吴恩达《深度学习》-第二门课 (Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization)-第一周:深度学习的实践层面 (Practical aspects of Deep Learning) -课程笔记
第一周:深度学习的实践层面 (Practical aspects of Deep Learning)
1.1 训练,验证,测试集(Train / Dev / Test sets)
创建新应用的过程中,不可能从一开始就准确预测出一些信息和其他超级参数,例如:神经网络分多少层;每层含有多少个隐藏单元;学习速率是多少;各层采用哪些激活函数。应用型机器学习是一个高度迭代的过程。

从一个领域或者应用领域得来的直觉经验,通常无法转移到其他应用领域,最佳决策取决于 所拥有的数据量,计算机配置中输入特征的数量,用 GPU 训练还是 CPU,GPU 和 CPU 的具体配置以及其他诸多因素。
对于很多应用系统,即使是经验丰富的深度学习行家也不太可能一开始就预设出最匹配的超级参数,所以说,应用深度学习是一个典型的迭代过程,需要多次循环往复,才能为应用程序找到一个称心的神经网络,因此循环该过程的效率是决定项目进展速度的一个关键因素,而创建高质量的训练数据集,验证集和测试集也有助于提高循环效率。
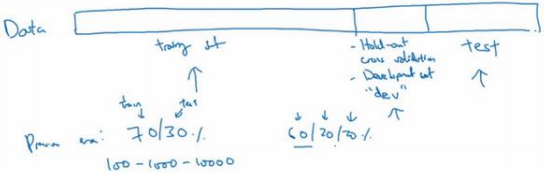
通常会将这些数据划分成几部分,一部分作为训练集,一部分作为简单交叉验证集,有时也称之为验证集(dev set)最后一部分则作为测试集。
在机器学习发展的小数据量时代,常见做法是将所有数据三七分,就是 70% 验证集,30%测试集,如果没有明确设置验证集,也可以按照60%训练,20%验证和20%测试集来划分。
在大数据时代,那么验证集和测试集占数据总量的比例会趋向于变得更小。因为验证集的目的就是验证不同的算法,检验哪种算法更有效, 因此,验证集要足够大才能评估,比如 2 个甚至 10 个不同算法,并迅速判断出哪种算法更有效。可能不需要拿出20%的数据作为验证集。验证集和测试集要小于数据总量的 20%或 10%。
根据经验,建议要确保验证集和测试集的数据来自同一分布。因为要用验证集来评估不同的模型,尽可能地优化性能。 如果验证集和测试集来自同一个分布就会很好。
最后一点,就算没有测试集也不要紧,测试集的目的是对最终所选定的神经网络系统做出无偏估计,如果不需要无偏估计,也可以不设置测试集。
1.2 偏差,方差(Bias /Variance)
过拟合、欠拟合概念
欠拟合:不能很好地拟合数据,是高偏差(high bias)的情况
过拟合:方差较高(high variance)
适度拟合(just right):介于过度拟合和欠拟合 中间的一类
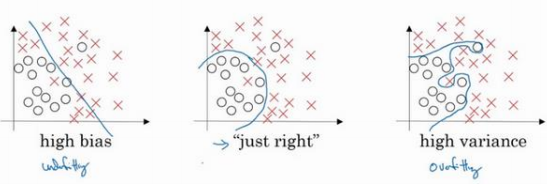
“高方差”:
假定训练集误差是 1%,验证集误差是 11%,训练集设置得非常好,而验证集设置相对较差,可能过度拟合了训练集,在某种程度上,验证集并没有充分利用交叉验证集的作用
“高偏差”:
假设训练集误差是 15%,验证集误差是 16%,人的错误率几乎为 0%,算法并没有在训练集中得到很好训练,训练数据的拟合度不高,就是数据欠拟合,就可以说这种算法偏差比较高。
它对于验证集产生的结果却是合理的,验证集中的错误率只比训练集的多了 1%,但这种算法偏差高,因为它甚至不能拟合训练集。
高、低|方差和偏差:
训练集误差是 15%,偏差相当高,但是,验证集的评估结果更糟糕,错误率达到 30%,在这种情况下,会认为这种算法偏差高,因为它在训练集上结果不理想, 而且方差也很高,这是方差偏差都很糟糕的情况。
训练集误差是 0.5%,验证集误差是 1%,只有 1%的错误率,偏差和方差都很低。
以上分析的前提都是假设基本误差很小,训练集和验证集数据来自相同分布,如果没有这些假设作为前提,分析过程更加复杂。
如果稍微改变一下分类器,它会过度拟合部分数据,用紫色线画出的分类器具有高偏差和高方差,偏差高是因为它几乎是一条线性分类器,并未拟合数据。而采用曲线函数或二次元函数会产生高方差,因为它曲线灵活性太高以致拟合了这两个错误样本和中间这些活跃数据。
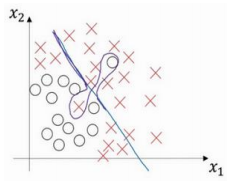
对于高维数据,有些数据区域偏差高,有些数据区域方差高。在高维数据中采用这种分类器看起来就不会那么牵强了
