sicp第1章
牛顿迭代法求平方:
(define (sqrt-iter guess x)
(if (good-enough? guess x)
guess
(sqrt-iter (improve guess x) x)
)
)
(define (improve guess x)
(average guess (/ x guess)))
(define (average x y)
(/ (+ x y) ))
(define (square x) (* x x))
(define (good-enough? guess x)
(< (abs (- (square guess) x)) 0.001)) (define (sqrt x)
(sqrt-iter 1.0 x))
习题1.6:
以下是 Alyssa 的 new-if 定义:
;;; 6-new-if.scm (define (new-if predicate then-clause else-clause)
(cond (predicate then-clause)
(else else-clause)))
把if换成new-if可以吗?
先使用 new-if 重写平方根过程:
;;; 6-sqrt-iter.scm (load "6-new-if.scm") (load "p15-good-enough.scm") ; 定义平方根用到的其他函数
(load "p15-improve.scm")
(load "p16-sqrt.scm") (define (sqrt-iter guess x)
(new-if (good-enough? guess x) ; <-- new-if 在这里
guess
(sqrt-iter (improve guess x)
x)))
然后将程序放进解释器尝试求值:
1 ]=> (load "6-sqrt-iter.scm") ;Loading "6-sqrt-iter.scm"...
; Loading "6-new-if.scm"... done
; Loading "p15-good-enough.scm"... done
; Loading "p15-improve.scm"...
; Loading "p15-average.scm"... done
; ... done
; Loading "p16-sqrt.scm"...
; Loading "p15-sqrt-iter.scm"...
; Loading "p15-good-enough.scm"... done
; Loading "p15-improve.scm"...
; Loading "p15-average.scm"... done
; ... done
; ... done
; ... done
;... done
;Value: sqrt-iter 1 ]=> (sqrt 9) ;Aborting!: maximum recursion depth exceeded
解释器抱怨说函数的递归层数太深了,超过了最大的递归深度,它不能处理这样的函数。
问题出在 sqrt-iter 函数,如果使用 trace 来跟踪它的调用过程的话,就会发现它执行了大量的递归调用,这些调用数量非常庞大,最终突破解释器的栈深度,造成错误:
1 ]=> (trace sqrt-iter) ;Unspecified return value 1 ]=> (sqrt 9) ; ... [Entering #[compound-procedure 11 sqrt-iter]
Args: 3.
9] [Entering #[compound-procedure 11 sqrt-iter]
Args: 3.
9] [Entering #[compound-procedure 11 sqrt-iter]
Args: 3.
9] ; ... [Entering #[compound-procedure 11 sqrt-iter]
Args: 3.
9]
^Z
[1]+ 已停止 mit-scheme
至于造成 sqrt-iter 函数出错的原因,毫无疑问就是新定义的 new-if 了。
根据书本 12 页所说, if 语句是一种特殊形式,当它的 predicate 部分为真时, then-clause 分支会被求值,否则的话, else-clause 分支被求值,两个 clause 只有一个会被求值。
而另一方面,新定义的 new-if 只是一个普通函数,它没有 if 所具有的特殊形式,根据解释器所使用的应用序求值规则,每个函数的实际参数在传入的时候都会被求值,因此,当使用 new-if 函数时,无论 predicate 是真还是假, then-clause 和 else-clause 两个分支都会被求值。
可以用一个很简单的实验验证 if 和 new-if 之间的差别,如果使用 if 的话,那么以下的代码只会打印 good :
1 ]=> (if #t (display "good") (display "bad"))
good
;Unspecified return value
如果使用 new-if 的话,那么两个语句都会被打印:
1 ]=> (new-if #t (display "good") (display "bad"))
badgood
;Unspecified return value
这就说明了为什么用 new-if 重定义的 sqrt-iter 会出错:因为无论测试结果如何, sqrt-iter 都会一直递归下去。
当然,单纯的尾递归并不会造成解释器的栈溢出,因为 scheme 解释器的实现都是带有尾递归优化的,但是在 new-if 的这个例子里,因为 sqrt-iter 函数的返回值要被new-if 作为参数使用,所以对 sqrt-iter 的调用并不是尾递归,这样的话,尾递归优化自然也无法进行了,因此 new-if 和 sqrt-iter 的递归会最终突破解释器的最大递归深度,从而造成错误:
(define (sqrt-iter guess x)
(new-if (good-enough? guess x) ; <- sqrt-iter 的返回值还要作为 new-if 的参数,因此 sqrt-iter 的调用不是尾递归
guess
(sqrt-iter (improve guess x) ; <- 无论 good-enough? 的结果如何
x))) ; 这个函数调用都会被一直执行下去
Note
你可能对 new-if 的输出感到疑惑,为什么 “bad” 会在 “good” 之前输出?事实是,函数式编程语言的解释器实现一般对参数的求值顺序并没有特定的规则,从左向右求值或从右向左求值都是可能的,而这里所使用的 MIT Scheme 使用从右往左的规则,仅此而已,使用不同的 Scheme 实现,打印的结果可能不同。(racket是从左向右)。
ICP的1.2.2节里提到了一个换零钱的问题
给了半美元(1美元100美分)、四分之一美元、10美分、5美分和1美分的硬币,将1美元换成零钱,一共有多少种不同方式?
