小样本利器3. 半监督最小熵正则 MinEnt & PseudoLabel代码实现
在前两章中我们已经聊过对抗学习FGM,一致性正则Temporal等方案,主要通过约束模型对细微的样本扰动给出一致性的预测,推动决策边界更加平滑。这一章我们主要针对低密度分离假设,聊聊如何使用未标注数据来推动决策边界向低密度区移动,相关代码实现详见ClassicSolution/enhancement
半监督领域有几个相互关联的基础假设
- Smoothness平滑度假设:两个样本在高密度空间特征相近,则他们的label大概率相同,宏毅老师美其名曰近朱者赤近墨者黑。这里的高密度比较难理解,感觉可以近似理解为DBSCAN中的密度可达
- Cluster聚类假设:高维特征空间中,同一个簇的样本应该有相同的label,这里的簇其实对应上面平滑假设中的高密度空间。这个假设很强可以理解成Smoothness的特例,在平滑假设中并不一定要成簇
- Low-density Separation低密度分离假设:分类边界应该处于样本空间的低密度区。这个假设更多是以上假设的必要条件,如果决策边界处高密度区,则无法保证聚类簇的完整,以及样本近邻label一致的平滑假设
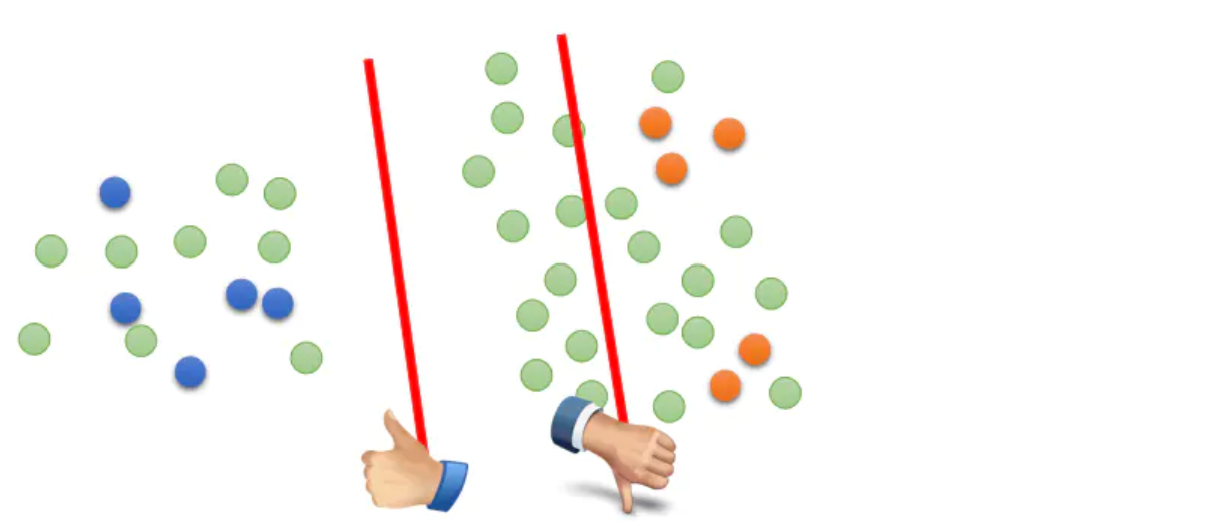
我们举个栗子来理解低密度分离,下图中蓝点和黄点是标注数据样本,绿点是未标注数据。只使用标注样本进行训练,决策边界可能处于中间空白的任意区域,包括未标注样本所在的高密度区。如果分类边界处于高密度区,模型在未标注样本上的预测熵值会偏高,也就是类别之间区分度较低。因此要推动模型远离高密度区,可以通过提高模型在无标注样本上的预测置信度,降低预测熵值来实现,以下给出两种方案MinEnt和PseudoLabel来实现最小熵正则
Entropy-Minimization
- Paper: Semi-supervised Learning by entropy minimization
在之后很多半监督的论文中都能看到05年这边Entropy Minimization的相关引用。论文的核心通过最小化未标注样本的预测概率熵值,来提高模型在以上聚类假设,低密度假设上的稳健性。
实现就是在标注样本交叉熵的基础上加入未标注样本的预测熵值H(y|x),作者称之为熵正则,并通过\(\lambda\)来控制正则项的权重
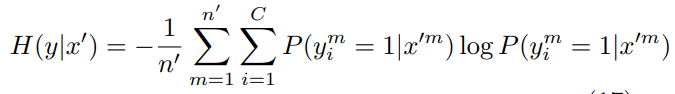
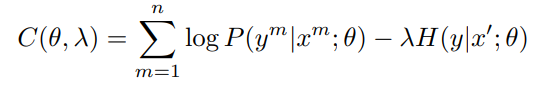
这篇paper咋说呢公式不少,不过都是旁敲侧击的从极大似然等角度来说熵正则有效的原因,但并没给出严谨的证明。。。
Pseudo-Label
- paper: Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks
13年提出的Pseudo Label,其实和上面的MinEnt可以说是一个模子出来的。设计很简单,在训练过程中直接加入未标注数据,使用模型当前的预测结果,也就是pseudo label直接作为未标注样本的label,同样计算交叉熵,并和标注样本的交叉熵融合得到损失函数,如下
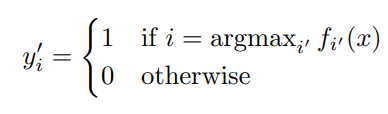
