2020重新出发,NOSQL,MongoDB是什么?
什么是MongoDB ?
MongoDB 是一个开源的文档数据库,它基于 C++ 语言编写,性能高,可用性强,能够自动扩展。
MongoDB 是最流行的 NoSQL 数据库之一,原生支持分布式集群架构,特别适合处理大数据,阿里巴巴、腾讯、头条、Twitter、Google、Facebook 等一线互联网公司都在使用 MongoDB 数据库。
与 HBase 相比,MongoDB 可以存储具有更加复杂的数据结构的数据,具有很强的数据描述能力。MongoDB 提供了丰富的操作功能,但是它没有类似于 SQL 的操作语言,语法规则相对比较复杂。
MongoDB(来自英文单词“Humongous”,中文含义为“庞大”)是可以应用于各种规模的企业、各个行业以及各类应用程序的开源数据库。
MongoDB的优势
MongoDB 使用广泛
MongoDB 是目前 NoSQL 数据库中使用最广泛的数据库之一,根据 DB-Engines 2020 年 9 月份发布的全球数据库排名(见图 1),前五名依次是 Oracle、MySQL、Microsoft SQL Server、PostgreSQL、MongoDB ,此排名顺序已经持续很长时间,MongoDB 排名第五,9月份 MongoDB 的分数依然保持增长,而且还是整个排行榜中增长幅度最大的一个。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-y4156G9g-1599613355326)(C:\Users\ALIENWARE\AppData\Roaming\Typora\typora-user-images\image-20200903093902688.png)]
MongoDB 性能高
MongoDB 是一个开源文档数据库,是用 C++ 语言编写的非关系型数据库。其特点是高性能、高可用、可伸缩、易部署、易使用,存储数据十分方便,主要特性有:面向集合存储,易于存储对象类型的数据,模式自由,支持动态查询,支持完全索引,支持复制和故障恢复,使用高效的二进制数据存储,文件存储格式为 BSON ( 一种 JSON 的扩展)等。
MongoDB 提供高性能数据读写功能,并且性能还在不断地提升。根据官方提供的 MongoDB 3.0 性能测试报告,在 YCSB 测试中,MongoDB 3.0 在多线程、批量插入场景下的处理速度比 MongoDB 2.6 快 7 倍。
关于读写与响应时间的具体测试结果参见图 2。
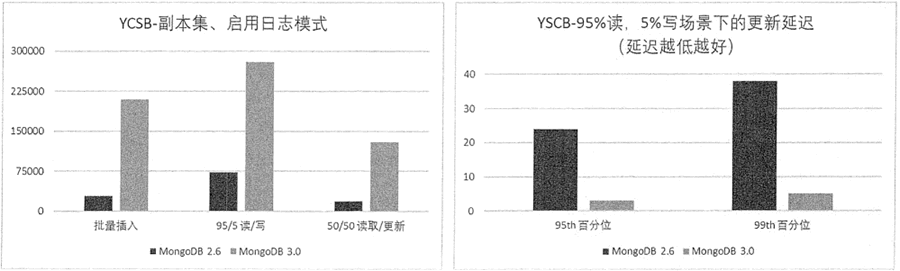
图 2:MongoDB 2.6 与 3.0 读写性能与响应时间性能测试
MongoDB 支持分布式
在生产过程中,因机器故障导致系统宕机的问题不可避免;集中式系统在计算能力和存储能力方面的瓶颈,也无法满足当前的数据量爆发式增长的需求。这两个问题就是系统对高可用和可伸缩架构的需求,MongoDB 在原生上就可满足这两方面的需求。
MongoDB 的高可用性体现在对副本集 Replication 的支持上,可伸缩性体现在分片集群的部署方式上。
MongoDB 的 Replication 集提供自动故障转移和数据冗余服务,Replication 结构可以保证数据库中的全部数据都会有多份备份,这与 HDFS 分布式文件系统的备份机制比较类似。采用副本集的集群中具有主(Master)、从(Slaver)、仲裁(Arbiter)三种角色。
主从关系(Master-Slaver) 负责数据的同步和读写分离;Arbiter 服务负责心跳(Heartbeat)监控,Master 宕机时可将 Slaver 切换到 Mas 血状态,继续提供数据的服务,完成了数据的高可用需求。
当需要存储大量的数据时,主从服务器都需要存储全部数据,可能会出现写性能问题。同时, Replication 主要解决的是读数据高可用方面的问题,在对数据库查询时也只限制在一台服务器上, 并不能支持一次查询多台数据库服务器,并没有满足数据库读写操作的分布式需求。
MongoDB 提供水平可伸缩性功能的是分片(Shard)。分片与在 HDFS 分布式文件系统中上传文件会将文件切成 128MB(Hadoop2.x 默认配置)相似,通过将数据切成数片(Sharding)写入不同的分片节点,完成分布式写的操作。同时,MongoDB 在读取时提供了分布式读的操作,这个功能与 HDFS 的分布式读写十分类似。
MongoDB 便于开发
