CDH6.2.0 搭建大数据集群
1. 资料准备
现在官网https://www.cloudera.com 需要注册账号,未来可能会收费等问题,十分麻烦,这里有一份我自己百度云的备份
链接: https://pan.baidu.com/s/1kh50Z2f9S09Ln8E8uOow8Q
提取码: b9jf
里面有一整套下载内容
比如: mysql 的包 和 mysql-connector-java-5.1.47.tar.gz
JDK1.8下载地址
https://www.oracle.com/java/technologies/javase/javase8-archive-downloads.html
jdk-8u241-linux-x64.tar.gz
准备 三台服务器:2核 16G内存(这里是在腾讯云申请的三台)
8G 内存也可以,但作为自己的实验环境会不大好用,仅仅是刚刚能把环境搭建起来而已
2. 环境配置
- 配置静态IP (腾讯云自带内网静态IP,不用搞了)
- 配置主机名映射(三台机器都需要配置)
添加内网IP 和对应的主机名称,三台都设置为腾讯云内网IP
vim /etc/hosts
10.206.16.14 hadoop1
10.206.16.2 hadoop2
10.206.16.8 hadoop3
- 关闭防火墙(三台机器都需要配置)
#停止firewall
systemctl stop firewalld.service
#禁止firewall开机启动
systemctl disable firewalld.service
#查看默认防火墙状态(关闭后显示notrunning,开启后显示running)
firewall-cmd --state
- 关闭SELINUX(三台都要配置)
vim /etc/selinux/config
修改
SELINUX=disabled
- 配置时钟同步(三台都要配置)
## 时区
# 所有节点保存时区一致 (由于腾讯云默认上海东八区,可以不搞)
timedatectl --help # 查看帮助命令
timedatectl list-timezones # 列出时区
timedatectl set-timezone # 设置时区
# 所有节点安装ntp
yum install -y ntp
# 所有节点停止禁用ntpd服务
systemctl stop ntpd
systemctl disable ntpd
# 每个节点使用crontab每天同步时间 从腾讯ntp服务器同步时间
crontab –e
#追加这一行定时任务
*/20 * * * * /usr/sbin/ntpdate ntpupdate.tencentyun.com > /dev/null &
- 配置免密登录(每个节点)
1. 创建用户hadoop
useradd hadoop
