KafkaMirrorMaker 的不足以及一些改进
背景
某系统使用 Kafka 存储实时的行情数据,为了保证数据的实时性,需要在多地机房维护多个 Kafka 集群,并将行情数据同步到这些集群上。
一个常用的方案就是官方提供的 KafkaMirrorMaker 方案:
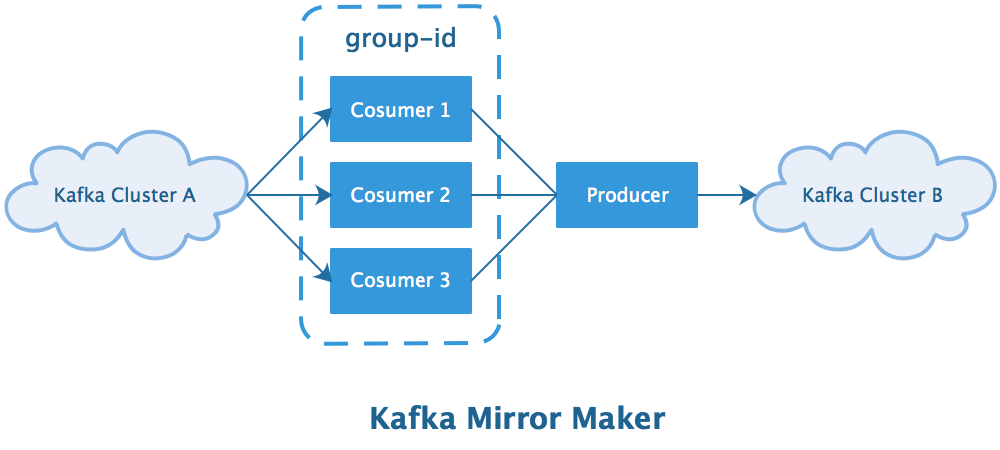
该方案的优点是能尽可能保证两个 Kafka 集群的数据一致(为了避免网络故障导致丢数据,要将其与 Kafka Cluster B 部署在同个机房),并且使用者无需进行开发工作,只需要进行响应的配置即可。
存在的问题
行情数据具有数据量大且时效性强的特点:
- 跨机房同步行情数据会消耗较多的专线带宽
- 网络故障恢复后继续同步旧数据意义不大并且可能引起副作用(行情数据延迟较大意味着已经失效)
因此 KafkaMirrorMaker 的同步方式存在以下两个不合理的地方:
- 无法实现多机房广播,会造成专线带宽浪费(多个机房同时拉取同一份数据)
- 单个 Producer 可能成为系统吞吐量的瓶颈(降低一致性以提高性能)
Producer 发送链路
主要的发送流程发送流程如下:
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
// 1. 阻塞获取集群信息,超时后抛出异常
ClusterAndWaitTime clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);
Cluster cluster = clusterAndWaitTime.cluster;
// 2. 序列化要发送的数据
byte[] serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
byte[] serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
// 3. 决定数据所属的分区
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
// 4. 将数据追加到发送缓冲,等待发送线程异步发送
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs);
// 5. 唤醒异步发送线程,将缓冲中的消息发送给 brokers
if (result.batchIsFull || result.newBatchCreated) {
this.sender.wakeup();
}
return result.future;
} catch (Exception e) {
// ...
}
}
决定分区
Producer 的功能是向某个 topic 的某个分区消息,所以它首先需要确认到底要向 topic 的哪个分区写入消息:
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
// 如果 key 为空,使用 round-robin 策略确认目标分区(保证数据均匀)
int nextValue = nextValue(topic);
return Utils.toPositive(nextValue) % numPartitions;
} else {
// 如果 key 不为空,使用 key 的 hash 值确认目标分区(保证数据有序)
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
追加缓冲
为了保证防止过量消息积压在内存中,每个 Producer 会设置一个内存缓冲,其大小由buffer.memory选项控制。
如果缓冲区的数据超过该值,会导致Producer.send方法阻塞,等待内存释放(记录被发送出去或超时后被清理):
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
Callback callback,
long maxTimeToBlock) throws InterruptedException {
ByteBuffer buffer = null;
if (headers == null) headers = Record.EMPTY_HEADERS;
try {
// 如果缓冲中存在未满的 ProducerBatch,则会尝试将记录追加到其中
// ...
