Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取。
《工作细胞》最近比较火,bilibili 上目前的短评已经有17000多条。
先看分析下页面
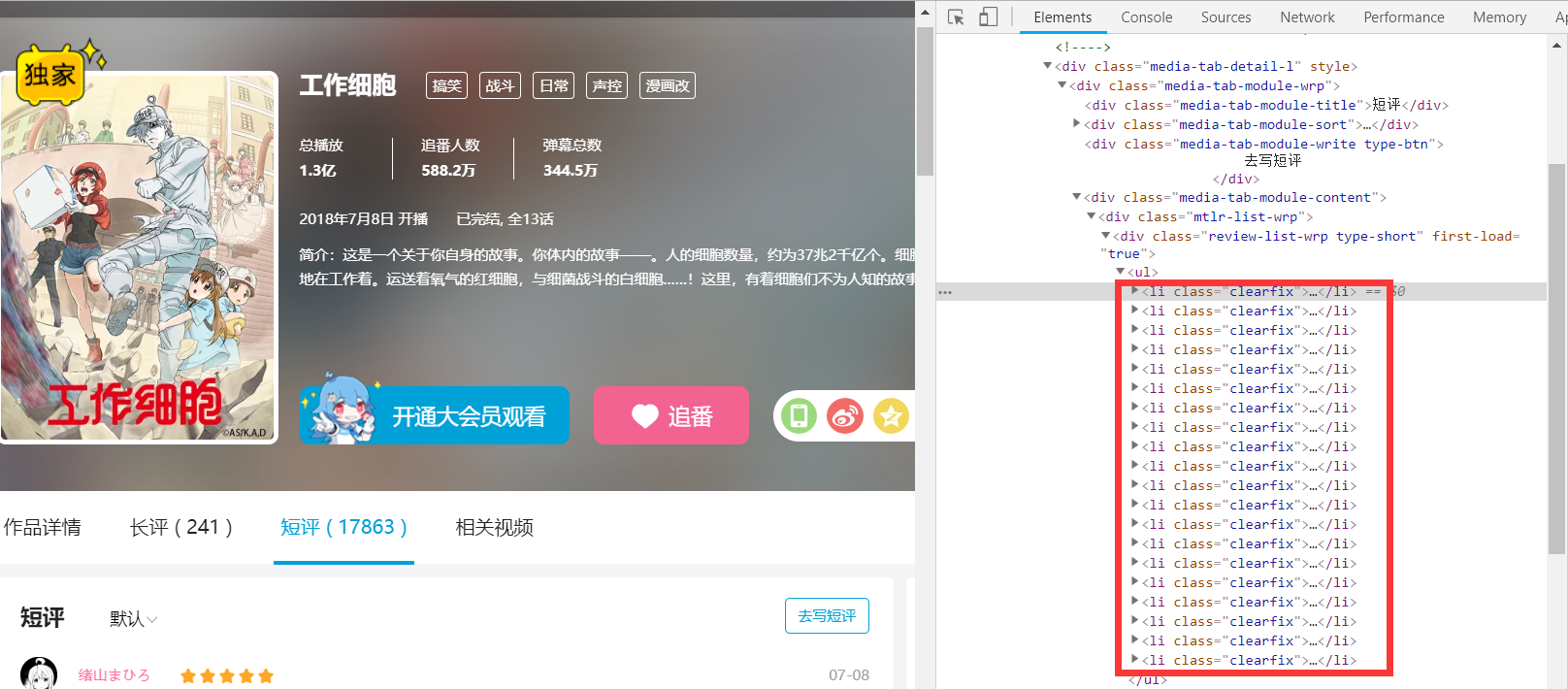
右边 li 标签中的就是短评信息,一共20条。一般我们加载大量数据的时候,都会做分页,但是这个页面没有,只有一个滚动条。
随着滚动条往下拉,信息自动加载了,如下图,变40条了。由此可见,短评是通过异步加载的。

我们不可能一次性将滚动条拉到最下面,然后来一次性获取全部的数据。既然知道是通过异步来加载的数据,那么我们可以想办法直接去获取这些异步的数据。
打开 Network 查看分析 http 请求,可以点击 XHR 过滤掉 img、css、js 等信息。这时我们发现了一些 fetch。fetch 我对它的了解就是一个比 ajax 更高级更好用的 API,当然这肯定是不准确的,但并并不影响我们的爬虫。
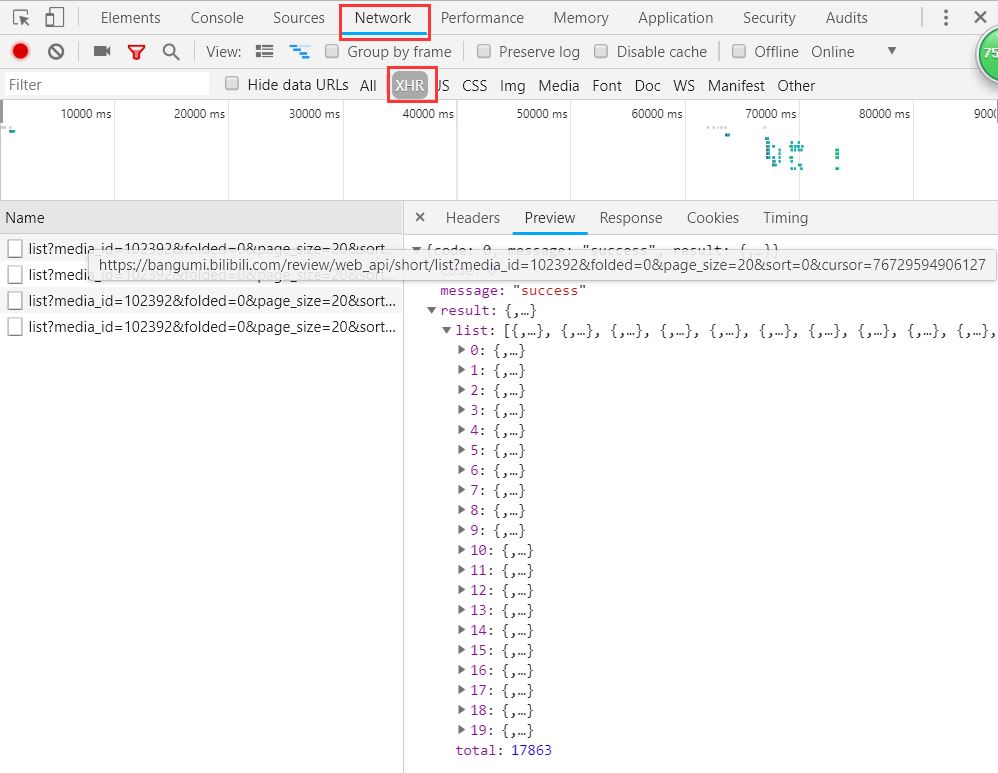
我们可以看到,其中返回的就是我们需要的内容,json 格式,一共20条,total 属性就是总的数目。分析一下 url 地址:https://bangumi.bilibili.com/review/web_api/short/list?media_id=102392&folded=0&page_size=20&sort=0&cursor=76729594906127
media_id 想必就是《工作细胞》的 id 了;
folded 不知道是啥,可以不管;
page_size 是每页的条数;
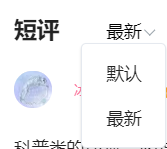
sort 排序,看名字就知道,找到排序的选项,试了下,果然是的,默认0,最新1;
cursor,字面意思的光标,猜测应该是指示本次获取开始的位置的,展开获取到的 json,发现其中包含有 cursor 属性,对比以后可以发现,url中的值跟上一次返回结果中的最后一条中的 cursor 的值是一致的。
好了,至此,页面已经分析清楚了,爬取的方式也明显了,根本不用管网页,直接根据 fetch 的地址获取 json 数据就可以了,连网页解析都省了,超级的方便。
下面的完整的代码:(如果 fake_useragent 报错,就手动写个 User-Agent 吧,那个库极度的不稳定)
import csv
import os
import time
import requests
from fake_useragent import UserAgent curcount = 0 def main():
url = 'https://bangumi.bilibili.com/review/web_api/short/list?media_id=102392&folded=0&page_size=20&sort=0'
crawling(url) def crawling(url):
print(f'正在爬取:{url}')
global curcount