书里给了一个树形递归的解法,思路非常简单,把所有的换法分成两类,包含50美分的和不包含的。包含50美分的换法里,因为它至少包含一张50美分,所以它的换法就相当于用5种硬币兑换剩下的50美分的换法;不包含50美分的,只能用4种硬币兑换1美元。这样用5种硬币兑换1美元就等价于用5种硬币兑换50美分的换法加上用前4种硬币兑换1美元的换法。以次类推,用4种硬币兑换1美元的换法就等价于用4种硬币兑换75美分的换法加上用3种硬币兑换1美元的换法。
假设用1种硬币求换法数量的函数是f(n),用2种的是g(n),3种的是h(n),4种的是i(n),5种的是j(n),那么
j(100) = j(50) + i(100)
j(50) = j(0) + i(50)
j(0) = 1 #有1种兑法兑换0元,那就是一个硬币都没有
i(100) = i(75) + h(100)
i(75) = i(50) + h(75)
i(50) = i(25) + h(50)
i(25) = i(0) + h(25)
i(0) = 1;求兑换零钱方式
(define (cc amount kinds-of-coins)
(cond
[(= amount ) ]
[(or (< amount ) (= kinds-of-coins )) ]
[else (+ (cc amount (- kinds-of-coins ))
(cc (- amount (first-denomination kinds-of-coins)) kinds-of-coins)) ]
)
) (define (first-denomination kinds-of-coins)
(cond [(= kinds-of-coins ) ]
[(= kinds-of-coins ) ]
[(= kinds-of-coins ) ]
[(= kinds-of-coins ) ]
[(= kinds-of-coins ) ])) (define (count-change amount)
(cc amount )
)
(count-change ) ;292
这个算法非常的简单,但是它的效率很低,有大量的重复计算,比如i(50),它的时间复杂度是指数级的,在我的电脑上(2.2GHz i7)计算500块就需要15秒了,根本不实用。书中给读者留了一个挑战,找出线性迭代的解法。这是个难的问题,我在Stackoverflow上找到了一点思路,用动态规划的方法从0到100“推”出结果。这个算法的核心思想跟之前的递归其实是一样的,只不过是反过来推,先算出f(1)到f(100)(都是1),将所有的结果保存到一个数组里,再算g(1)到g(100),保存到另一个数组里,因为计算g(n)所需要的数据g(n-5)和f(n)都已经准备好了,这样就可以避免重复的计算。接着再算h(1)到h(100),i(1)到i(100),最后是j(1)到j(100)。程序如下
(define coins (list ))
(define (current-coin coins)
(car coins))
(define (rest-coins coins)
(cdr coins))
(define (empty-coin? coins)
(= (length coins) )) (define current-counts (list ))
(define prev-counts '())
(define (add-count counts new-count)
(append counts (list new-count)))
(define (get-count counts amount)
(cond ((< amount ) )
((>= amount (length counts)) )
(else (list-ref counts amount)))) (define (cc total coins amount current prev)
(cond ((empty-coin? coins) (get-count prev total))
((<= amount total)
(let ((last-count (get-count current (- amount (car coins))))
(prev-count (get-count prev amount)))
(cc total coins (+ amount ) (add-count current (+ last-count prev-count)) prev)))
(else (cc total (rest-coins coins) (list ) current)))) (cc coins current-counts prev-counts)
这种解法只需要循环5遍就可以得到结果,所以它的时间复杂度是O(n),比书中的例子快多了。但是因为它至少需要保存两个长度为n的数组,所以它的空间复杂度也是O(n),还不能算是线性迭代的解法,因为它要求空间复杂度是O(1)。 我们再仔细观察下这个动态规划的过程,可以发现,当我们从1推到100的过程中,有很多值是没必要存储的。
j(100)=j(50)+i(100)
j(50)=j(0)+i(50)
j(0)=1
i(100)=i(75)+h(100)
i(75)=i(50)+h(75)
i(50)=i(25)+h(50)
i(25)=i(0)+h(25)
i(0)=1
