设计模式---单例模式,pickle模块
设计模式---单例模式
简介
单例模式(Singleton Pattern) 是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在。当你希望在整个系统中,某个类只能出现一个实例时,单例对象就能派上用场。单例模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建'''1、单例类只能有一个实例。2、单例类必须自己创建自己的唯一实例。3、单例类必须给所有其他对象提供这一实例。'''关键实现思想:第一次创建类的对象的时候判断系统是否已经有这个单例,如果有则返回,如果没有则创建。那么后续再次创建该类的实例的时候,因为已经创建过一次了,就不能再创建新的实例了,否则就不是单例啦,直接返回前面返回的实例即可。
单例模式的python实现
使用“装饰器”来实现单例模式
def Singleton(cls): # 这是一个函数,目的是要实现一个“装饰器”,而且是对类型的装饰器'''cls:表示一个类名,即所要设计的单例类名称,因为python一切皆对象,故而类名同样可以作为参数传递'''instance = {}def singleton(*args, **kargs):if cls not in instance:instance[cls] = cls(*args, **kargs) # 如果没有cls这个类,则创建,并且将这个cls所创建的实例,保存在一个字典中return instance[cls]return singleton@Singletonclass Student(object):def __init__(self, name, age):self.name = nameself.age = ages1 = Student('张三', 23)s2 = Student('李四', 24)print((s1 == s2))print(s1 is s2)print(id(s1), id(s2), sep=' ')运行结果:TrueTrue24171496 24171496
通过__new__函数去实现
若要得到当前类的实例,应在当前类__new__()中调用其父类的__new__()来返回,python2和python3调用父类的__new__()方法不同:python2: object.__new__(cls)python3: super().__new__(cls) #super()中类可加可不加'''基于python3代码:'''class Student(object):instance = Nonedef __new__(cls, name, age):if not cls.instance:cls.instance = super(Student, cls).__new__(cls)return cls.instancedef __init__(self, name, age):self.name = nameself.age = ages1 = Student('张三', 23)s2 = Student('李四', 24)print((s1 == s2))print(s1 is s2)print(id(s1), id(s2), sep=' ')运行结果:TrueTrue27579152 27579152'''基于python2代码实现:'''if not cls.instance:cls.instance = object.__new__(cls)return cls.instance
使用一个单独的模块作为单例模式
因为,Python 的模块就是天然的单例模式,因为模块在第一次导入时,会生成 .pyc 文件,当第二次导入时,就会直接加载 .pyc 文件,而不会再次执行模块代码。因此,我们只需把相关的函数和数据定义在一个模块中,就可以获得一个单例对象了。如果我们真的想要一个单例类,可以考虑这样做:在一个模块中定义一个普通的类,如在demo.py模块中定义如下代码#demo.pyclass Student:def __init__(self,name,age):self.name=nameself.age=agestudent=Student('张三',23)这里的student就是一个单例。 当我们在另外一个模块中导入student这个对象时,因为它只被导入了一次,所以总是同一个实例。#test.pyfrom demo import student#此时,无论该test脚本怎么运行,import进来的student实例是唯一的
pickle模块
pickle模块的介绍
