用python讲解数据结构之树的遍历

树的结构
树(tree)是一种抽象数据类型或是实现这种抽象数据类型的数据结构,用来模拟具有树状结构性质的数据集合
它具有以下的特点:
①每个节点有零个或多个子节点;
②没有父节点的节点称为根节点;
③每一个非根节点有且只有一个父节点;
④除了根节点外,每个子节点可以分为多个不相交的子树;
树的分类
二叉树
二叉树:每个节点最多含有两个子树的树称为二叉树。
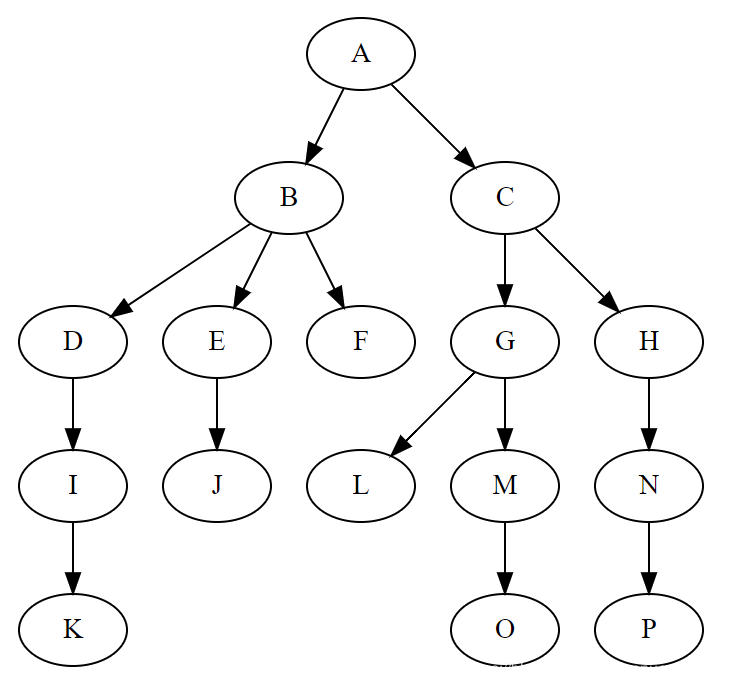
二叉树中一些专业术语:
- 父节点:A节点就是B节点的父节点,B节点是A节点的子节点
- 兄弟节点:B、C这两个节点的父节点是同一个节点,所以他们互称为兄弟节点
- 根节点:A节点没有父节点,我们把没有父节点的节点叫做根节点
- 叶子节点:图中的H、I、J、K、L节点没有子节点,我们把没有子节点的节点叫做叶子节点
节点的高度:节点到叶子结点的最长路径,比如C节点的高度是2(L->F是1,F->C是2)节点的深度:节点到根节点的所经历的边的个数比如C节点的高度是1(A->C,只有一条边,所以深度=1)节点的层:节点的高度树的高度:根节点的高度
基于二叉树衍生的多种树型结构:
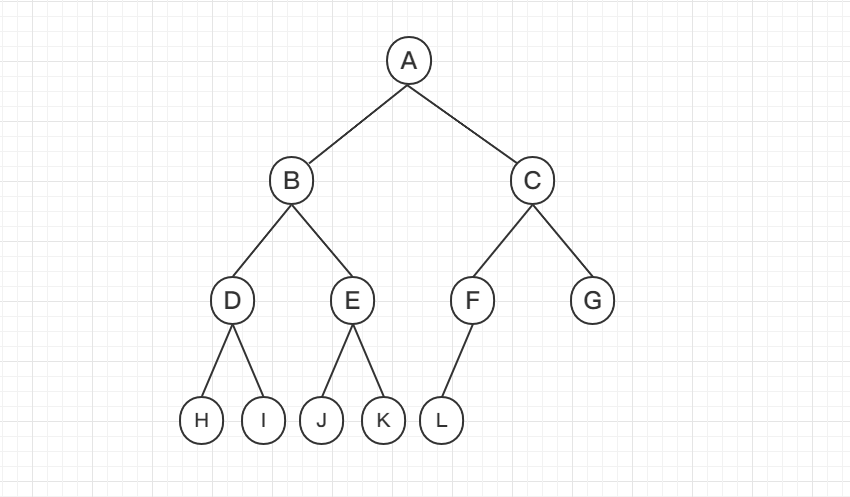
满二叉树
满二叉树:除最后一层无任何子节点外,每一层上的所有结点都有两个子结点。也可以这样理解,除叶子结点外的所有结点均有两个子结点。节点数达到最大值,所有叶子结点必须在同一层上

完全二叉树
完全二叉树:设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h 层所有的结点都连续集中在最左边,这就是完全二叉树
满二叉树和完全二叉树对比:

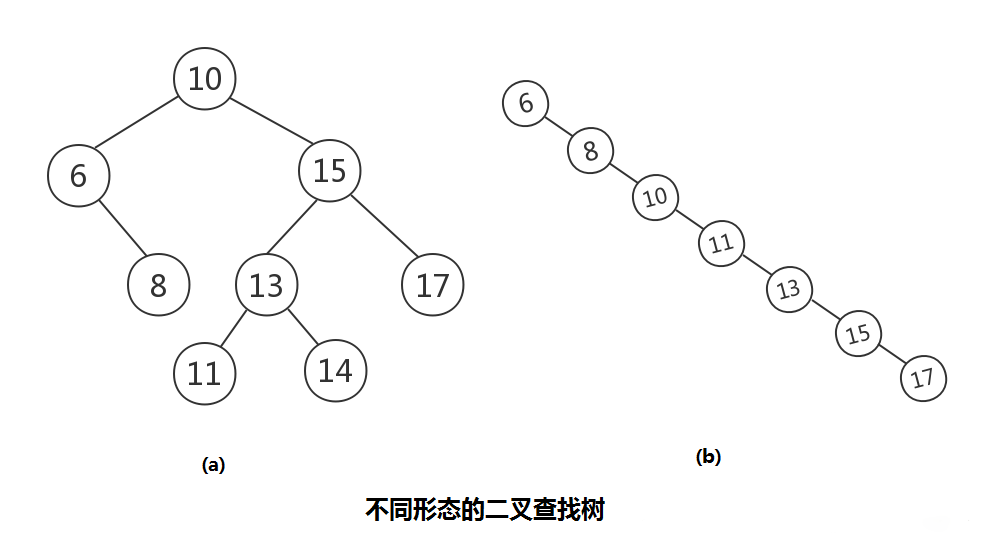
