我把 CPU 三级缓存的秘密,藏在这 8 张图里
本文已收录到 GitHub · AndroidFamily,有 Android 进阶知识体系,欢迎 Star。技术和职场问题,请关注公众号 [彭旭锐] 进 Android 面试交流群。
前言
大家好,我是小彭。
在上一篇文章里,我们聊到了计算机存储器系统的金字塔结构,其中在 CPU 和内存之间有一层高速缓存,就是我们今天要聊的 CPU 三级缓存。
那么,CPU Cache 的结构是怎样的,背后隐含着哪些设计思想,CPU Cache 和内存数据是如何关联起来的,今天我们将围绕这些问题展开。
学习路线图:
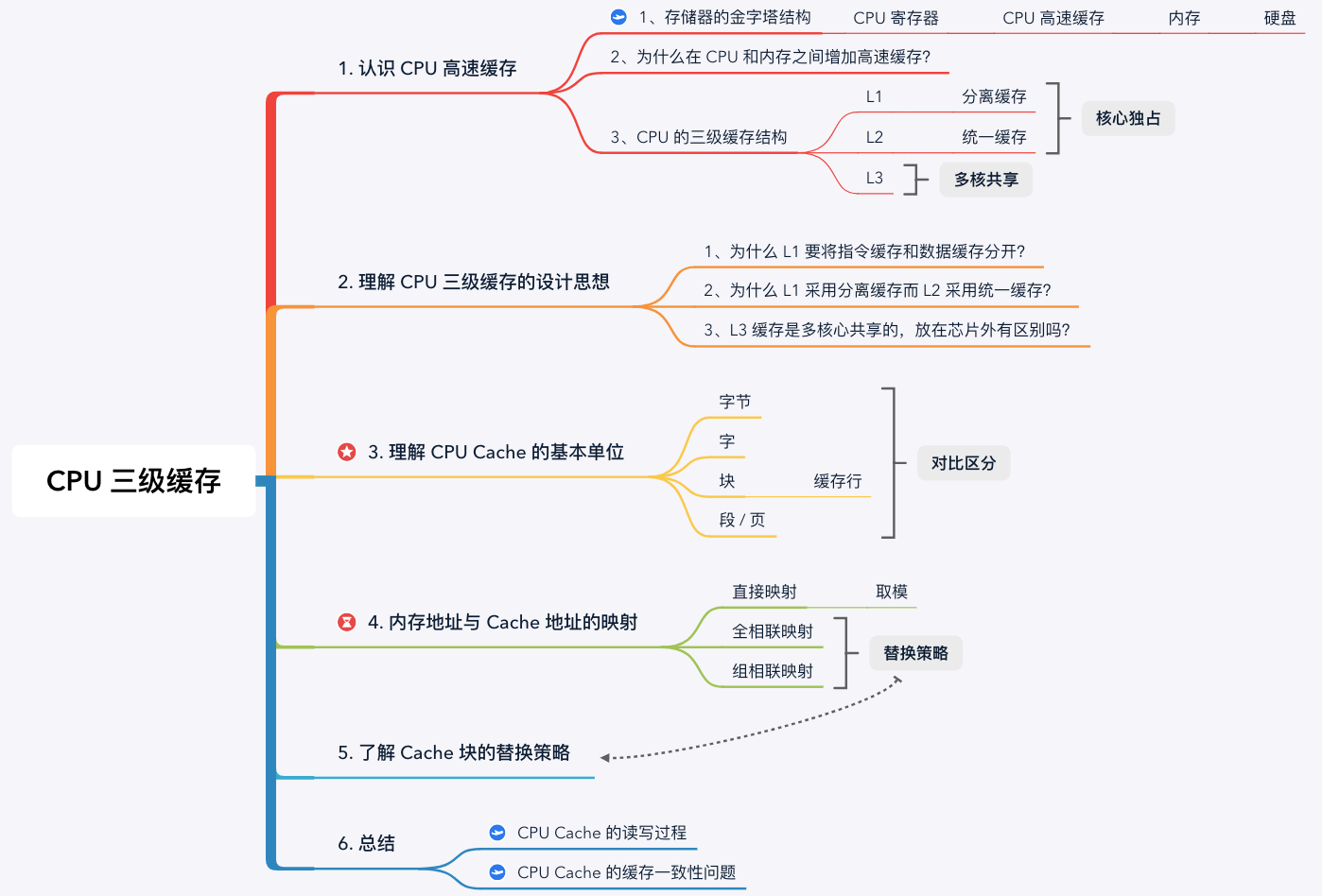
1. 认识 CPU 高速缓存
1.1 存储器的金字塔结构
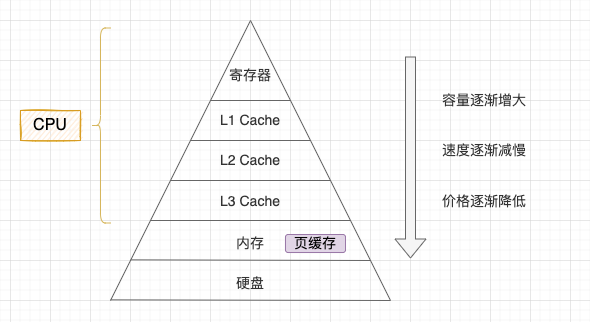
现代计算机系统为了寻求容量、速度和价格最大的性价比会采用分层架构,从 “CPU 寄存器 - CPU 高速缓存 - 内存 - 硬盘”自上而下容量逐渐增大,速度逐渐减慢,单位价格也逐渐降低。
- 1、CPU 寄存器: 存储 CPU 正在使用的数据或指令;
- 2、CPU 高速缓存: 存储 CPU 近期要用到的数据和指令;
- 3、内存: 存储正在运行或者将要运行的程序和数据;
- 4、硬盘: 存储暂时不使用或者不能直接使用的程序和数据。
存储器金字塔
1.2 为什么在 CPU 和内存之间增加高速缓存?
我认为有 2 个原因:
原因 1 - 弥补 CPU 和内存的速度差(主要): 由于 CPU 和内存的速度差距太大,为了拉平两者的速度差,现代计算机会在两者之间插入一块速度比内存更快的高速缓存。只要将近期 CPU 要用的信息调入缓存,CPU 便可以直接从缓存中获取信息,从而提高访问速度;
原因 2 - 减少 CPU 与 I/O 设备争抢访存: 由于 CPU 和 I/O 设备会竞争同一条内存总线,有可能出现 CPU 等待 I/O 设备访存的情况。而如果 CPU 能直接从缓存中获取数据,就可以减少竞争,提高 CPU 的效率。
