主成分分析PCA数据降维原理及python应用(葡萄酒案例分析)
目录
主成分分析(PCA)——以葡萄酒数据集分类为例
1、认识PCA
(1)简介
数据降维的一种方法是通过特征提取实现,主成分分析PCA就是一种无监督数据压缩技术,广泛应用于特征提取和降维。
换言之,PCA技术就是在高维数据中寻找最大方差的方向,将这个方向投影到维度更小的新子空间。例如,将原数据向量x,通过构建 维变换矩阵 W,映射到新的k维子空间,通常(
)。
原数据d维向量空间 经过
,得到新的k维向量空间
.
第一主成分有最大的方差,在PCA之前需要对特征进行标准化,保证所有特征在相同尺度下均衡。
(2)方法步骤
- 标准化d维数据集
- 构建协方差矩阵。
- 将协方差矩阵分解为特征向量和特征值。
- 对特征值进行降序排列,相应的特征向量作为整体降序。
- 选择k个最大特征值的特征向量,
。
- 根据提取的k个特征向量构造投影矩阵
。
- d维数据经过
下面使用python逐步完成葡萄酒的PCA案例。
2、提取主成分
下载葡萄酒数据集wine.data到本地,或者到时在加载数据代码是从远程服务器获取,为了避免加载超时推荐下载本地数据集。
来看看数据集长什么样子!一共有3类,标签为1,2,3 。每一行为一组数据,由13个维度的值表示,我们将它看成一个向量。
开始加载数据集。
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt # load data
df_wine = pd.read_csv('D:\\PyCharm_Project\\maching_learning\\wine_data\\wine.data', header=None) # 本地加载,路径为本地数据集存放位置
# df_wine=pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data',header=None)#服务器加载
下一步将数据按7:3划分为training-data和testing-data,并进行标准化处理。
# split the data,train:test=7:3
x, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, stratify=y, random_state=0) # standardize the feature 标准化
sc = StandardScaler()
x_train_std = sc.fit_transform(x_train)
x_test_std = sc.fit_transform(x_test)
这个过程可以自行打印出数据进行观察研究。
接下来构造协方差矩阵。 维协方差对称矩阵,实际操作就是计算不同特征列之间的协方差。公式如下:
公式中,jk就是在矩阵中的行列下标,i表示第i行数据,分别为特征列 j,k的均值。最后得到的协方差矩阵是13*13,这里以3*3为例,如下:
下面使用numpy实现计算协方差并提取特征值和特征向量。
# 构造协方差矩阵,得到特征向量和特征值
cov_matrix = np.cov(x_train_std.T)
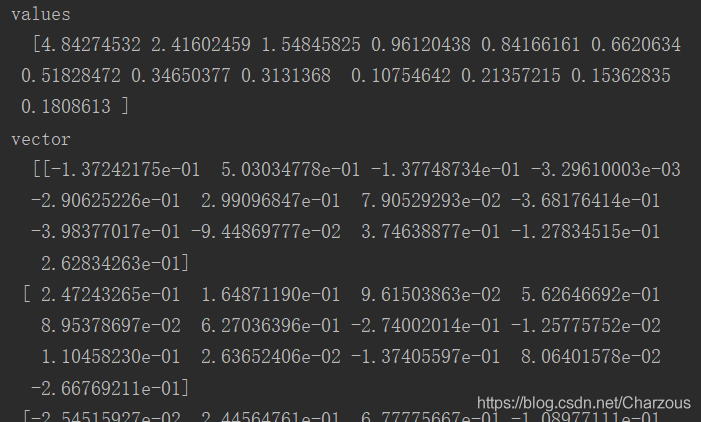
eigen_val, eigen_vec = np.linalg.eig(cov_matrix)
# print("values\n ", eigen_val, "\nvector\n ", eigen_vec)# 可以打印看看
3、主成分方差可视化
首先,计算主成分方差比率,每个特征值方差与特征值方差总和之比:
代码实现:
# 解释方差比
tot = sum(eigen_val) # 总特征值和
var_exp = [(i / tot) for i in sorted(eigen_val, reverse=True)] # 计算解释方差比,降序
# print(var_exp)
cum_var_exp = np.cumsum(var_exp) # 累加方差比率
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
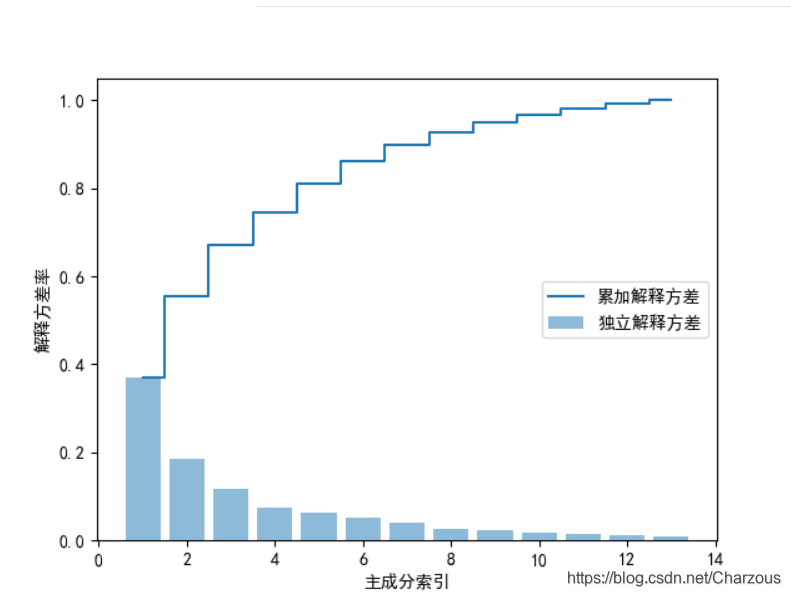
