Kernel methods on spike train space for neuroscience: a tutorial
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

时序点过程:http://www.tensorinfinity.com/paper_154.html
Abstract
在过去的十年中,人们提出了几个正定核来处理Hilbert空间中的脉冲序列。然而,在很大程度上,这种尝试仍然只是计算神经科学家和信号处理专家的好奇心。本教程说明了为什么核方法能够并且已经开始改变分析和处理脉冲序列的方式。这篇报告结合了简单的数学类比和令人信服的实际例子,试图展示正定函数量化点过程的潜力。它还详细概述了当前的最新现状和未来的挑战,希望能吸引读者积极参与。
I. INTRODUCTION
大脑中的信息处理是由一个复杂的神经元网络来完成的,这些神经元通过发送被称为动作电位(脉冲)的可靠的常规电脉冲进行通信。因此,信息在连续时间内以事件序列进行编码,而不是像在信号处理应用中常见的那样以信号的幅度进行编码(参见图1)。研究信息如何被表示和处理为脉冲序列,即神经编码问题,是神经科学面临的关键挑战之一。我们冒昧地说,如何在连续、无限维空间中表示信息的理论在信号处理和机器学习领域也远未被理解。鉴于目前信号处理的焦点是稀疏性,点处理(产生脉冲序列)非常吸引人,因为点处理提供了压缩感知下稀疏先验的自然限制情况,并且实现了最终的稀疏表示:系统仅在信息交叉时进行通信一些内部门槛。这种策略节省了能量,并且在时间上自然地提供了稀疏表示,因此不必花费昂贵的步骤来寻找替代空间来映射稀疏的输入数据。问题是系统变得不易观察,因此,用于预测、控制或以其他方式处理传入信息的算法效率较低,而且麻烦得多。工程文献中早期尝试将随机过程理论应用于过零分析(一种创建点过程的简单方法)始于40年代贝尔实验室的Rice,并在调频(FM)和散粒噪声中找到了应用。点过程理论主要在统计学文献[1]中发展,目前该理论是计算神经科学以及所有其他科学和工程领域中最广泛使用的量化脉冲训练的方法。点处理对于机器学习也很重要,特别是对于处理数据流的在线学习,因为向量空间既不能表示无限数据,也不能表示处理后得到的推理结构。
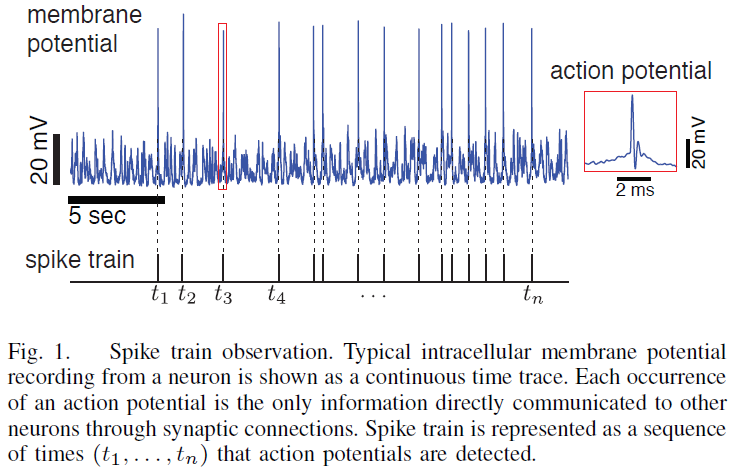
由于脉冲序列空间缺乏代数,给信号处理方法带来了许多挑战。然后,我们必须首先建立一个计算空间或转换为具有必要属性的空间。这里解释的方法是在脉冲序列上定义一个适当的核函数,以非参数地捕获感兴趣脉冲序列的时间结构和变异性。一旦定义了一个正定核,它就把脉冲序列映射到一个Hilbert函数空间,使得信号处理工具可以通过核技巧直接应用。这种方法有可能将数字信号处理的范围扩大到非数字对象,即我们可以对脉冲序列进行滤波,将其分解为主成分,并进行推理,与R中定义的时间序列完全相同。但更重要的是,核函数的使用为高斯过程、概率嵌入等众多先进的机器学习工具应用于脉冲序列提供了契机,为下一代脉冲序列信号处理开辟了新的前沿。
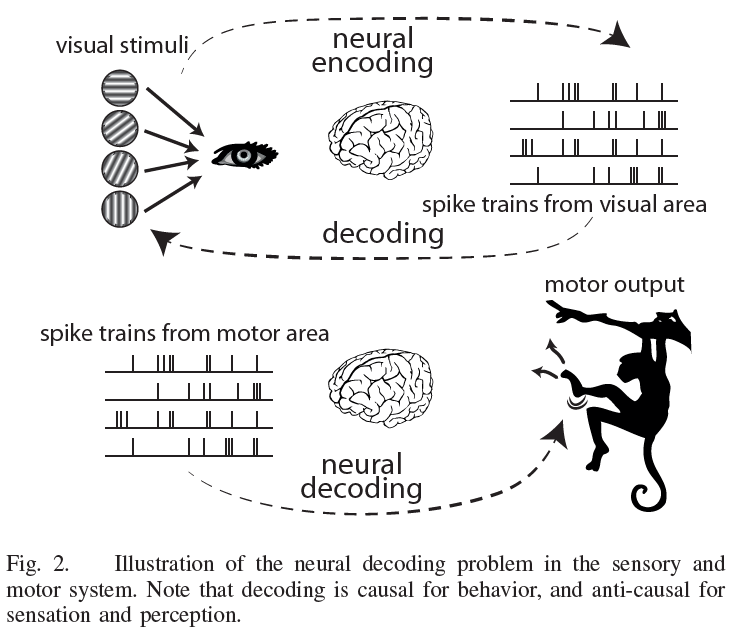
A. Neuroscience and neural engineering problems
神经编码的概念在感觉和运动系统中普遍存在,在这些系统中,感兴趣的变量是可以直接观察到的,尽管它在所有的神经交流中都是潜在的。在感觉系统中,我们常常想了解感觉刺激是如何在神经处理的每个阶段被编码和转换的。例如,视觉刺激从眼睛中的光感受器神经元,以及视网膜神经节细胞到视觉皮层的各个区域,刺激视觉通路中的一系列神经元。通过分析脉冲序列,我们可以理解刺激的某些方面是如何在这些神经元中处理和表达的[2]。神经编码的研究通常包括:
- 识别编码特定特征的神经元(神经元识别),以及
- 寻找被识别神经元的特征和脉冲序列之间的函数关系(神经编码/解码)。
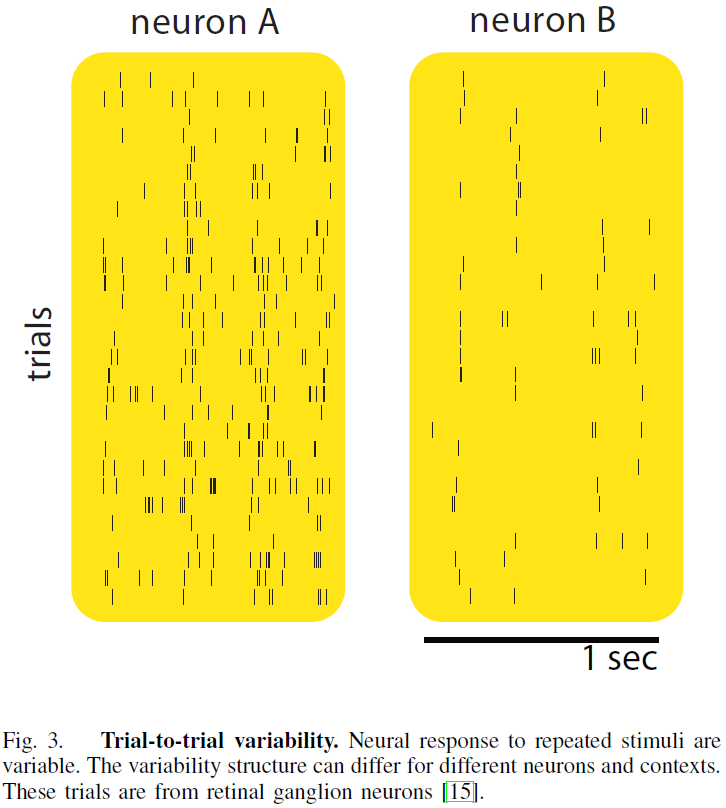
神经元识别的一个主要挑战是系统中的神经变异性,或者“噪声”。例如,当一个固定的刺激重复呈现给系统时,神经反应的试验-试验变异性通常是复杂的(见图3)。因此,要确定一个神经元是否为感兴趣的变量x编码,我们不能简单地比较单个试验反应,而是需要收集刺激条件分布p(spike train | x)的反应样本。幸运的是,信号检测理论和假设检验的工具可以通过核扩展到随机脉冲序列来解决神经识别问题(第III-A节)。
另一方面,一种更好的从脉冲序列中读出刺激的方法(神经解码)可以对许多临床和生物医学应用产生重大影响。例如,它可以改善广泛使用的人工耳蜗和正在积极发展中的视网膜和触觉假肢等感觉假肢[3-5]。在运动系统中,识别哪些神经元参与运动规划和控制,以及理解信息在脉冲序列中的表达方式,对于构建运动假肢至关重要[6-7]。类似的方法也被用于各种高级认知系统,如决策、记忆和语言[8]。
脉冲序列核为神经编码问题提供了替代工具(图2)。传统上,“rate code”一直是神经科学的主导思想[9-10],并且已经被反复的实验证明。rate code假说指出,平均脉冲计数编码了刺激的所有信息,即脉冲时间对神经处理没有用处。与rate code假设相反,也有充分的证据证明所谓的“时间编码”假设,即额外信息是在脉冲时间中编码的[11-13]。然而,神经科学界在很大程度上把时间编码的可能性降到了次要的地位,这可能是由于神经编码空间的大维度和统计方法的有限能力,这些方法直接在脉冲序列上运行,并有足够的能力发现新的模式。如果大脑在神经元之间以最佳方式处理和传递感官数据,一个自然的解决方案就是利用一种尽可能多地保留信息的表示法[14]。在这一推理过程中,时间假设应该是首选理论,因为它保证了信息的不丢失,并且解决了难题:在无法使用rate的情况下(当响应时间必须最小化时),脉冲时间是首选的,但是对脉冲时间敏感的表示可以很容易地通过集成来表示rate。实际上,rate和时间之间的争论也受到所需数学工具的复杂程度的影响:很难量化脉冲时间,而处理rate非常容易,因此,可能有许多实验观察证实了脉冲时间假说,但由于研究人员无法对其数据进行适当量化,因此这一假说从未发表过。脉冲序列核提供了一个研究脉冲序列的通用框架,可以同时容纳这两个假设,从而为这场争论提供了一个新的视角。我们希望,通过关注常见的问题,脉冲序列核方法可能会激发实验研究,以表明不同的神经元类是为不同的处理时间尺度而优化的,就像工程师为高速CMOS和采样保持电路设计不同的晶体管一样。