1.3 CPU 的三级缓存结构
在 CPU Cache 的概念刚出现时,CPU 和内存之间只有一个缓存,随着芯片集成密度的提高,现代的 CPU Cache 已经普遍采用 L1/L2/L3 多级缓存的结构来改善性能。自顶向下容量逐渐增大,访问速度也逐渐降低。当缓存未命中时,缓存系统会向更底层的层次搜索。
- L1 Cache: 在 CPU 核心内部,分为指令缓存和数据缓存,分开存放 CPU 使用的指令和数据;
- L2 Cache: 在 CPU 核心内部,尺寸比 L1 更大;
- L3 Cache: 在 CPU 核心外部,所有 CPU 核心共享同一个 L3 缓存。
CPU 三级缓存

2. 理解 CPU 三级缓存的设计思想
2.1 为什么 L1 要将指令缓存和数据缓存分开?
这个策略叫分离缓存,与之相对应的叫统一缓存:
- 分离缓存: 指令和数据分别存放在不同缓存中:
- 指令缓存(Instruction Cache,I-Cache)
- 数据缓存(Data Cache,D-Cache)
- 统一缓存: 指令和数据统一存放在一个缓存中。
那么,为什么 L1 缓存要把指令和数据分开呢?我认为有 2 个原因:
原因 1 - 避免取指令单元和取数据单元争夺访缓存(主要): 在 CPU 内核中,取指令和取数据指令是由两个不同的单元完成的。如果使用统一缓存,当 CPU 使用超前控制或流水线控制(并行执行)的控制方式时,会存在取指令操作和取数据操作同时争用同一个缓存的情况,降低 CPU 运行效率;
原因 2 - 内存中数据和指令是相对聚簇的,分离缓存能提高命中率: 在现代计算机系统中,内存中的指令和数据并不是随机分布的,而是相对聚集地分开存储的。因此,CPU Cache 中也采用分离缓存的策略更符合内存数据的现状;
2.2 为什么 L1 采用分离缓存而 L2 采用统一缓存?