// 估计记录所需要的空间
byte maxUsableMagic = apiVersions.maxUsableProduceMagic();
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
// 分配内存空间给当前记录
// 如果内存空间不足则会阻塞等待内存空间释放,如果超过等待时间会抛出异常
buffer = free.allocate(size, maxTimeToBlock);
synchronized (dq) {
// 再次尝试向现存的 ProducerBatch 中追加数据,如果成功则直接返回
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null) {
return appendResult;
}
// 新建 ProducerBatch 并将当前记录追加到其中
MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, time.milliseconds());
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds()))
;
dq.addLast(batch);
buffer = null;
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true);
}
} finally {
if (buffer != null)
free.deallocate(buffer);
}
}
异步发送
每个 Producer 都有一个发送线程,该线程会不停地调用Sender.sendProducerData方法将缓冲中的 RecordBatch 发送出去:
private long sendProducerData(long now) {
Cluster cluster = metadata.fetch();
// 获取就绪的 broker 节点信息,准备发送
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
if (!result.unknownLeaderTopics.isEmpty()) {
// 如果部分 topic 没有 leader 节点,则触发强制刷新
for (String topic : result.unknownLeaderTopics)
this.metadata.add(topic);
this.metadata.requestUpdate();
}
// 根据就绪 broker 节点信息,获取缓冲中对应的 ProducerBatch,准备发送
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes,
this.maxRequestSize, now);
if (guaranteeMessageOrder) {
// 排除已经检查过的分区,避免重复检查
for (List<ProducerBatch> batchList : batches.values()) {
for (ProducerBatch batch : batchList)
this.accumulator.mutePartition(batch.topicPartition);
}
}
// 清理已经过期的 ProducerBatch 数据,释放被占用的缓冲内存
List<ProducerBatch> expiredBatches = this.accumulator.expiredBatches(this.requestTimeout, now);
if (!expiredBatches.isEmpty())
log.trace("Expired {} batches in accumulator", expiredBatches.size());
for (ProducerBatch expiredBatch : expiredBatches) {
failBatch(expiredBatch, -1, NO_TIMESTAMP, expiredBatch.timeoutException(), false);
}
// 如果任意 broker 节点已经就绪,则将 pollTimeout 设置为 0
// 这是为了避免不必要的等待,让内存中的数据能够尽快被发送出去
long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);
if (!result.readyNodes.isEmpty()) {
pollTimeout = 0;
}
// 通过 NetworkClient -> NetworkChannel -> TransportLayer
// 最终将将消息写入 NIO 的 Channel
sendProduceRequests(batches, now);
return pollTimeout;
}
优化方案
从前面的分析我们可以得知以下两点信息:
- 每个 Producer 有一个内存缓冲区,当空间耗尽后会阻塞等待内存释放
- 每个 Producer 有一个异步发送线程,且只维护一个 socket 连接(每个 broker 节点)
为了提高转发效率、节省带宽,使用 Java 复刻了一版 KafkaMirrorMaker 并进行了一些优化:
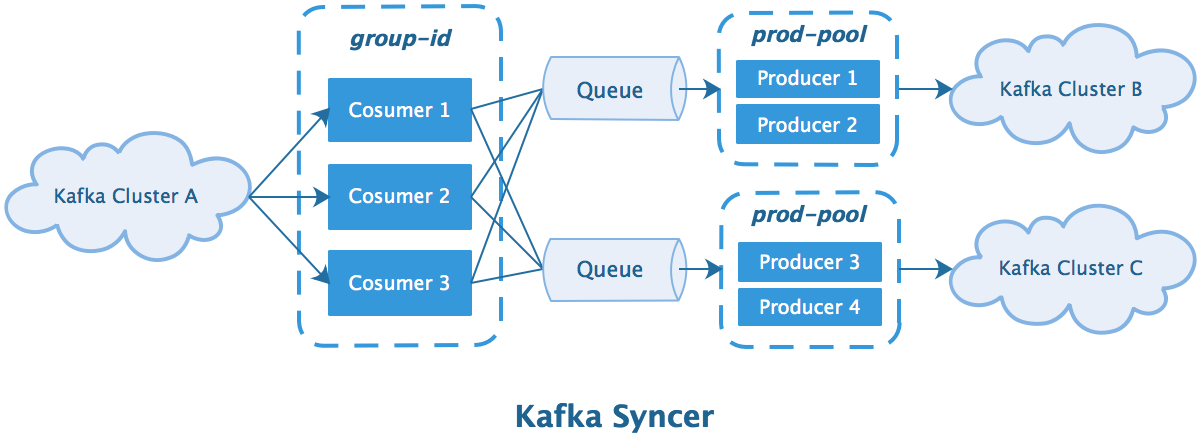
- 支持将一个集群的数据广播到多个集群
- 使用多个 Producer 同时进行转发提高效率
数据保序
如果同时使用多个 Producer,可能在转发过程中发生数据乱序,折中的策略是根据 key 的 hash 值来选择 Producer,保证 key 相同的数据会使用通过 Producer 进行发送:
void send(ConsumerRecord<byte[], byte[]> message) {
ProducerRecord record = new ProducerRecord<>(message.topic(), message.key(), message.value());
int hash = Math.abs(Arrays.hashCode(message.key()));
producers[hash % producers.length].send(record, onSend);
}
水位控制
多集群广播虽然能够一定程度上节省流量与机器资源,但是同时需要面对多个集群间发送速度不一致的问题。