MongoDB 对开发者十分友好,便于使用。支持丰富的查询语言、数据聚合、文本搜索和地理空间查询,用户可以创建丰富的索引来提升查询速度,MongoDB 被称为最像关系数据库的非关系数据库。
MongoDB 允许用户在服务端执行脚本,可以用 Javascript 编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,使用时直接调用即可。MongoDB 支持各种编程语言,包括 Ruby、Python、Java、C++、PHP、C# 等。
Robomongo(MongoDB可视化工具)简介
Robomongo 是一个界面友好且免费的 MongoDB 可视化工具,可在 Robomongo 官网下载此软件,其安装过程十分简单,安装好的界面如下图所示。
在 MongoDB Connections 窗口单击鼠标右键添加 MongoDB 数据库,设置如下图所示。
连接成功后,MongoDB 中所有数据库以及集合均显示在左侧导航栏,如图下所示。
从上图中可以看到 Robomango 提供可视化的界面将数据库中的文档显示出来,在集合上单击鼠标右键可以显示提供的集合操作。
使用 Robomango,初学者能更容易理解 MongoDB 数据库的概念。
MongoDB的文档数据模型
传统的文档数据库(Document Storage)概念的提岀要追溯到 1989 年,Lotus 提出的 Notes 产品被称为文档数据库,这种文档数据库常用于管理文档,如 Word、建立工作流任务等。
文档数据库区别于传统的其他数据库,它可用来管理文档,尤其擅长处理各种非结构化的文档数据。在传统的数据库中,信息被分割成离散的数据段,而在文档数据库中,文档是处理信息的基本单位。
传统的文档数据库与 20 世纪 50 ~ 60 年代管理数据的文件系统不同,文档数据库仍属于数据库范畴。
首先,文件系统中的文件基本上对应于某个应用程序。当不同的应用程序所需要的数据部分相同时,也必须建立各自的文件,而不能共享数据,而文档数据库可以共享相同的数据。因此,文件系统比文档数据库数据冗余度更大,更浪费存储空间,且更难于管理维护。
其次,文件系统中的文件是为某一特定应用服务的,因此,要想对现有的数据再增加一些新的应用是很困难的,系统难以扩展,数据和程序缺乏独立性。而文档数据库具有数据的物理独立性和逻辑独立性,数据和程序分离。
NoSQL 中的文档数据库
NoSQL 中的文档数据库(以下文档数据库均指 NoSQL 中的文档数据库)与传统的文档数据库不是同一种产品,NoSQL 中的文档数据库(MongoDB)有自己特定的数据存储结构及操作要求。
在传统数据库的发展过程中,基本都是出现一种数据模型,再依据数据模型,开发出相关的数据库,例如,层次数据库是建立在层次数据模型的基础上,关系数据库是建立在关系数据模型的基础上的。NoSQL 中文档数据库的出现也是建立在文档数据模型的基础上的。
NoSQL 中的文档数据库与传统的关系数据库均建立在对磁盘读写的基础上,实现对数据的各种操作。文档数据库的设计思路是尽可能地提升数据的读写性能,为此选择性地保留了部分关系型数据库的约束,通过减少读写过程的规则约束,提升了读写性能。
MongoDB 文档数据模型
传统的关系型数据库需要对表结构进行预先定义和严格的要求,而这样的严格要求,导致了处理数据的过程更加烦琐,甚至降低了执行效率。
在数据量达到一定规模的情况下,传统关系型数据库反应迟钝,想解决这个问题就需要反其道而行之,尽可能去掉传统关系型数据库的各种规范约束,甚至事先无须定义数据存储结构。
文档存储支持对结构化数据的访问,与关系模型不同的是,文档存储没有强制的架构。文档存储以封包键值对的方式进行存储,文档存储模型支持嵌套结构。
- 例如,文档存储模型支持 XML 和 JSON 文档,字段的“值”可以嵌套存储其他文档,也可存储数组等复杂数据类型。
MongoDB 存储的数据类型为 BSON,BSON 与 JSON 比较相似,文档存储模型也支持数组和键值对。
MongoDB 的文档数据模型如图下所示,MongoDB 的存储逻辑结构为文档,文档中采用键值对结构,文档中的 _id 为主键,默认创建主键索引。从 MongoDB 的逻辑结构可以看出,MongoDB 的相关操作大多通过指定键完成对值的操作。
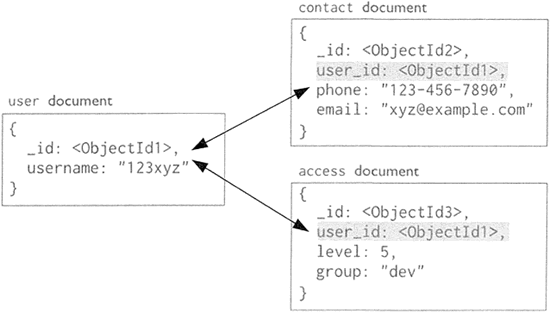
文档数据库无须事先定义数据存储结构,这与键值数据库和列族数据库类似,只需在存储时采用指定的文档结构即可。从上图可以看出,一个{}中包含了若干个键值对,大括号中的内容就被称为一条文档。
MongoDB的文档存储结构