plt.bar(range(1, 14), var_exp, alpha=0.5, align='center', label='独立解释方差') # 柱状 Individual_explained_variance
plt.step(range(1, 14), cum_var_exp, where='mid', label='累加解释方差') # Cumulative_explained_variance
plt.ylabel("解释方差率")
plt.xlabel("主成分索引")
plt.legend(loc='right')
plt.show()
可视化结果看出,第一二主成分占据大部分方差,接近60%。
4、特征变换
这一步需要构造之前讲到的投影矩阵,从高维d变换到低维空间k。
先将提取的特征对进行降序排列:
# 特征变换
eigen_pairs = [(np.abs(eigen_val[i]), eigen_vec[:, i]) for i in range(len(eigen_val))]
eigen_pairs.sort(key=lambda k: k[0], reverse=True) # (特征值,特征向量)降序排列
从上步骤可视化,选取第一二主成分作为最大特征向量进行构造投影矩阵。
w = np.hstack((eigen_pairs[0][1][:, np.newaxis], eigen_pairs[1][1][:, np.newaxis])) # 降维投影矩阵W
13*2维矩阵如下:
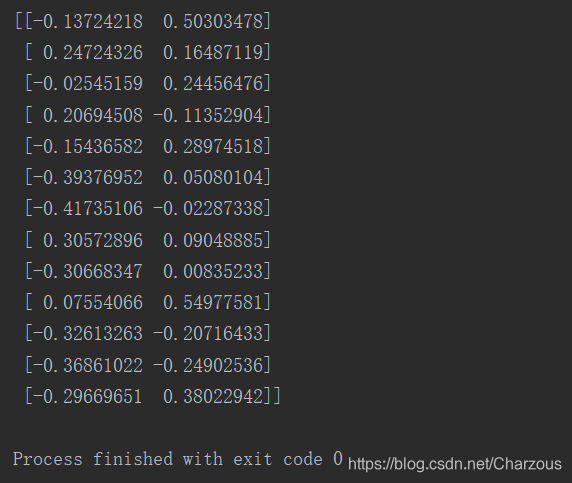
这时,将原数据矩阵与投影矩阵相乘,转化为只有两个最大的特征主成分。
x_train_pca = x_train_std.dot(w)
5、数据分类结果
使用 matplotlib进行画图可视化,可见得,数据分布更多在x轴方向(第一主成分),这与之前方差占比解释一致,这时可以很直观区别3种不同类别。
代码实现:
color = ['r', 'g', 'b']
marker = ['s', 'x', 'o']
for l, c, m in zip(np.unique(y_train), color, marker):
plt.scatter(x_train_pca[y_train == l, 0],
x_train_pca[y_train == l, 1],
c=c, label=l, marker=m)
plt.title('Result')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.legend(loc='lower left')
plt.show()
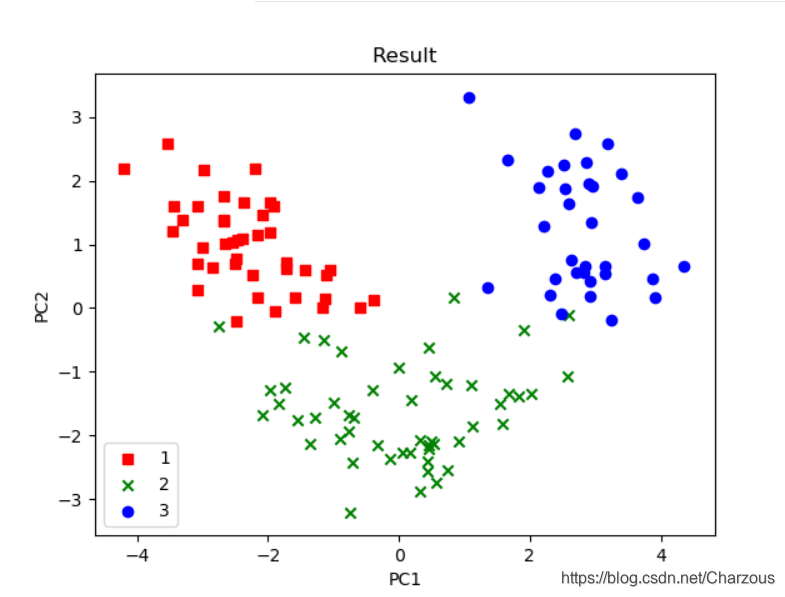
本案例介绍PCA单个步骤和实现过程,一点很重要,PCA是无监督学习技术,它的分类没有使用到样本标签,上面之所以看出3类不同标签,是后来画图时候自行添加的类别区分标签。
6、完整代码


import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt def main():
# load data
df_wine = pd.read_csv('D:\\PyCharm_Project\\maching_learning\\wine_data\\wine.data', header=None) # 本地加载
# df_wine=pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data',header=None)#服务器加载 # split the data,train:test=7:3
x, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, stratify=y, random_state=0) # standardize the feature 标准化单位方差
sc = StandardScaler()
x_train_std = sc.fit_transform(x_train)
x_test_std = sc.fit_transform(x_test)
