pytorch——合并分割
分割与合并
- import torch
- import numpy as np
- #假设a是班级1-4的数据,每个班级里有32个学生,每个学生有8门分数
- #假设b是班级5-9的数据,每个班级里有32个学生,每个学生有8门分数
- #现在要将两个班级合并
- a=torch.rand(4,32,8)
- b=torch.rand(5,32,8)
- c=torch.cat([a,b],dim=0) #在0维度上进行a和b的拼接.注意只有在拼接的维度上数字可以不一致
- print(c.shape)
- #使用stack拼接
- c1=torch.rand(3,8)
- d1=torch.rand(3,8)
- cd=torch.stack([c1,d1],dim=0)
- print('使用stack拼接',cd.shape) #在0维度进行拼接,会在前面插入多一个2的维度,
- # 如果新生维度取0就是取上半部分,如果取1就是取下半部分
- print('这里是c1',c1)
- print('这里是d1',d1)
- print('取上半部分',cd[0,0:,0:])
- print('取上半部分',cd[1,0:,0:])
- #拆分操作
- #现在想吧(3,32,8)拆分成三个(1,32,8)
- t1=torch.rand(3,32,8)
- ts1,ts2,ts3=t1.split(1,dim=0) #将维度0拆分成每个都是1的
- print(ts1.shape,ts2.shape,ts3.shape)
- #现在想吧(3,32,8)拆分成两个(2,32,8)和(1,32,8)
- ts1,ts2=t1.split([2,1],dim=0) #将维度0拆分成第一组两个,第二组1个
- print(ts1.shape,ts2.shape)
- #使用chunk按块的数量拆分
- t1=torch.rand(6,32,8)
- ts1,ts2,ts3=t1.chunk(3,dim=0) #将维度0拆分成3块
- print(ts1.shape,ts2.shape,ts3.shape)
数学运算
- #数学运算
- a=torch.rand(3,4)
- b=torch.rand(4)
- print(a+b) #能执行成功是因为b会用自动拓展使得变成(1,4),然后变成(3,4)来和a运算
- #print(a*b)
- #print(a/b)
- #print(a-b)
- #矩阵相乘torch.matmul
- a=torch.ones(3,3)
- b=torch.tensor([[2,2,2],[2,2,2],[2,2,2]]).type(torch.float32)
- print(torch.matmul(a,b))
- #四维情况下的matmul,此时前两维度不变,取后两维做成矩阵然后进行乘积
- a=torch.rand(4,3,28,64)
- b=torch.rand(4,3,64,32)
- print(torch.matmul(a,b).shape)
- #有关于取值
- qq=torch.tensor(3.14)
- print('向下取',qq.floor(),'向上取',qq.ceil(),'取整数部分',qq.trunc(),'取小数部分',qq.frac())
- print('四舍五入取整',qq.round())
- #筛选
- grad=torch.rand(2,3)*15
- print(grad.max())
- print(grad.median())
- print(grad)
- print(grad.clamp(9)) #小于9的变成9
- print(grad.clamp(6,9)) #大于9的变成9,小于6的变成6
- #求范数
- f=torch.tensor([[2,2,2,2],[2,2,2,2]]).type(torch.float32)
- print(f.norm(1),f.norm(2)) #可以加上dim指定某个维度求范数
- #mean和prod和max和min 括号里面如果不加维度的参数会默认将所有维度打平成一个向量来求
- m=torch.tensor([[0,1,2,3],[4,5,6,7]]).type(torch.float32)
- print(m.shape)
- #mean等于的是求和起来再除以size
- print(m.mean())
- #prod是乘积
- print(m.prod())
- #上面是打平来求的,下面来看不打平的
- print('不打平的求后面这两个列的乘积',m.prod(1))
- print('返回列的最大值的索引',m.argmax(1))
高级操作
- #keepdim用于求max或者argmax的时候,维度不改变,其他位置自动添加1
- #topk,按顺序取几个大的
- cd=torch.rand(2,3)
- print('初始的tensor',cd)
- print('取1维(针对前面的那一维也就是行)上最大的两个',cd.topk(2,dim=1))
- #topk,按顺序取几个小的
- cd=torch.rand(2,3)
- print('初始的tensor',cd)
- print('取1维(针对前面的那一维也就是行)上最小的两个',cd.topk(2,dim=1,largest=False))
- #取第n个小的
- cd=torch.rand(2,8)
- print('初始的tensor',cd)
- print('取1维(针对前面的那一维也就是行)上最小的第五个(第五小)',cd.kthvalue(5,dim=1))
- # where把用其他两个tensort通过特定的条件生成一个tensor
- cond=torch.tensor([[0.679,0.7271],[0.8884,0.4163]])
- a=torch.tensor([[0.,0.],[0.,0.]])