B. Kernels and kernel methods
RKHS(参考链接:https://blog.csdn.net/asd136912/article/details/79163368)
信号处理的实用性归功于对线性模型的巧妙开发。不幸的是,并非所有我们想要解决的问题都能很好地用线性模型来逼近。Hilbert空间方法[16],更具体地说是再生核Hilbert空间(RKHS)[17]将线性模型数学扩展到输入空间的非线性建模。该方法具有一定的原则性,因为它为处理不同类型的非线性问题提供了一种通用的方法,而且优化问题是凸的,而且该方法在计算复杂度方面仍然是实用的。但在我们看来,核方法对于神经信号处理的真正重要性在于它们将抽象对象映射到Hilbert空间的能力,Hilbert空间是一个具有内积的线性函数空间。事实上,神经科学量化脉冲序列的上述问题的核心是缺乏标准的代数运算,例如脉冲序列的线性投影和线性组合。这种映射提供了应用大多数信号处理工具所需的结构,并且还允许其他复杂的非线性计算。
再生核Hilbert空间的理论为一个(可能的)无限维Hilbert空间的存在提供了一个基础:一个特征空间与两个参数的任何正定函数相关,称为一个核[17-18]。让输入空间数据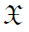 成为一个对象——例如,R3中的一个点、一个图或一个脉冲序列——和一个核
成为一个对象——例如,R3中的一个点、一个图或一个脉冲序列——和一个核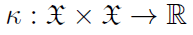 是在输入空间中定义的实值二元函数。输入样本
是在输入空间中定义的实值二元函数。输入样本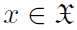 作为函数
作为函数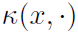 映射到RKHS(Reproducing Kernel Hilbert Space),因此核指定了变换的丰富性。核还定义了Hilbert空间的内积,即核
映射到RKHS(Reproducing Kernel Hilbert Space),因此核指定了变换的丰富性。核还定义了Hilbert空间的内积,即核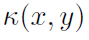 提供输入空间中任意两个样本x和y的函数图像的RKHS的相似性,并封装了关于输入空间结构的任何先验知识。此外,RKHS中两个函数的内积可以通过输入空间中的标量核来计算(核技巧),即
提供输入空间中任意两个样本x和y的函数图像的RKHS的相似性,并封装了关于输入空间结构的任何先验知识。此外,RKHS中两个函数的内积可以通过输入空间中的标量核来计算(核技巧),即 。这种性质带来了计算的简单性,因此我们有一个原则性的框架,允许非线性信号处理与线性算法,并使函数工作实用。
。这种性质带来了计算的简单性,因此我们有一个原则性的框架,允许非线性信号处理与线性算法,并使函数工作实用。
对于输入空间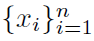 中的任何有限点集,得到的矩阵K,
中的任何有限点集,得到的矩阵K,

对于适当的核 ,即对于任意实向量x∈Rn,xTKx≥0,必须是对称且半正定的。给定中的数据,核矩阵K表示Hilbert空间中每对之间的内积。核矩阵在核方法算法中起着核心作用,因为对于大多数算法来说,它包含了输入所需的所有信息。
,即对于任意实向量x∈Rn,xTKx≥0,必须是对称且半正定的。给定中的数据,核矩阵K表示Hilbert空间中每对之间的内积。核矩阵在核方法算法中起着核心作用,因为对于大多数算法来说,它包含了输入所需的所有信息。
让我们来说明核设计的重要性,在我们显式地知道特征空间的实线上使用核映射。如果我们将x∈R映射到三维特征向量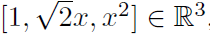 ,则特征空间中的线性回归对应于R中的二次拟合。等价地,这种二次拟合可以通过使用多项式核
,则特征空间中的线性回归对应于R中的二次拟合。等价地,这种二次拟合可以通过使用多项式核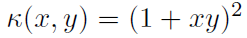 的核最小二乘来实现,而无需显式地构造特征空间[17]。这是因为最小二乘线性回归只需要Hilbert空间(线性组合,内积)提供的运算,多项式核是特征空间的内积。核方法的优点是避免了中间特征空间的表示(特别是在高维情况下)。
的核最小二乘来实现,而无需显式地构造特征空间[17]。这是因为最小二乘线性回归只需要Hilbert空间(线性组合,内积)提供的运算,多项式核是特征空间的内积。核方法的优点是避免了中间特征空间的表示(特别是在高维情况下)。
一个流行的核是高斯(即指数平方)核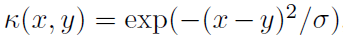 ,它隐式地对应于无限维特征空间。它捕捉实数线中的局部相似性;如果
,它隐式地对应于无限维特征空间。它捕捉实数线中的局部相似性;如果 ,则x和x+ε被认为是非常相似的,并且随着|ε|增大而逐渐变得不同。然而,选择σ是关键。当核大小参数σ趋于0时,它接近平凡核,对于x≠y,
