实验 3 Spark 和 Hadoop 的安装
1. 安装 Hadoop 和 Spark
进入 Linux 系统,参照本教程官网“实验指南”栏目的“Hadoop 的安装和使用”,完成 Hadoop 伪分布式模式的安装。完成 Hadoop 的安装以后,再安装Spark(Local 模式)。
2. HDFS 常用操作
使用 hadoop 用户名登录进入 Linux 系统,启动 Hadoop,参照相关 Hadoop 书籍或网络资料,或者也可以参考本教程官网的“实验指南”栏目的“HDFS 操作常用 Shell 命令”,
使用Hadoop 提供的 Shell 命令完成如下操作:
(1) 启动Hadoop,在HDFS 中创建用户目录“/user/hadoop”;
- hadoop fs -mkdir /user/hadoop
(2) 在 Linux 系统的本地文件系统的“/home/hadoop”目录下新建一个文本文件 test.txt,并在该文件中随便输入一些内容,然后上传到 HDFS 的“/user/hadoop”目录下;
- hdfs dfs -put /home/hadoop/test.txt /usr/hadoop
(3) 把 HDFS 中“/user/hadoop”目录下的 test.txt 文件,下载到 Linux 系统的本地文件系统中的“/home/hadoop/下载”目录下;
- hdfs dfs -get /user/hadoop/test.txt /home/hadoop
(4) 将HDFS 中“/user/hadoop”目录下的test.txt文件的内容输出到终端中进行显示;
- hdfs dfs -cat /user/hadoop/test.txt
(5) 在 HDFS 中的“/user/hadoop” 目录下, 创建子目录 input ,把 HDFS 中 “/user/hadoop”目录下的 test.txt 文件,复制到“/user/hadoop/input”目录下;
- hadoop fs -mkdir /user/hadoop/input
- hdfs dfs -cp /user/hadoop/test.txt /user/hadoop/input
(6) 删除HDFS 中“/user/hadoop”目录下的test.txt文件,删除HDFS 中“/user/hadoop”目录下的 input 子目录及其子目录下的所有内容。
- hdfs dfs -rm /user/hadoop/test.txt
- hdfs dfs -rm -r /user/hadoop/input
3. Spark 读取文件系统的数据
(1) 在 spark-shell 中读取Linux 系统本地文件“/home/hadoop/test.txt”,然后统计出文件的行数;
- bin/spark-shell
- val textFile = sc.textFile("file:///home/hadoop/test1.txt")
- textFile.count()

(2) 在 spark-shell 中读取HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;
- val textFile = sc.textFile("hdfs://node01:8020/user/hadoop/test.txt")
- textFile.count()

(3) 编写独立应用程序,读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;通过 sbt 工具将整个应用程序编译打包成 JAR 包,并将生成的JAR 包通过 spark-submit 提交到 Spark 中运行命令。
- cd ~ # 进入用户主文件夹
- mkdir ./sparkapp3 # 创建应用程序根目录
- mkdir -p ./sparkapp3/src/main/scala # 创建所需的文件夹结构
- vim ./sparkapp3/src/main/scala/SimpleApp.scala
- ----------------------------------------------------------
- /* SimpleApp.scala */
- import org.apache.spark.SparkContext
- import org.apache.spark.SparkContext._
- import org.apache.spark.SparkConf
- object SimpleApp {
- def main(args: Array[String]) {
- val logFile = "hdfs://localhost:9000/home/hadoop/test.csv"
- val conf = new SparkConf().setAppName("Simple Application")
- val sc = new SparkContext(conf)
- val logData = sc.textFile(logFile, 2)
- val num = logData.count()
- println("这个文件有 %d 行!".format(num))
- }
- }
- ----------------------------------------------------------
- vim ./sparkapp3/simple.sbt
- ----------------------------------------------------------
- name := "Simple Project"
- version := "1.0"
- scalaVersion := "2.12.10"
- libraryDependencies += "org.apache.spark" %% "spark-core" % "3.0.0-preview2"
- ----------------------------------------------------------
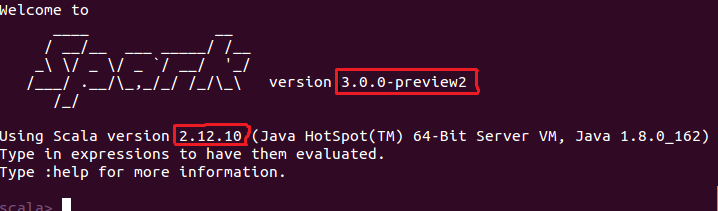
注意:文件 simple.sbt 需要指明 Spark 和 Scala 的版本,如下图所示:
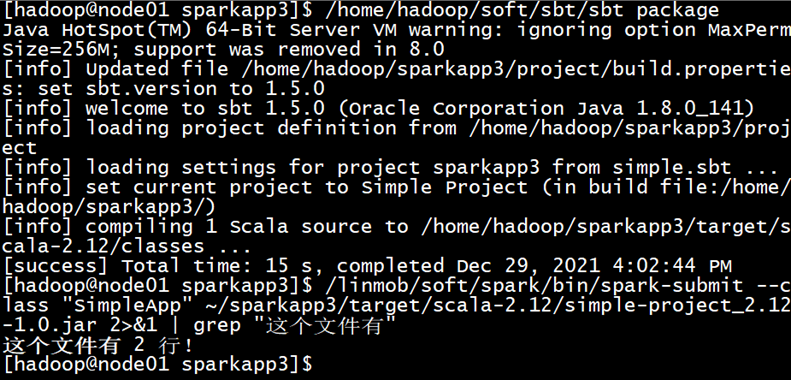
- cd ~/sparkapp3
- /usr/local/sbt/sbt package #这里是需要安装一个sbt,教程在下一篇linux安装sbt - 我试试这个昵称好使不 - 博客园 (cnblogs.com)
- /usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp3/target/scala-2.12/simple-project_2.12-1.0.jar 2>&1 | grep "这个文件有"
实验 3 Spark 和 Hadoop 的安装的更多相关文章
- spark实验(三)--Spark和Hadoop的安装(1)
一.实验目的 (1)掌握在 Linux 虚拟机中安装 Hadoop 和 Spark 的方法: (2)熟悉 HDFS 的基本使用方法: (3)掌握使用 Spark 访问本地文件和 HDFS 文件的方法. ...