MongoDB 文档数据库的存储结构分为四个层次,从小到大依次是:键值对、文档(document)、集合(collection)、数据库(database)。
图 1 描述了 MongoDB 的存储与 MySQL 存储的对应关系,可以看出,MongoDB中的文档、集合、数据库对应于关系数据库中的行数据、表、数据库。

图 1:MongoDB 存储与 Mysql 存储的对比
键值对
文档数据库存储结构的基本单位是键值对,具体包含数据和类型。键值对的数据包含键和值,键的格式一般为字符串,值的格式可以包含字符串、数值、数组、文档等类型。
按照键值对的复杂程度,可以将键值对分为基本键值对和嵌套键值对。
- 图 2 中的键值对中的键为字符串,值为基本类型,这种键值对就称为基本键值。
- 嵌套键值对类型如图 3 所示,从图中可以看岀, contact 的键对应的值为一个文档,文档中又包含了相关的键值对,这种类型的键值对称为嵌套键值对。
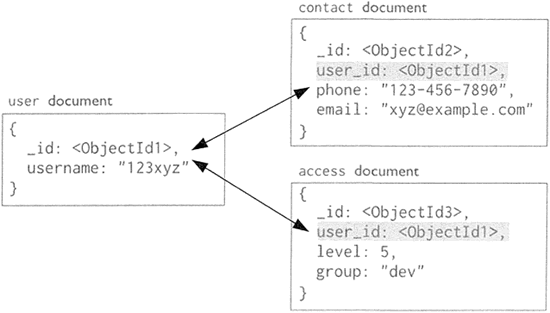
图 2:MongoDB 文档数据模型

图 3:嵌套键值对
键(Key)起唯一索引的作用,确保一个键值结构里数据记录的唯一性,同时也具有信息记录的作用。例如,country:"China",用:实现了对一条地址的分割记录,“country”起到了 “China”的唯一地址作用,另外,“country”作为键的内容说明了所对应内容的一些信息。
值(Value)是键所对应的数据,其内容通过键来获取,可存储任何类型的数据,甚至可以为空。
键和值的组成就构成了键值对(Key-Value Pair)。它们之间的关系是一一对应的,如定义了 “country:China”键值对,"country”就只能对应“China”,而不能对应“USA”。
文档中键的命名规则如下。
- UTF-8 格式字符串。
- 不用有
\0的字符串,习惯上不用.和$。 - 以开头的多为保留键,自定义时一般不以开头。
- 文档键值对是有序的,MongoDB 中严格区分大小写。
文档
文档是 MongoDB 的核心概念,是数据的基本单元,与关系数据库中的行十分类似,但是比行要复杂。文档是一组有序的键值对集合。文档的数据结构与 JSON 基本相同,所有存储在集合中的数据都是 BSON 格式。
BSON 是一种类 JSON 的二进制存储格式,是 Binary JSON 的简称。 一个简单的文档例子如下:
{"country" : "China", "city": "BeiJing"}
MongoDB 中的数据具有灵活的架构,集合不强制要求文档结构。但数据建模的不同可能会影响程序性能和数据库容量。文档之间的关系是数据建模需要考虑的重要因素。文档与文档之间 的关系包括嵌入和引用两种。
下面举一个关于顾客 patron 和地址 address 之间的例子,来说明在某些情况下,嵌入优于引用。
{_id: "joe",name: "Joe Bookreader"}{patron_id: "joe",street: "123 Fake Street",city: "Faketon",state: "MA",zip: "2345"}
关系数据库的数据模型在设计时,将 patron 和 address 分到两个表中,在查询时进行关联, 这就是引用的使用方式。如果在实际查询中,需要频繁地通过 _id 获得 address 信息,那么就需要频繁地通过关联引用来返回查询结果。在这种情况下,一个更合适的数据模型就是嵌入。
将 address 信息嵌入 patron 信息中,这样通过一次查询就可获得完整的 patron 和 address 信息,如下所示:
{_id: "joe",name: "Joe Bookreader",address: {street: "123 Fake Street",city: "Faketon”,state: nMAnzzip: T2345”}}
如果具有多个 address,可以将其嵌入 patron 中,通过一次查询就可获得完整的 patron 和多个 address 信息,如下所示:
{_id: "joe",name: "Joe Bookreader",addresses:[{street: "123 Fake Streetn,city: "Faketon",state: "MA",zip: "12345"},{street: "l Some Other Street",city: "Boston",state: "MA",zip: "12345"}]}
但在某种情况下,引用比嵌入更有优势。下面举一个图书出版商与图书信息的例子,代码如下:
{title: "MongoDB: The Definitive Guide",author: [ "Kristina Chodorow", "Mike Dirolfn"],published_date: ISODate("2010-09-24"),pages: 216,language: "English",publisher: {name: "O'Reilly Media",founded: 1980,location: "CA"}}{title: "50 Tips and Tricks for MongoDB Developer",author: "Kristina Chodorow",published_date: ISODate("2011-05-06"),pages: 68,language: "English",publisher: {name: "O'Reilly Media",founded: 1980,location: "CA"}}
从上边例子可以看出,嵌入式的关系导致出版商的信息重复发布,这时可采用引用的方式描述集合之间的关系。使用引用时,关系的增长速度决定了引用的存储位置。如果每个出版商的图书数量很少且增长有限,那么将图书信息存储在出版商文档中是可行的。
通过 books 存储每本图书的 id 信息,就可以查询到指定图书出版商的指定图书信息,但如果图书出版商的图书数量很多, 则此数据模型将导致可变的、不断增长的数组 books,如下所示:
{name: "O'Reilly Media",founded: 1980,location: "CA",books: [123456789, 234567890, …]}{_id: 123456789,title: "MongoDE: The Definitive Guide",author: ["Kristina Chodorow", "Mike Dirolf"],published_date: ISODate("2010-09-24"),pages: 216,language: "English"}{_id: 234567890,title: "50 Tips and Tricks for MongoDB Developer",author: "Kristina Chodorow",published_date: ISODate("2011-05-06"),pages: 68,language: "English"}
为了避免可变的、不断增长的数组,可以将出版商引用存放到图书文档中,如下所示:
{_id: "oreilly",name: "O'Reilly Media",founded: 1980,location: "CA"}{_id: 123456789,title: "MongoDB: The Definitive Guiden,author: [ "Kristina Chodorow", "Mike Dirolf"],published_date: ISODate("2010-09-24"),pages: 216,language: "English",publisher_id: "oreilly"}{_id: 234567890,title: "50 Tips and Tricks for MongoDB Developer",author: "Kristina Chodorow",published date: ISODate("2011-05-06"),pages: 68,language: "English",publisher_id: "oreilly"}
集合
MongoDB 将文档存储在集合中,一个集合是一些文档构成的对象。如果说 MongoDB 中的文档类似于关系型数据库中的“行”,那么集合就如同“表”。
集合存在于数据库中,没有固定的结构,这意味着用户对集合可以插入不同格式和类型的数据。但通常情况下插入集合的数据都会有一定的关联性,即一个集合中的文档应该具有相关性。
集合的结构如图 4 所示。

图 4:文档数据库中的一个集合
数据库
在 MongoDB 中,数据库由集合组成。一个 MongoDB 实例可承载多个数据库,互相之间彼此独立,在开发过程中,通常将一个应用的所有数据存储到同一个数据库中,MongoDB 将不同数据库存放在不同文件中。
数据库结构示例如图 5 所示。
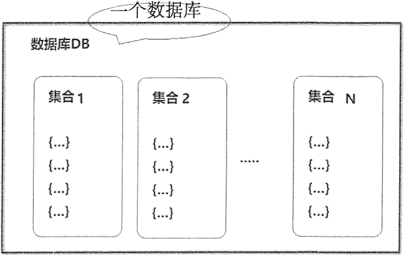
图 5:一个名为 DB 的数据库的结构
BSON对JSON做了哪些改进?