,则x和x+ε被认为是非常相似的,并且随着|ε|增大而逐渐变得不同。然而,选择σ是关键。当核大小参数σ趋于0时,它接近平凡核,对于x≠y,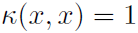 且
且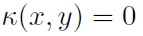 ,仍然将输入映射到无限维空间,其中每个映射的输入点彼此正交,因此特征空间没有泛化能力,基本上充当查找表。另一方面,如果σ大于数据的动态范围,高斯核基本上提供了参数的一个恒定映射,因此特征空间不能对距离进行不同的加权,也失去了区分不同点的能力。这两个示例核是极端的,不会带来任何好处。在实践中,我们使用一个介于两者之间的核(和核大小),它提供了一个具有适当平滑的丰富特征空间,使得实践者可以使用它在数据点之间进行非线性插值(例如,高斯核的σ尺度)。
,仍然将输入映射到无限维空间,其中每个映射的输入点彼此正交,因此特征空间没有泛化能力,基本上充当查找表。另一方面,如果σ大于数据的动态范围,高斯核基本上提供了参数的一个恒定映射,因此特征空间不能对距离进行不同的加权,也失去了区分不同点的能力。这两个示例核是极端的,不会带来任何好处。在实践中,我们使用一个介于两者之间的核(和核大小),它提供了一个具有适当平滑的丰富特征空间,使得实践者可以使用它在数据点之间进行非线性插值(例如,高斯核的σ尺度)。
II. SPIKE TRAIN KERNELS
在前一节中,我们讨论了实数线上的核方法,但是这个理论的优点是它可以应用于其他更抽象的空间。事实上,各种自然地表示为集合的离散对象(如图、集和字符串)已经通过核[19-21]成功地嵌入到Hilbert空间中,为使用合适的核时直接应用许多传统工具打开了大门。与高斯核的唯一区别是,我们现在需要一种方法来定义核,这种方法与测量脉冲序列之间的相似性相关。一旦完成,我们就可以在实数线上复制与高斯核相同的操作,也就是说,我们可以量化脉冲序列之间的相似性,并定义一个空间,在那里我们可以建立信号处理模型并进行推断。
在本节的剩余部分,我们将介绍几个重要的脉冲序列核,并讨论它们的优缺点。
A. Count and Binned Kernels
构造脉冲序列核的一种简单方法是,首先将脉冲序列映射到一个有限的、固定维数的欧氏空间,并使用其内积:x, y∈Rd,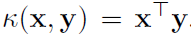 。例如,简单地计算每个脉冲序列的脉冲总数,就可以将脉冲序列映射为自然数(实数线的一个子集)。产生的核称为计数核。计数核完全忽略了时间,但它很有用,因为它包含了神经科学家所做的常规rate coding分析。例如,最优的最小二乘线性解码器等价于核最小二乘,平均rate差的检验等价于计数核的MMD(见第III-A节)。
。例如,简单地计算每个脉冲序列的脉冲总数,就可以将脉冲序列映射为自然数(实数线的一个子集)。产生的核称为计数核。计数核完全忽略了时间,但它很有用,因为它包含了神经科学家所做的常规rate coding分析。例如,最优的最小二乘线性解码器等价于核最小二乘,平均rate差的检验等价于计数核的MMD(见第III-A节)。
计数核的一个简单扩展是通过选择一系列连续的时间窗口(图4)来对脉冲序列进行容器划分。相邻的时间容器对应于不同的维度,因此核不会带来任何跨越容器边界的平滑。在精细时间容器划分的限制下,连续表示的所有信息都被保存在容器划分表示中,代价是巨大的维数。当与欧几里德内积结合时,这种情况下的容器划分是灾难性的,因为内积实现了一个查找表,就像前面提到的小核一样。另一方面,当容器大小较大时,尊重每个时间容器内的时间连续性,并提供一定的平滑度,然而,所得到的特征空间是低维的,并且脉冲序列中的时间细节不能完全表示。对于某些应用,有一个可能表现良好的容器大小,因为它可以部分提取与rate code假设相关的线性关系[22]。在脑机接口(BMI)[6]中流行的基于容器划分数据的线性模型就是这种技术的一个例子。

B. Spikernel
虽然直接将脉冲序列作为欧氏空间中的对象进行容器划分可能会产生误导,但使用这种表示方法可以构造出更好的核,但内积不同。神经科学的第一个成功核是spickernel[23],它属于这一类。它允许本地时间操作(时间扭曲)使相邻容器中的脉冲计数得到匹配,有效地平滑了容器边界。它还根据与感兴趣时间的距离对不同的时间段进行加权,这是基于神经系统有限记忆的合理假设。spikernel在脑机接口(从神经活动中解码运动信号)方面的性能已经被成功地证明优于容器划分计数核[23]。
一般来说,spikernel表现得健壮[24],但是,它根本上缺乏控制其时间精度的能力,因为它绑定到一个容器划分表示。此外,需要注意的是,spickernel的计算代价很高,它需要调整五个自由参数,包括容器大小。相对大量的自由参数提供了一个灵活的核,这是由它的性能所支持的,但是调整这些参数需要大量的优化,这阻碍了它的吸引力。
C. Linear functional kernels
如前所述,容器划分变换是有损失的,许多脉冲序列可以映射到相同的容器划分表示,而相似的脉冲序列可以映射到完全不同的表示。我们怎样才能避免容器划分,而把所有的信息进行保存,并创建一个正定核呢?一种解决方法是使用无限维表示[25]。
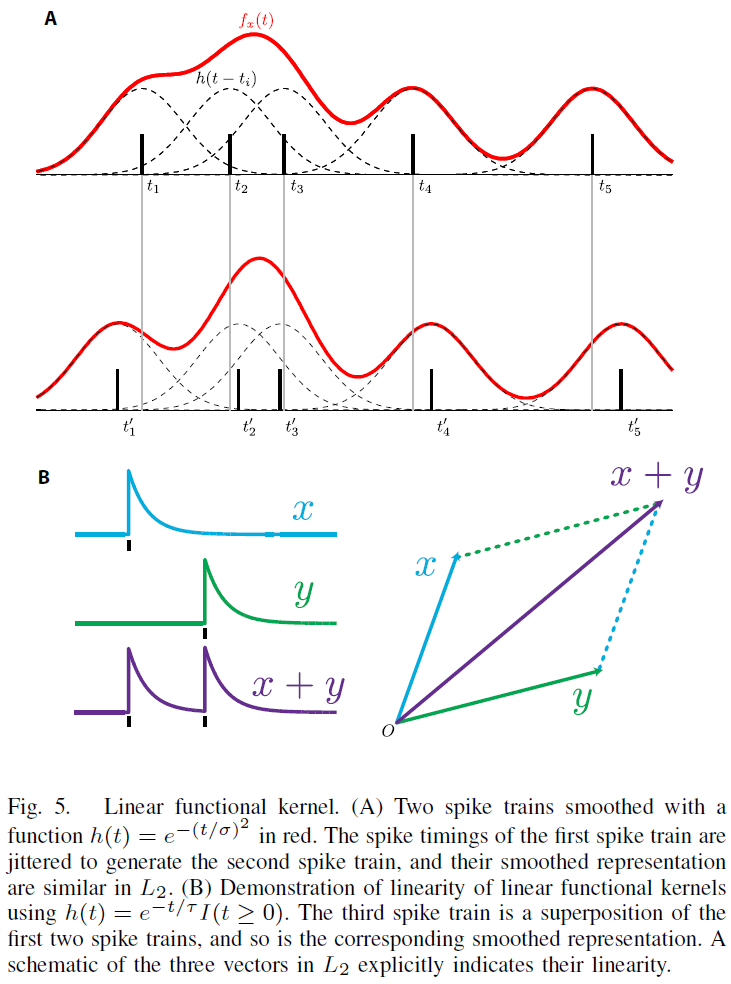
设h为线性滤波器随时间的有限能量脉冲响应(可能是非因果的),并将脉冲序列表示为Dirac δ函数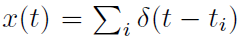 的和(非容器划分表示,见图4)。通过与非平凡h的卷积,每个脉冲序列可以唯一地转换为一个函数:
的和(非容器划分表示,见图4)。通过与非平凡h的卷积,每个脉冲序列可以唯一地转换为一个函数:
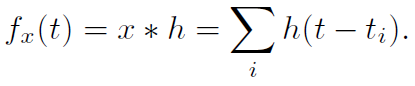 得到的转换脉冲序列fx(t)是L2空间中的一个函数,它本身就是一个Hilbert空间。L2中的内积定义为,
