Redis进阶知识一览
Redis的持久化机制
RDB: Redis DataBase
什么是RDB
RDB∶每隔一段时间,把内存中的数据写入磁盘的临时文件,作为快照,恢复的时候把快照文件读进内存。如果宕机重启,那么内存里的数据肯定会没有的,那么再次启动redis后,则会恢复。备份与恢复
内存备份-->磁盘临时文件
临时文件-->恢复到内存RDB优劣势
- 优势
- 每隔一段时间备份,全量备份
- 灾备简单,可以远程传输
- 子进程备份的时候,主进程不会有任何io操作(不会有写入修改或删除),保证备份数据的的完整性
- 相对AOF来说,当有更大文件的时候可以快速重启恢复
- 劣势
- 发生故障时,有可能会丢失最后一次的备份数据
- 子进程所占用的内存比会和父进程一模一样,这会造成CPU负担
- 由于定时全量备份是重量级操作,所以对于实时备份,就无法处理了。
- 优势
RDB的配置
- 保存位置,可以在redis.conf自定义∶
/user/local/redis/working/dump.rdb - 保存机制∶
- 保存位置,可以在redis.conf自定义∶
save 900 1 # 如果1个缓存更新,则15分钟后备份
save 300 10 # 如果10个缓存更新,则5分钟后备份
save 60 10000 # 如果10000个缓存更新,则1分钟后备份
- stop-writes-on-bgsave-error
- yes∶如果save过程出错,则停止写操作
- no∶ 可能造成数据不一致
- rdbcompression
- yes∶开启rdb压缩模式
- no∶关闭,会节约cpu损耗,但是文件会大,道理同nginx
- rdbchecksum
- yes∶使用CRC64算法校验对rdb进行数据校验,有10%性能损耗
- no∶不校验
总结
RDB适合大量数据的恢复,但是数据的完整性和一致性可能会不足
AOF: Append Only File
RDB会丢失最后一次备份的rdb文件,但是其实也无所谓,其实也可以忽略不计,毕竟是缓存,丢了就丢了,但是如果追求数据的完整性,那就的考虑使用AOF了。
AOF特点
- 以日志的形式来记录用户请求的写操作。读操作不会记录,因为写操作才会存存储。
- 文件以追加的形式而不是修改的形式。
- redis的aof恢复其实就是把追加的文件从开始到结尾读取执行写操作。
优势
- AOF更加耐用,可以以秒级别为单位备份,如果发生问题,也只会丢失最后一秒的数据,大大增加了可靠性和数据完整性。所以AOF可以每秒备份一次,使用fsync操作。
- 以log日志形式追加,如果磁盘满了,会执行redis-check-aof 工具
- 当数据太大的时候,redis可以在后台自动重写aof。当redis继续把日志追加到老的文件中去时,重写也是非常安全的,不会影响客户端的读写操作。
- AO日志包含了所有写操作,会更加便于redis的解析恢复。
劣势
- 相同的数据,同一份数据,AOF比RDB大
- 针对不同的同步机制,AOF会比RDB慢,因为AOF每秒都会备份做写操作,这样相对与RDB来说就略低。 每秒备份fsync没毛病,但是如果客户端的每次写入就做一次备份fsync 的话,那么redis的性能就会下降。
- AOF发生过bug,就是数据恢复的时候数据不完整,这样显得AOF会比较脆弱,容易出现bug,因为AOF没有RDB那么简单,但是呢为了防止bug的产生,AOF就不会根据日的指令去重构,而是根据当时缓存中存在的数据指令去做重构,这样就更加健壮和可靠了。
AOF的配置
# AOF 默认关闭,yes可以开启
appendonly no
# A0F 的文件名
appendfilename "appendonly.aof"
# no∶不同步
# everySec∶每秒备份,推荐使用
# always∶每次操作都会备份,安全并且数据完整,但是慢性能差
appendfsync everysec
# 重写的时候是否要同步,no可以保证数据安全
no-appendfsync-on-rewrite no
# 重写机制∶避免文件越来越大,自动优化压缩指令,会fork一个新的进程去完成重写动作,新进程里的内存数据会被重写,此时旧的aof文件不会被读取使用,类似rdb
# 当前A0F文件的大小是上次AOF大小的100% 并且文件体积达到64m,满足两者则触发重写
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
到底采用RDB还是AOF呢?