二叉查找树
二叉查找树: 也称二叉搜索树,或二叉排序树。其定义也比较简单,要么是一颗空树,要么就是具有如下性质的二叉树:
(1)若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
(2) 若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
(3) 任意节点的左、右子树也分别为二叉查找树;
(4) 没有键值相等的节点。
平衡二叉树
定义: 平衡二叉搜索树,又被称为AVL树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树
平衡二叉树出现原因:
由于普通的二叉查找树会容易失去”平衡“,极端情况下,二叉查找树会退化成线性的链表,导致插入和查找的复杂度下降到 O(n) ,所以,这也是平衡二叉树设计的初衷。那么平衡二叉树如何保持”平衡“呢?根据定义,有两个重点,一是左右两子树的高度差的绝对值不能超过1,二是左右两子树也是一颗平衡二叉树。
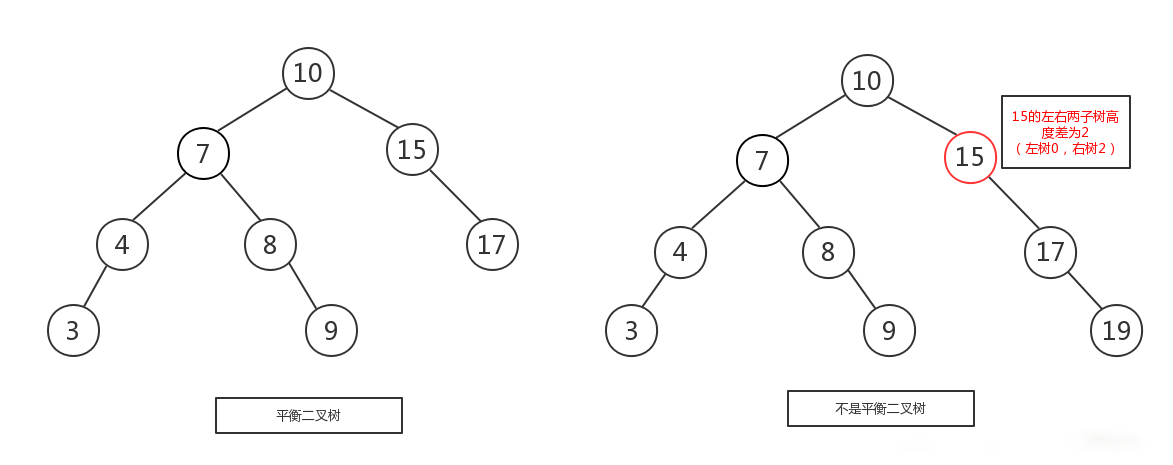
平衡二叉树的创建:
平衡二叉树是一棵高度平衡的二叉查找树。所以,要构建跟维系一棵平衡二叉树就比普通的二叉树要复杂的多。在构建一棵平衡二叉树的过程中,当有新的节点要插入时,检查是否因插入后而破坏了树的平衡,如果是,则需要做旋转去改变树的结构
红黑树
avl树每次插入删除会进行大量的平衡度计算导致IO数量巨大而影响性能。所以出现了红黑树。一种二叉查找树,但在每个节点增加一个存储位表示节点的颜色,可以是红或黑(非红即黑)

定义:
- 每个节点非红即黑;
- 根节点是黑的;
- 每个叶节点(叶节点即树尾端NULL指针或NULL节点)都是黑的;
- 如图所示,如果一个节点是红的,那么它的两儿子都是黑的;