得到的转换脉冲序列fx(t)是L2空间中的一个函数,它本身就是一个Hilbert空间。L2中的内积定义为,

通过选择局部集中的h,具有类似小抖动的脉冲序列被映射到类似的函数(图5A)。因此,它对于小的时间扰动是连续的。线性函数核的简单定义是,
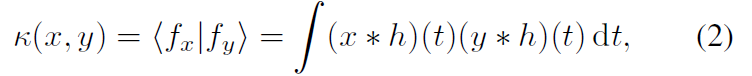
也就是说,L2中两个光滑函数表示的内积(图5)。注意(2)可以通过对所有脉冲的显式求和重写,
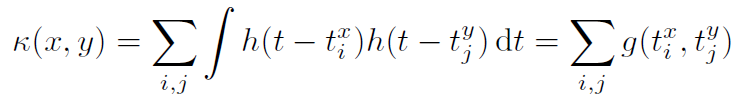
式中,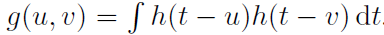 。因此,无穷维空间中的核求值可以用g的O(NxNy)函数求值来计算,其中Nx是脉冲序列x中的脉冲数目。
。因此,无穷维空间中的核求值可以用g的O(NxNy)函数求值来计算,其中Nx是脉冲序列x中的脉冲数目。
h的一些特殊选择值得注意[25-26]。如果平滑函数的形式为高斯函数,则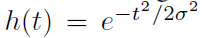 ,则
,则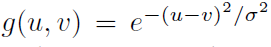 。更重要的是,如果平滑滤波器是一个因果指数衰减
。更重要的是,如果平滑滤波器是一个因果指数衰减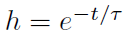 (t>0),我们得到以下核:
(t>0),我们得到以下核:
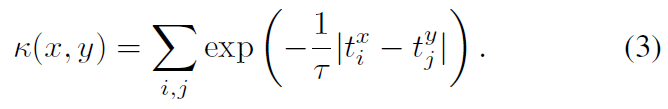 这个脉冲序列核有两个明显的优点。首先,它有一个神经生理学的解释,因为将脉冲序列转换为下游神经元中类似细胞内信号的突触传递函数可以近似为一阶动态系统(即一阶IIR滤波器)[27-28]。其次,它可以在O((Nx+Ny)log(Nx+Ny))时间内计算[25]。快速计算是由于双指数函数的性质[29]。
这个脉冲序列核有两个明显的优点。首先,它有一个神经生理学的解释,因为将脉冲序列转换为下游神经元中类似细胞内信号的突触传递函数可以近似为一阶动态系统(即一阶IIR滤波器)[27-28]。其次,它可以在O((Nx+Ny)log(Nx+Ny))时间内计算[25]。快速计算是由于双指数函数的性质[29]。
很容易看出线性函数核相对于脉冲序列的叠加是线性的。如果x(t)、y(t)和z(t)是脉冲序列,表示为δ函数之和,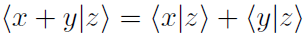 (图5B)。因此,建立在这个空间上的函数具有相同的约束条件;叠加x(t)+y(t)的函数值是x(t)和y(t)的函数值之和。注意,容器划分的脉冲序列核与叠加核具有这种线性特性。我们将看到,这种限制可能是一个关键的弱点。
(图5B)。因此,建立在这个空间上的函数具有相同的约束条件;叠加x(t)+y(t)的函数值是x(t)和y(t)的函数值之和。注意,容器划分的脉冲序列核与叠加核具有这种线性特性。我们将看到,这种限制可能是一个关键的弱点。
D. Nonlinear functional kernels
为了充分发挥核方法的潜力,我们需要无二元非线性脉冲核。有几种方法可以将线性函数核扩展为非线性函数核[24-25, 28, 30-31]。在这里,我们着重于构建Schoenberg核,因为它提供了一个可证明的通用核。Schoenberg核由径向基函数导出,其形式如下:
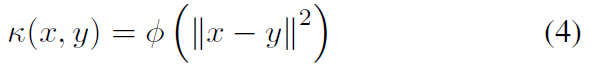
其中函数 在[0, ∞)上是完全单调的,但不是常数函数[32]。完全单调函数的例子有
在[0, ∞)上是完全单调的,但不是常数函数[32]。完全单调函数的例子有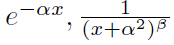 ,其中α和β是常数[33]。
,其中α和β是常数[33]。
我们取线性函数核的函数范数,也就是说,
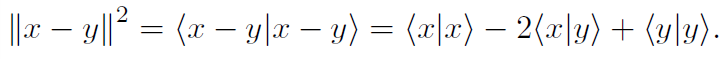
其次,在线性函数核所产生的特征空间上建立径向基核。因此,在Schoenberg核中,底层的线性函数核提供了空间上的光滑性,而径向基函数则强制线性叠加仅在局部保持。这种组合保证了得到的核对于神经识别和解码应用都是强大的。
一个典型的选择是使用(3)作为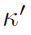 且
且 ,这能引出下式:
,这能引出下式:
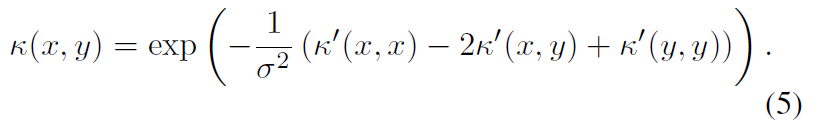
这可以看作是欧几里德空间中广泛使用的高斯核类似。Schoenberg核是普遍的,因为它们可以渐近逼近从脉冲序列到实数的任意非线性函数。它们还有一个额外的尺度参数σ,该参数控制对由基本核引起的空间应用多少平滑。
E. Extending single spike train kernels to multiple neurons
到目前为止,我们已经引入了计算一对脉冲序列之间相似性的核函数(不同时间的单个神经元或一对神经元)。然而,最近的记录技术允许同时记录多达数百个神经元。因此,我们需要一对来自许多神经元的脉冲序列的核。有两种简单而有效的方法可以将单个神经元核扩展到多个神经元核(参见[17, 34]中的组合核)。首先是使用乘积核,
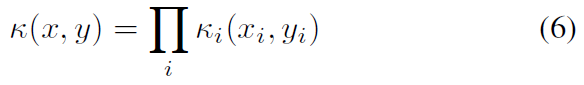 其中 i 索引同时记录的神经元。其次是使用直接总和核,
其中 i 索引同时记录的神经元。其次是使用直接总和核,
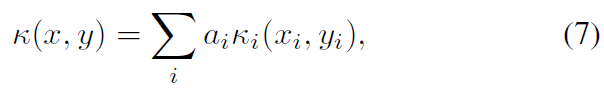