我们说,MongoDB 存储的数据格式与 JSON 十分类似,MongoDB 所采用的数据格式被称为 BSON,是一种基于 JSON 的二进制序列化格式,用于 MongoDB 存储文档并进行远程过程调用。
JSON 是一种网络常用的数据格式,具有自描述性。JSON 的数据表示方式易于解析,但支持的数据类型有限。BSON 目前主要用于 MongoDB 中,选择 JSON 进行改造的原因主要是 JSON 的通用性及 JSON 的 schemaless 的特性。
BSON 改进的主要特性有下面三点。
更快的遍历速度
BSON 对 JSON 的一个主要的改进是,在 BSON 元素的头部有一个区域用来存储元素的长度, 当遍历时,如果想跳过某个文档进行读取,就可以先读取存储在 BSON 元素头部的元素的长度, 直接 seek 到指定的点上就完成了文档的跳过。
在 JSON 中,要跳过一个文档进行数据读取,需要在对此文档进行扫描的同时匹配数据结构才可以完成跳过操作。
操作更简易
如果要修改 JSON 中的一个值,如将 9 修改为 10,这实际是将一个字符变成了两个,会导致其后面的所有内容都向后移一位。
在 BSON 中,可以指定这个列为整型,那么,当将 9 修正为 10 时,只是在整型范围内将数字进行修改,数据总长不会变化。
需要注意的是:如果数字从整型增大到长整型,还是会导致数据总长增加。
支持更多的数据类型
BSON 在 JSON 的基础上增加了很多额外的类型,BSON 增加了“byte array”数据类型。这使得二进制的存储不再需要先进行 base64 转换再存为 JSON,减少了计算开销。
BSON 支持的数据类型如表所示。
| 类型 | 描述示例 |
|---|---|
| NULL | 表示空值或者不存在的字段,{"x" : null} |
| Boolean | 布尔型有 true 和 false,{"x" : true} |
| Number | 数值:客户端默认使用 64 位浮点型数值。{"x" : 3.14} 或 {"x" : 3}。对于整型值,包括 NumberInt(4 字节符号整数)或 NumberLong(8 字节符号整数),用户可以指定数值类型,{"x" : NumberInt("3")} |
| String | 字符串:BSON 字符串是 UTF-8,{"x" : "中文"} |
| Regular Expression | 正则表达式:语法与 JavaScript 的正则表达式相同,{"x" : /[cba]/} |
| Array | 数组:使用“[]”表示,{"x" : ["a", "b", "c"]} |
| Object | 内嵌文档:文档的值是嵌套文档,{"a" : {"b" : 3}} |
| ObjectId | 对象 id:对象 id 是一个 12 字节的字符串,是文档的唯一标识,{"x" : objectId()} |
| BinaryData | 二进制数据:二进制数据是一个任意字节的字符串。它不能直接在 Shell 中使用。如果要将非 UTF-8 字符保存到数据库中,二进制数据是唯一的方式 |
| JavaScript | 代码:查询和文档中可以包括任何 JavaScript 代码,{"x" : function(){/.../}} |
| Data | 日期:{"x" : new Date()} |
| Timestamp | 时间戳:var a = new Timestamp() |
2020重新出发,NOSQL,MongoDB是什么?的更多相关文章
- 沉淀再出发:mongodb的使用
沉淀再出发:mongodb的使用 一.前言 这是一篇很早就想写却一直到了现在才写的文章.作为NoSQL(not only sql)中出色的一种数据库,MongoDB的作用是非常大的,这种文档型数据库, ...
- NOSQL -- Mongodb的简单操作与使用(win10)
NOSQL -- Mongodb的简单操作与使用(wins) MongoDB 创建集合: db.createCollection(name, options) use huhu db.createCo ...
- NOSQL -- Mongodb的简单操作与使用(wins)
NOSQL -- Mongodb的简单操作与使用(wins) 启动mongodb: 1.首先启动服务 dos命令下:net start Mongndb 也可以查询服务,手动开启服务: 完成后: 2.启 ...