极端情况下,如果其中某个机房的专线发生故障,Producer 会阻塞等待消息超时。当过量消息积压在 Queue 中,会导致 JMV 频繁的 FullGC,最终影响到对另一个机房的转发。
为了处理这一情况,需要在发送队列上加上水位线watermark限制:
interface Watermark {
default long high() { return Long.MAX_VALUE; }
default long low() { return 0; }
}
final BlockingQueue<byte[]> messageQueue = new LinkedBlockingQueue<>();
final AtomicLong messageBytes = new AtomicLong();
private void checkWatermark() {
long bytesInQueue = messageBytes.get();
if (bytesInQueue > bytesWatermark.high()) {
long discardBytes = bytesInQueue - bytesWatermark.low();
WatermarkKeeper keeper = new WatermarkKeeper(Integer.MAX_VALUE, discardBytes);
keeper.discardMessage(messageQueue);
long remainBytes = messageBytes.addAndGet(-discard.bytes());
}
}
为了实现高效的数据丢弃,使用BlockingQueue.drainTo减少锁开销:
public class WatermarkKeeper extends AbstractCollection<byte[]> {
private final int maxDiscardCount; // 丢弃消息数量上限
private final long maxDiscardBytes; // 丢弃消息字节上限
private int count; // 实际丢弃的消息数
private long bytes; // 实际丢弃消息字节数
public MessageBlackHole(int maxDiscardCount, long maxDiscardBytes) {
this.maxDiscardCount = maxDiscardCount;
this.maxDiscardBytes = maxDiscardBytes;
}
public void discardMessage(BlockingQueue<byte[]> queue) {
try {
queue.drainTo(this);
} catch (StopDiscardException ignore) {}
}
@Override
public boolean add(byte[] record) {
if (count >= maxDiscardCount || bytes >= maxDiscardBytes) {
throw new StopDiscardException();
}
count++;
bytes += record.length;
return true;
}
@Override
public int size() {
return count;
}
public long bytes() {
return bytes;
}
@Override
public Iterator<byte[]> iterator() {
throw new UnsupportedOperationException("iterator");
}
// 停止丢弃
private static class StopDiscardException extends RuntimeException {
@Override
public synchronized Throwable fillInStackTrace() {
return this;
}
}
}
监控优化
不使用 KafkairrorMaker 的另一个重要原因是其 JMX 监控不友好:
- RMI 机制本身存在安全隐患
- JMX 监控定制化比较繁琐(使用 jolokia 也无法解决这一问题)
一个比较好的方式是使用 SpringBoot2 的 micrometer 框架实现监控:
// 监控注册表(底层可以接入不同的监控平台)
@Autowired
private MeterRegistry meterRegistry;
// 接入 Kafka 的监控信息
new KafkaClientMetrics(consumer).bindTo(meterRegistry);
new KafkaClientMetrics(producer).bindTo(meterRegistry);
// 接入自定义监控信息
Gauge.builder("bytesInQueue", messageBytes, AtomicLong::get)
.description("Estimated message bytes backlog in BlockingQueue")
.register(meterRegistry);
通过这一方式能够最大程度地利用现有可视化监控工具,减少不必要地开发工作。
KafkaMirrorMaker 的不足以及一些改进的更多相关文章
- Kafka 博文索引
博文索引 KafkaBroker 简析 KafkaConsumer 简析 KafkaProducer 简析 KafkaMirrorMaker 的不足以及一些改进 Kafka 简介 数据是系统的燃料,系 ...
- 120项改进:开源超级爬虫Hawk 2.0 重磅发布!
沙漠君在历时半年,修改无数bug,更新一票新功能后,在今天隆重推出最新改进的超级爬虫Hawk 2.0! 啥?你不知道Hawk干吗用的? 这是采集数据的挖掘机,网络猎杀的重狙!半年多以前,沙漠君写了一篇 ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- 挑子学习笔记:两步聚类算法(TwoStep Cluster Algorithm)——改进的BIRCH算法
转载请标明出处:http://www.cnblogs.com/tiaozistudy/p/twostep_cluster_algorithm.html 两步聚类算法是在SPSS Modeler中使用的 ...