其中ai是用于组合每个神经元效果的权重。乘积核是乘积Hilbert空间的自然内积,直接总和核是直接总和Hilbert空间的自然内积。乘积核保留了基本核的普遍性(例如,对于Schoenberg核),但如果脉冲序列流形的有效维数增加(如在较少依赖脉冲序列和/或独立噪声过程的情况下),则“填充”相同核大小的空间所需的脉冲序列数目增加。因此,可能需要合并更多的平滑度(由核大小决定),或者可能需要指数级的更多数据来估计等效详细的非线性函数。直接总和核不具有普适性;事实上,这些核只跨越多个神经元上的加法函数。因此,除非这些限制因素引起人们的兴趣,否则它对于一般的神经科学应用是没有用处的。一般来说,合并核会增加超参数的数量,使得交叉验证不太实际,因此我们推荐经验贝叶斯方法来估计它们[35-36]。
尽管可以从spikernel形成乘积核,但不必这样做,因为spikernel可以通过考虑每个时间点的脉冲计数向量而直接扩展到多个神经元[23]。在这种结构中,时间扭曲均匀地应用于所有脉冲序列。由于时间复杂度只是神经元数量的加法,对于大量的记录,spikernel在计算上可能是有利的。
III. APPLICATIONS
配备了脉冲序列核,我们现在可以讨论神经科学和神经工程的应用领域,每一个领域都需要不同的核方法。首先讨论了假设检验问题,然后讨论了基于回归的平稳神经码分析和自适应滤波的在线神经解码问题。
A. Neuron identification
由于神经反应的试验间变异性(图3),对重复刺激的反应集合可以被视为随机过程的实现。当实现为脉冲序列时,对应的数学对象,脉冲序列上的概率定律,称为点过程。通常有必要确定给定不同实验条件的两组响应是否不同。我们想知道响应是否包含有关感兴趣实验条件的任何信息。例如,视觉皮层中的一些神经元编码刺激的颜色而不考虑运动,而有些则编码方向运动而不考虑颜色。
在实践中,当寻找一个编码特定特征信息的神经元时,特别是在体内电生理的背景下,可能会不情愿地包含严重的偏见。在一个典型的环境中,一个训练有素的电生理学家会倾听每个神经元的发放模式,并做出动态决定,从探测到的神经元记录下来,而探测到的神经元往往是具有较大发放率调节的神经元。在假设信息只在平均统计量(发放率)中表示的情况下,识别神经选择性已经被广泛地做了。传统的估计器是一个直方图(或一个平滑的版本),称为周刺激时间直方图(peri-stimulus time histogram,PSTH),它是通过对时间进行分类,并在试验中进行平均得到的。平均统计量的差异随后用于相关假设检验[37-38]。
另一个广泛使用的测试是脉冲计数的Wilcoxon秩总和测试[39]。它非参数地捕捉计数上分布的差异,因此,测试的不仅仅是平均计数。由于计数分布必须跨越多个值才能有意义,因此它需要一个捕获相对多个脉冲的大窗口,并且很难将其应用于多个容器。因此,计数分布不能捕捉时间结构中的差异。由于这些原因,这些广泛使用的参数统计检验从根本上无法区分许多特征。
相反,我们认为需要一类非参数统计量来区分多点过程分布,无论是高阶统计量还是时间维度。这种统计通常称为发散[24, 30, 40-41]。人们可以利用最近的一种称为概率嵌入(probability embedding)的方法从核定义散度测度,该方法通过将数据的概率分布表示为特征空间中的一个点来提供散度测度的一般构造[42-45]。
概率嵌入的思想非常简单。使用核函数将样本映射到特征空间,并取平均值表示(经验)概率分布。这是可能的,因为特征空间是(线性)Hilbert空间。只要使用一个足够强大的核,这个简单的过程就给出了渐近收敛到真实分布的经验概率定律的唯一表示。从技术上讲,证明核 是积分意义上的严格正定(strictly positive definite,spd)就足够了,也就是说,
是积分意义上的严格正定(strictly positive definite,spd)就足够了,也就是说,

对于输入空间上考虑的任何概率分布p[24]。
有趣的是,对于binned或线性函数核,Hilbert空间中的点过程的均值导致了发放率函数的估计。PSTH可以由一个binned脉冲序列核构成,强度函数的平滑估计可以由一个线性函数核产生。给定一系列脉冲序列(有可能重复),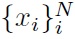 ,对应于线性函数核的Hilbert空间中的均值可以作为函数在任意脉冲序列z上被重述,
,对应于线性函数核的Hilbert空间中的均值可以作为函数在任意脉冲序列z上被重述,
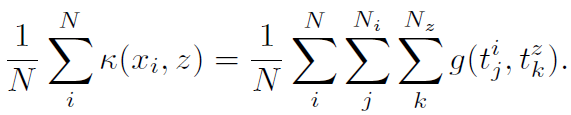
由于核对于叠加是线性的,所以均值并不取决于一个特定脉冲来自哪个脉冲序列。因此,在同一个试验中,均值不能捕捉到脉冲之间的任何统计结构。可以预期,binned核和线性函数核都不是spd[24]。
对于spd核,均值包含关于脉冲序列集合的所有信息。这并不奇怪,因为映射到Hilbert空间的唯一脉冲序列不仅是唯一的,而且是相互线性独立的(Gram矩阵是满秩的)。除了顺序,均值“记得”形成它的脉冲序列集合。重要的是Hilbert空间中的均值是一个光滑的表示,因此,如果组成均值的脉冲序列是相似的,那么它们在Hilbert空间中是接近的。
经验观测的散度测度可以定义为Hilbert空间中观测到的一对脉冲序列的均值的距离,
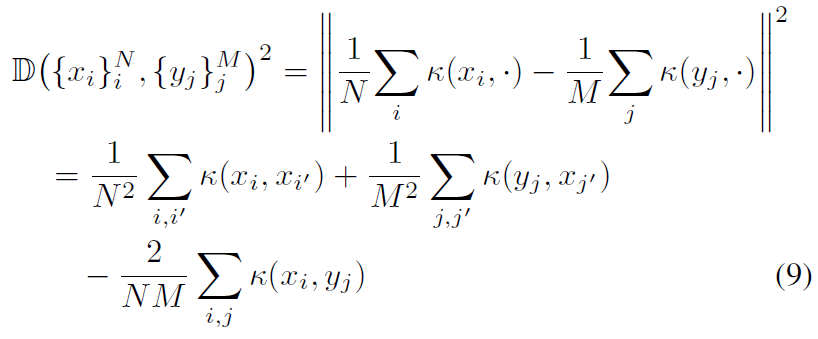
其中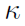 是spd核。这种散度统计量D称为最大平均差(maximum mean discrepancy,MMD)[42]。当MMD很大时,这表明两个点过程是不同的。在经典的假设检验框架中,我们需要假设两个集合来源于同一个潜在随机过程的零假设下的MMD分布。我们可以从零分布中产生MMD值,方法是将两个条件中的样本混合并从混合中重新采样[24, 42]。下面的简单过程描述了一个典型的假设检验,给出了简单的过程描述了一个典型的假设检验,给出了两个脉冲序列集合