passwd hadoop ##设置其密码
visudo
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL ## 自主添加的一行
修改完毕 :wq!
1.2 /opt 下创建目录
使用hadoop 登录
mkdir module
mkdir software
2. 在其hadoop和root用户目录下执行(都需要配置免密登录,或者仅配置root也可以)
ssh-keygen -t rsa
3. 三个节点执行完毕后,再每个节点执行(hadoop1 等为主机名)
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3
- hadoop1 配置文件分发脚本 xsync
创建文件
vim /usr/local/bin/xsync
插入内容
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=1; host<4; host++)); do
echo ------------------- hadoop$host --------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
添加脚本权限
chmod 777 /usr/local/bin/xsync
- 安装jdk (三台机器)
上传jdk的压缩文件
解压缩到指定目录下
tar -zxvf jdk-8u141-linux-x64.tar.gz -C /opt/module/
配置配置文件
vim /etc/profile
##JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_141
export PATH=$JAVA_HOME/bin:$PATH
source /etc/profile
## 验证
which java
java -version
- 上传 mysql-connector-java (三台机器)
通过rz 上传到 /opt/software
并mysql-connector-java-5.1.47-bin.jar去版本号 改名为 mysql-connector-java.jar
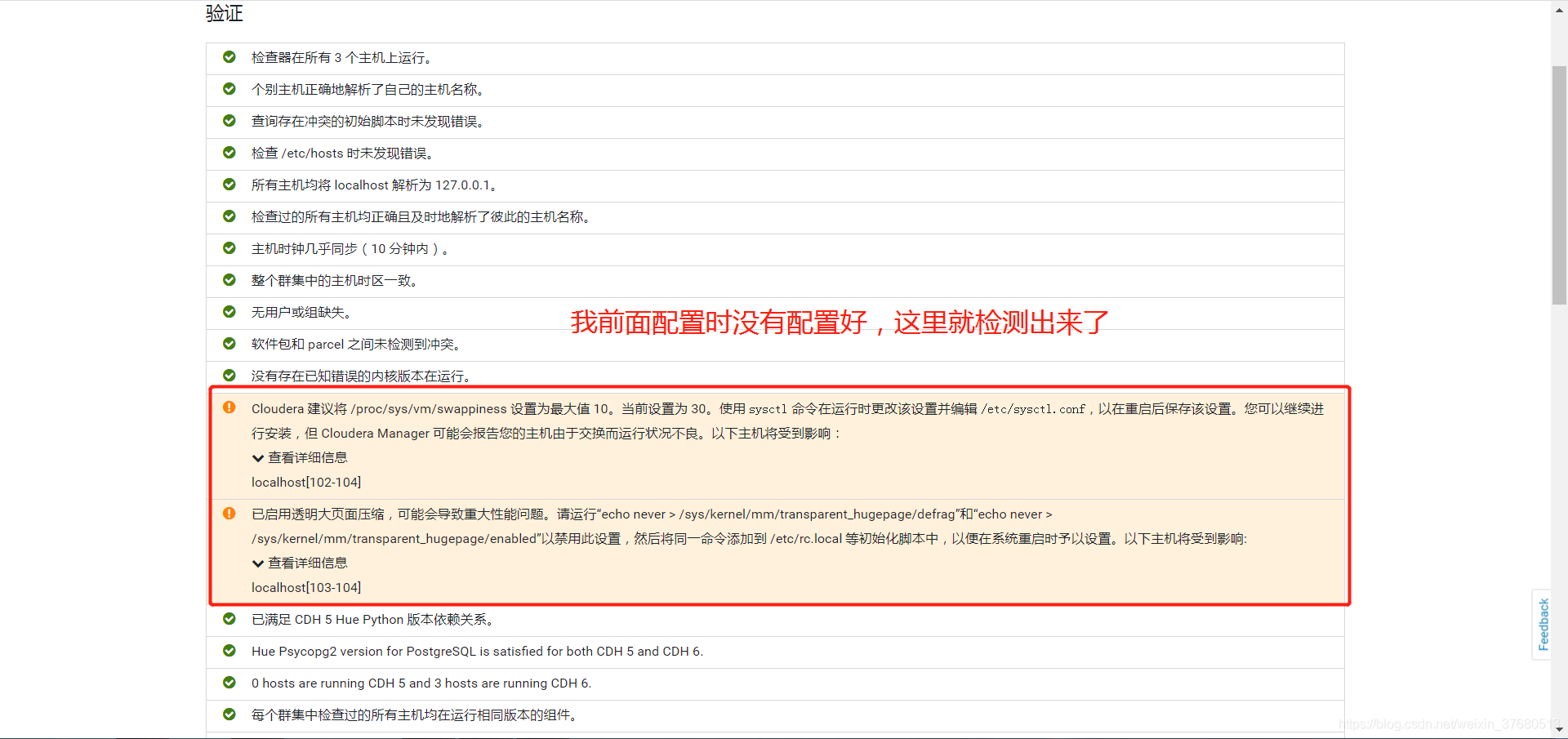
- 节点修改linux swappiness参数(三台机器)
## 设置为0,重启后又还原
echo 0 > /proc/sys/vm/swappiness
## 修改配置文件, 添加参数
vi /etc/sysctl.conf
vm.swappiness=0
## 上述在el6中有效,在el7中tuned服务会动态调整参数
## 查找tuned配置,直接修改,进入tuned目录
cd /usr/lib/tuned/
