深入浅出java常量池
理论
jvm虚拟内存分布:

程序计数器是jvm执行程序的流水线,存放一些跳转指令。
本地方法栈是jvm调用操作系统方法所使用的栈。
虚拟机栈是jvm执行java代码所使用的栈。
方法区存放了一些常量、静态变量、类信息等,可以理解成class文件在内存中的存放位置。
虚拟机堆是jvm执行java代码所使用的堆。
Java中的常量池,实际上分为两种形态:静态常量池和运行时常量池。
所谓静态常量池,即*.class文件中的常量池,class文件中的常量池不仅仅包含字符串(数字)字面量,还包含类、方法的信息,占用class文件绝大部分空间。这种常量池主要用于存放两大类常量:字面量(Literal)和符号引用量(Symbolic References),字面量相当于Java语言层面常量的概念,如文本字符串,声明为final的常量值等,符号引用则属于编译原理方面的概念,包括了如下三种类型的常量:
- 类和接口的全限定名
- 字段名称和描述符
- 方法名称和描述符
而运行时常量池,则是jvm虚拟机在完成类装载操作后,将class文件中的常量池载入到内存中,并保存在方法区中,我们常说的常量池,就是指方法区中的运行时常量池。
常量池是为了避免频繁的创建和销毁对象而影响系统性能,其实现了对象的共享。
例如字符串常量池,在编译阶段就把所有的字符串文字放到一个常量池中。
(1)节省内存空间:常量池中所有相同的字符串常量被合并,只占用一个空间。
(2)节省运行时间:比较字符串时,==比equals()快。对于两个引用变量,只用==判断引用是否相等,也就可以判断实际值是否相等。
接下来我们引用一些网络上流行的常量池例子,然后借以讲解。

1 String s1 = "Hello";
2 String s2 = "Hello";
3 String s3 = "Hel" + "lo";
4 String s4 = "Hel" + new String("lo");
5 String s5 = new String("Hello");
6 String s6 = s5.intern();
7 String s7 = "H";
8 String s8 = "ello";
9 String s9 = s7 + s8;
10
11 System.out.println(s1 == s2); // true
12 System.out.println(s1 == s3); // true
13 System.out.println(s1 == s4); // false
14 System.out.println(s1 == s9); // false
15 System.out.println(s4 == s5); // false
16 System.out.println(s1 == s6); // true
首先说明一点,在java 中,直接使用==操作符,比较的是两个字符串的引用地址,并不是比较内容,比较内容请用String.equals()。
s1 == s2这个非常好理解,s1、s2在赋值时,均使用的字符串字面量,说白话点,就是直接把字符串写死,在编译期间,这种字面量会直接放入class文件的常量池中,从而实现复用,载入运行时常量池后,s1、s2指向的是同一个内存地址,所以相等。
s1 == s3这个地方有个坑,s3虽然是动态拼接出来的字符串,但是所有参与拼接的部分都是已知的字面量,在编译期间,这种拼接会被优化,编译器直接帮你拼好,因此String s3 = "Hel" + "lo";在class文件中被优化成String s3 = "Hello",所以s1 == s3成立。只有使用引号包含文本的方式创建的String对象之间使用“+”连接产生的新对象才会被加入字符串池中。
s1 == s4当然不相等,s4虽然也是拼接出来的,但new String("lo")这部分不是已知字面量,是一个不可预料的部分,编译器不会优化,必须等到运行时才可以确定结果,结合字符串不变定理,鬼知道s4被分配到哪去了,所以地址肯定不同。对于所有包含new方式新建对象(包括null)的“+”连接表达式,它所产生的新对象都不会被加入字符串池中。