是spd核。这种散度统计量D称为最大平均差(maximum mean discrepancy,MMD)[42]。当MMD很大时,这表明两个点过程是不同的。在经典的假设检验框架中,我们需要假设两个集合来源于同一个潜在随机过程的零假设下的MMD分布。我们可以从零分布中产生MMD值,方法是将两个条件中的样本混合并从混合中重新采样[24, 42]。下面的简单过程描述了一个典型的假设检验,给出了简单的过程描述了一个典型的假设检验,给出了两个脉冲序列集合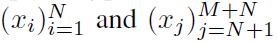 ,以及一个测试大小α:
,以及一个测试大小α:
- 计算核矩阵K
- 计算
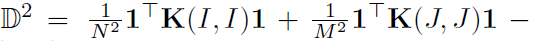
- 带替换的Bootstrap随机排列大小为N和M的索引并重新计算零分布的统计
- 如果D2高于bootstrapped零分布的(1-α)分位数,则拒绝零假设,否则接受零假设。
概率嵌入的光滑性由选择的脉冲序列核控制,因此选择一个能很好地捕捉脉冲序列自然相似性的核是非常重要的。这可能会令人惊讶,因为所有spd核对于MMD都是渐近等价的,也就是说,如果两个基本概率定律不同,任何spd核都可以在足够大的样本下进行判别。然而,将更多的相似性先验信息编码到脉冲序列核中,大大提高了散度检验的小样本能力。
B. Neural decoding
神经解码搜索神经活动和感兴趣变量之间的详细关系(图2)。成功的解码分析常常为神经系统使用的特定编码方案提供证据(或新的假设),对系统进行函数识别,并且可以用于开发神经修复体和接口。
根据目标变量的形式,神经解码可以用不同的工具来处理。当目标变量是类别(有限可能数)时,分类算法是合适的;例如,目标识别和多项选择决策是自然分类的。如果目标变量是连续值并且每次试验都是固定的,但是从一个值跳到另一个值,那么回归工具是合适的。这种基于试验的实验设计通常用于研究神经代码。当连续目标变量随时间变化时,滤波和平滑算法是合适的。大多数基本的感觉和运动特征自然属于这一类,在神经工程中是最实用的。这里我们将集中讨论回归和过滤。通过回归,我们指的是批处理分析,而通过滤波,我们指的是在线(实时)信号处理。
传统的将单个或多个脉冲序列映射到一个连续目标变量的方法是对具有相对较大容器的容器划分脉冲序列进行线性回归[46-48]。同样,理性来源于神经科学文献,主要集中于平均发放率所携带的信息,而很少涉及每次试验中的详细时间结构。尽管这些模型很粗糙,但对于运动脑机接口而言,容器划分脉冲序列上的线性模型表现得相当合理,因为行为的时间尺度是在100ms尺度上。
对于滤波,通常使用传统的线性滤波方法,如最小均方、递推最小二乘和Kalman滤波,并且循环神经网络滤波方法也值得一提[49]。近年来,基于状态空间的贝叶斯滤波方法得到了广泛的应用[50-53]。利用贝叶斯滤波框架,将状态空间(也称为隐变量)模型与连续观测到脉冲序列的编码模型相结合,进行倒装。这种方法需要一个良好的编码模型,该模型必须提前适应,并且基于训练和测试条件之间的平稳假设。由于神经可塑性,在实践中需要频繁的重训练或复杂的跟踪。
1) 高斯过程回归:高斯过程回归是一种应用广泛的非参数贝叶斯回归方法[35]。对于神经解码,我们假设从脉冲序列到R的函数上的一个先验分布。这个先验被明确地表述为一个协方差由核提供的高斯过程;在两个脉冲序列x和y处计算的函数值的协方差由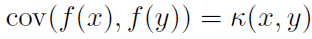 给出。具体地说,给定一组脉冲序列
给出。具体地说,给定一组脉冲序列 ,函数值的分布是先验的多元高斯分布
,函数值的分布是先验的多元高斯分布
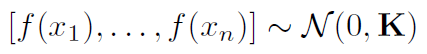
其中K是核矩阵(1)。
利用GP先验,我们可以在高斯噪声干扰的观测模型下推导出后验模型。在脉冲序列z处评估的函数预测如下:
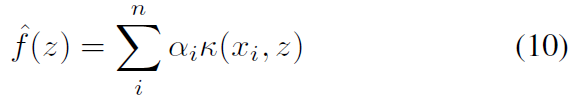
式中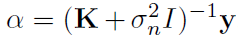 ,其中
,其中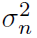 是观测噪声方差,y是对应于训练数据
是观测噪声方差,y是对应于训练数据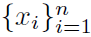 的期望信号矢量。
的期望信号矢量。
GP有几个优点:
- 预测与核岭回归(正则核最小二乘法)一致,但GP提供了后验可信区间(不要与频率置信区间混淆),表明模型假设下预测的不确定性,
- 给定一个通用核,它可以学习任何非线性函数关系,并且,
- 超参数(核参数和观测噪声方差)可以用经验贝叶斯方法进行原则性调整。
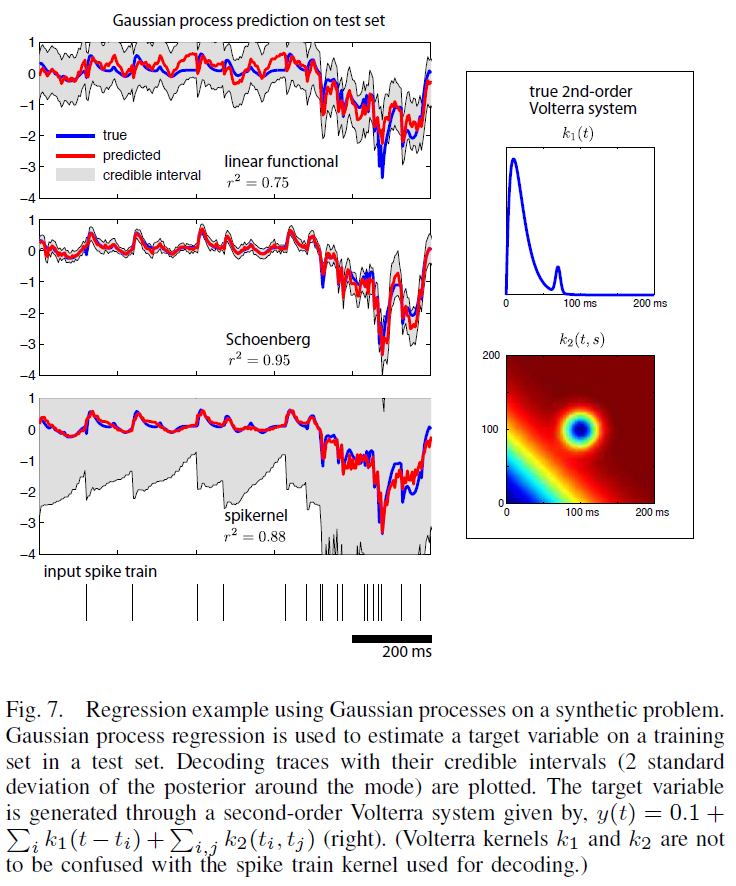
在图7中,我们将GP回归与线性函数、Schoenberg和spikernel在一个综合示例中进行比较,其中泊松脉冲序列通过二阶Volterra系统映射到实值信号。通过经验贝叶斯方法学习超参数,在训练集(400个点)上最大化边缘似然。(3)的线性函数核由于具有强的非线性成分(二阶Volterra核导致脉冲时间的两两相互作用),在均值预测(红迹)上表现不好,而spikernel得到了合理的预测。并且(5)的Schoenberg核获得了很高的性能。使用Schoenberg核得到的可信区间最小,这意味着该模型确信回归结果很好地描述了数据。相比之下,spikernel的推断可信区间较大,这意味着至少数据的某些方面没有用拟合模型很好地描述。
2) 核自适应滤波:对于闭环应用,系统辨识和预测得益于顺序处理,其中系统参数与每个新样本相适应,因为神经系统是可塑的,并且在实验装置中存在实时约束。因此,自适应滤波算法已广泛应用于脑机接口等神经修复领域[6]。如前所述,线性滤波算法,如最小均方(LMS)和递推最小二乘(RLS)算法以及Kalman滤波,已经成功地使用了二进制表示,但性能仍需改进。