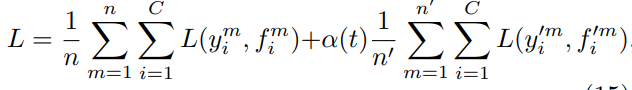
最开始读会比较疑惑,因为之前了解到对pseudo label多是self-training的路子,先用标注数据训练模型,然后在未标注样本上预测,筛选高置信的未标注样本再训练新模型,训练多轮直到模型效果不再提升,而这篇文章的实现其实是把未标注样本作为正则项。因为预测label和预测概率是相同模型给出的,因此最小化预测label的交叉熵,也就是最大化预测为1的class对应的概率值,和MinEnt直接最小化未标注样本交叉熵的操作可谓殊途同归~

正则项的权重部分设计的更加精巧一些,作者使用了分段的权重配置,epoch<T1时正则项的权重为0,避免模型最初训练效果较差时,预测的label准确率低正则项会影响模型收敛,训练到中段后逐渐提高正则项的权重,超过一定epoch之后,权重停止增长。

以上两个基于最小熵正则的实现方案都简单,不过在一些分类任务上尝试后感觉效果比较玄学,在kaggle上分技巧中有大神说过在一些样本很小, 整体边界比较清晰的任务上可能会有提升。主要问题是pseudo label中错误的预测值其实就是噪声样本,所以会在训练中引入噪声,尤其当epoch增长到一定程度后,噪声样本对模型拟合的影响会逐渐增加,而最小熵当样本本身处于错误的区域时,预测置信度的提高,其实是增加了错误预测的置信度。不过之后一些改良方案中都有借鉴最小熵,所以在后面我们会再提到它~
Reference
- https://github.com/iBelieveCJM/pseudo_label-pytorch
- https://zhuanlan.zhihu.com/p/72879773
- https://www.kaggle.com/code/cdeotte/pseudo-labeling-qda-0-969/notebook
- https://stats.stackexchange.com/questions/364584/why-does-using-pseudo-labeling-non-trivially-affect-the-results
小样本利器3. 半监督最小熵正则 MinEnt & PseudoLabel代码实现的更多相关文章
- 小样本利器1.半监督一致性正则 Temporal Ensemble & Mean Teacher代码实现
这个系列我们用现实中经常碰到的小样本问题来串联半监督,文本对抗,文本增强等模型优化方案.小样本的核心在于如何在有限的标注样本上,最大化模型的泛化能力,让模型对unseen的样本拥有很好的预测效果.之前 ...
- 小样本利器2.文本对抗+半监督 FGSM & VAT & FGM代码实现
小样本利器2.文本对抗+半监督 FGSM & VAT & FGM代码实现 上一章我们聊了聊通过一致性正则的半监督方案,使用大量的未标注样本来提升小样本模型的泛化能力.这一章我们结合FG ...
- OSVOS 半监督视频分割入门论文(中文翻译)
摘要: 本文解决了半监督视频目标分割的问题.给定第一帧的mask,将目标从视频背景中分离出来.本文提出OSVOS,基于FCN框架的,可以连续依次地将在IMAGENET上学到的信息转移到通用语义信息,实 ...