- spark实验(一)--spark安装(1)
一.实验目的 (1)掌握 Linux 虚拟机的安装方法.Spark 和 Hadoop 等大数据软件在 Linux 操作系统 上运行可以发挥最佳性能,因此,本教程中,Spark 都是在 Linux 系统 ...
- Spark Hadoop Free 安装遇到的问题
运行 ./sbin/start-master.sh : SparkCommand:/usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java -cp /home/se ...
- spark的standlone模式安装和application 提交
spark的standlone模式安装 安装一个standlone模式的spark集群,这里是最基本的安装,并测试一下如何进行任务提交. require:提前安装好jdk 1.7.0_80 :scal ...
- Spark系列—01 Spark集群的安装
一.概述 关于Spark是什么.为什么学习Spark等等,在这就不说了,直接看这个:http://spark.apache.org, 我就直接说一下Spark的一些优势: 1.快 与Hadoop的Ma ...
- Spark大数据平台安装教程
一.Spark介绍 Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎.Spark是开源的类Hadoop MapReduce的通用并行框架,Spark拥有Hadoop MapRe ...
- Spark学习笔记--Linux安装Spark集群详解
本文主要讲解如何在Linux环境下安装Spark集群,安装之前我们需要Linux已经安装了JDK和Scala,因为Spark集群依赖这些.下面就如何安装Spark进行讲解说明. 一.安装环境 操作系统 ...
- Spark standalone模式的安装(spark-1.6.1-bin-hadoop2.6.tgz)(master、slave1和slave2)
前期博客 Spark运行模式概述 Spark standalone简介与运行wordcount(master.slave1和slave2) 开篇要明白 (1)spark-env.sh 是环境变量配 ...
- 网站用户行为分析——Hadoop的安装与配置(单机和伪分布式)
Hadoop安装方式 Hadoop的安装方式有三种,分别是单机模式,伪分布式模式,伪分布式模式,分布式模式. 单机模式:Hadoop默认模式为非分布式模式(本地模式),无需进行其他配置即可运行.非分布 ...
随机推荐
- mysql事务、隔离级别
一.事务简介 事务是一组操作的集合,它是一一个不可分割的工作单位,事务会把所有的操作作为- -个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败. 二.有关事务操作 mysql中 ...
- SpringBoot入门一:基础知识(环境搭建、注解说明、创建对象方法、注入方式、集成jsp/Thymeleaf、logback日志、全局热部署、文件上传/下载、拦截器、自动配置原理等)
SpringBoot设计目的是用来简化Spring应用的初始搭建以及开发过程.该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置.通过这种方式,SpringBoot致力于在蓬勃发 ...
- Go redis hash存储结构体
需求 需要存储用户数据到redis,结构是hash. 然后取出来,自动转成结构体. 结构体 type UserCache struct { Id int64 `json:"id"` ...
- jq全选、全不选、反选、单删、批量删除
<!DOCTYPE html><html> <head> <meta charset="utf-8" /> <title> ...
- Laravel 报错: Dotenv values containing spaces must be surrounded by quotes.
报错信息如下: 原因: .env文件配置中欧冠包含空格的配置信息,用双引号""引起来即可
- Java IDE的历史变迁及idea的使用
Java开发工具的历史变迁 JCreator Jcreator是荷兰的Xinox Software公司开发的一个用于Java程序设计的集成开发环境(IDE),该公司成立于2001年: 官方网站:htt ...
- go1.18泛型的简单尝试
今天golang终于发布了1.18版本,这个版本最大的一个改变就是加入了泛型.虽然没有在beta版本的时候尝试泛型,但是由于在其他语言的泛型经验,入手泛型不是件难事~ 官方示例 Tutorial: G ...
- python学习之numpy实战
import numpy as np def main(): lst=[[1,3,5],[2,4,6]] print('hello world') print(type(lst)) np_lst = ...
- .NET Core剪裁器Zack.DotNetTrimmer升级瘦身引擎,并支持剪裁计划的录制和回放
上周,我发布了对.NET Core程序进行瘦身的开源软件Zack.DotNetTrimmer,与.NET Core内置的剪裁器相比,Zack.DotNetTrimmer不仅对程序的剪裁效果更好,而且还 ...
- SpringBoot中常用的45个注解
1.SpringBoot/spring @SpringBootApplication: 包含@Configuration.@EnableAutoConfiguration.@ComponentScan ...