小样本学习最新综述 A Survey on Few-shot Learning | Introduction and Overview
- 01 Introduction
- Bridging this gap between AI and humans is an important direction.
- FSL can also help relieve the burden of collecting large-scale supervised data.
- Driven by the academic goal for AI to approach humans and the industrial demand for inexpensive learning, FSL has drawn much recent attention and is now a hot topic.
- Contributions of this survey can be summarized as follows
- 02 Overview
原文链接:小样本学习与智能前沿·公众号

Author list
YAQING WANG, Hong Kong University of Science and Technology and Baidu Research
QUANMING YAO∗, 4Paradigm Inc.
JAMES T. KWOK, Hong Kong University of Science and Technology
LIONEL M. NI, Hong Kong University of Science and Technology
机器学习在数据密集型应用程序中非常成功,但是在数据集较小时通常会受到阻碍。近来,提出了“少量学习”(FSL)来解决这个问题。使用现有知识,FSL可以快速推广到仅包含少量带有监督信息的样本的新任务。
在本文中,我们进行了彻底的调查,以全面了解FSL。从FSL的正式定义开始,我们将FSL与几个相关的机器学习问题区分开来。然后,我们指出FSL的核心问题是经验风险最小化工具不可靠。根据如何使用先验知识来处理此核心问题,我们从三个角度对FSL方法进行了分类:
- (i)数据,它使用先验知识来增强监督经验;
- (ii)模型,它使用先验知识来减小假设空间的大小;
- (iii)算法,该算法使用先验知识来改变对给定假设空间中最佳假设的搜索。
通过这种分类法,我们将审查和讨论每个类别的利弊。在FSL问题设置,技术,应用和理论方面,也提出了有希望的方向,以为未来的研究提供见识。
Additional Key Words and Phrases: Few-Shot Learning, One-Shot Learning, Low-Shot Learning, Small Sample Learning, Meta-Learning, Prior Knowledge
01 Introduction
current AI techniques cannot rapidly generalize from a few examples. The aforementioned successful AI applications rely on learning from large-scale data.
In contrast, humans are capable of learning new tasks rapidly by utilizing what they learned in the past.
examples:
a child who learned how to add can rapidly transfer his knowledge to learn multiplication given a few examples (e.g., 2 × 3 = 2 + 2 + 2 and 1 × 3 = 1 + 1 + 1).
Another example is that given a few photos of a stranger, a child can easily identify the same person from a large number of photos.
Bridging this gap between AI and humans is an important direction.
In order to learn from a limited number of examples with supervised information, a new machine learning paradigm called Few-Shot Learning (FSL) [35, 36] is proposed.
当然,FSL还可以推进机器人技术[26],后者开发出可以复制人类行为的机器。 例子包括一杆模仿[147],多臂匪[33],视觉导航[37]和连续控制[156]。
FSL can also help relieve the burden of collecting large-scale supervised data.
although ResNet [55] outperforms humans on ImageNet, each class needs to have sufficient labeled images which can be laborious to collect.
Examples include
- image classification [138]
- image retrieval [130]
- object tracking [14]
- gesture recognition [102]
- image captioning
- visual question answering [31]
- video event detection [151]
- language modeling [138]
- neural architecture search [19]
Driven by the academic goal for AI to approach humans and the industrial demand for inexpensive learning, FSL has drawn much recent attention and is now a hot topic.
Many related machine learning approaches have been proposed:
- meta-learning [37, 106, 114],
- embedding learning [14, 126, 138]
- generative modeling [34, 35, 113].
Contributions of this survey can be summarized as follows
- 我们给出了FSL的正式定义,该定义自然与[92,94]中的经典机器学习定义相关。该定义不仅足够笼统地包括现有的FSL作品,而且足够具体以阐明FSL的目标是什么以及我们如何解决它。该定义有助于在FSL领域设定未来的研究目标。
- 我们通过具体示例列出了FSL的相关学习问题,阐明了它们与FSL的相关性和差异。这些讨论可以帮助更好地区分FSL,并将其定位在各种学习问题之间。
- 我们指出,FSL监督学习问题的核心问题是不可靠的经验风险最小化器,它是基于机器学习中的错误分解[17]进行分析的。这为以更组织和系统的方式改进FSL方法提供了见识。
- 我们进行了广泛的文献回顾,并从数据,模型和算法的角度将它们整理成统一的分类法。我们还提供了一些见解的摘要,并就每种类别的利弊进行了讨论。这些可以帮助您更好地理解FSL方法。
- 我们在问题设置,技术,应用和理论方面为FSL提出了有希望的未来方向。这些见解基于FSL当前发展的弱点,并可能在将来进行改进。
01. 2 Notation and Terminology
Consider a learning task \(T\), FSL deals with a data set \(D = \left\{D_{train},D_{test}\right\}\) consisting of a training set \(D_{train} = \left\{(x_i,y_i)\right\}_{i=1}^I\) whereI \(I\) is small,and a testing set \(D_{test} = \left\{x_{test}\right\}\). Letp(x,y) be the ground-truth joint probability distribution(联合概率分布) of input x and output y, and \(\hat{y}\) be the optimal hypothesis from x to y. FSL learns to discover \(\hat{y}\) by fitting \(D_{trian}\) and testing on \(D_{test}\). θ denotes all the parameters used by h.
A FSL algorithm is an optimization strategy that searches H in order to find the θ that parameterizes the best h*. The FSL performance is measured by a loss function \(l(\hat{y},y)\) defined over the prediction \(\hat{y}= h(x;θ)\) and the observed output y.
02 Overview
02.1 Problem definition
how machine learning is defined
A computer program is said to learn from experience E with respect to some classes of task T and performance measure P if its performance can improve with E on T measured by P .
examples:
consider an image classification task (T ), a machine learning program can improve its classification accuracy (P) through E obtained by training on a large number of labeled images (e.g., the ImageNet data set [73]).