在训练集上训练算法产生的误差和验证集上验证算法产生的误差来诊断算法是否存在高偏差和高方差,是否两个值都高,或者两个值都不高,根据算法偏差和方差的具体情况决定接下来要做的工作。
1.3 机器学习基础(Basic Recipe for Machine Learning)
在训练神经网络时用到的基本方法:
初始模型训练完成后,首先要知道算法的偏差高不高,如果偏差较高,试着评估训练集或训练数据的性能。如果偏差的确很高,甚至无法拟合训练集,那么要做的就是选择一个新的网络,比如含有更多隐藏层或者隐藏单元的网络,或者花费更多时间来训练网络,或者尝试更先进的优化算法。也可以尝试其他方法,可能有用,也可能没用。
不过采用规模更大的网络通常都会有所帮助,延长训练时间不一定有用,但也没什么坏处。训练学习算法时,不断尝试这些方法,直到解决掉偏差问题,这是最低标准,反复尝试,直到可以拟合数据为止,至少能够拟合训练集。
一旦偏差降低到可以接受的数值,检查一下方差有没有问题,为了评估方差,要查看验证集性能,如果方差高,最好的解决办法就是采用更多数据,但有时候,无法获得更多数据。也可以尝试通过正则化来减少过拟合。总之就是不断重复尝试,直到找到一个低偏差,低方差的框架,这时就成功了。
有两点需要注意:
第一点,高偏差和高方差是两种不同的情况,后续要尝试的方法也可能完全不同, 通常会用训练验证集来诊断算法是否存在偏差或方差问题,然后根据结果选择尝试部分方 法。
第二点,在机器学习的初期阶段,能尝试的方法有很多。可以增加偏差,减少方差,也可以减少偏差,增加方差,但是在深度学习的早期阶段,没有太多工具可以做到只减少偏差或方差却不影响到另一方。但在当前的深度学习和大数据时代,只要正则适度,通常构建一个更大的网络便可以,在不影响方差的同时减少偏差,而采用更多数据通常可以在不过多影响偏差的同时 减少方差。
1.4 正则化(Regularization)
深度学习可能存在过拟合问题——高方差,有两个解决方法,一个是正则化,另一个是准备更多的数据。正则化有助于避免过度 拟合,或者减少网络误差:
在逻辑回归函数中加入正则化:
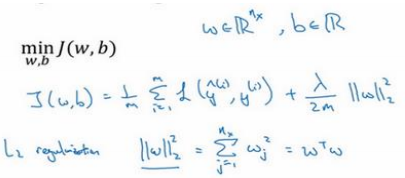
此方法称为
吴恩达《深度学习》-第二门课 (Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization)-第一周:深度学习的实践层面 (Practical aspects of Deep Learning) -课程笔记的更多相关文章
- 吴恩达《深度学习》-课后测验-第二门课 (Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization)-Week 1 - Practical aspects of deep learning(第一周测验 - 深度学习的实践)
Week 1 Quiz - Practical aspects of deep learning(第一周测验 - 深度学习的实践) \1. If you have 10,000,000 example ...
- 课程二(Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization),第二周(Optimization algorithms) —— 2.Programming assignments:Optimization
Optimization Welcome to the optimization's programming assignment of the hyper-parameters tuning spe ...
- Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization(第一周)深度学习的实践层面 (Practical aspects of Deep Learning)
1. Setting up your Machine Learning Application 1.1 训练,验证,测试集(Train / Dev / Test sets) 1.2 Bias/Vari ...
- 吴恩达课后习题第二课第三周:TensorFlow Introduction
目录 第二课第三周:TensorFlow Introduction Introduction to TensorFlow 1 - Packages 1.1 - Checking TensorFlow ...