## 查找包含的所在文件路径
grep "vm.swappiness" * -R
## 逐个修改参数vm.swappiness=0
vi latency-performance/tuned.conf
## 修改后确认
grep "vm.swappiness" * -R
## sysctl修改内核参数 重启不生效 参考:
https://blog.csdn.net/ygtlovezf/article/details/79014299
- 节点禁用透明页
## 立刻生效
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled
## 永久生效 在/etc/rc.local末尾添加两行
vi /etc/rc.local
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled
## 给与可执行权限
chmod +x /etc/rc.d/rc.local
3. mysql 安装
任选一节点,比如 hadoop1 上安装mysql
## 先卸载自带的数据库
rpm -qa | grep mariadb
rpm -e --nodeps mariadb-libs-5.5.64-1.el7.x86_64
## 查找并卸载老版本mysql
find / -name mysql|xargs rm -rf
## 安装
rpm -ivh mysql-community-common-5.7.31-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.31-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-compat-5.7.31-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-5.7.31-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-5.7.31-1.el7.x86_64.rpm
如果报错 执行
yum -y install numactl
# 查看状态及启动
systemctl status mysqld
systemctl start mysql
systemctl disable mysqld # 关闭开机自启动,不用的时候关掉,占资源
## 查看临时密码
grep 'temporary password' /var/log/mysqld.log
mysql -uroot -p临时密码
## 直接设置密码会出现
ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