- 如果你能接受一段时间的缓存丢失,那么可以使用RDB
- 如果你对实时性的数据比较care,那么就用AOF
- 使用RDB和AOF结合一起做持久化,RDB做冷备,可以在不同时期对不同版本做恢复,AOF做热备,保证数据仅仅只有1秒的损失。当AOF破损不可用了,那么再用RDB恢复,这样就做到了两者的相互结合,也就是说Redis恢复会先加载AOF,如果AOF有问题会再加载RDB,这样就达到冷热备份的目的了。
Redis 缓存过期处理与内存淘汰机制
计算机内存有限,越大越贵,Redis的高并发高性能都是基于内存的,用硬盘的话GG。
已过期的key如何处理?
设置了expire的key缓存过期了,但是服务器的内存还是会被占用,这是因为redis所基于的两种删除策略。
redis有两种策略∶
- (主动)定时删除
- 定时随机的检查过期的key,如果过期则清理删除。(每秒检查次数在redis.conf中的hz配置)
- (被动)惰性删除
- 当客户端请求一个已经过期的key的时候,那么redis会检查这个key是否过期,如果过期了,则删除,然后返回一个nil。这种策略对cpu比较友好,不会有太多的损耗,但是内存占用会比较高。
所以,虽然key过期了,但是只要没有被redis清理,那么其实内存还是会被占用着的。
那么如果内存被Redis缓存占用满了咋办?
内存占满了,可以使用硬盘,来保存,但是没意义,因为硬盘没有内存快,会影响redis性能。所以,当内存占用满了以后,redis提供了一套缓存淘汰机制∶ ME MORY MANAGEMENT。
maxmemory ∶当内存已使用率到达,则开始清理缓存
* noeviction∶旧缓存永不过期,新缓存设置不了,返回错误
* allkeys-lru∶清除最少用的旧缓存,然后保存新的缓存(推荐使用)
* allkeys-random∶在所有的缓存中随机删除(不推荐)
* volatie-lru∶在那些设置了expire过期时间的缓存中,清除最少用的旧缓存,然后保存新的缓存
* volatile-random∶在那些设置了expire过期时间的缓存中,随机删除缓存
* volatile-ttl∶在那些设置了expire过期时间的缓存中,删除即将过期的
哨兵模式
Master挂了,如何保证可用性,实现继续读写
什么是哨兵?
Sentinel(哨兵)是用于监控Redis集群中Master状态的工具,是 Redis 高可用解决方案,哨兵可以监视一个或者多个redis master服务,以及这些master服务的所有从服务; 当某个master服务宕机后,会把这个master下的某个从服务升级为master来替代已宕机的master继续工作。示例图:
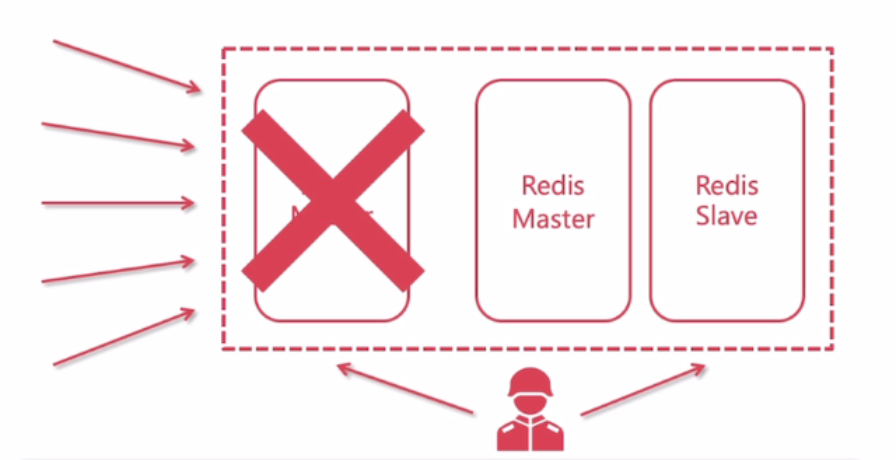
配置哨兵监控master
创建并且配置sentinel.conf∶
- 普通配置
port 26379
pidfile "/usr/local/redis/sentinel/redis-sentinel.pid"
dir "/usr/local/redis/sentinel"
daemonize yes
protected-mode no
logfile "/usr/local/redis/sentinel/redis-sentinel.1og"
- 核心配置