配上一张简图理清思路:
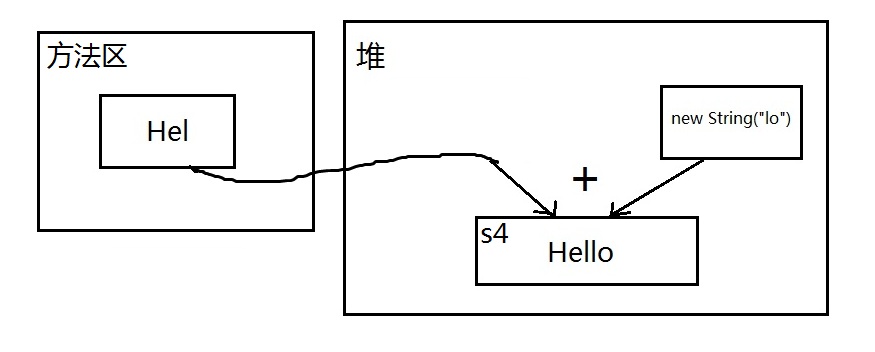
s1 == s9也不相等,道理差不多,虽然s7、s8在赋值的时候使用的字符串字面量,但是拼接成s9的时候,s7、s8作为两个变量,都是不可预料的,编译器毕竟是编译器,不可能当解释器用,不能在编译期被确定,所以不做优化,只能等到运行时,在堆中创建s7、s8拼接成的新字符串,在堆中地址不确定,不可能与方法区常量池中的s1地址相同。
s4 == s5已经不用解释了,绝对不相等,二者都在堆中,但地址不同。
s1 == s6这两个相等完全归功于intern方法,s5在堆中,内容为Hello ,intern方法会尝试将Hello字符串添加到常量池中,并返回其在常量池中的地址,因为常量池中已经有了Hello字符串,所以intern方法直接返回地址;而s1在编译期就已经指向常量池了,因此s1和s6指向同一地址,相等。
- 特例1
public static final String A = "ab"; // 常量A
public static final String B = "cd"; // 常量B
public static void main(String[] args) {
String s = A + B; // 将两个常量用+连接对s进行初始化
String t = "abcd";
if (s == t) {
System.out.println("s等于t,它们是同一个对象");
} else {
System.out.println("s不等于t,它们不是同一个对象");
}
}
s等于t,它们是同一个对象
A和B都是常量,值是固定的,因此s的值也是固定的,它在类被编译时就已经确定了。也就是说:String s=A+B; 等同于:String s="ab"+"cd";
- 特例2
public static final String A; // 常量A
public static final String B; // 常量B
static {
A = "ab";
B = "cd";
}
public static void main(String[] args) {
// 将两个常量用+连接对s进行初始化
String s = A + B;
String t = "abcd";
if (s == t) {
System.out.println("s等于t,它们是同一个对象");
} else {
System.out.println("s不等于t,它们不是同一个对象");
}
}
s不等于t,它们不是同一个对象
A和B虽然被定义为常量,但是它们都没有马上被赋值。在运算出s的值之前,他们何时被赋值,以及被赋予什么样的值,都是个变数。因此A和B在被赋值之前,性质类似于一个变量。那么s就不能在编译期被确定,而只能在运行时被创建了。
至此,我们可以得出三个非常重要的结论:
必须要关注编译期的行为,才能更好的理解常量池。
运行时常量池中的常量,基本来源于各个class文件中的常量池。
程序运行时,除非手动向常量池中添加常量(比如调用intern方法),否则jvm不会自动添加常量到常量池。
以上所讲仅涉及字符串常量池,实际上还有整型常量池、浮点型常量池(java中基本类型的包装类的大部分都实现了常量池技术,即Byte,Short,Integer,Long,Character,Boolean;两种浮点数类型的包装类Float,Double并没有实现常量池技术) 等等,但都大同小异,只不过数值类型的常量池不可以手动添加常量,程序启动时常量池中的常量就已经确定了,比如整型常量池中的常量范围:-128~127,(Byte,Short,Integer,Long,Character,Boolean)这5种包装类默认创建了数值[-128,127]的相应类型的缓存数据,但是超出此范围仍然会去创建新的对象。