headers = {"User-Agent": UserAgent(verify_ssl=False).random}
json_content = requests.get(url, headers).json()
total = json_content['result']['total']
infolist = []
for item in json_content['result']['list']:
info = {
'author': item['author']['uname'],
'content': item['content'],
'ctime': time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(item['ctime'])),
'likes': item['likes'],
'disliked': item['disliked'],
'score': item['user_rating']['score']
}
infolist.append(info)
savefile(infolist) curcount += len(infolist)
print(f'当前进度{curcount}/{total}')
if curcount >= total:
print('爬取完毕。')
return nexturl = f'https://bangumi.bilibili.com/review/web_api/short/list?' \
f'media_id=102392&folded=0&page_size=20&sort=0&cursor={json_content["result"]["list"][-1]["cursor"]}'
time.sleep(1)
crawling(nexturl) def savefile(infos):
with open('WorkingCell.csv', 'a', encoding='utf-8') as sw:
fieldnames = ['author', 'content', 'ctime', 'likes', 'disliked', 'score']
writer = csv.DictWriter(sw, fieldnames=fieldnames)
writer.writerows(infos) if __name__ == '__main__':
if os.path.exists('WorkingCell.csv'):
os.remove('WorkingCell.csv')
main()
相关博文推荐:
Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取的更多相关文章
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python 爬虫练习项目——异步加载爬取
项目代码 from bs4 import BeautifulSoup import requests url_prefix = 'https://knewone.com/discover?page=' ...