set global validate_password_policy=LOW;
set global validate_password_length=6;
set password=password('999999');
use mysql;
select host, user, authentication_string from user;
update user set host='%' where host="localhost";
## 登录
mysql -uroot -p999999
## 注意
# mysql5.6需要安装以下两个组件,否则无法安装agent
MySQL-shared-5.6.49-1.el7.x86_64.rpm
MySQL-shared-compat-5.6.49-1.el7.x86_64.rpm
# mysql5.7需要安装
mysql-community-libs-compat-5.7.31-1.el7.x86_64.rpm
创建元数据库和用户
DROP DATABASE IF EXISTS cmf;
DROP DATABASE IF EXISTS amon;
DROP DATABASE IF EXISTS cmserver;
DROP DATABASE IF EXISTS metastore;
DROP DATABASE IF EXISTS amon;
DROP DATABASE IF EXISTS rman;
DROP DATABASE IF EXISTS oozie;
DROP DATABASE IF EXISTS hue;
DROP DATABASE IF EXISTS hive;
CREATE DATABASE scm DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON scm.* TO 'scm'@'%' IDENTIFIED BY 'scm';
CREATE DATABASE amon DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON amon.* TO 'amon'@'%' IDENTIFIED BY 'amon';
CREATE DATABASE rman DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON rman.* TO 'rman'@'%' IDENTIFIED BY 'rman';
CREATE DATABASE hue DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON hue.* TO 'hue'@'%' IDENTIFIED BY 'hue';