- b=torch.tensor([[1.,1.],[1.,1.]])
- print(torch.where(cond>0.5,a,b))
神经元——激活函数
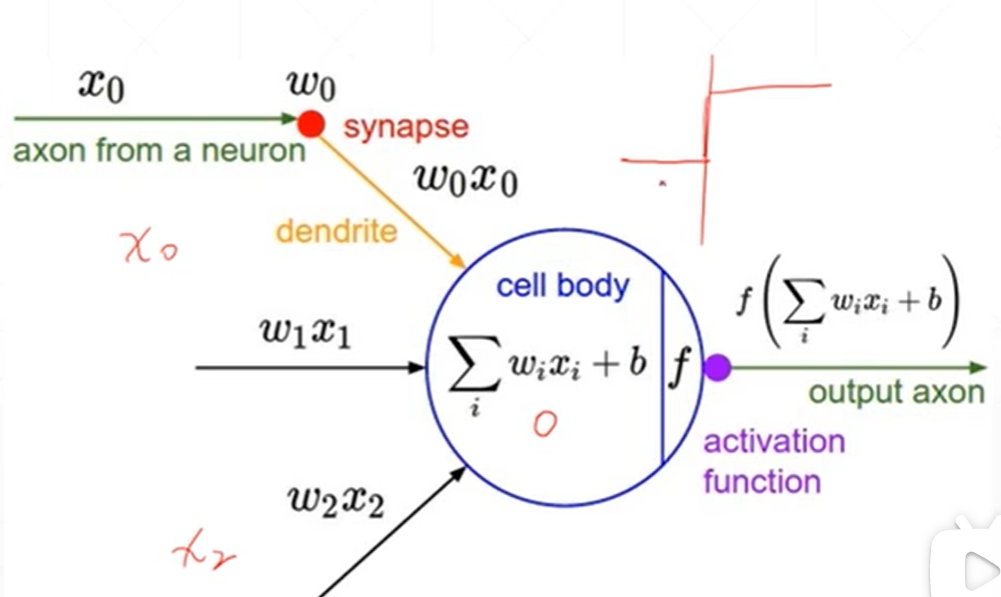
有x0到xi的多个输入,然后经过多个输入的ax+b的加权平均得到一个值,如果这个值大于阈值就可以做出反应,
而且这个反应的输出点平是定的,如果这个值不达到阈值就不会作出反应
为了弄可以求导的连续的提出了一种激活函数sigmoid(区间从0到1)
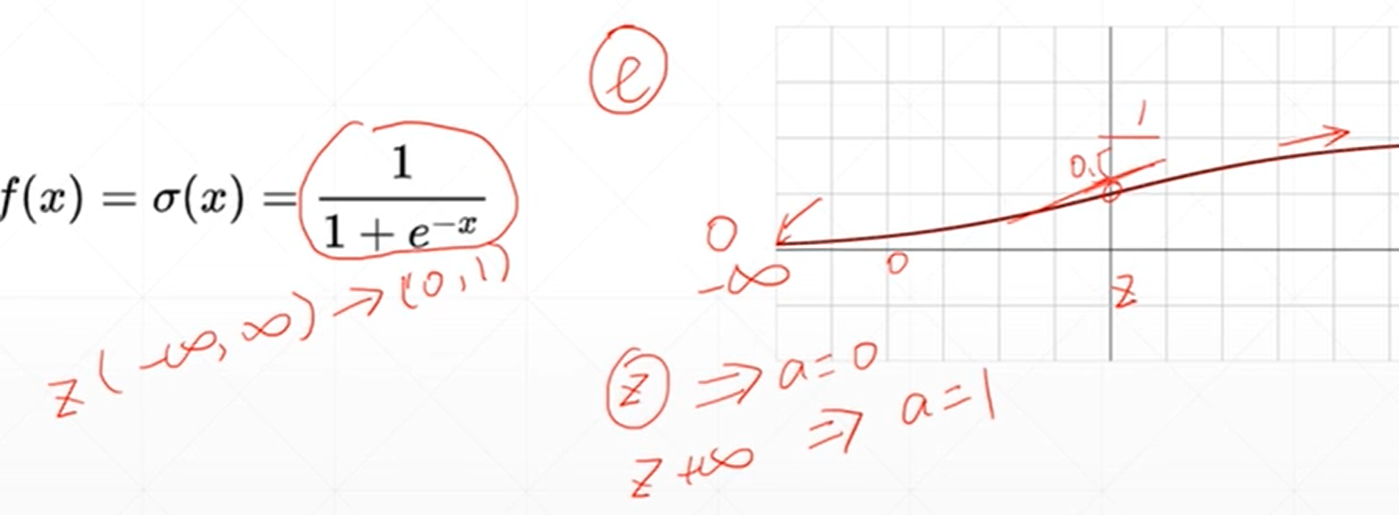
激活函数的导数
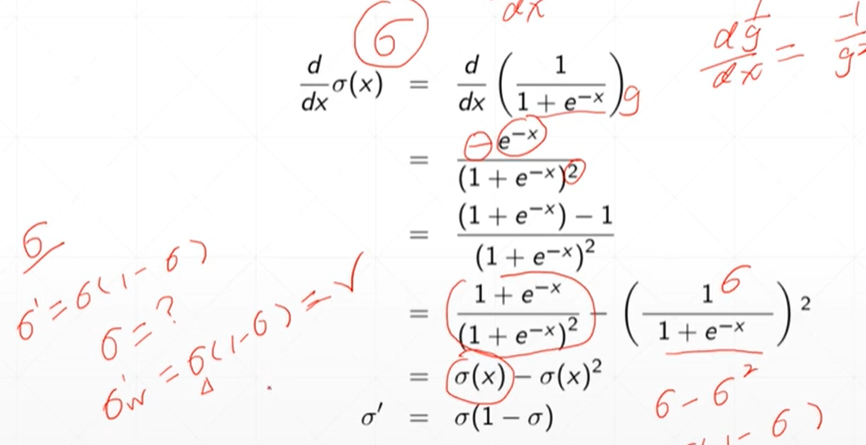
- #调用sigmore函数
- sig=torch.linspace(-100,100,10)
- print(torch.sigmoid(sig))
另外一种的激活函数tanh(区间从-1到1)

tanh激活函数求得的导数的值
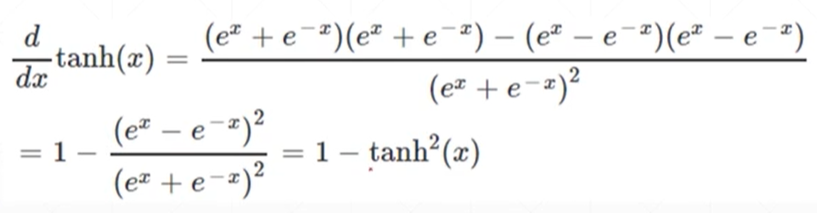
- #调用tanh函数