对于j(100),我们只需要存储j(50),j(25)和j(0) 对于i(100),我们只需要存储i(75),i(50),i(25)和i(0) 对于h(100),我们只需要存储h(90),h(80),h(70),h(60),…,h(10),h(0),但是为了辅助i(75),我们还需要多存h(75),h(65),…,h(5) 对于g(100),我们只需要存储g(95),g(90)直到g(5),g(0)
如果我们改变下循环的次序,先计算f(0)到j(0),再计算f(5)到j(5),接着是f(10)到j(10),最后f(100)到j(100),这样就可以节省很多不必要的空间。当我们计算j(100)时,j(25)对我们来说已经没有意义了,我们只需要知道j(50)就够了,计算i(100)时,只用i(75)也就够了,所以对于每一个函数,都只用保存一个值。但一个值其实是不够的,我们可以从h(0)推到h(10)再推到h(100),但是没法从h(0)推到h(75),只能从h(5)开始推起,所以对于函数h,我们需要保存两个值,一个用于推出h(100),一个用于推出h(75)。为什么i不需要保存两个值呢,因为50是25的整数倍,所以当我们推导i的时候,会自动包含h所需要的值,而25并不是10的整数倍,所以需要为其单独保存一个值。这里不管是哪个函数我们都是从0开始推的,因为0是100除以所有硬币的余数,当我们要算99块钱的兑法时,就不能从0开始了,对于j,我们需要知道j(49),对于i,我们则需要知道i(24),而对于h,则需要h(9)和h(4)了,h(4)怎么算出来的呢,(99-25)%10。所以对于每一个函数,我们只需要保存最多两个值就够了,一个推出f(n),一个推出f(n-V),这里的V是下一种硬币的面值。
我用两个长度为硬币种数的数组来保存计算结果,一个是用来保存f(n)到j(n)的counts,一个是用来保存f(n-Vg)到i(n-Vj)的counts-alt。
(define coins (list ))
(define (coin index)
(list-ref coins index)) (define (append-count count coinIndex value)
(define (ac head tail index)
(cond ((< index coinIndex)
(cond ((= (length tail) )
(ac (append head (list )) (list ) (+ index )))
((= (length tail) )
(ac (append head (list (car tail))) (list ) (+ index )))
((> (length tail) )
(ac (append head (list (car tail))) (cdr tail) (+ index )))))
((= index coinIndex)
(if (= (length tail) )
(append head (list value))
(append head (list (+ (car tail) value)) (cdr tail))))))
(ac '() count 0)) (define (cal-count index amount coinIndex counts counts-alt)
(if (= (remainder index (coin coinIndex)) (remainder amount (coin coinIndex)))
(if (= coinIndex )
(if (= index )
(append-count counts coinIndex )
counts)
(cond ((= (remainder index (coin (- coinIndex ))) (remainder amount (coin (- coinIndex ))))
(append-count counts coinIndex (list-ref counts (- coinIndex ))))
((= (remainder index (coin (- coinIndex ))) (remainder (- amount (coin coinIndex)) (coin (- coinIndex ))))
(append-count counts coinIndex (list-ref counts-alt (- coinIndex ))))))
counts)) (define (cal-count-alt index amount coinIndex counts counts-alt)
(if (and (< coinIndex (- (length coins) )) (= (remainder index (coin coinIndex)) (remainder (- amount (coin (+ coinIndex ))) (coin coinIndex))))
(if (= coinIndex )
(if (= index )
(append-count counts-alt coinIndex )
counts-alt)
(cond ((= (remainder index (coin (- coinIndex ))) (remainder amount (coin (- coinIndex ))))
(append-count counts-alt coinIndex (list-ref counts (- coinIndex ))))