我认为原因有 2 个:
原因 1: L1 采用分离缓存后已经解决了取指令单元和取数据单元的争夺访缓存问题,所以 L2 是否使用分离缓存没有影响;
原因 2: 当缓存容量较大时,分离缓存无法动态调节分离比例,不能最大化发挥缓存容量的利用率。例如数据缓存满了,但是指令缓存还有空闲,而 L2 使用统一缓存则能够保证最大化利用缓存空间。
2.3 L3 缓存是多核心共享的,放在芯片外有区别吗?
集成在芯片内部的缓存称为片内缓存,集成在芯片外部(主板)的缓存称为片外缓存。最初,由于受到芯片集成工艺的限制,片内缓存不可能很大,因此 L2 / L3 缓存都是设计在主板上,而不是在芯片内的。
后来,L2 / L3 才逐渐集成到 CPU 芯片内部后的。片内缓冲和片外缓存是有区别的,主要体现在 2 个方面:
区别 1 - 片内缓存物理距离更短: 片内缓存与取指令单元和取数据单元的物理距离更短,速度更快;
区别 2 - 片内缓存不占用系统总线: 片内缓存使用独立的 CPU 片内总线,可以减轻系统总线的负担。
3. CPU Cache 的基本单位 —— Cache Line
CPU Cache 在读取内存数据时,每次不会只读一个字或一个字节,而是一块块地读取,这每一小块数据也叫 CPU 缓存行(CPU Cache Line)。这也是对局部性原理的应用,当一个指令或数据被访问过之后,与它相邻地址的数据有很大概率也会被访问,将更多可能被访问的数据存入缓存,可以提高缓存命中率。
当然,块长也不是越大越好(一般是取 4 到 8 个字长,即 64 位):
- 前期:当块长由小到大增长时,随着局部性原理的影响使得命中率逐渐提高;
- 后期:但随着块长继续增大,导致缓存中承载的块个数减少,很可能内存块刚刚装入缓存就被新的内存块覆盖,命中率反而下降。而且,块长越长,追加的部分距离被访问的字越远,近期被访问的可能性也更低,无济于事。
区分几种容量单位:
- 字节(Byte): 字节是计算机数据存储的基本单位,即使存储 1 个位也需要按 1 个字节存储;
- 字(Word): 字长是 CPU 在单位时间内能够同时处理的二进制数据位数。多少位 CPU 就是指 CPU 的字长是多少位(比如 64 位 CPU 的字长就是 64 位);
- 块(Block): 块是 CPU Cache 管理数据的基本单位,也叫 CPU 缓存行;
- 段(Segmentation)/ 页(Page): 段 / 页是操作系统管理虚拟内存的基本单位。
事实上,CPU 在访问内存数据的时候,与计算机中对于 “缓存设计” 的一般性规律是相同的: 对于基于 Cache 的系统,对数据的读取和写入总会先访问 Cache,检查要访问的数据是否在 Cache 中。如果命中则直接使用 Cache 上的数据,否则先将底层的数据源加载到 Cache 中,再从 Cache 读取数据。