- tanh=torch.linspace(-3,3,5)
- print(torch.tanh(tanh))
relu整形的线性单元
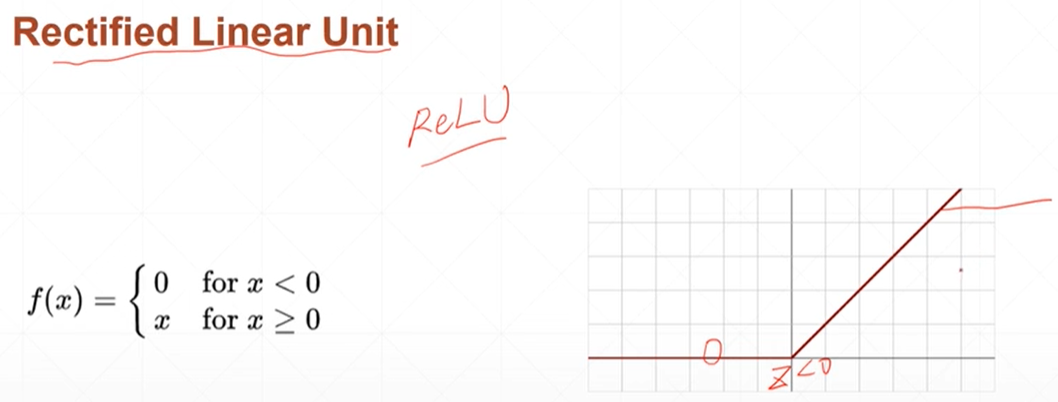
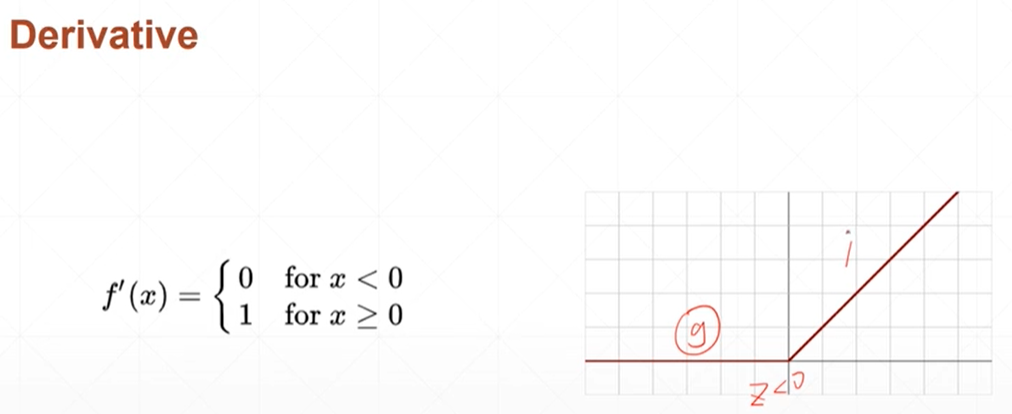
- #调用relu函数
- relu=torch.linspace(-3,3,5)
- print(torch.relu(relu))
loss损失种类及其求导后的公式
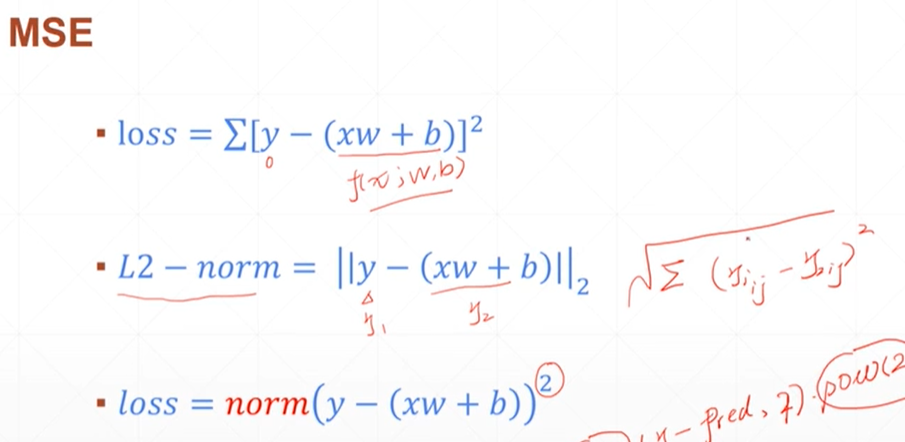
1.均方差
均方差里面有两种,一种是loss还有一种是norm,norm相当于是对loss的开平方
- import torch
- x = torch.tensor([1]).type(torch.float32) #x的值是单个数字1
- x.requires_grad_() #设置x是需要进行求导的
- y = x*2 #公式
- grads = torch.autograd.grad(outputs=y, inputs=x)[0] #导数是output(y)去对input--x求导,由于y=2*1=2是标量,不是向量
- #所以不用设置grad_outputs
- print(grads)
pytorch——合并分割的更多相关文章
- js数组常用操作方法小结(增加,删除,合并,分割等)
本文实例总结了js数组常用操作方法.分享给大家供大家参考,具体如下: var arr = [1, 2, 3, 4, 5]; //删除并返回数组中第一个元素 var theFirst = arr.shi ...
- 【daily】文件分割限速下载,及合并分割文件
说明 主要功能: 1) 分割文件, 生成下载任务; 2) 定时任务: 检索需要下载的任务, 利用多线程下载并限制下载速度; 3) 定时任务: 检索可合并的文件, 把n个文件合并为完整的文件. GitH ...
- NumPy学习(索引和切片,合并,分割,copy与deep copy)
NumPy学习(索引和切片,合并,分割,copy与deep copy) 目录 索引和切片 合并 分割 copy与deep copy 索引和切片 通过索引和切片可以访问以及修改数组元素的值 一维数组 程 ...