((= (remainder index (coin (- coinIndex ))) (remainder (- amount (coin coinIndex)) (coin (- coinIndex ))))
(append-count counts-alt coinIndex (list-ref counts-alt (- coinIndex ))))))
counts-alt)) (define (cc index amount coinIndex counts counts-alt)
(if (< coinIndex (length coins))
(cc index amount (+ coinIndex ) (cal-count index amount coinIndex counts counts-alt) (cal-count-alt index amount coinIndex counts counts-alt))
(if (= index amount)
(list-ref counts (- coinIndex ))
(cc (+ index ) amount counts counts-alt)))) (cc '() '())
c是主函数,有两层循环,外层循环从0到100,内层循环从1美分到50美分,对于每一个index,都计算一次包含当前coinIndex的情况下,有多少种换法,由counts或counts-alt里已计算好的值来得出。
append-count是一个辅助函数,用来更新数组,当index超出数组长度时,自动补零。
cal-count计算f(n)到j(n)的counts,cal-count-alt计算f(n-Vg)到i(n-Vj)的counts-alt。这两个函数的逻辑基本上一样的,只是计算新值的条件不同。在index从0涨到100的过程中,假设coinIndex为3,即10美分,只有当index除以10的余数和100除以10的余数相同时,才会计算新的counts,否则不用计算,因为h(20)=h(10)+g(20),h(11)到h(19)对我们来说都没意义。每次计算counts里某个coinIndex的值时,都是由现有的值加上一个counts或counts-alt里coinIndex-1的值,是counts还是counts-alt取决于余数的状态。计算counts-alt时,则是考虑当前coinIndex的值是否对coinIndex+1有用,也是通过余数来比较。
这个版本的算法空间上的需求是O(1),满足线形迭代的要求,在计算较大数目的时候不管是时间还是空间的优势都很明显,但是理解起来就比树形递归那个难多了。
以上转自:http://blog.pengqi.me/2012/06/07/sicp-making-change/
- 用了最大的面额的,减去最大面额的值,递归。
- 没有用最大面额兑换的,不考虑最大的面额,递归。
然后这样就会展开一个二叉树,其中树叶的数量就是总数,可以画图来看一下:
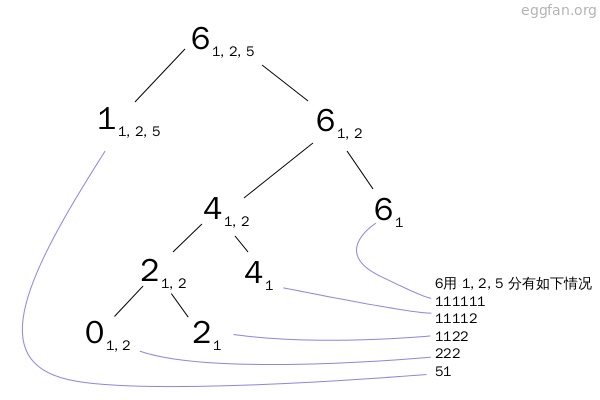
这张图是用这样的方法,用1, 2, 5 去划分 6的情况。每个节点的左枝是第一种方法所递归的,右枝是第二种。(update: 之前这里左右搞反了。)
然后蓝色的线就代表每个叶子所对应的排列方式。
迭代:
n =
v = [, , , , ]
L = [i== for i in range(n+)]#内容为true,false,flase.......... for i in range(len(v)): #零钱种类
for j in xrange(v[i], len(L)):
L[j] += L[j - v[i]]
print L[n]
另外答:
代码如下
#include <iostream>
#include <cstdio>
#include <cstring>
using namespace std;
int ans[1005][10];
int first_denomination[100] = {0, 1, 5, 10, 25, 50};
int cc(int amount, int kinds_of_coins)
{
if(amount == 0)
return 1;
else if(amount < 0 || kinds_of_coins == 0)
return 0;
else if(ans[amount][kinds_of_coins] >= 0)
return ans[amount][kinds_of_coins];
else
return ans[amount][kinds_of_coins] = cc(amount, kinds_of_coins - 1) +
cc(amount - first_denomination[kinds_of_coins], kinds_of_coins);
}
int main()
{
memset(ans, -1, sizeof(ans));
cout << cc(100, 5) << endl;
}
即使数据增加10倍,还是能在1秒内算出结果。
使用迭代或者递推的话,大概就是根据递归树,自底向上计算。
代码如下:
#include <iostream>
#include <cstdio>
#include <cstring>
using namespace std;
int ans[105][10];
int V[10] = {0, 1, 5, 10, 25, 50};