- 对于任意节点而言,其到叶子点树NULL指针的每条路径都包含相同数目的黑节点;
- 每条路径都包含相同的黑节点;
红黑树有两个重要性质:
1、红节点的孩子节点不能是红节点;
2、从根到叶子节点的任意一条路径上的黑节点数目一样多。
这两条性质确保该树的高度为logN,所以是平衡树。
优势:
红黑树的查询性能略微逊色于AVL树,因为他比avl树会稍微不平衡最多一层,也就是说红黑树的查询性能只比相同内容的avl树最多多一次比较,但是,红黑树在插入和删除上完爆avl树,avl树每次插入删除会进行大量的平衡度计算,而红黑树为了维持红黑性质所做的红黑变换和旋转的开销,相较于avl树为了维持平衡的开销要小得多
使用场景:
- 广泛用于C ++的STL中,地图和集都是用红黑树实现的;
- 着名的Linux的的进程调度完全公平调度程序,用红黑树管理进程控制块,进程的虚拟内存区域都存储在一颗红黑树上,每个虚拟地址区域都对应红黑树的一个节点,左指针指向相邻的地址虚拟存储区域,右指针指向相邻的高地址虚拟地址空间;
- IO多路复用的epoll的的的实现采用红黑树组织管理的的的sockfd,以支持快速的增删改查;
- Nginx的的的中用红黑树管理定时器,因为红黑树是有序的,可以很快的得到距离当前最小的定时器;
- Java的的的中TreeMap中的中的实现;
B树
定义:
B树是为实现高效的磁盘存取而设计的多叉平衡搜索树。(B树和B-tree这两个是同一种树)
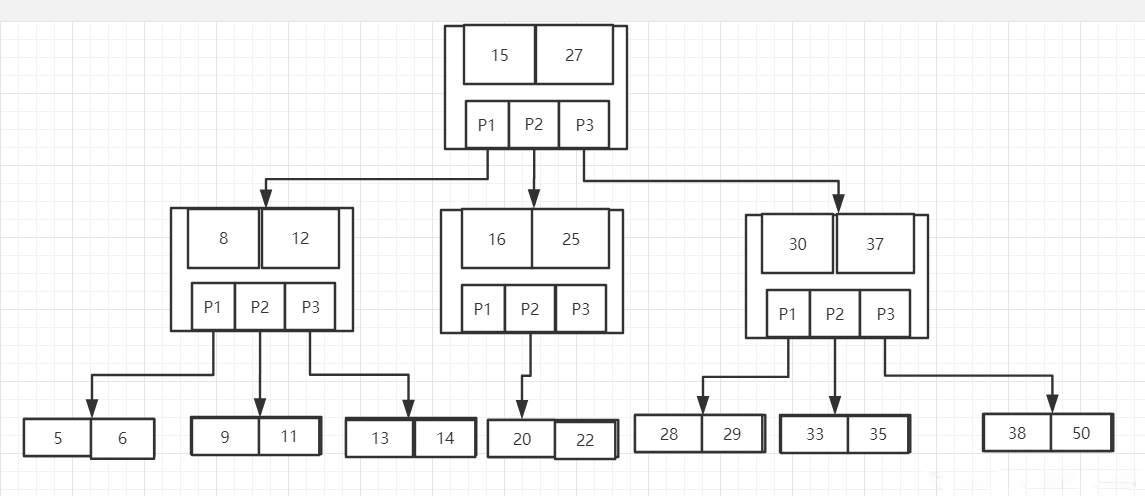
产生原因:
B树是一种查找树,我们知道,这一类树(比如二叉查找树,红黑树等等)最初生成的目的都是为了解决某种系统中,查找效率低的问题。
B树也是如此,它最初启发于二叉查找树,二叉查找树的特点是每个非叶节点都只有两个孩子节点。然而这种做法会导致当数据量非常大时,二叉查找树的深度过深,搜索算法自根节点向下搜索时,需要访问的节点也就变的相当多。