CREATE DATABASE metastore DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON metastore.* TO 'hive'@'%' IDENTIFIED BY 'hive';
CREATE DATABASE sentry DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON sentry.* TO 'sentry'@'%' IDENTIFIED BY 'sentry';
CREATE DATABASE nav DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON nav.* TO 'nav'@'%' IDENTIFIED BY 'nav';
CREATE DATABASE navms DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON navms.* TO 'navms'@'%' IDENTIFIED BY 'navms';
CREATE DATABASE oozie DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON oozie.* TO 'oozie'@'%' IDENTIFIED BY 'oozie';
CREATE DATABASE hive default charset utf8 collate utf8_general_ci;
GRANT ALL PRIVILEGES ON hive.* TO 'hive'@'%' IDENTIFIED BY '999999';
flush privileges;
4. CDH 安装
- 离线安装cm server及agent
## 先安装agent需要的依赖
yum install -y redhat-lsb httpd mod_ssl openssl-devel python-psycopg2 MySQL-python libpq.so
yum -y install chkconfig python bind-utils psmisc libxslt zlib sqlite cyrus-sasl-plain cyrus-sasl-gssapi fuse fuse-libs redhat-lsb portmap
## 主节点为hadoop1,其他节点为从节点
## 主节点安装daemons, server, agent
rpm -ivh cloudera-manager-daemons-6.2.0-968826.el7.x86_64.rpm # 必要包
rpm -ivh cloudera-manager-server-6.2.0-968826.el7.x86_64.rpm # server