那么,CPU 怎么知道要访问的内存数据是否在 CPU Cache 中,在 CPU 中的哪个位置,以及是不是有效的呢?这就是下一节要讲的内存地址与 Cache 地址的映射问题。
4. 内存地址与 Cache 地址的映射
无论对 Cache 数据检查、读取还是写入,CPU 都需要知道访问的内存数据对应于 Cache 上的哪个位置,这就是内存地址与 Cache 地址的映射问题。
事实上,因为内存块和缓存块的大小是相同的,所以在映射的过程中,我们只需要考虑 “内存块索引 - 缓存块索引” 之间的映射关系,而具体访问的是块内的哪一个字,则使用相同的偏移在块中寻找。举个例子:假设内存有 32 个内存块,CPU Cache 有 8 个缓存块,我们只需要考虑 紫色 部分标识的索引如何匹配即可。
目前,主要有 3 种映射方案:
- 1、直接映射(Direct Mapped Cache): 固定的映射关系;
- 2、全相联映射(Fully Associative Cache): 灵活的映射关系;
- 3、组相联映射(N-way Set Associative Cache): 前两种方案的折中方法。
内存块索引 - 缓存块索

4.1 直接映射
直接映射是三种方式中最简单的映射方式,直接映射的策略是: 在内存块和缓存块之间建立起固定的映射关系,一个内存块总是映射到同一个缓存块上。
具体方式:
1、将内存块索引对 Cache 块个数取模,得到固定的映射位置。例如 13 号内存块映射的位置就是 13 % 8 = 5,对应 5 号 Cache 块;
2、由于取模后多个内存块会映射到同一个缓存块上,产生块冲突,所以需要在 Cache 块上增加一个 组标记(TAG),标记当前缓存块存储的是哪一个内存块的数据。其实,组标记就是内存块索引的高位,而 Cache 块索引就是内存块索引的低 4 位(8 个字块需要 4 位);
3、由于初始状态 Cache 块中的数据是空的,也是无效的。为了标识 Cache 块中的数据是否已经从内存中读取,需要在 Cache 块上增加一个 有效位(Valid bit) 。如果有效位为 0,则 CPU 可以直接读取 Cache 块上的内容,否则需要先从内存读取内存块填入 Cache 块,再将有效位改为 1。
直接映射

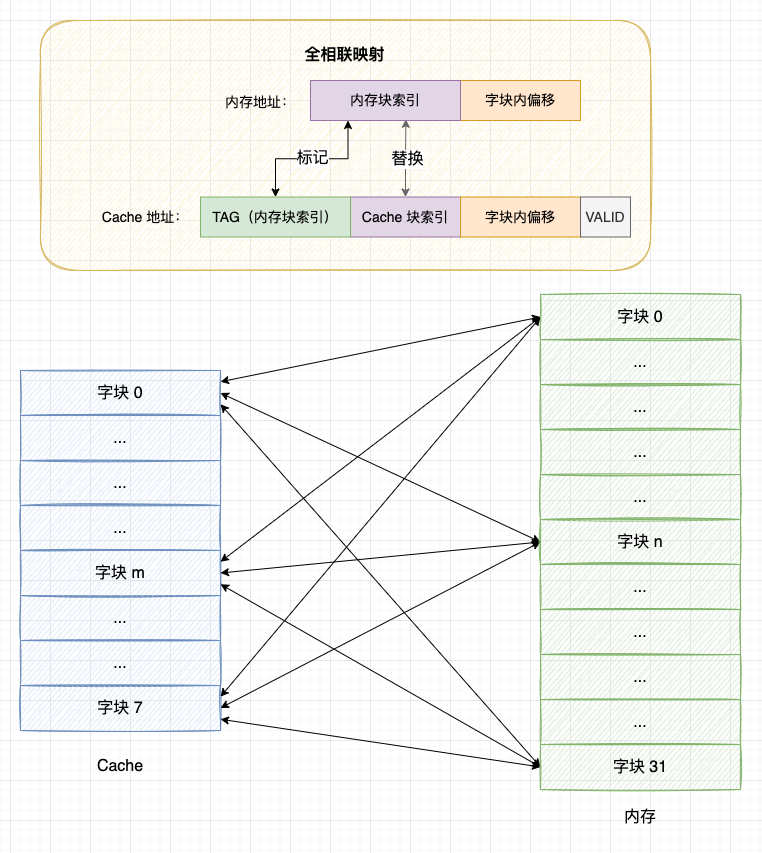
4.2 全相联映射
理解了直接映射的方式后,我们发现直接映射存在 2 个问题:
- 问题 1 - 缓存利用不充分: 每个内存块只能映射到固定的位置上,即使 Cache 上有空闲位置也不会使用;