如果这些节点存储在外存储器中,每访问一个节点,相当于就是进行了一次I/O操作,随着树高度的增加,频繁的I/O操作一定会降低查询的效率。
定义:
B树是一种平衡的多分树,通常我们说m阶的B树,它必须满足如下条件:
- 每个节点最多只有m个子节点。
- 每个非叶子节点(除了根)具有至少⌈ m/2⌉子节点。
- 如果根不是叶节点,则根至少有两个子节点。
- 具有k个子节点的非叶节点包含k -1个键。
所有叶子都出现在同一水平,没有任何信息(高度一致)。
特点:
- 关键字集合分布在整棵树中;
- 多路,非二叉树
- 每个节点既保存索引,又保存数据
- 搜索时相当于二分查找
B+树
B+树是应文件系统所需而产生的B树的变形树
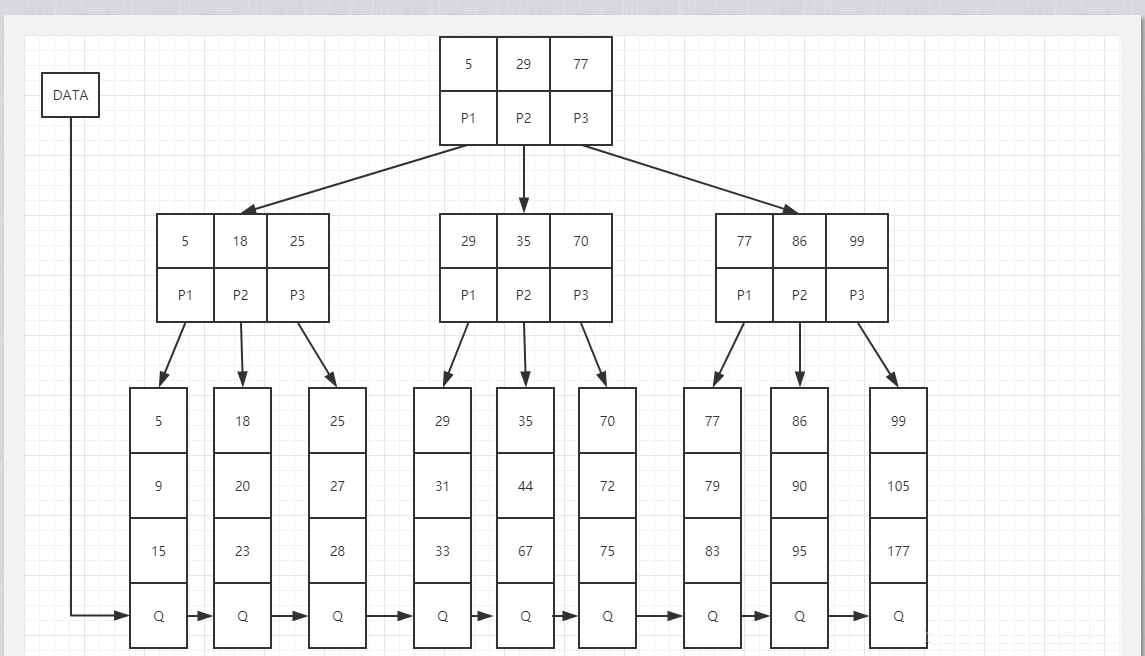
B+树有两种类型的节点:内部结点(也称索引结点)和叶子结点。内部节点就是非叶子节点,内部节点不存储数据,只存储索引,数据都存储在叶子节点。
内部结点中的key都按照从小到大的顺序排列,对于内部结点中的一个key,左树中的所有key都小于它,右子树中的key都大于等于它。叶子结点中的记录也按照key的大小排列。
每个叶子结点都存有相邻叶子结点的指针,叶子结点本身依关键字的大小自小而大顺序链接
父节点存有右孩子的第一个元素的索引。
最核心的特点如下:
(1)多路非二叉
(2)只有叶子节点保存数据
(3)搜索时相当于二分查找
(4)增加了相邻接点的指向指针
B+树为什么时候做数据库索引:由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫。简单来说就是:B+树查询某一个数据时扫描叶子节点即可;而B树需要中序遍历整个树,所以B+树更快。
为什么说B+树比B树更适合数据库索引?