核自适应滤波器(KAF)是近年来发展起来的,它将线性自适应滤波算法进行核化[54],继承其简单的计算结构,并将其扩展到非线性传递函数。类似地,KAF在逐个样本的基础上操作,并且可以处理非平稳环境。
这里我们描述了最简单但函数强大的核最小均方(KLMS)算法,该算法已成功地应用于神经工程中,作为体感假肢领域的逆控制[56]。KLMS是LMS算法的一个非线性扩展,它可以在均方误差上以随机梯度下降的形式导出,但具有无穷维权向量。滤波器映射的形式与(10)相同,其中α与瞬时误差成比例:

式中,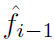 是第 i 次观察之前的估计滤波器,|η|<1是学习率[54]。因此,滤波器输入输出映射完全由真实系数αi和观测脉冲序列xi进行配对来表示。KLMS在连续振幅信号的非线性处理中得到了广泛的应用,主要采用高斯核,但RKHS方法的优点之一是算法的形式与核无关。因此,本文提出的任何脉冲序列核都可以直接用于KLMS。
是第 i 次观察之前的估计滤波器,|η|<1是学习率[54]。因此,滤波器输入输出映射完全由真实系数αi和观测脉冲序列xi进行配对来表示。KLMS在连续振幅信号的非线性处理中得到了广泛的应用,主要采用高斯核,但RKHS方法的优点之一是算法的形式与核无关。因此,本文提出的任何脉冲序列核都可以直接用于KLMS。
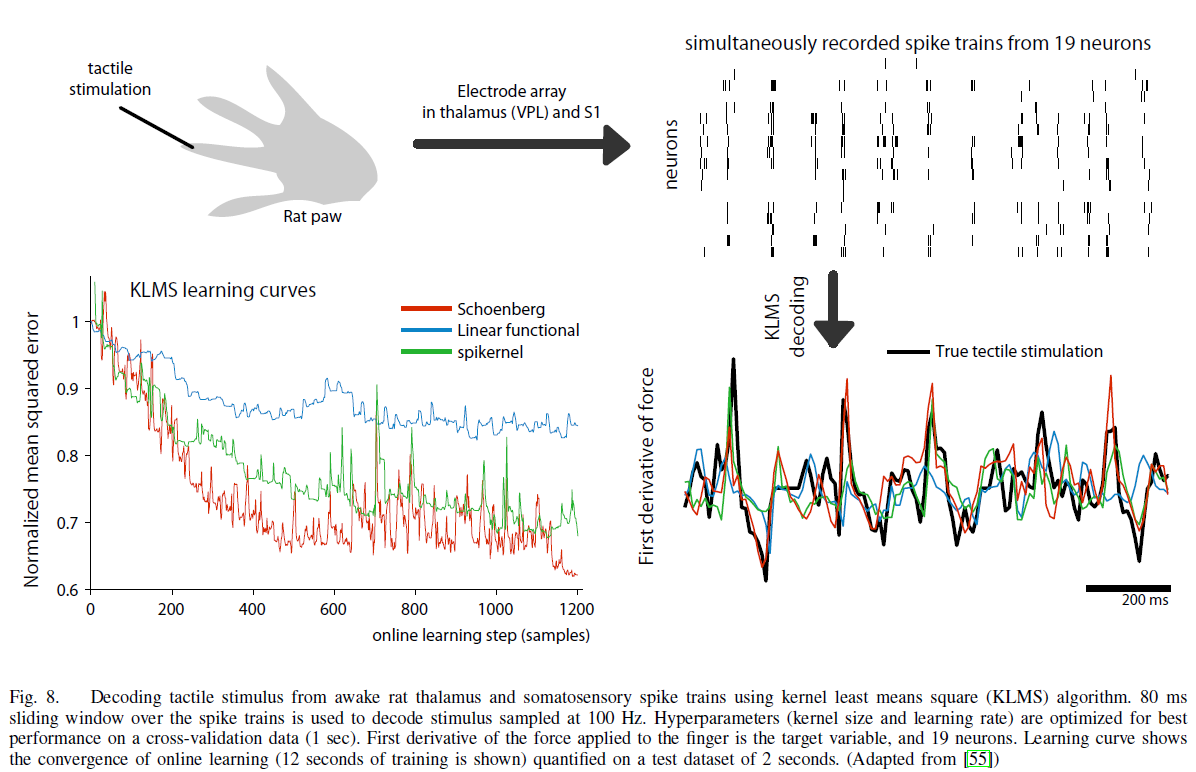
我们在图8[55, 57]中演示了使用KLMS的在线逆建模。目的是从刺激后丘脑(VPL)和初级感觉区(S1)产生的多通道脉冲重建诱导触觉刺激(这里是力的衍生物)的特性。给定神经系统中的有限内存,典型的例子是使用一个80ms的移动窗口,每次在脉冲数据上滑动2ms。在这个MISO KLMS模型中,我们使用产品核,在训练集上训练一个触觉刺激时间序列解码器,并在测试集上比较不同脉冲训练核的重建性能。总的来说,与之前的例子类似,在这个应用中,Schoenberg核在训练集中更快的收敛性和测试集中更好的刺激重建方面都优于spickernel和线性核。
IV. DISCUSSION
脉冲序列核通过为计算提供特征空间来实现脉冲序列的信号处理和机器学习。本文研究了正定函数如何在rate或脉冲时间水平上量化脉冲序列,并实现了神经解码的重要操作,如基于概率嵌入的假设检验和脉冲序列的连续函数映射估计。正如我们简单地演示过的,脉冲序列核为脉冲序列处理中使用的大多数技术提供了一个统一的框架,从统计rate描述符来看,无穷维函数空间中脉冲序列时序结构的完全描述(spd核的内射映射)的容器划分表示。因此,该方法是多用途的和数学原理的,将信号处理和机器学习的足迹扩展到更抽象的空间。
在脉冲序列核中,我们推广了无容器划分Schoenberg核,因为:(1)它提供了一个内射映射,(2)它可以将神经响应的任意随机性作为样本均值嵌入到RKHS中,(3)它是一个可以逼近脉冲序列上任意函数的通用核。由于核映射的强非参数性质,点过程和函数类中允许这种任意性。

A. Interpretation of decoding analysis
与其他先进的信号处理方法(如深度学习和非参数贝叶斯方法)一样,由于隐式特征空间的高维性,严格正定脉冲序列核使得结果不易解释。较弱的核只显式地封装了某些设计的特征,例如计数核只对总脉冲计数敏感,线性函数核对触发率分布最敏感。虽然强核可以捕捉任意特征,但它们并不是唯一的。因此,显式地设计更强的脉冲序列核是非常重要的,因为很难理解它们所强调的脉冲序列特性。有几种方法可以部分恢复直觉,尽管在这方面还需要更多的研究:在MMD-PCA的情况下通过特征空间中的脉冲序列可视化(图6),通过相关向量机等稀疏回归方法,或者通过对一组强可解释弱(更参数化)核集进行核选择。
解码分析的另一个注意事项是,成功的解码并不意味着大脑正在使用信息,它只意味着信息存在于所收集的神经信号中。例如,在像视网膜神经节细胞或听觉纤维这样的早期感觉神经元中,我们常常能够比受试者通过行为所报告的更好地解码和重建感觉刺激。因此,我们应该谨慎,不要过度解读成功的解码。
B. Future directions
过去十年在许多抽象(非欧几里德)空间的新核方面取得了成果,但仍有改进的余地。我们希望有一个足够强大的脉冲序列核,即spd和广泛适用的,同时,能够捕获关于脉冲序列之间相似性的先验知识。神经系统的变异性可以为设计更好的脉冲训练核提供线索。
设计一个有用的核有三个实际的方面:(1)核应该编码输入域的先验知识和手头的问题,(2)核应该是可计算的,可能在脉冲数目上具有线性或更少的时间复杂性;(3)核应该没有或只有很少的参数——在后一种情况下,参数后面应该有简单的直觉,更重要的是设置参数值的简单规则。
在本文中,我们讨论了两个框架,即binned核和函数核。binned核要么过于简单,要么忽略了时间结构,要么在计算上过于昂贵,例如spikernel。另一方面,一些函数核要么对平均rate过于敏感,如线性函数核,要么涉及不易可视化的参数。在这三个属性之间保持适当平衡的核仍有待发现。可以肯定的是,我们只触及了这个问题的表面,还有许多公开的途径有待探索。两种可能的方法是编辑核和生成核。编辑核依赖于采用简单操作(如移位、添加和删除)的原则,将一个脉冲序列转换为另一个脉冲序列,其中每个操作分配一个成本,而生成核依赖于如果两个脉冲序列来自同一生成模型,那么它们相似原则。
Kernel methods on spike train space for neuroscience: a tutorial的更多相关文章
- Kernel Methods (2) Kernel function
几个重要的问题 现在已经知道了kernel function的定义, 以及使用kernel后可以将非线性问题转换成一个线性问题. 在使用kernel 方法时, 如果稍微思考一下的话, 就会遇到以下几个 ...