# 配置哨兵
sentinel monitor mymaster 127.0.0.1 6379 2
#密码
sentinel auth-pass <master-name> <password>
# master被sentinel认定为失效的间隔时间
sentinel down-after-milliseconds mymaster 30000
# 剩余的slaves重新和新的master做同步的并行个数
sentinel parallel-syncs mymaster 1
# 主备切换的超时时间,哨兵要去做故障转移,这个时候哨兵也是一个进程,如果他没有去执行,超过这个时间后,会由其他的哨兵来处理
sentinel failover-timeout mymaster 180000
启动哨兵x3
redis-sentinel sentinel.conf
测试
- master挂了,看slave是否成为master
- master恢复,观察slave状态
结论:master挂了以后,由于哨兵监控,剩余slave会进行选举,选举后其中一个成为master,当原来的master恢复后,他会成为slave。
一般master数据无法同步给slave的方案检查为如下∶
- 网络通信问题,要保证互相ping通,内网互通。
- 关闭防火墙,对应的端口开放(虚拟机中建议永久关闭防火墙,云服务器的话需要保证内网互通)。
- 统一所有的密码,通过逐台检查机器以防某个节点被遗漏。
哨兵信息检查
查看相关信息
# 查看reminis-master下的master节点信息
sentinel master reminis-master
# 查看reminis-master下的slaves节点信息
sentinel slaves reminis-master
# 查看reminis-master下的哨兵节点信息
sentinel sentinels reminis-master
SpringBoot集成Redis哨兵-配置
配置如下:
spring:
redis:
database: 1
password: reminis
sentinel:
master: reminis-master
nodes: 192.168.32.10:26379,192.168.32.12:26379,192.168.32.13:26379
Redis集群
前面我们一起学习了主从复制以及哨兵,他们可以提高读的并发,但是单个master容量有限,数据达到一定程度会有瓶颈,这个时候可以通过水平扩展为多master-slave成为集群。那么这一节开始我们就一起来学习redis-cluster∶他可以支撑多个master-slave,支持海量数据,实现高可用与高并发。
哨兵模式其实也是一种集群,他能够提高读请求的并发,但是容错方面可能会有一些问题,比如master同步数据给slave的时候,这其实是异步复制吧,这个时候master挂了,那么slave上的数据就没有master新,数据同步需要时间的,1-2秒的数据会丢失。master恢复并转换成slave后,新数据则丢失。
特点:
- 每个节点知道彼此之间的关系,也会知道自己的角色,当然他们也会知道自己存在于一个集群环境中,他们彼此之间可以交互和通信,比如ping pong。那么这些关系都会保存到某个配置文件中,每个节点都有,这个我们在搭建的时候需要做配置的。