1)B+树的磁盘读写代价更低
B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了;
2)B+树查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当;
3)B+树便于范围查询(最重要的原因,范围查找是数据库的常态)
B树在提高了IO性能的同时并没有解决元素遍历效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低;
B树的范围查找用的是中序遍历,而B+树用的是在链表上遍历;
树的创建
树的创建有很多种方式,分为迭代创建和递归创建。下面分别介绍这两种创建数的方式。
迭代创建
创建的树:
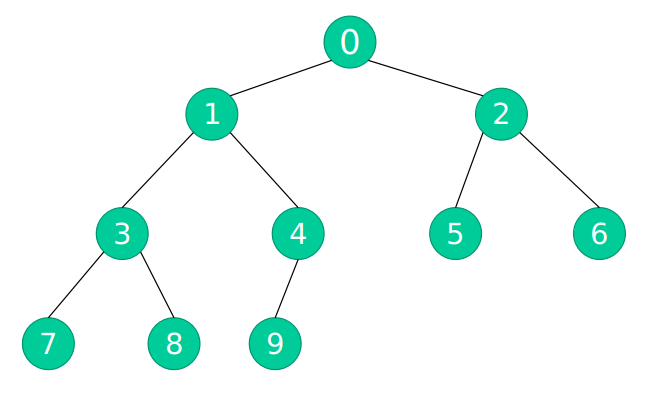
该创建方法是按照层次创建,第一层创建好之后第二层,第二层完成后创建第三层。
class Node(object):
def __init__(self,value=-1,left=None,right=None):
self.value = value
self.left = left
self.right = right
class Tree(object):
def __init__(self, root=None):
self.root = root
def insert(self,element):
node = Node(element)
if self.root == None:
self.root = node
else:
queue = []
queue.append(self.root)
while queue:
cur = queue.pop(0)
if cur.left == None:
cur.left = node
return
elif cur.right == None:
cur.right = node
return
else:
queue.append(cur.left)
queue.append(cur.right)
def output(self, root):
if root == None:
return
print(root.value)
self.output(root.left)
self.output(root.right)
one = Tree()
for i in range(10):
one.insert(i)
one.output(one.root)
递归创建
该创建方式是递归创建,前提是将树的数据组织成一个完全二叉树的形式
class Node(object):
def __init__(self,value=None):
self.value = value
self.left = None
self.right = None
def create_two(index, length, arr):
if index > length:
return None
node = Node(arr[index])
node.left = create_two(index*2+1, length, arr)
node.right = create_two(index*2+2, length, arr)
return node
def BFS(root):
queue = [root]
while queue:
cur = queue.pop(0)
print(cur.value)
if cur.left:
queue.append(cur.left)
if cur.right:
queue.append(cur.right)
arr = [1,2,3,4,None,None,None,None,None]
length = len(arr) -1
head = create_two(0,length, arr)
print(head.value)
print(head.left)
print(head.right)
BFS(head)
树的遍历
树的遍历方式有很多种,可以分为五类:
- 前序遍历
- 中序遍历
- 后序遍历
- 层次遍历
- 子树遍历
实现遍历的方式中有可以分为递归和迭代
class TreeNode(object):
def __init__(self,value=None):
self.value = value
self.left = None
self.right = None
class Tree(object):
def __init__(self):
self.root = TreeNode(None)
self.arr = []
def create(self,value):
if self.root.value is None:
self.root = TreeNode(value)
else:
queue = [self.root]
while queue:
node = queue.pop(0)
if node.left:
queue.append(node.left)
else:
node.left = TreeNode(value)
return
if node.right:
queue.append(node.right)
else:
node.right = TreeNode(value)
return
# 递归、前序遍历
def preorder(self,root):
if root is None:
return
self.arr.append(root.value)
self.preorder(root.left)
self.preorder(root.right)