int get(int i, int j)
{
if(i == 0)
return 1;
if(i < 0 || j == 0)
return 0;
return ans[i][j];
}
int cc(int S, int N)
{
for(int i = 0; i <= S; i++)
for(int j = 1; j <= N; j++)
ans[i][j] = get(i, j - 1) + get(i - V[j], j);
return ans[S][N];
}
int main()
{
memset(ans, 0, sizeof(ans));
cout << cc(100, 5) << endl;
}
这个问题和动态规划的还是有点区别的。动态规划主要用来解决最优化问题,算出来的结果往往是一个最优方案。对于找零钱问题来说,要找出使用硬币数目最少或者最多的方案,这时候就适合使用动态规划。而这个问题要求的是总的方案数,就需要找出所有的方案,然后累加
参考:http://www.zhihu.com/question/22219036、
练习题有一道类似:
练习2.32
这个题目比较有意思:集合的子集所构成的集合等于除去第一个元素外的剩余元素构成的集合的子集的集合并上一定包含第一个元素的集合所构成的集合。
(我快被自己写的这句话搞晕了,不过它却是正确的)
要想很简单地理解这道题,我们得复习一下1.2.2节中的“换零钱问题”:我们说, 换取零钱的总方式数 等于 不包含第一种面值的硬币时的方式数 加上 一定包含第一种面值时的方式数 ,这是因为任何一种方式中那么包含第一种面值,要么不包含,所以可以以这个为依据将换零钱方式归为两类,这两类方式之和则是总的方式数。
用数学公式表示一下:
S(L, a) = S(M, a) + P(L, a)
其中S表示求换零钱方式的函数,P表示必须包含第一种面值时换零钱方式的函数,L表示全体面值的集合(或列表) , M表示除去第一中面值后由集合剩余元素构造的集合,a表示需要被换成零钱的现金总额。我们会发现在P(L, a) 中,“将数量为a的现金换成必须包含第一种面值时换零钱方式数” 和 “将数量为(a-d)的现金换成有可能包含第一种面值时的换零钱方式数”是相等的,其中d是第一种面值(的数量值),因为我们可以将前者的包含了第一种面值的方式中都拿出一颗第一种面值的硬币。
那么上面的公式就可以改写成:
S(L, a) = S(M, a) + S(L, a-d)
这个公式也就是SICP课本中在换零钱问题上所提到的那个计算方法。
至此,换零钱问题你应该完全理解了。
OK,回到集合问题上来。
与换零钱问题很相似:在所有的子集中,这些子集那么包含第一个元素,要么不包含,他们的并集构成了我们所要的答案。在看题目给出的代码片段似乎在暗示我们所说的观点是正确的:
(define (subsets s)
(if (null? s)
(list '())
(let ((rest (subsets (cdr s))))
(append rest (map <???> rest)))))
代码片段中的 rest 也就是我们上面所说的“不包含第一个元素”的子集所构成的集合。而 (append rest (map <???> rest))) 要片段要在其后追加一些东西,稍稍想以下,集合的append似乎和“并集”比较神似,对,其就是要将那些“一定包含了第一个元素”的子集所构成的集合追加到后面。
那么如何求“一定包含了第一个元素”的子集所构成的集合呢?
又回到换换零钱问题上进行类比,我们将一定包含了第一种面值的方式中取了一颗第一种面值的硬币出来,其就变成了可能包含第一种面值,那么反过来,在任何一种方式中,如果我们放入一颗第一种面值的硬币,那么它一定包含了第一种面值(废话)。呵呵呵,应用到这个问题上就是:在 rest 中的每一个集合中 追加原集合的第一个元素,那么它就“一定包含了第一个元素”,这就是我们的解法,所以,代码如下:
(define (subsets s)
(if (null? s)
(list '())
(let ((rest (subsets (cdr s))))
(append rest (map
(lambda (x)
(let ((firstOne (list (car s))))
(append firstOne x)))
rest)))))
;test
(define theSet '(1 2 3))
(subsets theSet)
'(() (3) (2) (2 3) (1) (1 3) (1 2) (1 2 3))
参考:http://www.cnblogs.com/zhouyinhui/archive/2009/11/04/1596080.html
http://zhoushijingguo.blog.163.com/blog/static/15359663620114801844853/
Exercise 1.11. A function f is defined by the rule that f(n) = n if n<3 and f(n) = f(n - 1) + 2f(n - 2) + 3f(n - 3) if n> 3. Write a procedure that computes f by means of a recursive process. Write a procedure that computes f by means of an iterative process.