- GAN实战笔记——第七章半监督生成对抗网络(SGAN)
半监督生成对抗网络 一.SGAN简介 半监督学习(semi-supervised learning)是GAN在实际应用中最有前途的领域之一,与监督学习(数据集中的每个样本有一个标签)和无监督学习(不使 ...
- 小样本利器4. 正则化+数据增强 Mixup Family代码实现
前三章我们陆续介绍了半监督和对抗训练的方案来提高模型在样本外的泛化能力,这一章我们介绍一种嵌入模型的数据增强方案.之前没太重视这种方案,实在是方法过于朴实...不过在最近用的几个数据集上mixup的表 ...
- [论文][半监督语义分割]Adversarial Learning for Semi-Supervised Semantic Segmentation
Adversarial Learning for Semi-Supervised Semantic Segmentation 论文原文 摘要 创新点:我们提出了一种使用对抗网络进行半监督语义分割的方法 ...
- [论文][半监督语义分割]Semi-Supervised Semantic Segmentation with High- and Low-level Consistency
Semi-Supervised Semantic Segmentation with High- and Low-level Consistency TPAMI 2019 论文原文 code 创新点: ...
- 常见半监督方法 (SSL) 代码总结
经典以及最新的半监督方法 (SSL) 代码总结 最近因为做实验需要,收集了一些半监督方法的代码,列出了一个清单: 1. NIPS 2015 Semi-Supervised Learning with ...
- cips2016+学习笔记︱NLP中的消岐方法总结(词典、有监督、半监督)
歧义问题方面,笔者一直比较关注利用词向量解决歧义问题: 也许你寄希望于一个词向量能捕获所有的语义信息(例如run即是动车也是名词),但是什么样的词向量都不能很好地进行凸显. 这篇论文有一些利用词向量的 ...
随机推荐
- 使用PowerShell下载文件
更新记录 本文迁移自Panda666原博客,原发布时间:2021年7月12日. 使用Invoke-WebRequest指令下载文件 [Net.ServicePointManager]::Securit ...
- SQL Server 2008~2019版本序列号/密钥/激活码 汇总
SQL Server 2019 Enterprise:HMWJ3-KY3J2-NMVD7-KG4JR-X2G8G Strandard:PMBDC-FXVM3-T777P-N4FY8-PKFF4 SQL ...
- SimpleMarkDown编辑器离线版以及桌面应用版上线
之前,我们开发了Web版本SimpleMarkDown编辑器.今天,我们又推出了离线版和桌面应用版. 主要功能: 页面简约: 实时保存: 一键清空内容: 支持微信公众号.知乎.稀土掘金.CSDN等多个 ...
- UiPath循环活动While的介绍和使用
一.While循环的介绍 先判断条件是否满足, 如果满足, 再执行循环体, 直到判断条件不满足,则跳出循环 二.While循环在UiPath中的使用 1. 打开设计器,在设计库中新建一个Flowcha ...
- Autograd: 自动求导
Pytorch中神经网络包中最核心的是autograd包,我们先来简单地学习它,然后训练我们第一个神经网络. autograd包为所有在tensor上的运算提供了自动求导的支持,这是一个逐步运行的框架 ...
- 华为Mate14上安装Ubuntu20.04纪要
Ubuntu16.04用了将近五年了,已经好几年没折腾过系统,所以简要记录一下. 1. 关于UEFI分区,之前的笔记本UEFI是可选的(只是默认该模式),Bios里面还有其他选项.一般安装系统之前 ...
- Identity Server 4客户端认证控制访问API
项目源码: 链接:https://pan.baidu.com/s/1H3Y0ct8xgfVkgq4XsniqFA 提取码:nzl3 一.说明 我们将定义一个api和要访问它的客户端,客户端将在iden ...
- Java_占位符使用
public class t7 { public static void main(String[] args) { // TODO Auto-generated method stub //Java ...
- Solution -「HNOI」EVACUATE
Sol. 可以发现人的移动除了不能穿墙以外没有别的限制.也就是说人的移动多半不是解题的突破口. 接下来会发现出口的限制很强,即出口每个时刻只能允许一个人出去. 每个时刻? 不难想到对于每一个时刻每一个 ...
- pinia 入门及使用
自上月从上海结束工作回来 在家闲来无事 想写点东西打发时间 也顺便学习学习新的技术.偶然发现了 pinia 据说比vuex好用些 所以便搭了个demo尝试着用了下 感觉确实不错,于是便有了这篇随笔. ...