例如在自动装箱时,把int变成Integer的时候,是有规则的,当你的int的值在-128-IntegerCache.high(127) 时,返回的不是一个新new出来的Integer对象,而是一个已经缓存在堆 中的Integer对象,(我们可以这样理解,系统已经把-128到127之 间的Integer缓存到一个Integer数组中去了,如果你要把一个int变成一个Integer对象,首先去缓存中找,找到的话直接返回引用给你就 行了,不必再新new一个),如果不在-128-IntegerCache.high(127) 时会返回一个新new出来的Integer对象。
实践
说了这么多理论,接下来让我们触摸一下真正的常量池。
前文提到过,class文件中存在一个静态常量池,这个常量池是由编译器生成的,用来存储java源文件中的字面量(本文仅仅关注字面量),假设我们有如下java代码:
1 String s = "hi";
为了方便起见,就这么简单,没错!将代码编译成class文件后,用winhex打开二进制格式的class文件。如图:
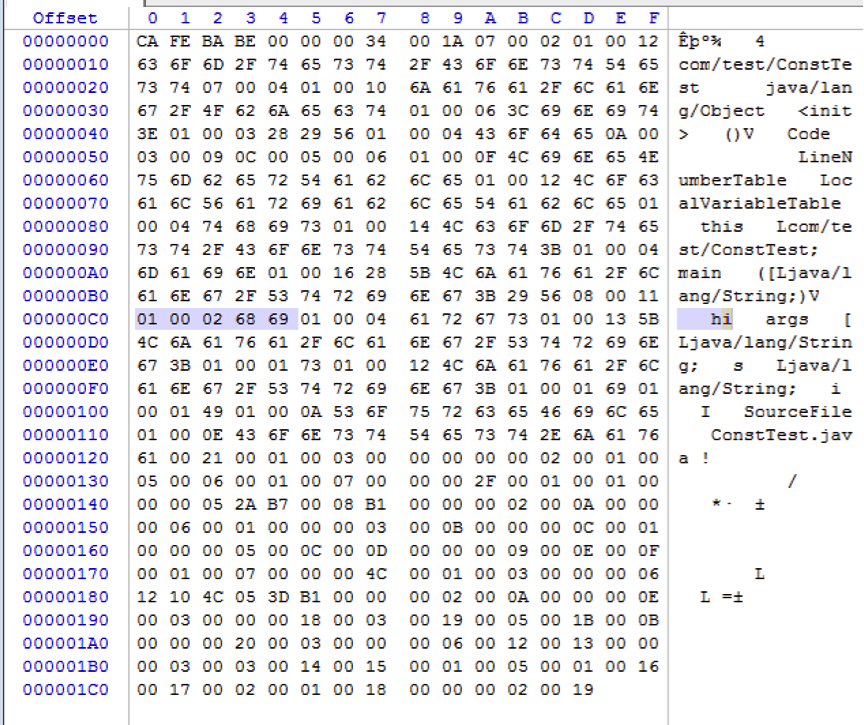
简单讲解一下class文件的结构,开头的4个字节是class文件魔数,用来标识这是一个class文件,说白话点就是文件头,既:CA FE BA BE。
紧接着4个字节是java的版本号,这里的版本号是34,因为笔者是用jdk8编译的,版本号的高低和jdk版本的高低相对应,高版本可以兼容低版本,但低版本无法执行高版本。所以,如果哪天读者想知道别人的class文件是用什么jdk版本编译的,就可以看这4个字节。
接下来就是常量池入口,入口处用2个字节标识常量池常量数量,本例中数值为00 1A,翻译成十进制是26,也就是有25个常量,其中第0个常量是特殊值,所以只有25个常量。
常量池中存放了各种类型的常量,他们都有自己的类型,并且都有自己的存储规范,本文只关注字符串常量,字符串常量以01开头(1个字节),接着用2个字节记录字符串长度,然后就是字符串实际内容。本例中为:01 00 02 68 69。
接下来再说说运行时常量池,由于运行时常量池在方法区中,我们可以通过jvm参数:-XX:PermSize、-XX:MaxPermSize来设置方法区大小,从而间接限制常量池大小。
假设jvm启动参数为:-XX:PermSize=2M -XX:MaxPermSize=2M,然后运行如下代码:
1 //保持引用,防止自动垃圾回收
2 List<String> list = new ArrayList<String>();
3
4 int i = 0;
5
6 while(true){
7 //通过intern方法向常量池中手动添加常量
8 list.add(String.valueOf(i++).intern());
9 }
程序立刻会抛出:Exception in thread "main" java.lang.outOfMemoryError: PermGen space异常。PermGen space正是方法区,足以说明常量池在方法区中。
在jdk8中,移除了方法区,转而用Metaspace区域替代,所以我们需要使用新的jvm参数:-XX:MaxMetaspaceSize=2M,依然运行如上代码,抛出:java.lang.OutOfMemoryError: Metaspace异常。同理说明运行时常量池是划分在Metaspace区域中。具体关于Metaspace区域的知识,请自行搜索。
参考文献:《深入理解java虚拟机———jvm高级特性与最佳实践》
深入浅出java常量池的更多相关文章
- 触摸java常量池
java常量池是一个经久不衰的话题,也是面试官的最爱,题目花样百出,小菜早就对常量池有所耳闻,这次好好总结一下. 理论 小菜先拙劣的表达一下jvm虚拟内存分布: 程序计数器是jvm执行程序的 ...