- NOSQL -- mongoDB的了解与安装(Wins10)
NOSQL -- mongoDB的了解与安装 首先看看什么是nosql: 我的理解:非关系型数据库,大多是以map形式存储,map<key,value>,适合存储,查询.redis也是no ...
- 2020重新出发,NOSQL,MongoDB分布式集群架构
MongoDB分布式集群架构 看到这里相信你已经掌握了 MongoDB 的大部分基本知识,现在在单机环境下操作 MongoDB 已经不存在问题,但是单机环境只适合学习和开发测试,在实际的生产环境中,M ...
- 2020重新出发,NOSQL,什么是Redis?
@ 目录 Redis是什么? NoSQL和传统数据库的区别 Redis的优点 Redis在Java Web中的应用 缓存 高速读/写场合 Redis是什么? Redis 是一个由 Salvatore ...
- 2020重新出发,NOSQL,Redis的事务
Redis的基础事务和常用操作 和其他大部分的 NoSQL 不同,Redis 是存在事务的,尽管它没有数据库那么强大,但是它还是很有用的,尤其是在那些需要高并发的网站当中. 使用 Redis 读/写数 ...
- 2020重新出发,NOSQL,Redis主从复制
Redis主从复制 尽管 Redis 的性能很好,但是有时候依旧满足不了应用的需要,比如过多的用户进入主页,导致 Redis 被频繁访问,此时就存在大量的读操作. 对于一些热门网站的某个时刻(比如促销 ...
- 2020重新出发,NOSQL,redis高并发系统的分析和设计
高并发系统的分析和设计 任何系统都不是独立于业务进行开发的,真正的系统是为了实现业务而开发的,所以开发高并发网站抢购时,都应该先分析业务需求和实际的场景,在完善这些需求之后才能进入系统开发阶段. 没有 ...
随机推荐
- Hello GCN
参考链接: https://www.zhihu.com/question/54504471/answer/611222866 1 拉普拉斯矩阵 参考链接: http://bbs.cvmart.net/ ...
- Canal v1.1.4版本避坑指南
前提 在忍耐了很久之后,忍不住爆发了,在掘金发了条沸点(下班时发的): 这是一个令人悲伤的故事,这条情感爆发的沸点好像被屏蔽了,另外小水渠(Canal意为水道.管道)上线一段时间,不出坑的时候风平浪静 ...
- Redis服务之集群节点管理
上一篇博客主要聊了下redis cluster的部署配置,以及使用redis.trib.rb工具所需ruby环境的搭建.使用redis.trib.rb工具创建.查看集群相关信息等,回顾请参考https ...
- C#算法设计排序篇之11-二叉树排序(附带动画演示程序)
二叉树排序(Binary Tree Sort) 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/695 访问. 二叉树排序 ...
- 使用BERT进行情感分类预测及代码实例
文章目录 0. BERT介绍 1. BERT配置 1.1. clone BERT 代码 1.2. 数据处理 1.2.1预训练模型 1.2.2数据集 训练集 测试集 开发集 2. 修改代码 2.1 加入 ...
- ES读写流程
简述ES的写流程,GET读取数据流程和Search搜索数据流程. ES的读写流程主要是协调节点,主分片节点.副分片节点间的相互协调. ES的读取分为GET和Search两种操作.GET根据文档id从正 ...
- Web框架的原理详情
Web框架的原理 Web框架本质 我们可以这样理解:所有的Web应用本质上就是一个socket服务端,而用户的浏览器就是一个socket客户端. 这样我们就可以自己实现Web框架了. socket服务 ...
- es数据库基本操作
1.es建立索引: curl -XPUT 'http://10.xx.xx.xx:9200/索引名称' 2.es查询所有索引: curl -XGET 'http://10.xx.xx.xx:9200/ ...
- 手牵手,使用uni-app从零开发一款视频小程序 (系列下 开发实战篇)
系列文章 手牵手,使用uni-app从零开发一款视频小程序 (系列上 准备工作篇) 手牵手,使用uni-app从零开发一款视频小程序 (系列下 开发实战篇) 扫码体验,先睹为快 可以扫描下微信小程序的 ...
- css3 属性 text-overflow 实现截取多余文字内容 以省略号来代替多余内容
css3 属性 text-overflow: ellipsis 前言 正文 结束语 前言 我们在设计网站的时候有时会遇到这样一个需求:因为页面空间大小的问题,需要将多余的文字隐藏起来,并以省略号代替, ...