rpm -ivh cloudera-manager-agent-6.2.0-968826.el7.x86_64.rpm # agent
## 从节点安装daemons, agent
rpm -ivh cloudera-manager-daemons-6.2.0-968826.el7.x86_64.rpm
rpm -ivh cloudera-manager-agent-6.2.0-968826.el7.x86_64.rpm
## 从节点修改agent的配置,指向server的节点
vi /etc/cloudera-scm-agent/config.ini
server_host=hadoop1
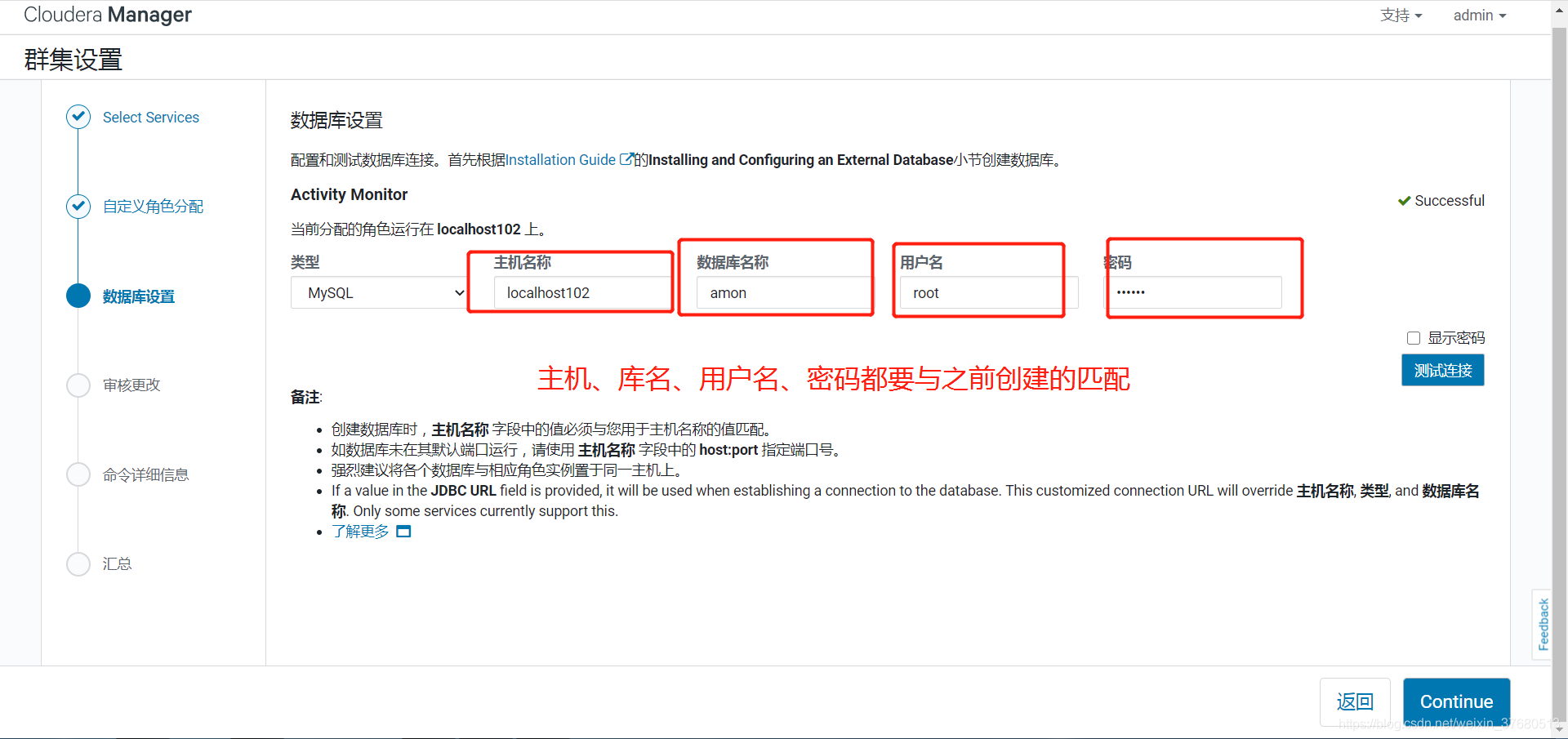
## 主节点修改server的配置,确定以下项与之前创建库时一致
vi /etc/cloudera-scm-server/db.properties
com.cloudera.cmf.db.type=mysql
com.cloudera.cmf.db.host=hadoop1
com.cloudera.cmf.db.name=cmf
com.cloudera.cmf.db.user=cmf
com.cloudera.cmf.db.password=999999
com.cloudera.cmf.db.setupType=EXTERNAL
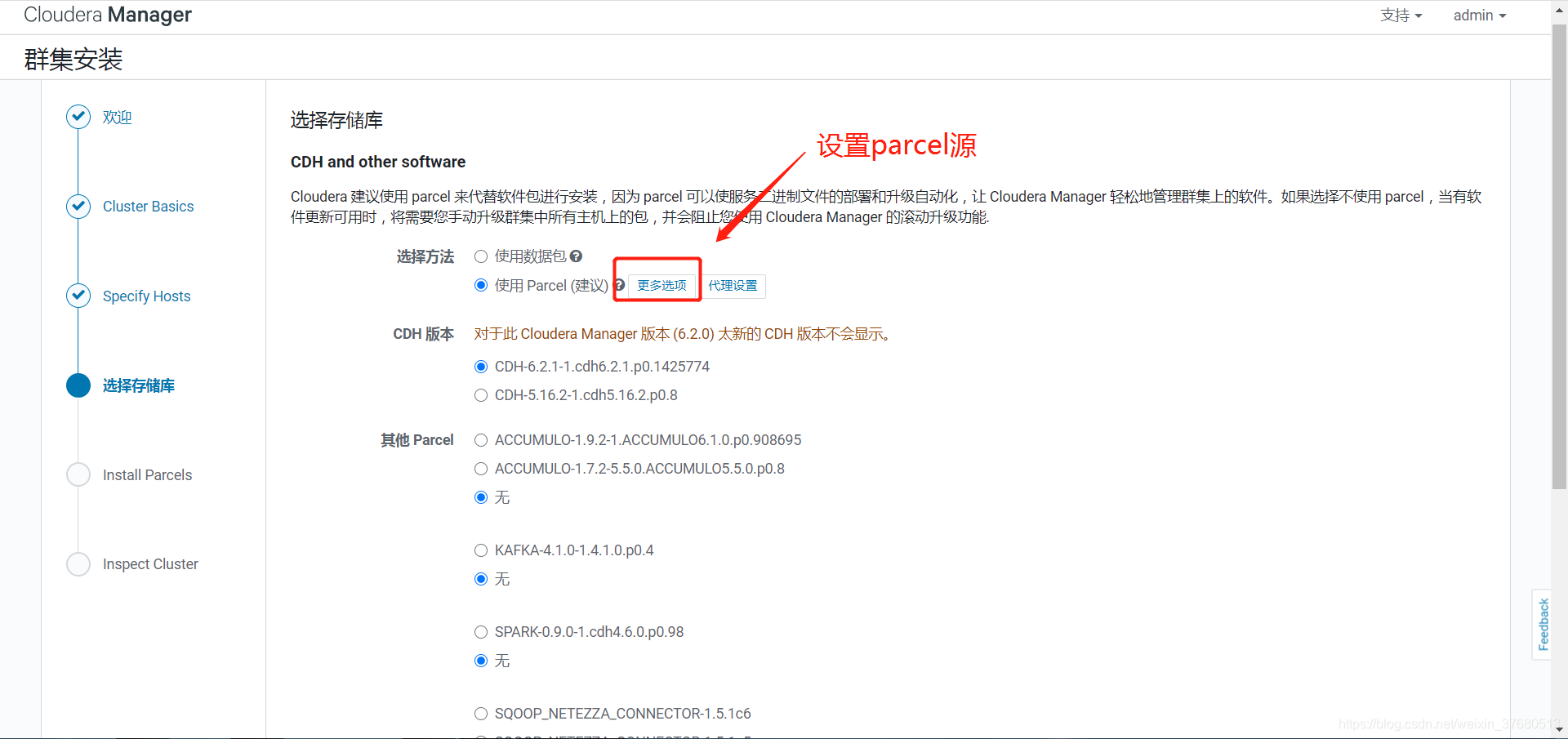
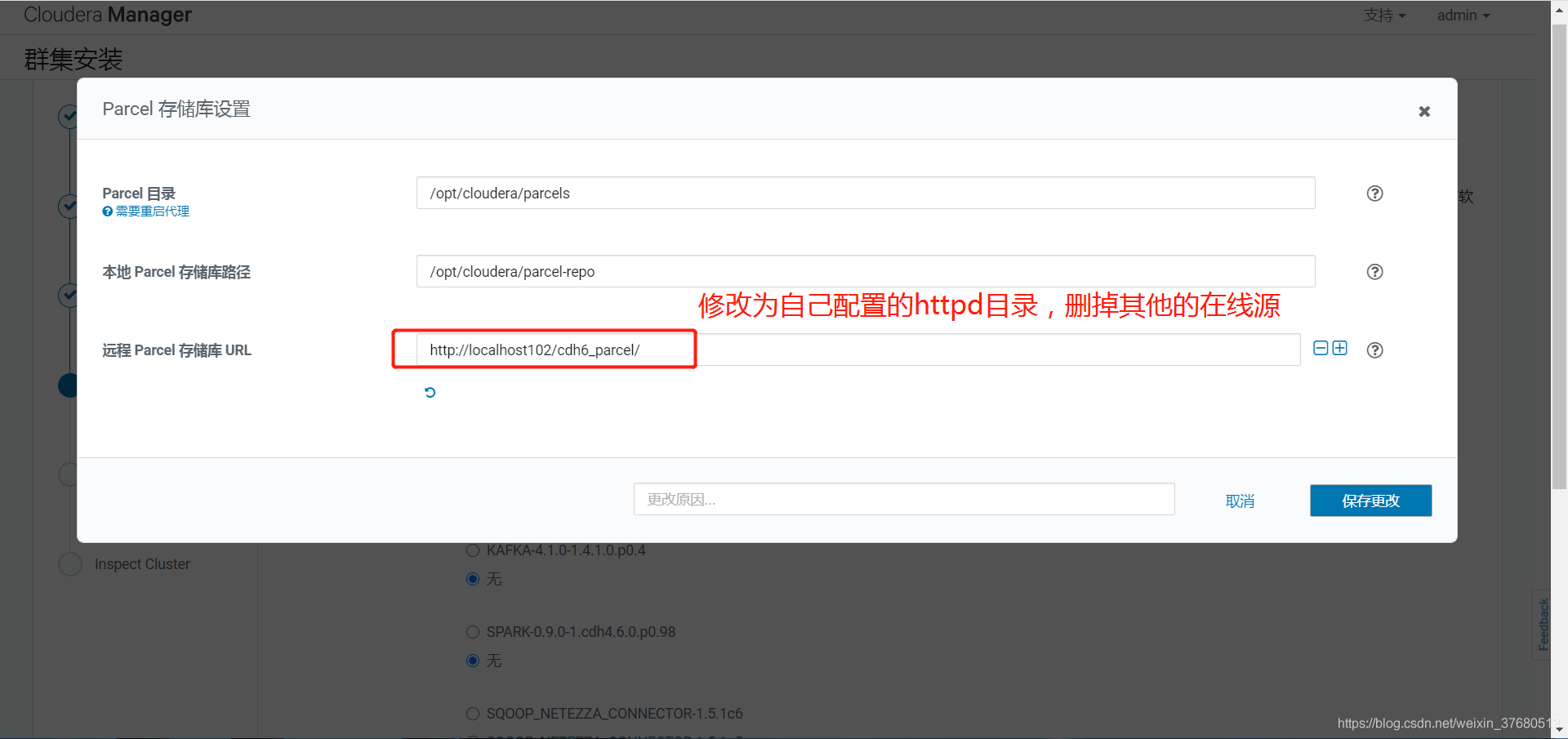
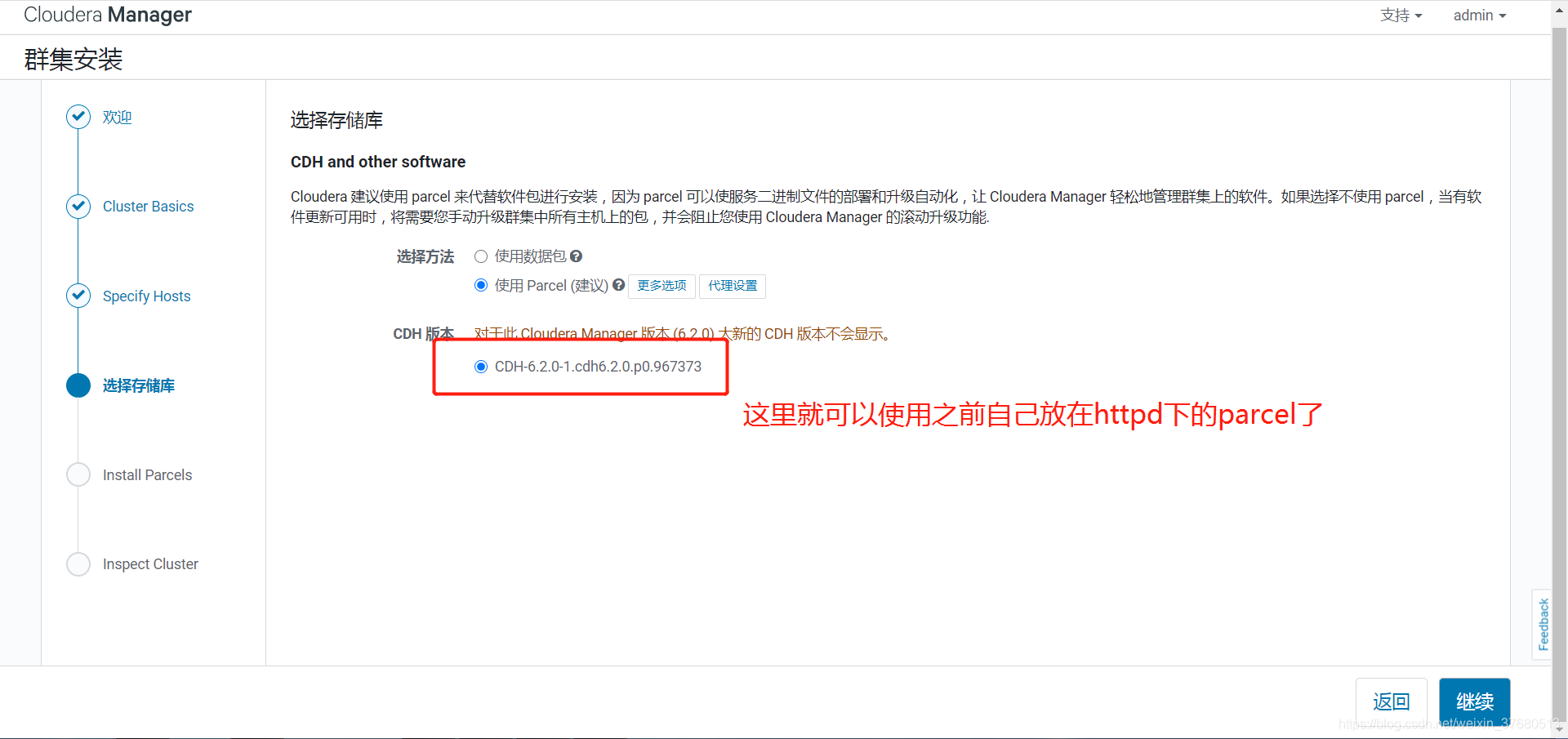
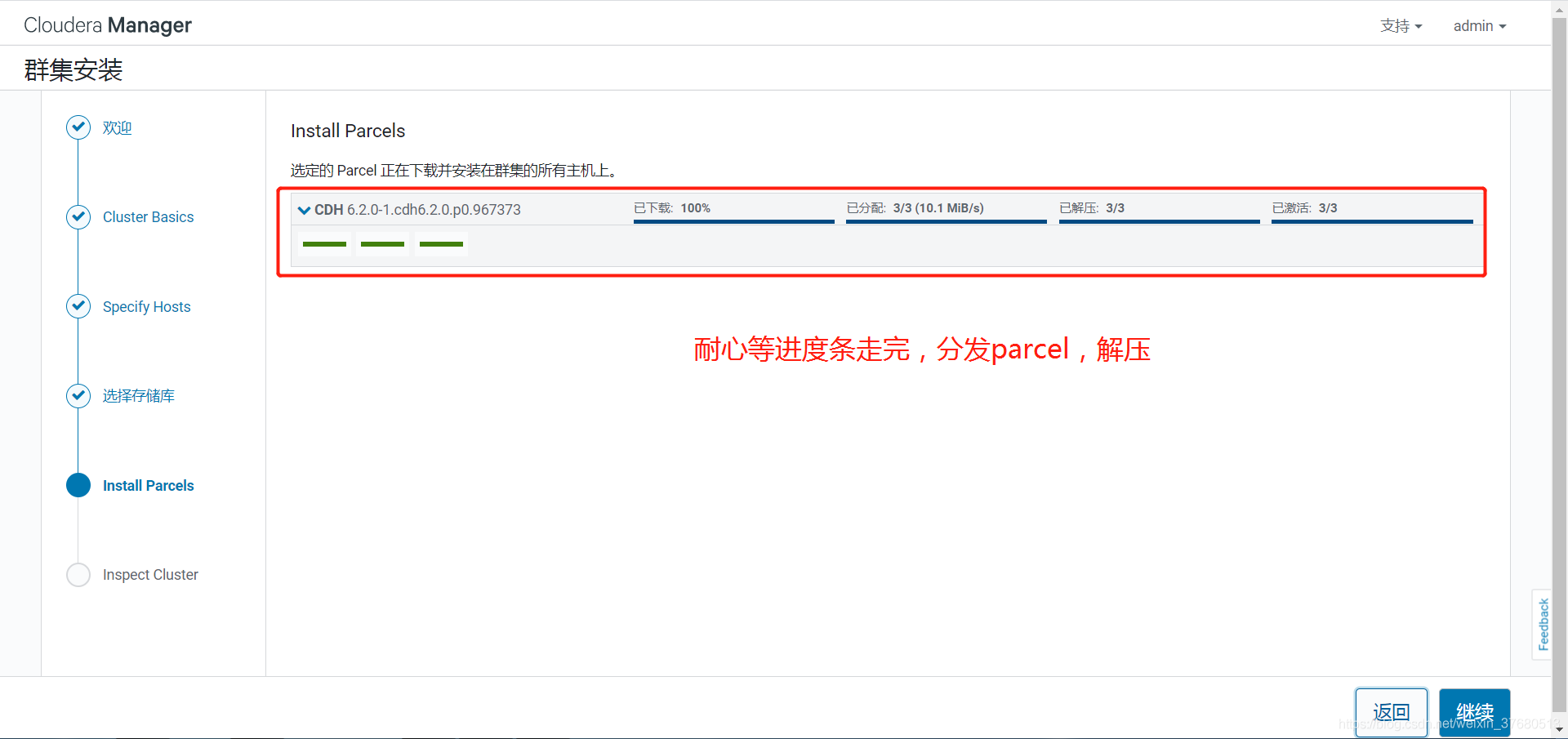
- 部署离线parcel源
## hadoop2安装httpd服务(前面已经安装),web查看http://hadoop2/
systemctl status httpd # 查看状态
systemctl start httpd # 启动
systemctl enable httpd.service #设置httpd服务开机自启
## 部署离线parcel源,将parcel相关的三个文件拷贝进去, .sha1将1去掉
## web查看http://hadoop2/cdh6_parcel
mkdir -p /var/www/html/cdh6_parcel
mv CDH-6.2.0-1.cdh6.2.0.p0.967373-el7.parcel /var/www/html/cdh6_parcel
mv CDH-6.2.0-1.cdh6.2.0.p0.967373-el7.parcel.sha /var/www/html/cdh6_parcel