- 问题 2 - 块冲突率高: 直接映射会频繁出现块冲突,影响缓存命中率。
基于直接映射的缺点,全相联映射的策略是: 允许内存块映射到任何一个 Cache 块上。 这种方式能够充分利用 Cache 的空间,块冲突率也更低,但是所需要的电路结构物更复杂,成本更高。
具体方式:
- 1、当 Cache 块上有空闲位置时,使用空闲位置;
- 2、当 Cache 被占满时则替换出一个旧的块腾出空闲位置;
- 3、由于一个 Cache 块会映射所有内存块,因此组标记 TAG 需要扩大到与主内存块索引相同的位数,而且映射的过程需要沿着 Cache 从头到尾匹配 Cache 块的 TAG 标记。
全相联映射
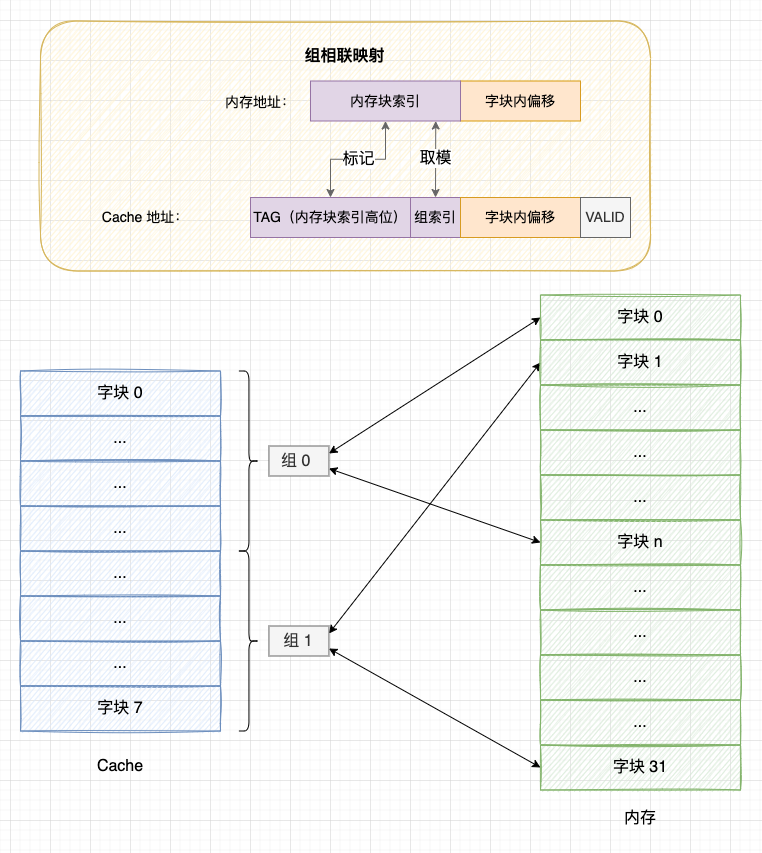
4.3 组相联映射
组相联映射是直接映射和全相联映射的折中方案,组相联映射的策略是: 将 Cache 分为多组,每个内存块固定映射到一个分组中,又允许映射到组内的任意 Cache 块。显然,组相联的分组为 1 时就等于全相联映射,而分组等于 Cache 块个数时就等于直接映射。
组相联映射
5. Cache 块的替换策略
在使用直接映射的 Cache 中,由于每个主内存块都与某个 Cache 块有直接映射关系,因此不存在替换策略。而使用全相联映射或组相联映射的 Cache 中,主内存块与 Cache 块没有固定的映射关系,当新的内存块需要加载到 Cache 中时(且 Cache 块没有空闲位置),则需要替换到 Cache 块上的数据。此时就存在替换策略的问题。
常见替换策略:
1、随机法: 使用一个随机数生成器随机地选择要被替换的 Cache 块,实现简单,缺点是没有利用 “局部性原理”,无法提高缓存命中率;
2、FIFO 先进先出法: 记录各个 Cache 块的加载事件,最早调入的块最先被替换,缺点同样是没有利用 “局部性原理”,无法提高缓存命中率;
3、LRU 最近最少使用法: 记录各个 Cache 块的使用情况,最近最少使用的块最先被替换。这种方法相对比较复杂,也有类似的简化方法,即记录各个块最近一次使用时间,最久未访问的最先被替换。与前 2 种策略相比,LRU 策略利用了 “局部性原理”,平均缓存命中率更高。
6. 总结
1、为了弥补 CPU 和内存的速度差和减少 CPU 与 I/O 设备争抢访存,计算机在 CPU 和内存之间增加高速缓存,一般存在 L1/L2/L3 多级缓存的结构;
2、对于基于 Cache 的存储系统,对数据的读取和写入总会先访问 Cache,检查要访问的数据是否在 Cache 中。如果命中则直接使用 Cache 上的数据,否则先将底层的数据源加载到 Cache 中,再从 Cache 读取数据;