- 客户端要和集群建立连接的话,只需要和其中一个建立关系就行。
- 某个节点挂了,也是通过超过半数的节点来进行的检测,客观下线后主从切换,和我们之前在哨兵模式中提到的是一个道理。
- Redis中存在很多的插槽,又可以称之为槽节点,用于存储数据,这个先不管,后面再说。
集群容错
构建Redis集群,需要至少3个节点作为master,以此组成一个高可用的集群,此外每个master都需要配备一个slave,所以整个集群需要6个节点,这也是最经典的Redis集群,也可以称之为三主三从,容错性更佳。所以在搭建的时候需要有6台虚拟机。请各自准备6台虚拟机,可以通过克隆去构建,使用单实例的Redis 去克隆即可。
- 集群也可以在单服务器构建,称之为伪集群,但是生产环境肯定是真的,所以建议用6台。
- 克隆后务必关闭Redis。
构建Redis集群
redis.conf 配置
# 开启集群模式
cluster-enabled yes
# 每一个节点需要有一个配置文件,需要6份。每个节点处于集群的角色都需要告知其他所有节点,彼此知道,这个文件用于存储集群模式下的集群状态等信息,这个文件是由redis自己维护,我们不用管。如果你要重新创建集群,那么把这个文件删了就行
cluster-config-file nodes-201.conf
# 超时时间,超时则认为master宕机,随后主备切换
cluster-node-timeout 5000
# 开启AOF
appendonly yes
启动6个redis实例
- 启动6台
- 如果启动过程出错,把rdb等文件删除清空
创建集群
####
# 注意1∶如果你使用的是redis3.x版本,需要使用redis-trib.rb来构建集群,最新版使用C语言来构建了,这个要注意
# 注意2∶以下为新版的redis构建方式
####
# 创建集群,主节点和从节点比例为1,1-3为主,4-6为从,1和4.2和5 3和6分别对应为主从关系,这也是最经典用的最多的集群模式
redis-cli --cluster create ip1:port1 ip2:port2 ip3:port 3 ip4:port4 ip5:port5 ip6:port6 --cluster-replicas 1
slots槽,用于装数据,主节点有,从节点没有
检查集群信息:redis-cli--cluster check 192.168.25.64:6380
总结
最后,让我们来看一下下方的思维导图进行梳理内容:
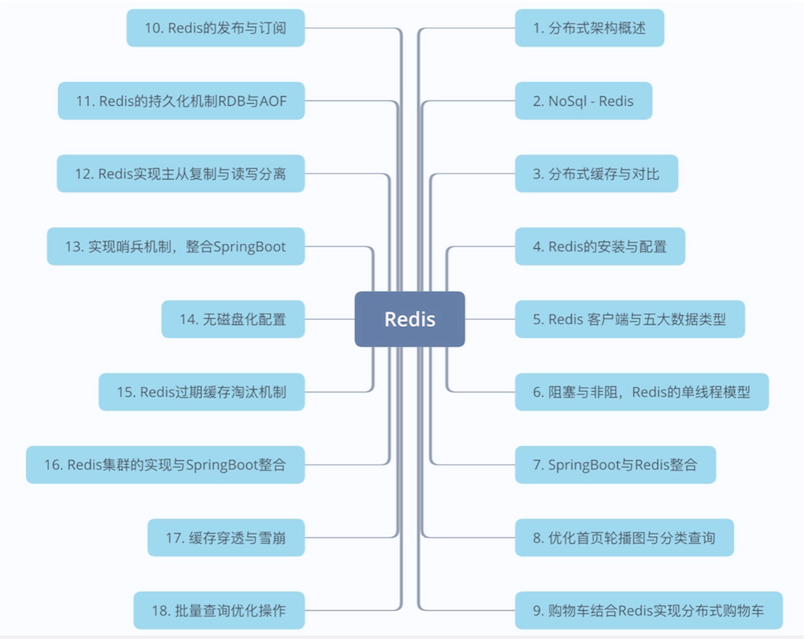
复习
- 本阶段开篇讲述了分布式相关,其实分布式和集群的概念在前期就介绍过了,不同的节点做着不同的事,就是分布式,不同的节点做着相同的事就是集群。那么Redis是NoSql,不仅仅是sql,功能更强劲,可以作为缓存写入内存,提供高速访问,为数据库做了一道屏障,保护数据库,把热点数据放入缓存,从而提升项目的并发量与吞吐量。
- 介绍完Redis后我们又一起搭建了单机单实例版的Redis,需要注意,Redis虽然可以在win或mac上搭建,但是企业里都是linux,所以我们一定要使用linux来搭建和配置。
- Redis提供命令行客户端工具,也就是redis-cli进入命令行后可以进行相应的操作,我们讲述了五大数据类型,分别为∶string,list,hash,set与zset。每个数据类型包含了一些操作指令,这些没有必要去死记硬背,遇到了,就去查一下api,百度一下即可。