- ITTC数据挖掘平台介绍(四) 框架改进和新功能
本数据挖掘框架在这几个月的时间内,有了进一步的功能增强 一. 超大网络的画布显示虚拟化 如前几节所述,框架采用了三级层次实现,分别是数据,抽象Node和绘图的DataPoint,结构如下: ...
- C# 3.0新语言特性和改进(一)
引言 关于C#3.0的特性,园子里已经有了一大把,可能大家都很熟悉了,虽然本人开发中使用过,但自己还是需要记录一下,总结一下.同时也是后面写Linq知识的基础.希望有兴趣的朋友,可以看看. C# 3. ...
- jqGrid插件getCol方法的一个改进
jgGrid插件是非常常用的一个基于jQuery的表格插件,功能非常强大.我最近也频繁使用.但是这个插件也有一些不够完善的地方.比如这个getCol方法. getCol方法接受三个参数 colname ...
- kaggle入门2——改进特征
1:改进我们的特征 在上一个任务中,我们完成了我们在Kaggle上一个机器学习比赛的第一个比赛提交泰坦尼克号:灾难中的机器学习. 可是我们提交的分数并不是非常高.有三种主要的方法可以让我们能够提高他: ...
- SQL Server 2016中In-Memory OLTP继CTP3之后的新改进
SQL Server 2016中In-Memory OLTP继CTP3之后的新改进 转译自:https://blogs.msdn.microsoft.com/sqlserverstorageengin ...
随机推荐
- Cpython的全局解释器锁(GIL)
# Cpyrhon解释器下有个全局解释器锁-GIL:在同一 # 在同一时刻,多线程中只有一个线程访问CPU # 有了全局解释器锁(GIL)后,在同一时刻只能有一个线程访问CPU. # 全局解释器锁锁的 ...
- SMBv3远程代码执行漏洞复现(CVE-2020-0796)
漏洞基本信息 服务器消息块(SMB),是一个网络通信协议,用于提供共享访问到文件,打印机和串行端口的节点之间的网络上.它还提供了经过身份验证的进程间通信机制.SMB的大多数用法涉及运行Microsof ...
- tp5 上传视频方法
控制器调用 /** * 视频上传 */ public function video_add(){ if (request()->isPost()){ $video = $_FILES['vide ...
- 还不懂spring中的bean的话,你一定得好好看看这篇文章
bean的作用域 bean的生命周期 bean的装配 代码 实体类 package com; import java.util.List; public class User { private St ...
- 直面秋招!非科班生背水一战,最终拿下阿里等大厂offer!
前言 2020年已经接近到9月份了,很多粉丝朋友都对金九银十雀雀欲试了吧!也有很多朋友向我求教经验,因为我自己工作相对于稳定,在这里给大家分享一个粉丝朋友的经历,他作为一个曾经的菜鸡面试者,在不断的失 ...
- ABBYY FineReader 15 新增编辑表格单元格功能
ABBYY FineReader 15(Windows系统)新增编辑表格单元格功能,在PDF文档存在表格的前提下,可将表中的每个单元格作为单独的文字块进行单独编辑,单元格内的编辑不会影响同一行中其他单 ...
- css3系列之animation实现逐帧动画
上面这个两个简单的动画,是用 animation-timing-function: steps(); 这个属性实现的,具体如何实现,看下面: 这上面的图片,也就是我们的素材, 有些人,可能不是很理解 ...
- FL Studio新手入门:FL Studio五大常用按钮介绍
我们打开FL Studio编曲软件会发现界面中有好多的菜单和窗口,这些窗口每个都有其单独的功能.今天小编主要给大家详细讲解下FL Studio水果软件的五大常用按钮. 1.首先我,我们双击桌面的水果图 ...
- 推荐系统实践 0x09 基于图的模型
用户行为数据的二分图表示 用户的购买行为很容易可以用二分图(二部图)来表示.并且利用图的算法进行推荐.基于邻域的模型也可以成为基于图的模型,因为基于邻域的模型都是基于图的模型的简单情况.我们可以用二元 ...
- WireShark抓包分析以及对TCP/IP三次握手与四次挥手的分析
WireShark抓包分析TCP/IP三次握手与四次挥手 Wireshark介绍: Wireshark(前称Ethereal)是一个网络封包分析软件.功能十分强大,是一个可以在多个操作系统平台上的开源 ...