FSL is a special case of machine learning, which targets at obtaining good learning performance given limited supervised information provided in the training set \(D_{train}\).
The definition of FSL
Few-Shot Learning (FSL) is a type of machine learning problems (specified by E, T and P), where E contains only a limited number of examples with supervised information for the target T .
few-shot classification learns classifiers given only a few labeled examples of each class.
example applications:
- image classification [138]
- sentiment classification(情绪分类) from short text [157]
- object recognition [35].
N-way-K-shot classification[37,138]
\(D_{train}\) contains I = KN examples from N classes each with K examples.
Few-shot regression [37, 156]
estimates a regression function h given only a few input-output example pairs sampled from that function, where output \(y_i\) is the observed value of the dependent variable y, and \(x_i\) is the input which records the observed value of the independent variable x.
few-shot reinforcement learning [3, 33]
targets at finding a policy given only a few trajectories consisting of state-action pairs.
three typical scenarios of FSL
- 像人类一样充当学习的试验床。为了迈向人类智能,计算机程序能够解决FSL问题至关重要。一个流行的任务(T)是仅给出几个例子就生成一个新角色的样本[76]。受人类学习方式的启发,计算机程序使用E进行学习,E由既有监督信息的给定示例以及受过训练的概念(如零件和关系)作为先验知识组成。通过视觉图灵测试(P)的通过率评估生成的字符,该测试可区分图像是由人还是由机器生成的。有了这些先验知识,计算机程序还可以学习分类,解析和生成新 -的手写字符,例如人类。
- 学习罕见的情况。当很难或不可能获得带有监督信息的足够示例时,FSL可以为罕见情况学习模型。例如,考虑一个药物发现任务(T),该任务试图预测一个新分子是否具有毒性作用[4]。通过新分子的有限测定和许多类似分子的测定(既有知识)获得的E,正确分配为有毒或无毒(P)分子的百分比会提高。
- 减少数据收集工作量和计算成本。 FSL可以帮助减轻收集大量带有监督信息的示例的负担。考虑少量拍摄图像分类任务(T)[35]。图像分类精度(P)随目标类别T的每个类别的少量标记图像获得的E以及从其他类别中提取的先验知识(例如原始图像到共同训练)而提高。成功完成此任务的方法通常具有较高的通用性。因此,它们可以轻松地应用于许多样本的任务。

