2宽依赖源代码分析
由于宽依赖的实现只有一种:ShuffleDependency;即父RDD的一个Partition被子RDD的多个partition所使用,我们主要关注以下两点:

图8
ShuffleId表示获取新的Id,下面的shuffleHandle表示向ShuffleManger注册Shuffle信息。
宽依赖支持两种类型的Shuffle Manager,即HashShuffleManager和SortShuffleManager。如图9所示:
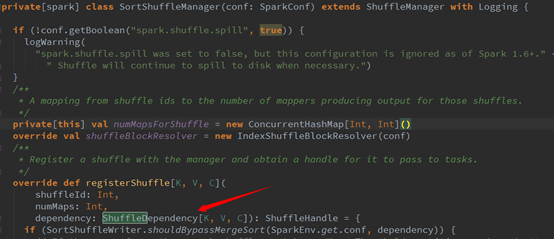
图9
感谢下面的博主:
http://bbs.pinggu.org/thread-4637506-1-1.html
DT大数据梦工厂联系方式:
新浪微博:www.weibo.com/ilovepains/
微信公众号:DT_Spark
博客:http://.blog.sina.com.cn/ilovepains
TEL:18610086859
Email:18610086859@vip.126.com
Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)的更多相关文章
- Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系? RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency). 1)窄依赖指的是每 ...
- Spark RDD概念学习系列之RDD的转换(十)
RDD的转换 Spark会根据用户提交的计算逻辑中的RDD的转换和动作来生成RDD之间的依赖关系,同时这个计算链也就生成了逻辑上的DAG.接下来以“Word Count”为例,详细描述这个DAG生成的 ...
- Spark RDD概念学习系列之RDD的checkpoint(九)
RDD的检查点 首先,要清楚.为什么spark要引入检查点机制?引入RDD的检查点? 答:如果缓存丢失了,则需要重新计算.如果计算特别复杂或者计算耗时特别多,那么缓存丢失对于整个Job的影响是不容 ...
- Spark RDD概念学习系列之RDD的5大特点(五)
RDD的5大特点 1)有一个分片列表,就是能被切分,和Hadoop一样,能够切分的数据才能并行计算. 一组分片(partition),即数据集的基本组成单位,对于RDD来说,每个分片都会被一个计 ...
- Spark RDD概念学习系列之RDD是什么?(四)
RDD是什么? 通俗地理解,RDD可以被抽象地理解为一个大的数组(Array),但是这个数组是分布在集群上的.详细见 Spark的数据存储 Spark的核心数据模型是RDD,但RDD是个抽象类 ...
- Spark RDD概念学习系列之RDD的容错机制(十七)
RDD的容错机制 RDD实现了基于Lineage的容错机制.RDD的转换关系,构成了compute chain,可以把这个compute chain认为是RDD之间演化的Lineage.在部分计算结果 ...
- Spark RDD概念学习系列之RDD的缓存(八)
RDD的缓存 RDD的缓存和RDD的checkpoint的区别 缓存是在计算结束后,直接将计算结果通过用户定义的存储级别(存储级别定义了缓存存储的介质,现在支持内存.本地文件系统和Tachyon) ...
- Spark RDD概念学习系列之RDD的操作(七)
RDD的操作 RDD支持两种操作:转换和动作. 1)转换,即从现有的数据集创建一个新的数据集. 2)动作,即在数据集上进行计算后,返回一个值给Driver程序. 例如,map就是一种转换,它将数据集每 ...
- Spark RDD概念学习系列之RDD的缺点(二)
RDD的缺点? RDD是Spark最基本也是最根本的数据抽象,它具备像MapReduce等数据流模型的容错性,并且允许开发人员在大型集群上执行基于内存的计算. 为了有效地实现容错,(详细见ht ...
随机推荐
- nodejs框架express4.x 学习--安装篇
一.安装建立项目 1.安装nodejs 2.安装express(全局) npm install -g express 默认安装的是4.12.4 3.由于在3.6版本之后项目构建器被单独拆分出来,所以还 ...
- POJ_1088 滑雪(记忆型DP+DFS)
Description Michael喜欢滑雪,这并不奇怪, 因为滑雪的确很刺激.可是为了获得速度,滑的区域必须向下倾斜,而且当你滑到坡底,你不得不再次走上坡或者等待升降机来载你.Michael想知道 ...
- VS2008中MFC界面编程Caption中文全是乱码的解决办法 -转载
一.问题 在预览状态下可能看到中文,但是编译运行后对话框中的中文全是问号.即使你用的VS中文版,即使你也用了Unicode编码,即使有条件编译 #ifdef _WIN32LANGUAGE LANG_C ...
- Photon引擎开发实战(1)——Photon 简介
Photon简介 Photon是一套使用广泛的socket server引擎,服务端底层C++编写,客户端C#编写,跨多平台,收费,效率可观的一款引擎.实用上前有九城游戏(原魔兽世界代理),现在笔者发 ...
- 解决GDB输出Qt内置类型的显示问题
自从GDB 7.0之后,就加入了Pretty-Printer的这个概念.简单理解就是他可以让你用Python写一串脚本,然后让gdb去读取这串脚本后,可以自由的输出由你想自己定义的格式.我们直接举个简 ...
- 求LR(0)文法的规范族集和ACTION表、GOTO表的构造算法
原理 数据结构 // GO private static Map<Map<Integer,String>,Integer> GO = new HashMap<Map< ...
- python中os模块的常用接口和异常中Exception的运用
1.os.path.join(arg1, arg2) 将arg1和arg2对应的字符串连接起来并返回连接后的字符串,如果arg1.arg2为变量,就先将arg1.arg2转换为字符串后再进行连接. 2 ...
- 实用lsof常用命令行
1, 使用 lsof 命令行列出所有打开的文件 # lsof 这可是一个很长的列表,包括打开的文件和网络 上述屏幕截图中包含很多列,例如 PID.user.FD 和 TYPE 等等. FD - Fil ...
- Java POI 导出EXCEL经典实现 Java导出Excel
转自http://blog.csdn.net/evangel_z/article/details/7332535 在web开发中,有一个经典的功能,就是数据的导入导出.特别是数据的导出,在生产管理或者 ...
- 当用DJANGO的migrate不成功时。。。。
URL:http://my.oschina.net/u/862582/blog/355421 因为操作SQL数据库时不规范,或是多人开发时产生了同步问题,就可能导致正规的MIGRATE时不能完成. 已 ...