mv manifest.json /var/www/html/cdh6_parcel
#如果没下载sha1,可以生成
sha1sum CDH-6.2.0-1.cdh6.2.0.p0.967373-el7.parcel | awk '{ print $1 }' > CDH-6.2.0-1.cdh6.2.0.p0.967373-el7.parcel.sha
- 启动server和agent
## 主节点hadoop1启动server
systemctl start cloudera-scm-server
# 查看日志,出现7180说明启动成功,,有错误解决错误
tail -F /var/log/cloudera-scm-server/cloudera-scm-server.log
# 使用hadoop1外网ip:7180可以进入web页面表示成功,接下来启动agent
## 从节点启动agent
systemctl start cloudera-scm-agent
## 停止
systemctl stop cloudera-scm-server
systemctl stop cloudera-scm-agent
systemctl disable cloudera-scm-server # 关闭开机启动
systemctl disable cloudera-scm-agent # 关闭开机启动
## 查看端口 7180
netstat -nltp
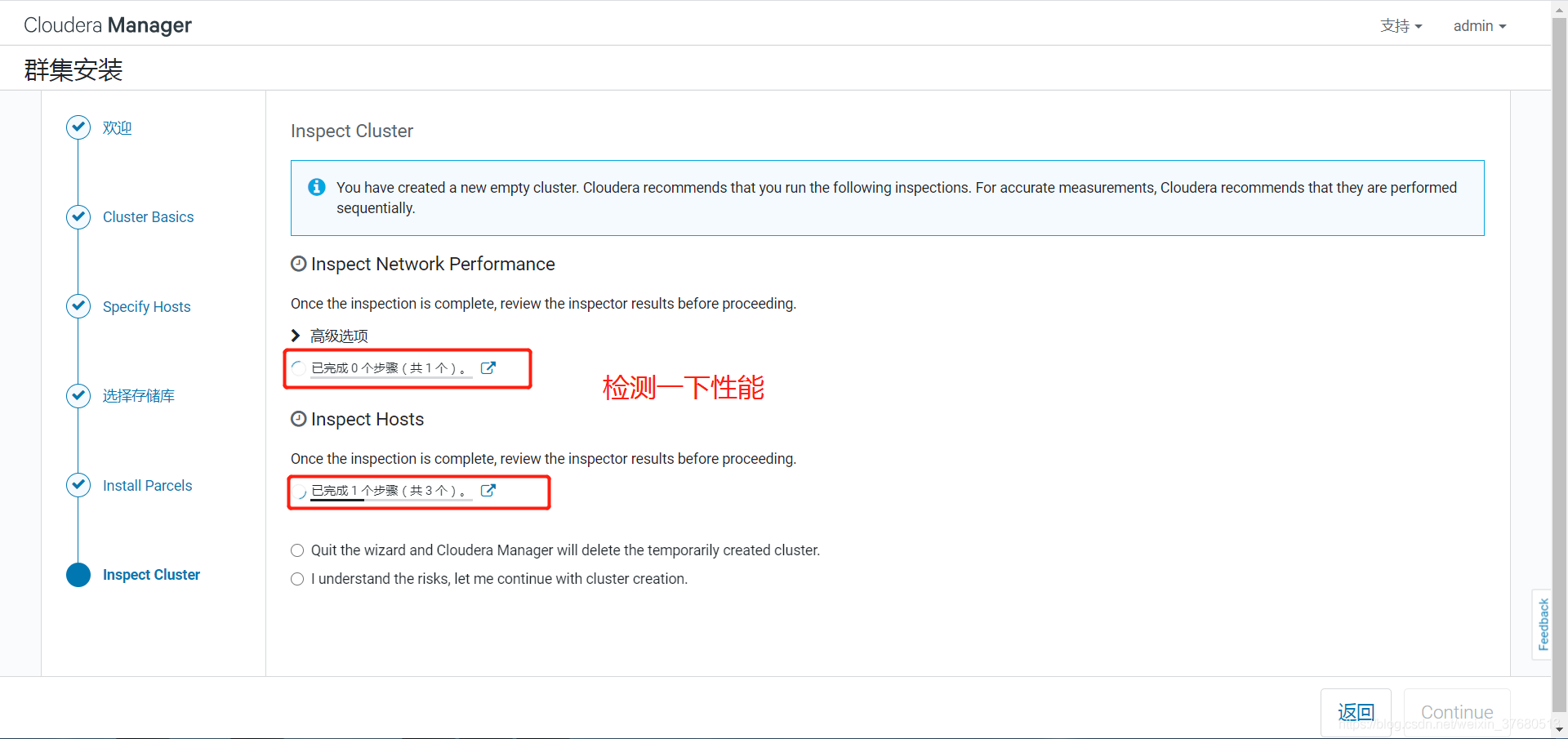
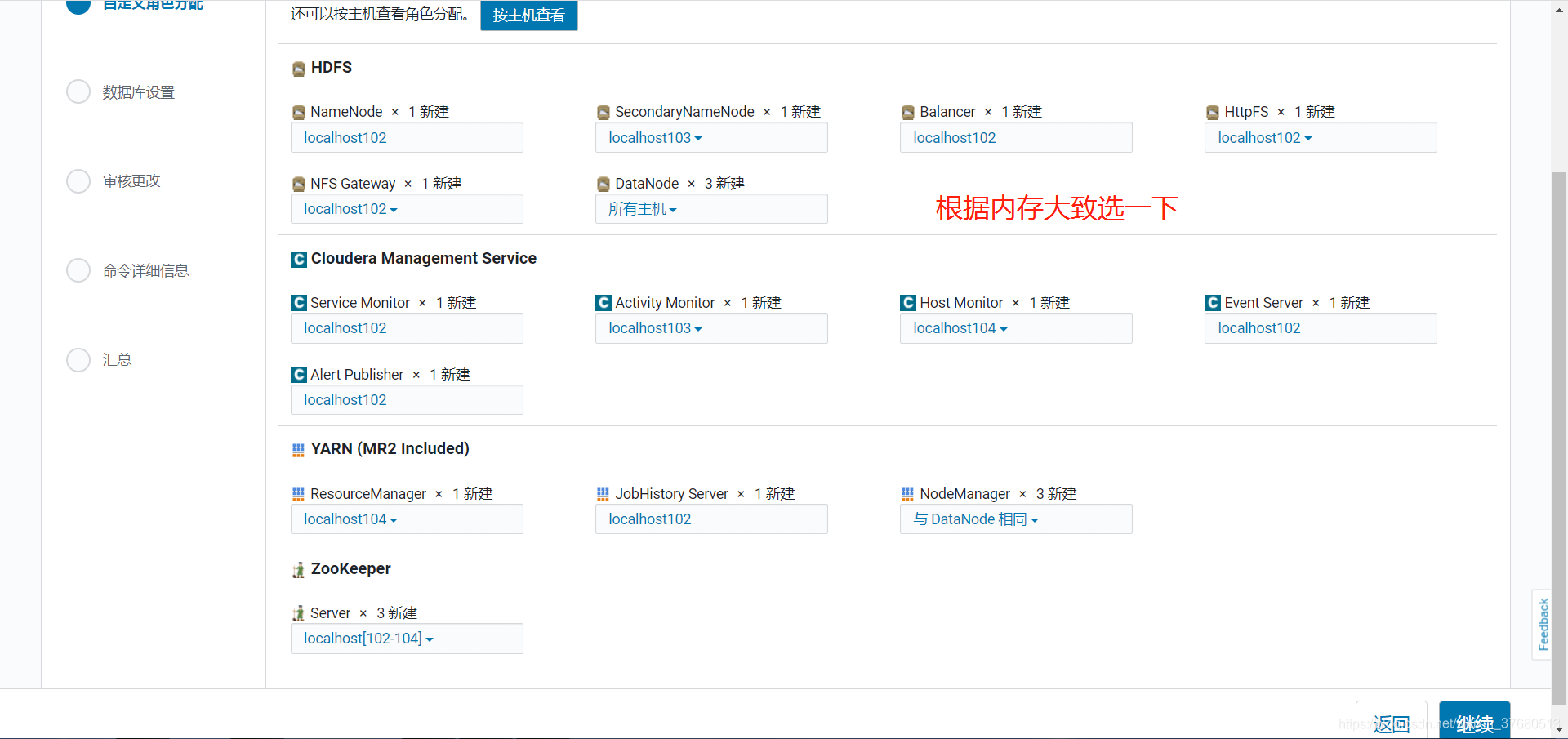
web界面操作,登录http://hadoop1外网ip:7180,默认用户名密码为admin
八成进不去,需要在腾讯云配置安全组,打开7180端口才能访问(默认没有打开7180)web 操作
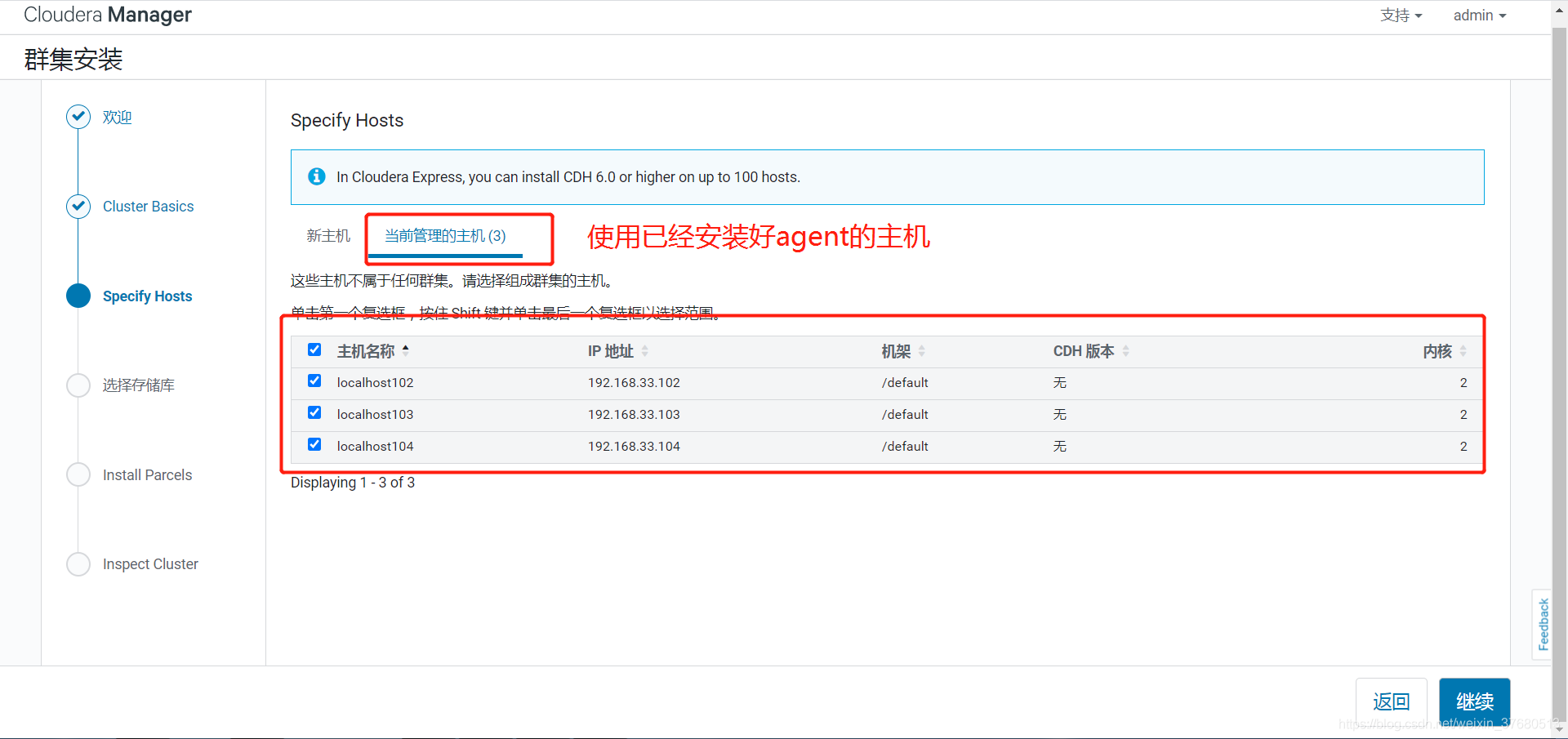

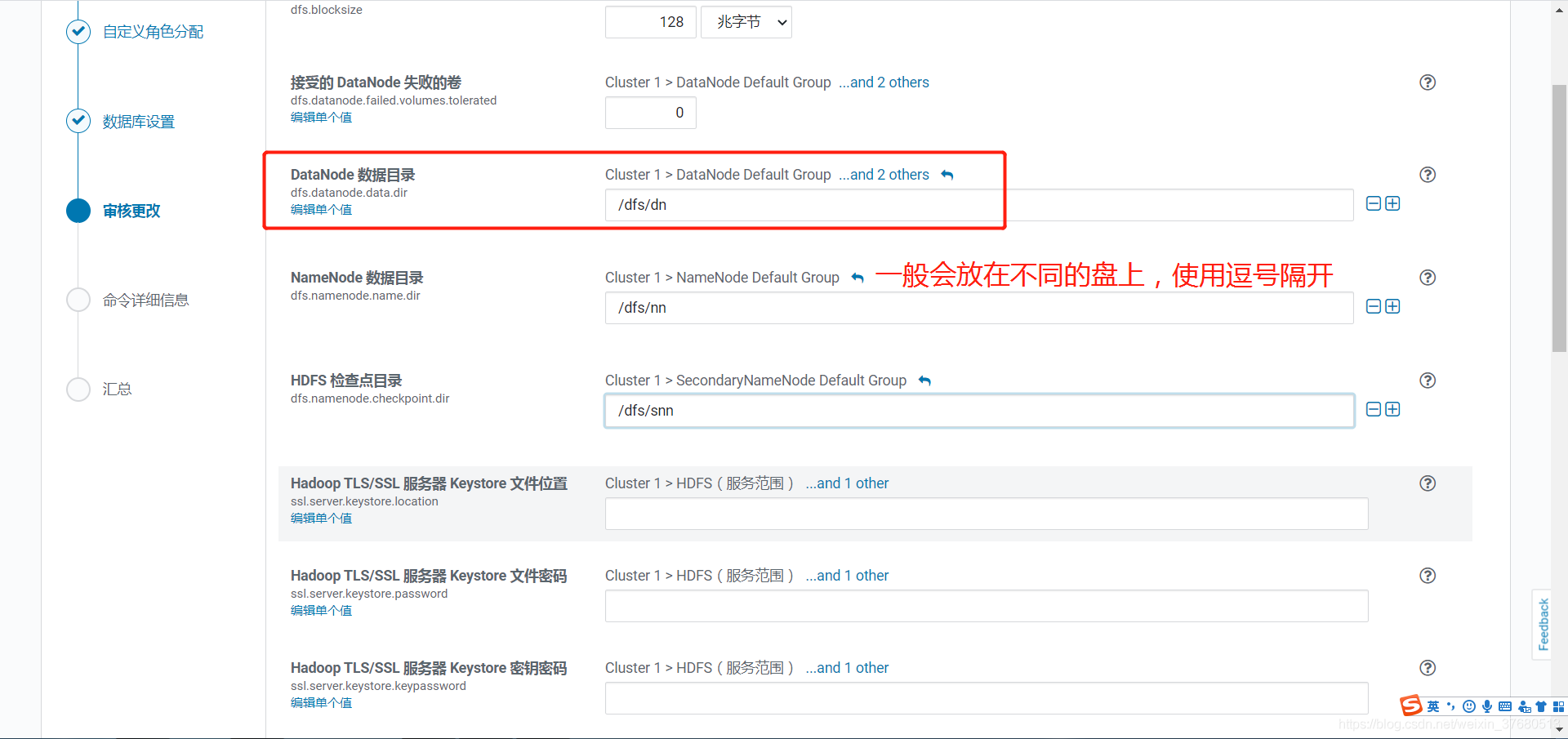
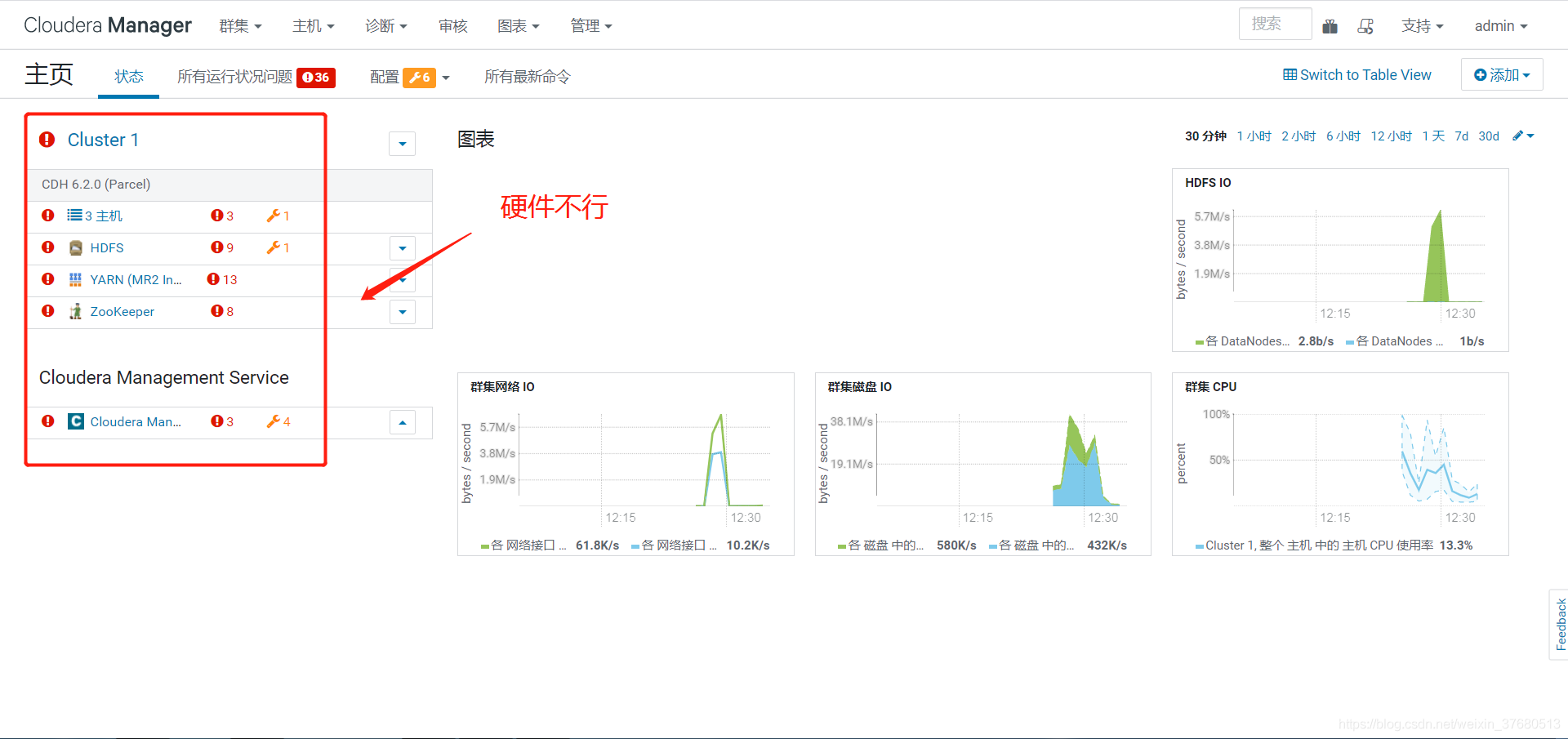
参考博文:
https://blog.csdn.net/weixin_37680513/article/details/111713387
https://zhuanlan.zhihu.com/p/254742441
CDH6.2.0 搭建大数据集群的更多相关文章
- 关于在真实物理机器上用cloudermanger或ambari搭建大数据集群注意事项总结、经验和感悟心得(图文详解)
写在前面的话 (1) 最近一段时间,因担任我团队实验室的大数据环境集群真实物理机器工作,至此,本人秉持负责.认真和细心的态度,先分别在虚拟机上模拟搭建ambari(基于CentOS6.5版本)和clo ...