3、CPU Cache 是一块块地从内存读取数据,一块数据就是缓存行;
4、内存地址与 Cache 地址的映射有直接映射、全相联映射和组相联映射;
5、使用全相联映射或组相联映射的 Cache 中,当新的内存块需要加载到 Cache 中时且 Cache 块没有空闲位置,则需要替换到 Cache 块上的数据。
今天,我们主要讨论了 CPU Cache 的基本设计思想以及 Cache 与内存的映射关系。具体 CPU Cache 是如何读取和写入的还没讲,另外有一个 CPU 缓存一致性问题 说的又是什么呢?下一篇文章我们详细展开讨论,请关注。
参考资料
- 深入浅出计算机组成原理(第 37、38 讲) —— 徐文浩 著,极客时间 出品
- 计算机组成原理教程(第 7 章) —— 尹艳辉 王海文 邢军 著
- 面试官:如何写出让 CPU 跑得更快的代码? —— 小林 Coding 著
- CPU cache —— Wikipedia
- CPU caches —— LWN.net
我把 CPU 三级缓存的秘密,藏在这 8 张图里的更多相关文章
- 浅谈CPU三级缓存和缓存命中率
CPU: CPU缓存(Cache Memory)是位于CPU与内存之间的临时存储器,它的容量比内存小的多但是交换速度却比内存要快得多.缓存的出现主要是 为了解决CPU运算速度与内存读写速度不匹配的矛盾 ...
- Dubbo的设计理念原来就藏在这三张图中
Dubbo在众多的微服务框架中脱颖而出,占据RPC服务框架的半壁江山,非常具有普适性,熟练掌握 Dubbo的应用技巧后深刻理解其内部实现原理,让大家能更好的掌控工作,助力职场,特别能让大家在面试中脱颖 ...
- CPU 执行程序的秘密,藏在了这 15 张图里
前言 代码写了那么多,你知道 a = 1 + 2 这条代码是怎么被 CPU 执行的吗? 软件用了那么多,你知道软件的 32 位和 64 位之间的区别吗?再来 32 位的操作系统可以运行在 64 位的电 ...
- 聊聊高并发(三十四)Java内存模型那些事(二)理解CPU快速缓存的工作原理
在上一篇聊聊高并发(三十三)从一致性(Consistency)的角度理解Java内存模型 我们说了Java内存模型是一个语言级别的内存模型抽象.它屏蔽了底层硬件实现内存一致性需求的差异,提供了对上层的 ...
- [转帖]CPU 的缓存
缓存这个词想必大家都听过,其实缓存的意义很广泛:电脑整机最大的缓存可以体现为内存条.显卡上的显存就是显卡芯片所需要用到的缓存.硬盘上也有相对应的缓存.CPU有着最快的缓存(L1.L2.L3缓存等),缓 ...