迭代还不太清楚怎么写,
要写出函数 f 的迭代版本,关键是在于看清初始条件和之后的计算进展之间的关系,就像书本 25-26 页中,将斐波那契函数从递归改成迭代那样。
根据函数 f 的初始条件『如果 n<3 ,那么 f(n)=n 』,有等式:
f(0)=0
f(1)=1
f(2)=2
另一方面, 根据条件『当 n≥3 时,有 f(n)=f(n−1)+2f(n−2)+3f(n−3) 』,如果继续计算下去,一个有趣的结果就会显现出来:
f(3)=f(2)+2f(1)+3f(0)
f(4)=f(3)+2f(2)+3f(1)
f(5)=f(4)+2f(3)+3f(2)
…
可以看出,当 n≥3 时,所有函数 f 的计算结果都可以用比当前 n 更小的三个 f 调用计算出来。
迭代版的函数定义如下:它使用 i 作为渐进下标, n 作为最大下标, a 、 b 和 c 三个变量分别代表函数调用 f(i+2) 、 f(i+1) 和 f(i) ,从 f(0) 开始,一步步计算出 f(n) :
;; -iter.scm (define (f n)
(f-iter n)) (define (f-iter a b c i n)
(if (= i n)
c
(f-iter (+ a (* b) (* c)) ; new a
a ; new b
b ; new c
(+ i )
n)))
两个 f 函数不仅使用的计算方式不同(前一个递归计算,另一个迭代计算),而且效率方面也有很大的不同。
递归版本的函数 f 有很多多余的计算,比如说,要计算 f(5) 就得计算 f(4) 、 f(3) 和 f(2) ,而计算 f(4) 又要计算 f(3) 、 f(2) 和 f(1) 。
对于每个 f(n) 调用,递归版 f 函数都要执行 f(n−1) 、 f(n−2) 和 f(n−3) ,而 f(n−1) 的计算又重复了对 f(n−2) 和 f(n−3) 的计算,因此,递归版本的 f 函数是一个指数级复杂度的算法(和递归版本的斐波那契数函数类似)。
另一方面,迭代版本使用三个变量储存 f(n−1) 、 f(n−2) 和 f(n−3) 的值,使用自底向上的计算方式进行计算,因此迭代版的函数 f 没有多余的重复计算工作,它的复杂度正比于 n ,是一个线性迭代函数。
See also
查看维基词条 Dynamic Programming 了解更多关于自底向上计算的信息。
Warning
习题1.12
这道练习的翻译有误,原文是『...Write a procedure that computes elements of Pascal’s triangle by means of a recursive process.』,译文只翻译了『。。。它采用递归计算过程计算出帕斯卡三角形。』,这里应该是『帕斯卡三角形的各个元素』才对。
使用示例图可以更直观地看出帕斯卡三角形的各个元素之间的关系:
row:
0 1
1 1 1
2 1 2 1
3 1 3 3 1
4 1 4 6 4 1
5 . . . . . .
col: 0 1 2 3 4
如果使用 pascal(row, col) 代表第 row 行和第 col 列上的元素的值,可以得出一些性质:
- 每个 pascal(row, col) 由 pascal(row-1, col-1) (左上边的元素)和 pascal(row-1, col) (右上边的元素)组成
- 当 col 等于 0 (最左边元素),或者 row 等于 col (最右边元素)时, pascal(row, col) 等于 1
比如说,当 row = 3 , col = 1 时, pascal(row,col) 的值为 3 ,而这个值又是根据 pascal(3-1, 1-1) = 1 和 pascal(3-1, 1) = 2 计算出来的。
综合以上的两个性质,就可以写出递归版本的 pascal 函数了:
;;; 12-rec-pascal.scm (define (pascal row col)
(cond ((> col row)
(error "unvalid col value"))
((or (= col 0) (= row col))
1)
(else (+ (pascal (- row 1) (- col 1))
(pascal (- row 1) col)))))
pascal三角形模式:http://ptri1.tripod.com/
要想把这个转成迭代,利用上面的计算公式做不到,可以换一个公式,参考:http://sicp.readthedocs.org/en/latest/chp1/12.html
1.13证明:

sicp第1章的更多相关文章
- SICP第三章题解
目录 SICP第三章题解 ex3-17 ex3-18 ex3-19 队列 ex3-21 ex3-22 ex3-24 ex3-25 3.4 并发:时间是一个本质问题 ex3-38 3.4.2 控制并发的 ...