One typical type of FSL methods is Bayesian learning [35, 76]. It combines the provided training set \(D_{train}\) with some prior probability distribution which is available before \(D_{train}\) is given [15].
When there is only one example with supervised information in E,FSL is called one-shot learning [14, 35, 138]. When E does not contain any example with supervised information for the target T , FSL becomes a zero-shot learning problem (ZSL) [78].
ZSL requires E to contain information from other modalities(形式) (such as attributes, WordNet, and word embeddings used in rare object recognition tasks), so as to transfer some supervised information and make learning possible.
02.2 Relevant Learning Problems
Weakly supervised learning [163]
only a small amount of samples have supervised information.
this can be further classified into the following:
- Semi-supervised learning [165], which learns from a small number of labeled samples and (usually a large number of) unlabeled samples in E. Positive-unlabeled learning [81] is a special case of semi-supervised learning, in which only positive and unlabeled samples are given.
- Active learning [117], which selects informative unlabeled data to query an oracle for output y. This is usually used for applications where annotation labels are costly, such as pedestrian detection.
weakly supervised learning with incomplete supervision mainly uses unlabeled data as ad- ditional information in E, while FSL leverages various kinds of prior knowledge such as pre-trained models, supervised data from other domains or modalities and does not restrict to using unlabeled data. Therefore, FSL becomes weakly supervised learning problem only when prior knowledge is unlabeled data and the task is classification or regression.
Imbalanced learning [54]
从经验E中学习y的偏斜分布。 当很少使用y的某些值时(例如在欺诈检测和巨灾预测应用程序中),就会发生这种情况。 它会进行训练和测试,以便在所有可能的y中进行选择。 相比之下,FSL会通过一些示例对y进行训练和测试,同时可能会将其他y作为学习的先验知识。
Transfer learning [101]
It can be used in applications such as cross-domain recommendation, WiFi localization across time periods, space and mobile devices.
Domain adaptation [11] is a type of transfer learning in which the source/target tasks are the same but the source/target domains are different.
example:
in sentiment analysis, the source domain data contains customer comments on movies, while the target domain data contains customer comments on daily goods.
Meta-learning [59]
Meta-learning [59] improves P of the new task T by the provided data set and the meta- knowledge extracted across tasks by a meta-learner. Specifically, the meta-learner gradually learns generic information (meta-knowledge) across tasks, and the learner generalizes the meta-learner for a new task T using task-specific information.
the meta-learner is taken as prior knowledge to guide each specific FSL task.
02.3 Core Issue
we illustrate the core issue of FSL based on error decomposition(分解) in supervised machine learning [17, 18]
02.3.1 Empirical Risk Minimization.
Given a hypothesis h, we want to minimize its expected risk R, which is the loss measured with respect to p(x,y). Specifically,
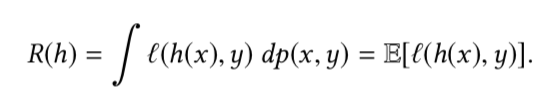
因为p(x,y)是未知的, the empirical risk(训练集\(D_{train}\)的I个样本的平均loss)表达如下:
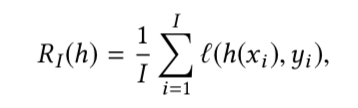
The empirical risk 通常被用作\(R(h)\)的proxy,可以使得empirical risk minimization.(可能有一些正则化)
为了更好的说明,我们规定:

我们假设三者独立,那么the total error 可以被分解为:
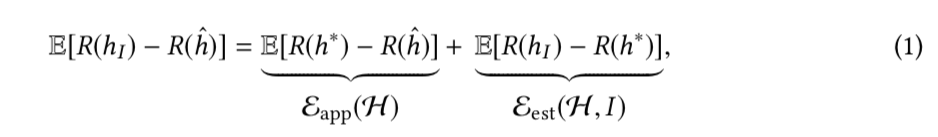
公式右边第一项为 approximation error,第二项为estimation error.
总的来说,the total error 收到H(hypothesis space)和I(训练集中样本的数量)的影响,也就是说,想要减少total error,可以从三个方面下手:
- data
- model, which determines H
- algorithm,which 搜索满足data的最优\(h_I\)
02.3.2 Unreliable Empirical Risk Minimizer.
estimation error 可以通过增加样本量来减少[17,18,41]。所以,当有充足的训练监督信息数据的时候,estimation error 很小。
this is the core issue of FSL supervised learning:
the empirical risk minimizer \(h_I\) is no longer reliable.

02.4 Taxonomy
为了缓解在FSL监督学习中具有不可靠的经验风险最小化工具\(h_I\)的问题,必须使用先验知识。基于使用先验知识对哪个方面进行了增强,可以将现有的FSL作品分为以下几个方面(图2)。

- Data. 这种方法是利用先验知识来增强训练集,扩大I的数量。 使得在这种情况下,标准的机器学习模型和算法可以被使用。
- Model。 这种方式是利用先验知识来约束假设空间的复杂性,使得假设空间变小。在这种情况下,训练集足够去学习一个可靠的\(h_I\).
- Algorithm. 这种方法使用先验知识来搜索\(\theta\),\(\theta\) 参数化最佳的h。 先验知识通过提供良好的初始化(图2(c)中的灰色三角形)或指导搜索步骤(图2(b)中的灰色虚线)来更改搜索策略。 对于后者,最终的搜索步骤受先验知识和经验风险最小化因素的影响。