- Python 爬取异步加载的数据
在我们的工作中,可能会遇到这样的情况:我们需要爬取的数据是通过ajax异步加载的,这样的话通过requests得到的只是一个静态页面,而我们需要的是ajax动态加载的数据! 那我们应该怎么办呢??? ...
- Python爬虫爬取异步加载的数据
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:努力努力再努力 爬取qq音乐歌手数据接口数据 https://y.qq ...
- 爬虫--selenuim和phantonJs处理网页动态加载数据的爬取
1.谷歌浏览器的使用 下载谷歌浏览器 安装谷歌访问助手 终于用上谷歌浏览器了.....激动 问题:处理页面动态加载数据的爬取 -1.selenium -2.phantomJs 1.selenium 二 ...
- 爬虫开发6.selenuim和phantonJs处理网页动态加载数据的爬取
selenuim和phantonJs处理网页动态加载数据的爬取阅读量: 1203 动态数据加载处理 一.图片懒加载 什么是图片懒加载? 案例分析:抓取站长素材http://sc.chinaz.com/ ...
- Scrapy爬取Ajax(异步加载)网页实例——简书付费连载
这两天学习了Scrapy爬虫框架的基本使用,练习的例子爬取的都是传统的直接加载完网页的内容,就想试试爬取用Ajax技术加载的网页. 这里以简书里的优选连载网页为例分享一下我的爬取过程. 网址为: ht ...
- Scrapy爬虫框架教程(四)-- 抓取AJAX异步加载网页
欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章 sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction ...
随机推荐
- dqname.go
package nsqd func getBackendName(topicName, channelName string) string { // backend names, for u ...
- BZOJ_1098_[POI2007]办公楼biu_链表优化BFS
BZOJ_1098_[POI2007]办公楼biu_链表优化BFS Description FGD开办了一家电话公司.他雇用了N个职员,给了每个职员一部手机.每个职员的手机里都存储有一些同事的 电话号 ...
- BZOJ_5118_Fib数列2_矩阵乘法+欧拉定理
BZOJ_5118_Fib数列2_矩阵乘法+欧拉定理 Description Fib定义为Fib(0)=0,Fib(1)=1,对于n≥2,Fib(n)=Fib(n-1)+Fib(n-2) 现给出N,求 ...
- BZOJ_3585_mex && BZOJ_3339_Rmq Problem_主席树
BZOJ_3585_mex && BZOJ_3339_Rmq Problem_主席树 Description 有一个长度为n的数组{a1,a2,...,an}.m次询问,每次询问一个区 ...
- 计算机17-1,2作业D
D.环形矩阵 Description 给定一个整数m,按m形成一个环形矩阵.如m=5,则环形矩阵为: 1 1 1 1 1 1 1 1 1 1 2 2 ...
- 深度学习与自动驾驶领域的数据集(KITTI,Oxford,Cityscape,Comma.ai,BDDV,TORCS,Udacity,GTA,CARLA,Carcraft)
http://blog.csdn.net/solomon1558/article/details/70173223 Torontocity HCI middlebury caltech 行人检测数据集 ...
- 启动链码报rpc error: code = Unimplemented desc = unknown service protos.ChaincodeSupport start error
参考链接:https://stackoverflow.com/questions/48007519/unimplemented-desc-unknown-service-protos-chaincod ...
- Netty实现高性能的HTTP服务器
浅谈HTTP Method 要通过netty实现HTTP服务器(或者客户端),首先你要了解HTTP协议. HTTP在客户端 - 服务器计算模型中用作请求 - 响应协议. 例如,web浏览器可以是客户端 ...
- java基础( 九)-----深入分析Java的序列化与反序列化
序列化是一种对象持久化的手段.普遍应用在网络传输.RMI等场景中.本文通过分析ArrayList的序列化来介绍Java序列化的相关内容.主要涉及到以下几个问题: 怎么实现Java的序列化 为什么实现了 ...
- C#读写Excel的几种方法
1 使用Office自带的库 前提是本机须安装office才能运行,且不同的office版本之间可能会有兼容问题,从Nuget下载 Microsoft.Office.Interop.Excel 读写代 ...