- Redis是单线程的,但是他的性能却很高,在这里我们讲述了Redis的单线程模型,这一点往往在面试过程中会被问到。
- 当单机的Redis安装配置完毕以后,我们整合到了项目中,结合了SpringBoot,优化了首页的轮播图与分类,因为这些完全可以放入缓存,没有必要去查询数据库。当然,对干前期单体阶段的购物车,我们结合了redis实现了分布式购物车,如此,不论用户在任何电脑访问,都能看到曾经的购物车数据,并且我们也实现了登录后的同步购物车功能。
- Redis可以实现类似于MQ的发布与订阅,是属于生产者与消费者模式,但是正所谓专人做专事,发布订阅机制没有必要用Redis来实现,企业里都是使用的MQ。
- Redis的持久化机制,RDB与AOF,这两种模式大家一定要知道他们之间的区别,一个是全量备份,一个是增量定时,各有各的好,也有缺点,面试过程中会被问到。
- 单机Redis存在单点故障与读并发量的限制,所以可以通过主从与哨兵来实现,主从解决读写分离,并且一主多从能够提升读的并发。哨兵提供监控机制,一旦主挂了,备则上位成为主,如此实现高可用。
- 在Redis中可以设置无磁盘化,如果磁盘比较慢,可以打开,但是一般来说,服务器都会采用ssd,尤其针对数据存储类的。
- 当key过期了,你会发现内存占用率还是很高,这是因为redis的机制,有被动主动之分。这一点在面试中可能会被问到哟。此外,对于内存写满后的kev淘汰机制,我们也在这里提到过,不同的策略都可以配置。
- Redis除了单机与哨兵模式外,还能搭建集群,最经典的还属三主三从,搭建完毕后我们还整合了SpringBoot,其实由于springboot的yml配置特性,大大的减少了配置项,如果你使用springmvc,xml中的配置会有很多,而yml中的配置也就2-3行的事。
- 对于缓存来说,我们还需要预防缓存穿透与雪崩,穿透的话一般来说只需要针对空值缓存就行,过期时间设置5-10分钟,这样就流量就不会打在数据库上导致死机宕机。雪崩其实也可以做到提前预防,那就是用到过期时间的key,时间全部错开,此外,有些数据可以做永久保存的话那就直接保存好了,这样就不会造成大面积的key失效了。
- 最后有一点还需要说的,就是当一次请求过来,如果查询的key比较多,能做到批量就批量,如果是循环查询缓存的话,一来吞吐量低,而来比较low。
Redis进阶知识一览的更多相关文章
- redis进阶知识
原文地址:https://my.oschina.net/u/4052893/blog/3001173 一.缓存雪崩 1.1什么是缓存雪崩? 回顾一下我们为什么要用缓存(Redis): 现在有个问题,如 ...
- 【进阶之路】Redis基础知识两篇就满足(一)
导言 大家好,我是南橘,一名练习时常两年半的java练习生,这是我在博客园的第一篇文章,当然,都是要从别处搬运过来的,不过以后新的文章也会在博客园同步发布,希望大家能多多支持^_^ 这篇文章的出现,首 ...
- 【进阶之路】Redis基础知识两篇就满足(二)
导言 大家好,我是南橘,一名练习时常两年半的java练习生,这是我在博客园的第二篇文章,当然,都是要从别处搬运过来的,不过以后新的文章也会在博客园同步发布,希望大家能多多支持^_^ 这篇文章的出现,首 ...