小样本学习最新综述 A Survey on Few-shot Learning | Introduction and Overview的更多相关文章
- Generalizing from a Few Examples: A Survey on Few-Shot Learning 小样本学习最新综述 | 三大数据增强方法
目录 原文链接:小样本学习与智能前沿 01 Transforming Samples from Dtrain 02 Transforming Samples from a Weakly Labeled ...
- 最新小样本学习综述 A Survey on Few-Shot Learning | 四大模型Multitask Learning、Embedding Learning、External Memory…
目录 原文链接: 小样本学习与智能前沿 01 Multitask Learning 01.1 Parameter Sharing 01.2 Parameter Tying. 02 Embedding ...
- 小样本学习Few-shot learning
One-shot learning Zero-shot learning Multi-shot learning Sparse Fine-grained Fine-tune 背景:CVPR 2018收 ...
- 《A Survey on Transfer Learning》迁移学习研究综述 翻译
迁移学习研究综述 Sinno Jialin Pan and Qiang Yang,Fellow, IEEE 摘要: 在许多机器学习和数据挖掘算法中,一个重要的假设就是目前的训练数据和将来的训练数据 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- 吴恩达《深度学习》-第二门课 (Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization)-第一周:深度学习的实践层面 (Practical aspects of Deep Learning) -课程笔记
第一周:深度学习的实践层面 (Practical aspects of Deep Learning) 1.1 训练,验证,测试集(Train / Dev / Test sets) 创建新应用的过程中, ...
- 【GS文献】基因组选择在植物分子育种应用的最新综述(2020)
目录 1. 简介 2. BLUP类模型 3. Bayesian类模型 4. 机器学习 5. GWAS辅助的GS 6. 杂交育种 7. 多性状 8. 长期选择 9. 预测准确性评估 10. GS到植物育 ...
- 转录组分析综述A survey of best practices for RNA-seq data analysis
转录组分析综述 转录组 文献解读 Trinity cufflinks 转录组研究综述文章解读 今天介绍下小编最近阅读的关于RNA-seq分析的文章,文章发在Genome Biology 上的A sur ...
- 论文笔记:多标签学习综述(A review on multi-label learning algorithms)
2014 TKDE(IEEE Transactions on Knowledge and Data Engineering) 张敏灵,周志华 简单介绍 传统监督学习主要是单标签学习,而现实生活中目标样 ...
随机推荐
- python实现城市气候与海洋的关系研究
城市气候与海洋的关系研究 关注公众号"轻松学编程"了解更多. 以下命令都是在浏览器中输入. cmd命令窗口输入:jupyter notebook 后打开浏览器输入网址http:// ...
- c++11-17 模板核心知识(三)—— 非类型模板参数 Nontype Template Parameters
类模板的非类型模板参数 函数模板的非类型模板参数 限制 使用auto推断非类型模板参数 模板参数不一定非得是类型,它们还可以是普通的数值.我们仍然使用前面文章的Stack的例子. 类模板的非类型模板参 ...
- 【Kata Daily 190923】Odder Than the Rest(找出奇数)
题目: Create a method that takes an array/list as an input, and outputs the index at which the sole od ...
- 等效介质理论模型---利用S参数反演法提取超材料结构的等效参数
等效介质理论模型---利用S参数反演法提取超材料结构的等效参数 S参数反演法,即利用等效模型的传输矩阵和S参数求解超材料结构的等效折射率n和等效阻抗Z的过程.本文对等效介质理论模型进行了详细介绍,并提 ...
- 13、form组件
Form介绍 我们之前在HTML页面中利用form表单向后端提交数据时,都会写一些获取用户输入的标签并且用form标签把它们包起来. 与此同时我们在好多场景下都需要对用户的输入做校验,比如校验用户是否 ...
- GAMES101系列笔记一 图形学概述与线性代数入门
概述+线性代数 为什么学习图形学? Computer Graphics is AWESOME! 主要涉及内容: 光栅化 曲线和网格 光线追踪 动画与模拟 Differences between CG ...
- Layui弹出层详解
今天空了学习一下弹出层 还是一步步展示把 首先,layer可以独立使用,也可以通过Layui模块化使用.我个人一直是用的模块化的 所以下面素有的都是基于模块化的. 引入好相关文件就可以开始啦 今天放 ...
- DevExpress XtraReport报表预览时可编辑的功能
设置控件的EditOptions.Enabled=true即可 注册实现PrintingSystem. EditingFieldChanged事件,可获得当前发生更改的控件的值. 另:XtraRepo ...
- [MIT6.006] 9. Table Doubling, Karp-Rabin 双散列表, Karp-Rabin
在整理课程笔记前,先普及下课上没细讲的东西,就是下图,如果有个操作g(x),它最糟糕的时间复杂度为Ο(c2 * n),它最好时间复杂度是Ω(c1 * n),那么θ则为Θ(n).简单来说:如果O和Ω可以 ...
- 搭建vue-cli4.0项目
① Vue CLI的包名称由 vue-cli 改成了 @vue/cli. 如果已经全局安装了旧版本的 vue-cli(1.x或2.x), 你需要先通过 npm uninstall vue-cli ...