- [C0] 人工智能大师访谈 by 吴恩达
人工智能大师访谈 by 吴恩达 吴恩达采访 Geoffery Hinton Geoffery Hinton主要观点:要阅读文献,但不要读太多,绝对不要停止编程. Geoffrey Hinton:谢谢你 ...
- 吴恩达深度学习第1课第4周-任意层人工神经网络(Artificial Neural Network,即ANN)(向量化)手写推导过程(我觉得已经很详细了)
学习了吴恩达老师深度学习工程师第一门课,受益匪浅,尤其是吴老师所用的符号系统,准确且易区分. 遵循吴老师的符号系统,我对任意层神经网络模型进行了详细的推导,形成笔记. 有人说推导任意层MLP很容易,我 ...
- 吴恩达深度学习第2课第2周编程作业 的坑(Optimization Methods)
我python2.7, 做吴恩达深度学习第2课第2周编程作业 Optimization Methods 时有2个坑: 第一坑 需将辅助文件 opt_utils.py 的 nitialize_param ...
- 吴恩达深度学习第4课第3周编程作业 + PIL + Python3 + Anaconda环境 + Ubuntu + 导入PIL报错的解决
问题描述: 做吴恩达深度学习第4课第3周编程作业时导入PIL包报错. 我的环境: 已经安装了Tensorflow GPU 版本 Python3 Anaconda 解决办法: 安装pillow模块,而不 ...
- 【吴恩达课后测验】Course 1 - 神经网络和深度学习 - 第二周测验【中英】
[中英][吴恩达课后测验]Course 1 - 神经网络和深度学习 - 第二周测验 第2周测验 - 神经网络基础 神经元节点计算什么? [ ]神经元节点先计算激活函数,再计算线性函数(z = Wx + ...
随机推荐
- 同步博客到cnblogs平台
缘由 最最开始在csdn写博客,广告太多,平台暗调资源积分,退:后来使用githubpage+jeklly搭建静态博客,感觉不错,回归到安静的敲打环境.emmmm,由于是静态博客项目,虽能最大化自定义 ...
- 5年Java程序员,五面蚂蚁险拿offer定级P7,大厂面试不过如此?
当时面试能记下的就这些了,可能不太全请见谅: 一面 1.HashMap和ConcurrentHashMap: 2.再谈谈一致hash算法? 3.乐观锁还有悲观锁: 4.可重入锁和Synchronize ...
- 第一篇博客 Python开发环境配置
本文主要介绍Windows7环境下安装并配置Anaconda+VSCode作为Python开发环境. 目录 Anaconda与包管理配 Anaconda安装 添加环境变量 Anaconda安装错误及解 ...
- YApi——手摸手,带你在Win10环境下安装YApi可视化接口管理平台
手摸手,带你在Win10环境下安装YApi可视化接口管理平台 YApi YApi 是高效.易用.功能强大的 api 管理平台,旨在为开发.产品.测试人员提供更优雅的接口管理服务.可以帮助开发者轻松创建 ...
- UML活动图(二)
转载于https://www.cnblogs.com/xiaolongbao-lzh/p/4591953.html 活动图概述 •活动图和交互图是UML中对系统动态方面建模的两种主要形式 •交互图强调 ...
- python爬虫以及后端开发--实用加密模板整理
都是作者累积的,且看其珍惜,大家可以尽量可以保存一下,如果转载请写好出处https://www.cnblogs.com/pythonywy 一.md5加密 1.简介 这是一种使用非常广泛的加密方式,不 ...
- Jmeter 常用函数(23)- 详解 __longSum
如果你想查看更多 Jmeter 常用函数可以在这篇文章找找哦 https://www.cnblogs.com/poloyy/p/13291704.htm 作用 计算两个或多个长值的和 注意 当值不在 ...
- 结构体深度比较 reflect.DeepEqual
demo1 package main import ( "fmt" "reflect" ) func main() { sliceMap1 := make([] ...
- neutron-server Connection pool is full, discarding connection 连接池过满
参考链接:https://zhiliao.h3c.com/Theme/details/48291 问题: -- ::33.235 WARNING requests.packages.urllib3.c ...
- Maven通解
参考博文:通俗理解maven 该篇文章篇幅很长,大概的思路如下 maven的介绍,初步认识,获取jar包的三个关键属性 --> 介绍仓库(获取的jar包从何而来)-->用命令行管理ma ...