- java并发编程(三)cpu cache & 缓存一致性
一 cpu cache 1. cache的意义 为什么需要CPU cache?因为CPU的频率太快了,快到主存跟不上,这样在处理器时钟周期内,CPU常常需要等待主存,浪费资源.所以cache的出 ...
- 10 张图打开 CPU 缓存一致性的大门
前言 直接上,不多 BB 了. 正文 CPU Cache 的数据写入 随着时间的推移,CPU 和内存的访问性能相差越来越大,于是就在 CPU 内部嵌入了 CPU Cache(高速缓存),CPU Cac ...
- 并发编程二、CPU多级缓存架构与MESI协议的诞生
前言: 文章内容:线程与进程.线程生命周期.线程中断.线程常见问题总结 本文章内容来源于笔者学习笔记,内容可能与相关书籍内容重合 偏向于知识核心总结,非零基础学习文章,可用于知识的体系建立,核心内容 ...
- 关于Android中的三级缓存
三级缓存的提出就是为了提升用户体验.当我们第一次打开应用获取图片时,先到网络去下载图片,然后依次存入内存缓存,磁盘缓存,当我们再一次需要用到刚才下载的这张图片时,就不需要再重复的到网络上去下载,直接可 ...
- Android 的图片异步请求加三级缓存 ACE
使用xUtils等框架是很方便,但今天要用代码实现bitmapUtils 的功能,很简单, 1 AsyncTask请求一张图片 ####AsyncTask #####AsyncTask是线程池+han ...
随机推荐
- D - Distinct Trio
D - Distinct Trio 题意:求三个数个各不相同的数目. 题解:正面考虑比较困难,可以反向思考,在总值上减去不符合的即可 #include<bits/stdc++.h> usi ...
- 硬核解析MySQL的MVCC实现原理,面试官看了都直呼内行
1. 什么是MVCC MVCC全称是Multi-Version Concurrency Control(多版本并发控制),是一种并发控制的方法,通过维护一个数据的多个版本,减少读写操作的冲突. 如果没 ...
- docker_命令总结
docker -v /hostDir:/containerDir /hostDir为宿主机的目录 /containerDir为容器内的目录 -v 实现两个目录的挂在,即容器内数据持久化到本机 dock ...
- MariaDB数据库 主-从 部署
〇.前言 好久没碰数据库了 准备环境: centos7自带的MariaDB,没有的话下面是安装命令 yum install -y mariadb mariadb-server systemctl re ...
- 华南理工大学 Python第3章课后小测-2
1.(单选)给出如下代码 s = 'Hello scut' print(s[4::-1]) 上述代码的输出结果是(本题分数:2)A) HelloB) olleHC) scutD) tucs您的答案:B ...
- 类似微信聊天小程序-网易云信,IM DEMO小程序版本
类似微信聊天小程序-网易云信,IM DEMO小程序版本 代码地址: https://github.com/netease-im/NIM_Web_Weapp_Demo 云信IM DEMO 小程序版本 ( ...
- 现有rabbitmq集群添加新节点,移除旧节点(可以作为rabbitmq集群迁移使用)
原有集群安装步骤:https://www.cnblogs.com/sanduzxcvbnm/p/15797788.html 1.拉取镜像 集群中新节点需要执行 docker pull rabbitmq ...
- 使用KubeOperator扩展k8s集群的worker节点
官方文档网址:https://kubeoperator.io/docs/installation/install/ 背景说明 原先是一个三节点的k8s集群,一个master,三个woker(maste ...
- 玖章算术受邀参加红杉Talk「创新的复利」科技专场,共同探讨云计算的前世今生
9月2日,本周五14:00 「创新的复利」 Sequoia Talk系列论坛,首期直播盛大启动.在第一期科技专场,4位红杉中国资深投资人.8位创新创业者将带我们深入工业软件.机器人.云计算等领域,围绕 ...
- PHP全栈开发(八):CSS Ⅰ 选择器
直到目前为止,我们把从HTML中的数据是如何通过PHP到服务器端,然后又通过PHP到数据库,然后从数据库中出来,通过PHP到HTML的整个过程通过一个案例过了一遍. 可以说,这些才刚刚开始.下面我们开 ...