- Linux大文件split分割以及cat合并
文件大小分割文件时,需要以-C参数指定分割后的文件大小: $ split -C 100M large_file.txt stxt 如上所示,我们将大文件large_file.txt按100M大小进 ...
- Linux中split大文件分割和cat合并文件
当需要将较大的数据上传到服务器,或从服务器下载较大的日志文件时,往往会因为网络或其它原因而导致传输中断而不得不重新传输.这种情况下,可以先将大文件分割成小文件后分批传输,传完后再合并文件. 1.分割 ...
- WinRAR分割超大文件
在自己的硬盘上有一个比较大的文件,想把它从网上通过E-Mail发送给朋友时,却发现对方的收信服务器不能够支持那么大的文件……,这时即使用ZIP等压缩软件也无济于事,因为该文件本身已经被压缩过了.于是许 ...
- Atitit 数据存储视图的最佳实际best practice attilax总结
Atitit 数据存储视图的最佳实际best practice attilax总结 1.1. 视图优点:可读性的提升1 1.2. 结论 本着可读性优先于性能的原则,面向人类编程优先于面向机器编程,应 ...
- FastReport.Net 常用功能总汇
一.常用控件 文本框:输入文字或表达式 表格:设置表格的行列数,输入数字或表达式 子报表:放置子报表后,系统会自动增加一个页面,你可以在此页面上设计需要的报表.系统在打印处理时,先按主报表打印,当碰到 ...
- python字符串及其方法详解
首先来一段字符串的基本操作 str1="my little pony" str2="friendship is magic" str3=str1+", ...
随机推荐
- 彻底理解Spring如何解决循环依赖
Spring bean生命周期 可以简化为以下5步. 1.构建BeanDefinition 2.实例化 Instantiation 3.属性赋值 Populate 4.初始化 Initializati ...
- Docker 部署 _实现每日情话 定时推送(apscheduler)
由于最近工作比较忙,后续博客可能更新不及时,哈哈 前言: 由于python对于微信推送不够友好,需要扫码登录,短信接口需要RMB.我就想到了qq邮箱发送到好友,然而微信有qq邮箱提醒功能,就实现了我需 ...
- http详解笔记
http详解笔记 http,(HyperText Transfer Protocol),超文本传输协议,亦成为超文本转移协议 通常使用的网络是在TCP/IP协议族的基础上运作的,HTTP属于它的一 ...
- spring整合sharding-jdbc实现分库分表
1.创建两个库,每个库创建两个分表t_order_1,t_order_2 DROP TABLE IF EXISTS `t_order_1`; CREATE TABLE `t_order_1` ( `i ...
- 区块链从零开始做开发(0):hyperledger Fabric2.3安装
一.前言 各位看官好,这是本人第一篇技术博客. 写博客的契机是因为原来配的环境在虚拟机扩容后莫名奇妙崩了(具体情况我以后会写),为了以后的自己特此从头开始记录.以前都是作为一个读者,这次终于有机会能够 ...
- Java 从 Redis中取出的Json字符串 带斜杠的问题解决方案
Java 从 Redis中取出的Json字符串 带斜杠的问题: { "code": 200, "message": "成功", " ...
- Scrum转型(二) Scrum的角色
1.1 ScurmMaster 作为Scrum流程的捍卫者和布道者,ScrumMaster在Scrum团队中起到至关重要的作用,他们确保团队使用正确的流程,确保团队正确地召开各种会议,他们训练团队的敏 ...
- JS内存
内存是用来存什么的 通俗的来说呢,就是用来存 var let function const 声明的变量. 内存的大小 与操作系统有关,64位1.4G 32位0.7G. 为啥内存大小要这么设计,为啥不是 ...
- JVM 源码分析(二):搭建 JDK 8 源码调试环境(Windows 上使用 CLion)
前言 一.准备源码 二.安装 "Bootstrap JDK" 三.配置编译环境 四.编译与测试 五.安装 CMake 和 GDB 五.准备远程调试 六.开始远程调试 前言 上一篇文 ...
- kafka 异步双活方案 mirror maker2 深度解析
mirror maker2背景 通常情况下,我们都是使用一套kafka集群处理业务.但有些情况需要使用另一套kafka集群来进行数据同步和备份.在kafka早先版本的时候,kafka针对这种场景就有推 ...