(1)pickle模块:pickle模块是python语言的一个系统内置模块,安装python后已包含pickle库,不需要单独再安装。(2)pickle模块的特点:1、只能在python中使用,只支持python的基本数据类型,是python独有的模块。2、序列化的时候,只是序列化了整个序列对象,而不是内存地址。3、pickle有两类主要的接口,即序列化和反序列化;通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储;通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。(3)为什么需要序列化和反序列化操作呢?1、便于存储序列化过程是将Python程序运行中得到了一些字符串、列表、字典等数据信息转变为二进制数据流。这样信息就容易存储在硬盘之中,当需要读取文件的时候,从硬盘中读取数据,然后再将其反序列化便可以得到原始的数据。2、便于传输当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把对象转换为字节序列,在网络上传输;接收方则需要把字节序列在恢复为对象,得到原始的数据。
pickle模块的使用
序列化操作
序列化方法1:pickle.dump()格式为:pickle.dump(obj,file)该方法是将序列化后的对象obj以二进制形式写入文件file中,进行保存,不能直接预览。 关于文件file,必须是以二进制的形式进行操作(写入)。示例如下:将五个学生的成绩写入到成绩表中,保存在cjb.txt文件中import randomimport pickle# 初始化成绩表为空cjb = []# 写入5个学生的数据到成绩表中for i in range(5):name = input("name:") # 姓名cj = random.randint(50, 100) # 随机生成50——100之间的整数作为成绩cjb.append([name, cj])print(cjb)# 将成绩表中的数据保存到cjb.txt文件中with open('cjb.txt', 'wb') as f:pickle.dump(cjb, f)print("结果已保存")
序列化方法2:pickle.dumps()格式为:pickle.dumps(obj)pickle.dumps()方法跟pickle.dump()方法不同:pickle.dumps()方法不需要写入文件中,而是直接返回一个序列化的bytes对象。示例如下:与上面的例子一样,只是方法不同,将五个学生的成绩写入到成绩表中,保存在cjb.txt文件中import randomimport pickle#初始化成绩表为空cjb=[]#写入5个学生的数据到成绩表中for i in range(5):name=input("name:") #姓名cj=random.randint(50,100) #成绩cjb.append([name,cj])print(cjb)print(pickle.dumps(cjb)) #序列化的bytes对象print(type(pickle.dumps(cjb))) #class 'bytes'#将成绩表中的数据保存到cjb.txt文件中with open('cjb.txt','wb')as f:f.write(pickle.dumps(cjb))print("结果已保存")运行结果为:[['1', 66], ['2', 70], ['3', 58], ['4', 96], ['5', 63]]b'\x80\x04\x957\x00\x00\x00\x00\x00\x00\x00]\x94(]\x94(\x8c\x011\x94KBe]\x94(\x8c\x012\x94KFe]\x94(\x8c\x013\x94K:e]\x94(\x8c\x014\x94K`e]\x94(\x8c\x015\x94K?ee.'<class 'bytes'>结果已保存
反序列化操作