- Spring实战3:装配bean的进阶知识
主要内容: Environments and profiles Conditional bean declaration 处理自动装配的歧义 bean的作用域 The Spring Expressio ...
- Redis进阶实践之十三 Redis的Redis-trib.rb文件详解
一.简介 事先说明一下,本篇文章不涉及对redis-trib.rb源代码的分析,只是从使用的角度来阐述一下,对第一次使用的人来说很重要.redis-trib.rb是redis官方推出的管理re ...
- Redis进阶实践之十六 Redis大批量增加数据
一.介绍 有时,Redis实例需要在很短的时间内加载大量先前存在或用户生成的数据,以便尽可能快地创建数百万个键.这就是所谓的批量插入,本文档的目标是提供有关如何以尽可能快的速度向Redis提 ...
- Redis进阶实践之十八 使用管道模式加速Redis查询
一.引言 学习redis 也有一段时间了,该接触的也差不多了.后来有一天,以为同事问我,如何向redis中批量的增加数据,肯定是大批量的,为了这主题,我从新找起了解决方案.目前 ...
- Redis基础知识小结
Redis是一个高性能的key-value型数据库.Redis能读的速度是110000次/s,写的速度是81000次/s ,性能极高.Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全 ...
- Redis进阶实践之十三 Redis的Redis-trib.rb脚本文件使用详解
转载来源:http://www.cnblogs.com/PatrickLiu/p/8484784.html 一.简介 事先说明一下,本篇文章不涉及对redis-trib.rb源代码的分析,只是从使用的 ...
随机推荐
- Robinhood基于Apache Hudi的下一代数据湖实践
1. 摘要 Robinhood 的使命是使所有人的金融民主化. Robinhood 内部不同级别的持续数据分析和数据驱动决策是实现这一使命的基础. 我们有各种数据源--OLTP 数据库.事件流和各种第 ...
- Leetcode刷题之螺旋矩阵
矩阵之螺旋矩阵 总体思路: 注意遍历顺序 每次遍历一圈时候不要多加元素 Leetcode54螺旋矩阵 给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素. ...
- 安装Backstage.io应用
Backstage介绍 What's Backstage? Backstage is an open platform for building developer portals. Powered ...
- MySQL索引机制(详细+原理+解析)
MySQL索引机制 永远年轻,永远热泪盈眶 一.索引的类型与常见的操作 前缀索引 MySQL 前缀索引能有效减小索引文件的大小,提高索引的速度.但是前缀索引也有它的坏处:MySQL 不能在 ORDER ...
- 直接使用sublime编译stylus
stylus介绍 Stylus 是一个CSS的预处理框架,2010年产生,来自Node.js社区,主要用来给Node项目进行CSS预处理支持,所以 Stylus 是一种新型语言,可以创建健壮的.动态的 ...
- 结合Vue.js的前端压缩图片方案
这是一个很简单的方案.嗯,是真的. 为什么要这么做? 在移动Web蓬勃发展的今天,有太多太多的应用需要让用户在移动Web上传图片文件了,正因如此,我们有些困难必须去攻克: 低网速下上传进度缓慢,用户体 ...
- 【每日日报】第五十一天---jsp
1 开始学习JSP的使用 一个简单的jsp代码 <html> <head><title>Hello World</title></head> ...
- java中Array(数组)的用法
8.Array(数组) 数组是作为对象来实现的.(really occupy the memopry,真实的占用内存 ) An array is a data structure that st ...
- 实现一个promise.all方法
思路: 1:首先明白all的用法 2:promise.all可以接受一个由promise数组作为参数,并且返回一个promise实例, 3:promise.all([a,b,c...]).then方法 ...
- 设计模式之:享元模式FlyweightPattern的实现
享元模式的理解: 享元模式的定义:运用共享技术支持大量细粒度对象的复用: Flyweight Pattern Definition:Use sharing to support large numbe ...