# 递归、中序遍历
def inorder(self,root):
if root is None:
return
self.inorder(root.left)
self.arr.append(root.value)
self.inorder(root.right)
# 递归、后序遍历
def postorder(self,root):
if root is None:
return
self.postorder(root.left)
self.postorder(root.right)
self.arr.append(root.value)
# 迭代、前序遍历
def preorder_two(self,root):
stack = [root]
arr = []
while stack:
cur = stack.pop()
arr.append(cur.value)
if cur.right:
stack.append(cur.right)
if cur.left:
stack.append(cur.left)
print(arr)
# 迭代、后序遍历
def postorder_two(self,root):
stack = [root]
arr = []
while stack:
cur = stack.pop()
arr.append(cur.value)
if cur.left:
stack.append(cur.left)
if cur.right:
stack.append(cur.right)
print(arr[::-1])
# 迭代、中序遍历
def inorder_two(self,root):
cur = root
stack = []
arr = []
while cur or stack:
while cur:
stack.append(cur)
cur = cur.left
node = stack.pop()
arr.append(node.value)
cur = node.right
print(arr)
# 层次遍历
def levelorder(self,root):
queue = [root]
arr = []
while queue:
cur = queue.pop(0)
arr.append(cur.value)
if cur.left:
queue.append(cur.left)
if cur.right:
queue.append(cur.right)
print(arr)
# 子数遍历,返回从根节点到每一个叶子节点的一条路径
# 子数遍历,返回从根节点到每一个叶子节点的一条路径
def zishu(self,root,arr):
if not root.left and not root.right:
print(arr)
return
if root.left:
self.zishu(root.left, arr + [root.left.value])
if root.right:
self.zishu(root.right, arr + [root.right.value])
tree = Tree()
for i in range(10):
tree.create(i)
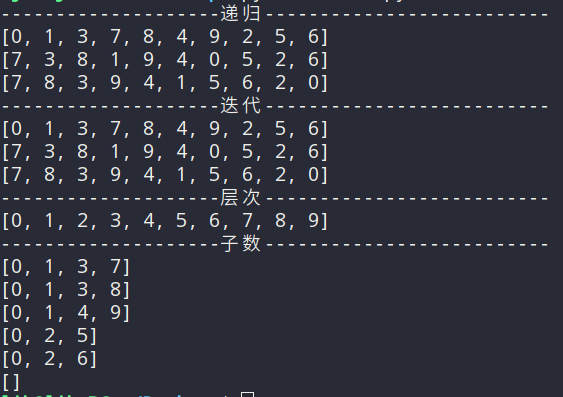
print('--------------------递归--------------------------')
tree.preorder(tree.root)
print(tree.arr)
tree.arr = []
tree.inorder(tree.root)
print(tree.arr)
tree.arr = []
tree.postorder(tree.root)
print(tree.arr)
print('--------------------迭代--------------------------')
tree.preorder_two(tree.root)
tree.inorder_two(tree.root)
tree.postorder_two(tree.root)
print('--------------------层次--------------------------')
tree.levelorder(tree.root)
print('--------------------子数--------------------------')
tree.arr = []
tree.zishu(tree.root, [tree.root.value])
print(tree.arr)
用python讲解数据结构之树的遍历的更多相关文章
- [0x00 用Python讲解数据结构与算法] 概览
自从工作后就没什么时间更新博客了,最近抽空学了点Python,觉得Python真的是很强大呀.想来在大学中没有学好数据结构和算法,自己的意志力一直不够坚定,这次想好好看一本书,认真把基本的数据结构和算 ...
- 用Python实现数据结构之树
树 树是由根结点和若干颗子树构成的.树是由一个集合以及在该集合上定义的一种关系构成的.集合中的元素称为树的结点,所定义的关系称为父子关系.父子关系在树的结点之间建立了一个层次结构.在这种层次结构中有一 ...
- Python与数据结构[3] -> 树/Tree[0] -> 二叉树及遍历二叉树的 Python 实现
二叉树 / Binary Tree 二叉树是树结构的一种,但二叉树的每一个节点都最多只能有两个子节点. Binary Tree: 00 |_____ | | 00 00 |__ |__ | | | | ...