反序列化方法1:pickle.load()该方法是将序列化的对象从文件file中读取出来。关于文件file,必须是以二进制的形式进行操作(读取)。示例如下:与上面的例子一样,将五个学生的成绩写入到成绩表中,保存在cjb.txt文件中;再次运行程序时,读取cjb.txt中的学生信息,进行加载,再次写入数据时,以追加的方式写入。import randomimport pickle#如果没有cjb,就让cjb=[],如果存在,就将内容读取出来try:with open('cjb.txt','rb')as f:cjb=pickle.load(f)print(cjb)print("结果已加载")except:cjb=[]#写入5个学生的数据到成绩表中for i in range(5):name=input("name:") #姓名cj=random.randint(50,100) #成绩cjb.append([name,cj])print(cjb)#将成绩表中的数据保存到cjb.txt文件中with open('cjb.txt','wb')as f:pickle.dump(cjb,f)print("结果已保存")运行结果:[['1', 66], ['2', 70], ['3', 58], ['4', 96], ['5', 63]]结果已加载name:11name:22name:33name:44name:55[['1', 66], ['2', 70], ['3', 58], ['4', 96], ['5', 63], ['11', 97], ['22', 87], ['33', 50], ['44', 98], ['55', 89]]结果已保存
反序列化方法2:pickle.loads()格式为:pickle.loads()pickle.loads()方法跟pickle.load()方法不同:pickle.loads()方法是直接从bytes对象中读取序列化的信息,而非从文件中读取。下面的例子是将信息保存到了文件中,所以要从文件中读取,以pickle.loads(f.read())的方式读取。示例如下:与上面的例子一样,将五个学生的成绩写入到成绩表中,保存在cjb.txt文件中;再次运行程序时,读取cjb.txt中的学生信息,进行加载,再次写入数据时,以追加的方式写入。import randomimport pickle#如果没有cjb,就让cjb=[],如果存在,就将内容读取出来try:with open('cjb.txt','rb')as f:cjb=pickle.loads(f.read())print(cjb)print("结果已加载")except:cjb=[]#写入5个学生的数据到成绩表中for i in range(5):name=input("name:") #姓名cj=random.randint(50,100) #成绩cjb.append([name,cj])print(cjb)#将成绩表中的数据保存到cjb.txt文件中with open('cjb.txt','wb')as f:f.write(pickle.dumps(cjb))print("结果已保存")运行结果:[['1', 87], ['2', 59], ['3', 78], ['4', 77], ['5', 75]]结果已加载name:aname:bname:cname:dname:e[['1', 87], ['2', 59], ['3', 78], ['4', 77], ['5', 75], ['a', 55], ['b', 86], ['c', 86], ['d', 61], ['e', 67]]结果已保存
选课系统项目分析
需求分析
选课系统角色:学校、学员、课程、讲师要求:1. 创建北京、上海 2 所学校2. 创建linux , python , go 3个课程 , linux\py 在北京开, go 在上海开3. 课程包含,周期,价格,通过学校创建课程4. 通过学校创建班级, 班级关联课程、讲师5. 创建学员时,选择学校,关联班级5. 创建讲师角色时要关联学校,6. 提供三个角色接口6.1 学员视图, 可以登录,注册, 选择学校,选择课程,查看成绩6.2 讲师视图, 讲师登录,选择学校,选择课程, 查看课程下学员列表 , 修改所管理的学员的成绩6.3 管理视图,登录,注册,创建讲师, 创建班级,创建课程,创建学校7. 上面的操作产生的数据都通过pickle序列化保存到文件里
设计分析
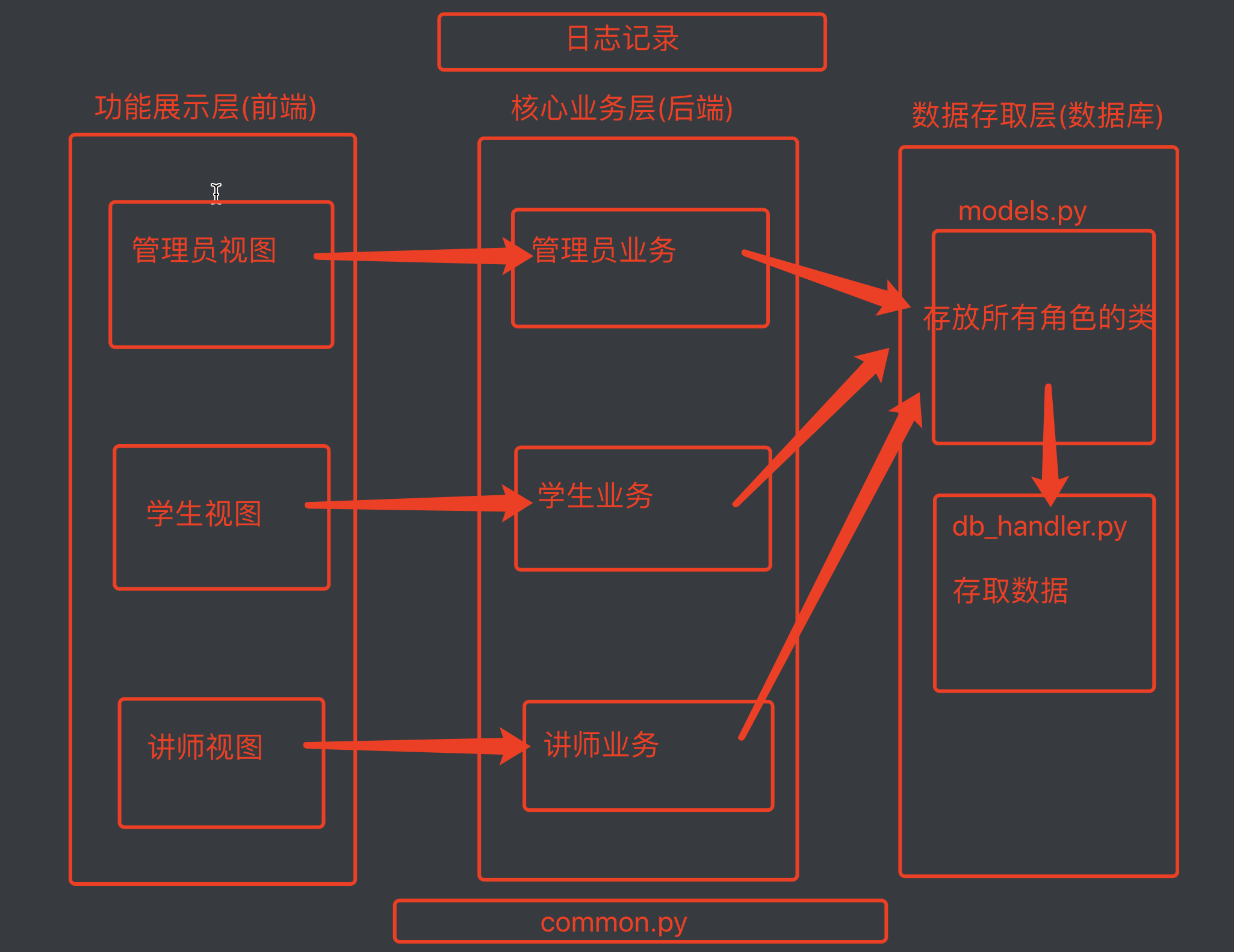
表示层:(向用户显示对应视图的功能)管理员视图学生视图讲师视图业务逻辑层:(主要实现功能的代码)管理员业务:登录,注册,创建讲师, 创建班级,创建课程,创建学校学生业务:登录,注册, 选择学校,选择课程,查看成绩讲师业务:讲师登录,选择学校,选择课程, 查看课程下学员列表 , 修改所管理的学员的成绩数据访问层:(对数据库的存储和取出)存储数据
设计模式---单例模式,pickle模块的更多相关文章
- JavaScript设计模式-单例模式、模块模式(转载 学习中。。。。)
(转载地址:http://technicolor.iteye.com/blog/1409656) 之前在<JavaScript小特性-面向对象>里面介绍过JavaScript面向对象的特性 ...