- 【转载】Java常量池
本篇随笔为转载,原贴地址:Java常量池理解与总结. (其实Java的常量池有点像C++中的存储字符串常量的常量存储区). 一.相关概念 什么是常量用final修饰的成员变量表示常量,值一旦给定就无法 ...
- java常量池概念
在class文件中,“常量池”是最复杂也最值得关注的内容. Java是一种动态连接的语言,常量池的作用非常重要,常量池中除了包含代码中所定义的各种基本类型(如int.long等等)和对象型(如Stri ...
- java常量池理解
String类两种不同的创建方式 String s1 = "zheng"; //第一种创建方式 String s2 = new String("junxiang" ...
- java常量池中基本数据类型包装类的小陷阱
想必大部分学过java的人都应该做过这种题目: public class Test { public static void main(String[] args) { //第一个字符串 String ...
- java虚拟机学习-触摸java常量池(13-1)
java虚拟机学习-深入理解JVM(1) java虚拟机学习-慢慢琢磨JVM(2) java虚拟机学习-慢慢琢磨JVM(2-1)ClassLoader的工作机制 java虚拟机学习-JVM内存管理:深 ...
- java常量池概念 (转)
在class文件中,“常量池”是最复杂也最值得关注的内容. Java是一种动态连接的语言,常量池的作用非常重要,常量池中除了包含代码中所定义的各种基本类型(如int.long等等)和对象型(如Stri ...
- Java常量池详细说明
java常量池技术 java中的常量池技术,是为了方便快捷地创建某些对象而出现的,当需要一个对象时,就可以从池中取一个出来(如果池中没有则创建一个),则在需要重复创建相等变量时节省了很多时间.常量池 ...
- 浅析Java常量池
Java常量池 Java常量池其实分为两种:静态常量池和运行时常量池 1.静态常量池 所谓静态常量池,即*.class文件中的常量池,class文件中的常量池不仅仅包含字符串(数字)字面量,还包含类. ...
随机推荐
- postgresql to_char 问题
select create_time from xxx; select to_char(create_time,'yyyy-MM-dd HH24:mm:ss') as create_time fr ...
- ExtJs radiogroup form.loadRecord方法无法赋值正确解决办法
一.radiogroup的name和radio的name一致,inputValue为整形 { xtype: 'radiogroup', fieldLabel: '是否有效', name: 'statu ...
- 四年级--python函数基础用法
一.函数的定义,调用和返回值 1.1 语法 def 函数(参数一,参数二...): ''' 文档注释 ''' 代码逻辑一 代码逻辑二 .... return 返回值 1.2 定义函数的三种形式 说明: ...
- 14.Ubuntu基本命令
vi编辑器 { :上一段diamante } :下一段代码 dw: 删除一个单词 权限 前面的分三组 第一: 文件拥有者的权限 第二:同组者拥有的权限 第三:其他人拥有的权限 前面“-”表示是文件 ...
- Tomcat PermGen space的解决方案
Tomcat报告 Caused by: java.lang.OutOfMemoryError: PermGen space异常 内存溢出PermGen space的全称是Permanent Gener ...
- JS的事件绑定、事件流模型
.t1 { background-color: #ff8080; width: 1100px; height: 40px } 一.JS事件 (一)JS事件分类 1.鼠标事件:click/dbclick ...
- jenkins中集成commander应用
jenkins中集成commander应用 jenkins 集成测试 promotion 最近参加公司的集成测试平台的开发,在开发中遇到了不少问题,两个星期的迭代也即将完成,在这也用这篇博客记录下开发 ...
- Caffe 编译后 make runtest 出现locale::facet::_S_create_c_locale 错误
You might need to append LC_ALL="en_US.UTF-8" to file: /etc/default/locale and reboot your ...
- vh、vw、vmin、vmax 知多少
介绍一些 CSS3 新增的单位,平时可能用的比较少,但是由于单位的特性,在一些特殊场合会有妙用. vw and vh 1vw 等于1/100的视口宽度 (Viewport Width) 1vh 等于1 ...
- maven 编译出错Fatal error compiling: 无效的目标发行版: 1.8 -> [Help 1] 解决办法
这几天在为公司项目搭建一个后台框架,使用的是eclipse-Mars自带的maven插件,在maven进行编译的时候,出现Fatal error compiling: 无效的目标发行版: 1.8 -& ...