- 基于Docker搭建大数据集群(七)Hbase部署
基于Docker搭建大数据集群(七)Hbase搭建 一.安装包准备 Hbase官网下载 微云下载 | 在 tar 目录下 二.版本兼容 三.角色分配 节点 Master Regionserver cl ...
- 基于Docker搭建大数据集群(一)Docker环境部署
本篇文章是基于Docker搭建大数据集群系列的开篇之作 主要内容 docker搭建 docker部署CentOS 容器免密钥通信 容器保存成镜像 docker镜像发布 环境 Linux 7.6 一.D ...
- Docker搭建大数据集群 Hadoop Spark HBase Hive Zookeeper Scala
Docker搭建大数据集群 给出一个完全分布式hadoop+spark集群搭建完整文档,从环境准备(包括机器名,ip映射步骤,ssh免密,Java等)开始,包括zookeeper,hadoop,hiv ...
- 基于Docker搭建大数据集群(六)Hive搭建
基于Docker搭建大数据集群(六)Hive搭建 前言 之前搭建的都是1.x版本,这次搭建的是hive3.1.2版本的..还是有一点细节不一样的 Hive现在解析引擎可以选择spark,我是用spar ...
- CDH搭建大数据集群(5.10.0)
纠结了好久,还是花钱了3个4核8G的阿里云主机,且行且珍惜,想必手动搭建过Hadoop集群的完全分布式.HBase的完全分布式的你(当然包括我,哈哈),一定会抱怨如此多的配置,而此时CDH正是解决我们 ...
- ClouderManger搭建大数据集群时ERROR 2003 (HY000): Can't connect to MySQL server on 'ubuntucmbigdata1' (111)的问题解决(图文详解)
问题详情 相关问题的场景,是在我下面的这篇博客里 Cloudera Manager安装之利用parcels方式(在线或离线)安装3或4节点集群(包含最新稳定版本或指定版本的安装)(添加服务)(Ubun ...
- 基于Docker搭建大数据集群(二)基础组件配置
主要内容 jdk环境搭建 scala环境搭建 zookeeper部署 mysql部署 前提 docker容器之间能免密钥登录 yum源更换为阿里源 安装包 微云分享 | tar包目录下 JDK 1.8 ...
- 基于Docker搭建大数据集群(三)Hadoop部署
主要内容 Hadoop安装 前提 zookeeper正常使用 JAVA_HOME环境变量 安装包 微云下载 | tar包目录下 Hadoop 2.7.7 角色划分 角色分配 NN DN SNN clu ...
随机推荐
- 华为AppLinking中统一链接的创建和使用
运营的同学近期在准备海外做一波线下投放,涉及到海外的Google Play,iOS设备的App Store,以及华为渠道的AppGallery. 其中运营希望我们能够将三个平台的下载整合到一个链接 ...
- UiPath选择器之动态选择器的介绍和使用
一.动态选择器的介绍 使用通配符, 能够替换字符串中的零个或多个字符的符号.这些在处理选择器中的动态更改的属性时非常有用. 二.动态选择器在UiPath中的使用 1.在设计库中新建一个Sequence ...
- bat-安装程序-切换路径的问题(小坑)
当批处理以管理员身份运行时,默认的cmd路径是 C:\Windows\system32 如果在批处理所在目录下存放了一些 安装程序,使用bat安装程序时,bat中去执行时 不会去当前目录去找 exe文 ...
- UML之顺序图(时序图)
1 顺序图 1.1 顺序图的概念 顺序图(sequence diagram): 用来描述为了完成确定事务,对象之间按照时间消息交互的顺序关系. 1.2 顺序图样式和元素 (1) 对象及命名 (2) 生 ...
- C++ 练气期之指针所指何处
1. 指针 指针是一种C++数据类型,用来描述内存地址. 什么是内存地址? 内存中的每一个存储单元格都有自己的地址,地址是使用二进制进行编码.地址从形态上看是一个整型数据类型.但是,它的数据含义并不表 ...
- 『现学现忘』Git后悔药 — 29、版本回退git reset --mixed命令说明
git reset --mixed commit-id命令:回退到指定版本.(mixed:混合的,即:中等回退.) 该命令不仅修改了分支中HEAD指针的位置,还将暂存区中数据也回退到了指定版本. 但是 ...
- Tomcat 安装及配置,创建动态的web工程
Tomcat可以认为是对Servlet标准的实现,是一个具体的Servlet容器. 1) 将Tomcat的安装包解压到磁盘的任意位(非中文无空格) 2) Tomcat服务的 ...
- 漏洞扫描工具nessus、rapid7 insightvm、openvas安装&简单使用
Rapid7-insightvm 申请试用 申请地址 邮件地址不能用常用邮件,要使用自己域名的邮件,可以使用这个临时邮箱 手机号随便输入,10位以上 提交后会跳转下载页面 安装 安装:./Rapid7 ...
- nexus org.sonatype.nexus.bootstrap.jetty.JettyServer - Start failed
INFO [jetty-main-1] *SYSTEM org.sonatype.nexus.bootstrap.jetty.JettyServer - Runningjvm 1 | 2020-04- ...
- kube-scheduler的调度上下文
前一章节了解到了kube-scheduler中的概念,该章节则对调度上下文的源码进行分析 Scheduler Scheduler 是整个 kube-scheduler 的一个 structure,提供 ...