- 单例模式与pickle模块
目录 设计模式之单例模式 pickle模块 设计模式之单例模式 设计模式是前辈们发明的经过反复验证用于解决固定问题的固定套路,在IT行业中设计模式总共有23种,可以分为三大类:创建型.结构型.行为型. ...
- python_way,day8 面向对象【多态、成员--字段 方法 属性、成员修饰符、特殊成员、异常处理、设计模式之单例模式、模块:isinstance、issubclass】
python_way day8 一.面向对象三大特性: 多态 二.面向对象中的成员 字段.方法属性 三.成员修饰符 四.特殊成员 __init__.__doc__.__call__.__setitem ...
- Java设计模式の单例模式
-------------------------------------------------- 目录 1.定义 2.常见的集中单例实现 a.饿汉式,线程安全 但效率比较低 b.单例模式的实现:饱 ...
- python模块(json和pickle模块)
json和pickle模块,两个都是用于序列化的模块 • json模块,用于字符串与python数据类型之间的转换 • pickle模块,用于python特有类型与python数据类型之间的转换 两个 ...
- 【python】pickle模块
持久性的基本思想很简单.假定有一个 Python 程序,它可能是一个管理日常待办事项的程序,您希望在多次执行这个程序之间可以保存应用程序对象(待办事项).换句话说,您希望将对象存储在磁盘上,便于以后检 ...
- python数据持久存储:pickle模块的基本使用
经常遇到在Python程序运行中得到了一些字符串.列表.字典等数据,想要长久的保存下来,方便以后使用,而不是简单的放入内存中关机断电就丢失数据. 这个时候Pickle模块就派上用场了,它可以将对象转换 ...
- python数据持久存储:pickle模块的使用
python的pickle模块实现了基本的数据序列和反序列化.通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储:通过pickle模块的反序列化操作,我们能够从文件 ...
- Python(正则 Time datatime os sys random json pickle模块)
正则表达式: import re #导入模块名 p = re.compile(-]代表匹配0至9的任意一个数字, 所以这里的意思是对传进来的字符串进行匹配,如果这个字符串的开头第一个字符是数字,就代表 ...
随机推荐
- 杭电OJ 1248 不死族巫妖王 完全背包问题 字节跳动 研发岗编程原题
转载至:https://blog.csdn.net/ssdut_209/article/details/51557776 Problem Description不死族的巫妖王发工资拉,死亡骑士拿到一张 ...
- HTML 5中不同的新表单元素类型是什么?
HTML 5推出了10个重要的新的表单元素: Color. Date Datetime-local Email Time Url Range Telephone Number Search
- C++分布式系统——《开题》
在下自大二接触编程,大二.大三刻苦涉猎编程相关书籍,自那时起爱上了 C++,C++确实极有魅力,本想从此在C++领域深钻,但是扩展技术的广度在那个算是半只脚踏入编程且已经读完了 C++ 流行书籍的阶段 ...
- BMZCTF simple_pop
simple_pop 打开题目得到源码 这边是php伪协议的考点,需要去读取useless.php 解码获得源码 <?php class Modifier { protected $var; p ...
- java Web开发实现手机拍照上传到服务器
第一步: 搭环境,基本jdk 1.6+apache tomcat6.0+myeclipse2014 1.我们要清楚自己的jdk版本.因为我们Apache Tomcat配置的成功的前提是版本相对应. 安 ...
- Java/C++实现备忘录模式--撤销操作
改进课堂上的"用户信息操作撤销"实例,使得系统可以实现多次撤销(可以使用HashMap.ArrayList等集合数据结构实现). 类图: Java代码: import java.u ...
- Python读文件并写入数组
直接上代码: # 读文件 def get_venue(file): fname = file # 文件名 # 获取数据长度 len = 0 with open(fname, 'r+', encodin ...
- java中封装encapsulate的概念
封装encapsulate的概念:就是把一部分属性和方法非公有化,从而控制谁可以访问他们. https://blog.csdn.net/qq_44639795/article/details/1018 ...
- oracle查询出现科学计数法问题
- [ SOS ] 版本控制工具 笔记
https://www.cnblogs.com/yeungchie/ soscmd 创建工作区 soscmd newworkarea $serverName $projectName [$path] ...