- PRML读书会第六章 Kernel Methods(核函数,线性回归的Dual Representations,高斯过程 ,Gaussian Processes)
主讲人 网络上的尼采 (新浪微博:@Nietzsche_复杂网络机器学习) 网络上的尼采(813394698) 9:16:05 今天的主要内容:Kernel的基本知识,高斯过程.边思考边打字,有点慢, ...
- Kernel Methods - An conclusion
Kernel Methods理论的几个要点: 隐藏的特征映射函数\(\Phi\) 核函数\(\kappa\): 条件: 对称, 正半定; 合法的每个kernel function都能找到对应的\(\P ...
- Kernel Methods (4) Kernel SVM
(本文假设你已经知道了hard margin SVM的基本知识.) 如果要为Kernel methods找一个最好搭档, 那肯定是SVM. SVM从90年代开始流行, 直至2012年被deep lea ...
- 核方法(Kernel Methods)
核方法(Kernel Methods) 支持向量机(SVM)是机器学习中一个常见的算法,通过最大间隔的思想去求解一个优化问题,得到一个分类超平面.对于非线性问题,则是通过引入核函数,对特征进行映射(通 ...
- Kernel Methods for Deep Learning
目录 引 主要内容 与深度学习的联系 实验 Cho Y, Saul L K. Kernel Methods for Deep Learning[C]. neural information proce ...
- Kernel Methods (6) The Representer Theorem
The Representer Theorem, 表示定理. 给定: 非空样本空间: \(\chi\) \(m\)个样本:\(\{(x_1, y_1), \dots, (x_m, y_m)\}, x_ ...
- Kernel Methods (3) Kernel Linear Regression
Linear Regression 线性回归应该算得上是最简单的一种机器学习算法了吧. 它的问题定义为: 给定训练数据集\(D\), 由\(m\)个二元组\(x_i, y_i\)组成, 其中: \(x ...
- Kernel Methods (1) 从简单的例子开始
一个简单的分类问题, 如图左半部分所示. 很明显, 我们需要一个决策边界为椭圆形的非线性分类器. 我们可以利用原来的特征构造新的特征: \((x_1, x_2) \to (x_1^2, \sqrt 2 ...
随机推荐
- yield 复习
1.协程,微型进程: yield 生成器 yield 会保存声明的变量,可以进行迭代 使用 接收函数返回的对象.__next__() next(接收函数返回的对象) .send() 方法 传递给函数中 ...
- PHP fflush() 函数
定义和用法 fflush() 函数向打开的文件写入所有的缓冲输出. 如果成功则返回 TRUE,如果失败则返回 FALSE. 语法 fflush(file) 参数 描述 file 必需.规定要检查的打开 ...
- Skill 解决 Design Library 被识别成 Technology Library 的问题
https://www.cnblogs.com/yeungchie/ code procedure(ycTechLibToDesign(libName attachLibName) prog((lib ...
- MySQL选错索引导致的线上慢查询事故
前言 又和大家见面了!又两周过去了,我的云笔记里又多了几篇写了一半的文章草稿.有的是因为质量没有达到预期还准备再加点内容,有的则完全是一个灵感而已,内容完全木有.羡慕很多大佬们,一周能产出五六篇文章, ...
- 5.15 省选模拟赛 T1 点分治 FFT
LINK:5.15 T1 对于60分的暴力 都很水 就不一一赘述了. 由于是询问所有点的这种信息 确实不太会. 想了一下 如果只是询问子树内的话 dsu on tree还是可以做的. 可以自己思考一下 ...
- LVS-DR:搭建HTTP和HTTPS负载均衡集群
目录 LVS-DR实战:搭建HTTP和HTTPS负载均衡集群 1. 搭建lvs-dr模式的http负载集群 1.1 LVS上配置IP 1.2 RS上配置arp内核参数 1.3 RS上配置VIP 1.4 ...
- 第二次作业:卷积神经网络 part 1
第二次作业:卷积神经网络 part 1 视频学习 数学基础 受结构限制严重,生成式模型效果往往不如判别式模型. RBM:数学上很漂亮,且有统计物理学支撑,但主流深度学习平台不支持RBM和预训练. 自编 ...
- 题解 Luogu P1514 【引水入城】
有一种神奇的算法叫做floodfill 就是一个n*m的矩阵,a[i][j]为当前高度,我们可以任选一个点倒水,开始bfs,如果要搜的点没有被搜到过,并且高度小于当前的点,我们就把这个点加入队列中 而 ...
- 44-final, finally, finalize的区别
final—修饰符(关键字) 如果一个类被声明为final,意味着它不能再派生出新的子类,不能作为父类被继承. 因此一个类不能既被声明为 abstract的,又被声明为final的.将变量或方法声明为 ...
- 理解JavaScript的原型链
1. 什么是对象 在JavaScript中,对象是属性的无序集合,每个属性存放一个原始值.对象或函数. 1.1 创建对象 在JavaScript中创建对象的两种方法: ① 字面上: var myObj ...