- SICP 习题(1.1,1.2,1.3,1.4)解题总结。
近来在重读SICP,以前读过一次,读了第一二章就没有坚持下去,时间一长就基本忘记了,脑海里什么都不剩,就隐约记得自己曾经读过一本很牛B的书. 这次读希望能够扎实一点,不管能读到哪里,希望可以理解一些东 ...
- [LeetCode] Pow(x, n)
Implement pow(x, n). 有史以来做过最简单的一题,大概用5分钟ac,我采用fast exponential,这个在sicp的第一章就有描述.思想是:如果n是偶数的话,那么m^n = ...
- Python和Lua的默认作用域以及闭包
默认作用域 前段时间学了下Lua,发现Lua的默认作用域和Python是相反的.Lua定义变量时默认变量的作用域是全局(global,这样说不是很准确,Lua在执行x = 1这样的语句时会从当前环境开 ...
- SICP— 第一章 构造过程抽象
SICP Structure And Interpretation Of Computer Programs 中文第2版 分两部分 S 和 I 第一章 构造过程抽象 1,程序设计的基本元素 2,过 ...
- [蛙蛙推荐]SICP第一章学习笔记-编程入门
本书简介 <计算机程序的构造与解释>这本书是MIT计算机科学学科的入门课程, 大部分学生在学这门课程前都没有接触过程序设计,也就是说这本书是针对编程新手写的. 虽然是入门课程,但起点比较高 ...
- SICP 习题解 第二章
计算机程序的构造和解释习题解答 Structure and Interpretation os Computer Programs Exercises Answer 第二章 构造数据抽象 练习2.17 ...
- Lisp和SICP
大概不少programmer都看过<黑客与画家>,作者用了整整一章的篇幅讨论Lisp的强大.我自然就会手痒痒. 几个月前,几天内攻城略地搞定了Python,用的方法便是 ...
- 【SICP感应】3
级数据和符号数据
在本书的第二章学习时,有一个问题我一直很困扰,那是2.2.4举例节.因为没有华丽的输出模式书,它只能有一个对的英文字母.两三个月的这浅浅的学校前Common Lisp同样是真实的,当.了非常赞的线条, ...
随机推荐
- 关于 Android 进程保活,你所需要知道的一切
早前,我在知乎上回答了这样一个问题:怎么让 Android 程序一直后台运行,像 QQ 一样不被杀死?.关于 Android 平台的进程保活这一块,想必是所有 Android 开发者瞩目的内容之一.你 ...
- 编写android的widget
以前对这个东西很感兴趣,因为确实方便,如今有时间了来做一个例子 首先要定义一个layout(widgetview.xml)和一个配置文件(widgetconfig.xml) <?xml vers ...
- Extending Robolectric
Robolectric is a work in progress, and we welcome contributions from the community. We encourage dev ...
- windows 环境下mysql 如何修改root密码
windows 环境下mysql 如何修改root密码 以windows为例: 无法开启服务,将mysql更目录下的data文件夹清空,然后调用 mysqld --initialize 开启mysql ...
- SQLCLR
hsrzyn SQLCLR 什么是SQLCLR SQL CLR (SQL Common Language Runtime) 是自 SQL Server 2005 才出现的新功能,它将.NET Fr ...
- Javascript绝句欣赏
1. 取整同时转成数值型: '10.567890'|0 结果: 10 '10.567890'^0 结果: 10 -2.23456789|0 结果: -2 ~~-2.23456789 结果: -2 2. ...
- 处理ASP.NET 请求(IIS)
原文:http://www.cnblogs.com/hkncd/archive/2012/03/23/2413917.html 英文原文:Beginner’s Guide: How IIS Proce ...
- web前端:js
内嵌样式<script></script> alert(“123”)弹出对话框 document.write(“test”) 引入方式 <title></ti ...
- [原创] SQLite数据库使用清单(下)
上文两章对SQLite的功能.语法.和操作进行了介绍,本文讲解SQLite的一些高级语法和操作. 3.
- Log4j简单配置
Log4j是一组强大的日志组件,在项目中时常需要用它提供一些信息,这两天学习了一下它的简单配置. 第一步,我们需要导入log4j-1.2.14.jar到lib目录下 第二步,在src下建立log4j. ...