# print(x_train_std) # 构造协方差矩阵,得到特征向量和特征值
cov_matrix = np.cov(x_train_std.T)
eigen_val, eigen_vec = np.linalg.eig(cov_matrix)
# print("values\n ", eigen_val, "\nvector\n ", eigen_vec) # 解释方差比
tot = sum(eigen_val) # 总特征值和
var_exp = [(i / tot) for i in sorted(eigen_val, reverse=True)] # 计算解释方差比,降序
# print(var_exp)
# cum_var_exp = np.cumsum(var_exp) # 累加方差比率
# plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
# plt.bar(range(1, 14), var_exp, alpha=0.5, align='center', label='独立解释方差') # 柱状 Individual_explained_variance
# plt.step(range(1, 14), cum_var_exp, where='mid', label='累加解释方差') # Cumulative_explained_variance
# plt.ylabel("解释方差率")
# plt.xlabel("主成分索引")
# plt.legend(loc='right')
# plt.show() # 特征变换
eigen_pairs = [(np.abs(eigen_val[i]), eigen_vec[:, i]) for i in range(len(eigen_val))]
eigen_pairs.sort(key=lambda k: k[0], reverse=True) # (特征值,特征向量)降序排列
# print(eigen_pairs)
w = np.hstack((eigen_pairs[0][1][:, np.newaxis], eigen_pairs[1][1][:, np.newaxis])) # 降维投影矩阵W
# print(w)
x_train_pca = x_train_std.dot(w)
# print(x_train_pca)
color = ['r', 'g', 'b']
marker = ['s', 'x', 'o']
for l, c, m in zip(np.unique(y_train), color, marker):
plt.scatter(x_train_pca[y_train == l, 0],
x_train_pca[y_train == l, 1],
c=c, label=l, marker=m)
plt.title('Result')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.legend(loc='lower left')
plt.show() if __name__ == '__main__':
main()
总结:
本案例介绍PCA步骤和实现过程,单步进行是我更理解PCA内部实行的过程,主成分分析PCA作为一种无监督数据压缩技术,学习之后更好掌握数据特征提取和降维的实现方法。记录学习过程,不仅能让自己更好的理解知识,而且能与大家共勉,希望我们都能有所帮助!
我的博客园:
我的CSDN:原创 PCA数据降维原理及python应用(葡萄酒案例分析)
主成分分析PCA数据降维原理及python应用(葡萄酒案例分析)的更多相关文章
- LDA线性判别分析原理及python应用(葡萄酒案例分析)
目录 线性判别分析(LDA)数据降维及案例实战 一.LDA是什么 二.计算散布矩阵 三.线性判别式及特征选择 四.样本数据降维投影 五.完整代码 结语 一.LDA是什么 LDA概念及与PCA区别 LD ...
- [机器学习]-PCA数据降维:从代码到原理的深入解析
&*&:2017/6/16update,最近几天发现阅读这篇文章的朋友比较多,自己阅读发现,部分内容出现了问题,进行了更新. 一.什么是PCA:摘用一下百度百科的解释 PCA(Prin ...