- Python与数据结构[3] -> 树/Tree[1] -> 表达式树和查找树的 Python 实现
表达式树和查找树的 Python 实现 目录 二叉表达式树 二叉查找树 1 二叉表达式树 表达式树是二叉树的一种应用,其树叶是常数或变量,而节点为操作符,构建表达式树的过程与后缀表达式的计算类似,只不 ...
- [0x01 用Python讲解数据结构与算法] 关于数据结构和算法还有编程
忍耐和坚持虽是痛苦的事情,但却能渐渐地为你带来好处. ——奥维德 一.学习目标 · 回顾在计算机科学.编程和问题解决过程中的基本知识: · 理解“抽象”在问题解决过程中的重要作用: · 理解并实现抽象 ...
- Python与数据结构[3] -> 树/Tree[2] -> AVL 平衡树和树旋转的 Python 实现
AVL 平衡树和树旋转 目录 AVL平衡二叉树 树旋转 代码实现 1 AVL平衡二叉树 AVL(Adelson-Velskii & Landis)树是一种带有平衡条件的二叉树,一棵AVL树其实 ...
- 用python语言讲解数据结构与算法
写在前面的话:关于数据结构与算法讲解的书籍很多,但是用python语言去实现的不是很多,最近有幸看到一本这样的书籍,由Brad Miller and David Ranum编写的<Problem ...
- 用Python实现数据结构之二叉搜索树
二叉搜索树 二叉搜索树是一种特殊的二叉树,它的特点是: 对于任意一个节点p,存储在p的左子树的中的所有节点中的值都小于p中的值 对于任意一个节点p,存储在p的右子树的中的所有节点中的值都大于p中的值 ...
- python数据结构之树和二叉树(先序遍历、中序遍历和后序遍历)
python数据结构之树和二叉树(先序遍历.中序遍历和后序遍历) 树 树是\(n\)(\(n\ge 0\))个结点的有限集.在任意一棵非空树中,有且只有一个根结点. 二叉树是有限个元素的集合,该集合或 ...
随机推荐
- IL角度理解for 与foreach的区别——迭代器模式
IL角度理解for 与foreach的区别--迭代器模式 目录 IL角度理解for 与foreach的区别--迭代器模式 1 最常用的设计模式 1.1 背景 1.2 摘要 2 遍历元素 3 删除元素 ...
- Excel字符串函数
Excel字符串函数(用到的记录一下)"a1"代表a1单元格 mid(a1,start_num,nums) a1格从第start_num取nums个,从1开始. len(a1) ...
- 找回了当年一篇V4L2 linux 摄像头驱动的博客
从csdn找回 , 无缘无故被封了..当时损失不少啊!!!!!!!!! linux 摄像头驱动 :核心数据结构: /** * struct fimc_dev - abstraction ...
- PF_PACKET&&tcpdump
linux下抓包原理 linux下的抓包是通过注册一种虚拟的底层网络协议来完成对网络设备消息的处理权.当网卡接收到一个网络报文之后,它会遍历系统中所有已经注册的网络协议,当抓包模块把自己伪装成一个网络 ...
- linux 进程间通信 共享内存 shmat
系统调用mmap()通过映射一个普通文件实现共享内存.系统V则是通过映射特殊文件系统shm中的文件实现进程间的共享内存通信.也就是说,每个共享内存区域对应特殊文件系统shm中的一个文件(这是通过shm ...
- 1. 线性DP 300. 最长上升子序列 (LIS)
最经典单串: 300. 最长上升子序列 (LIS) https://leetcode-cn.com/problems/longest-increasing-subsequence/submission ...
- spring boot实现超轻量级网关(反向代理、转发)
在我们的rest服务中,需要暴露一个中间件的接口给用户,但是需要经过rest服务的认证,这是典型的网关使用场景.可以引入网关组件来搞定,但是引入zuul等中间件会增加系统复杂性,这里实现一个超轻量级的 ...
- linux中/etc/passwd和/etc/shadow文件说明
/etc/passwd是用来存储登陆用户信息: [root@localhost test]# cat /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x ...
- 01Java环境安装监测
下载安装JDK JDK:Java开发套件 JDK下载 监测JDK安装是否成功 运行Java命令 运行Javac命令
- Java8 方法引用和构造方法引用
如果不熟悉Java8新特性的小伙伴,初次看到函数式接口写出的代码可能会是一种懵逼的状态,我是谁,我在哪,我可能学了假的Java,(・∀・(・∀・(・∀・*),但是语言都是在进步的,就好比面向对象的语言 ...