- 深入学习主成分分析(PCA)算法原理(Python实现)
一:引入问题 首先看一个表格,下表是某些学生的语文,数学,物理,化学成绩统计: 首先,假设这些科目成绩不相关,也就是说某一科目考多少分与其他科目没有关系,那么如何判断三个学生的优秀程度呢?首先我们一眼 ...
- 机器学习--主成分分析(PCA)算法的原理及优缺点
一.PCA算法的原理 PCA(principle component analysis),即主成分分析法,是一个非监督的机器学习算法,是一种用于探索高维数据结构的技术,主要用于对数据的降维,通过降维可 ...
- 【Python代码】TSNE高维数据降维可视化工具 + python实现
目录 1.概述 1.1 什么是TSNE 1.2 TSNE原理 1.2.1入门的原理介绍 1.2.2进阶的原理介绍 1.2.2.1 高维距离表示 1.2.2.2 低维相似度表示 1.2.2.3 惩罚函数 ...
- 主成分分析 (PCA) 与其高维度下python实现(简单人脸识别)
Introduction 主成分分析(Principal Components Analysis)是一种对特征进行降维的方法.由于观测指标间存在相关性,将导致信息的重叠与低效,我们倾向于用少量的.尽可 ...
- PCA数据降维
Principal Component Analysis 算法优缺点: 优点:降低数据复杂性,识别最重要的多个特征 缺点:不一定需要,且可能损失有用的信息 适用数据类型:数值型数据 算法思想: 降维的 ...
- 初识PCA数据降维
PCA要做的事降噪和去冗余,其本质就是对角化协方差矩阵. 一.预备知识 1.1 协方差分析 对于一般的分布,直接代入E(X)之类的就可以计算出来了,但真给你一个具体数值的分布,要计算协方差矩阵,根据这 ...
- 运用sklearn进行主成分分析(PCA)代码实现
基于sklearn的主成分分析代码实现 一.前言及回顾 二.sklearn的PCA类介绍 三.分类结果区域可视化函数 四.10行代码完成葡萄酒数据集分类 五.完整代码 六.总结 基于sklearn的主 ...
随机推荐
- react : umi 引入 antd 踩坑
首先要明确一个问题. 不管是 antd 还是 dva 还是别的什么东西,他们都是 umi 的插件——只要这个项目是使用 umi 脚手架生成的. 所以第一步应该是 .umirc.js (config.j ...
- Codeforces1379-题解
很久以前,申蛤申请了一个cf号叫 wzxakioi 有一天,戌蛤带着申蛤用这个账号打了一场div3,然后它的rating超过了shzr 之后申蛤又用这个号打了三场div2,于是 CF1379C 题意 ...
- 数据库分布式事务XA规范介绍及Mysql底层实现机制
1. 引言 分布式事务主要应用领域主要体现在数据库领域.微服务应用领域.微服务应用领域一般是柔性事务,不完全满足ACID特性,特别是I隔离性,比如说saga不满足隔离性,主要是通过根据分支事务执行成功 ...
- django-celery 版本 常用命令
http://celery.github.io/django-celery/introduction.html #先启动服务器 python manage.py runserver #再启动worke ...
- Docker 概念-1
阅读本文大概需要15分钟,通过阅读本文你将知道一下概念: 容器 什么是Docker? Docker思想.特点 Docker容器主要解决什么问题 容器 VS 虚拟机 Docker基本概念: 镜像(Ima ...
- websocket推送进度条百分比给前台
说明:后台springboot项目 前台vue+element-UI 直接放代码: //别忘了开启springboot的websocket <dependency> <groupId ...
- windows下nginx问题:[crit] 796#7096: *1 GetFileAttributesEx() "F: ginx-1.12.2\html\dist" failed (123: The filename, directory name, or volume label syntax is incorrect), client: 127.0.0.1, server: localho
错误信息: 2019/09/09 13:54:37 [crit] 796#7096: *1 GetFileAttributesEx() "F: ginx-1.12.2\html\dist&q ...
- Spring报错: org.springframework.beans.factory.CannotLoadBeanClassException: Cannot find class [xxx]
如果确实没有这个类,就挨个将总项目,子项目clean,install一下,注意他们的依赖关系.
- PHP date_get_last_errors() 函数
------------恢复内容开始------------ 实例 返回解析日期字符串时的警告和错误: <?phpdate_create("gyuiyiuyui%&&/ ...
- 重学c#系列——异常(六)
前言 用户觉得异常是不好的,认为出现异常是写的人的问题. 这是不全面,错误的出现并不总是编写程序的人的原因,有时会因为应用程序的最终用户引发的动作或运行代码的环境而发生错误,比如你用android4去 ...