详解神经网络基础部件BN层
摘要:在深度神经网络训练的过程中,由于网络中参数变化而引起网络中间层数据分布发生变化的这一过程被称为内部协变量偏移(Internal Covariate Shift),而 BN 可以解决这个问题。
本文分享自华为云社区《神经网络基础部件-BN层详解》,作者:嵌入式视觉 。
一,数学基础
1.1,概率密度函数
随机变量(random variable)是可以随机地取不同值的变量。随机变量可以是离散的或者连续的。简单起见,本文用大写字母 XX 表示随机变量,小写字母 xx 表示随机变量能够取到的值。例如,x1x1 和 x2x2 都是随机变量 XX 可能的取值。随机变量必须伴随着一个概率分布来指定每个状态的可能性。
概率分布(probability distribution)用来描述随机变量或一簇随机变量在每一个可能取到的状态的可能性大小。我们描述概率分布的方式取决于随机变量是离散的还是连续的。
当我们研究的对象是连续型随机变量时,我们用概率密度函数(probability density function, PDF)而不是概率质量函数来描述它的概率分布。
更多内容请阅读《花书》第三章-概率与信息论,或者我的文章-深度学习数学基础-概率与信息论。
1.2,正态分布
当我们不知道数据真实分布时使用正态分布的原因之一是,正态分布拥有最大的熵,我们通过这个假设来施加尽可能少的结构。
实数上最常用的分布就是正态分布(normal distribution),也称为高斯分布 (Gaussian distribution)。
如果随机变量 XX ,服从位置参数为 μμ、尺度参数为 σσ 的概率分布,且其概率密度函数为:
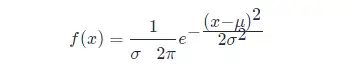
则这个随机变量就称为正态随机变量,正态随机变量服从的概率分布就称为正态分布,记作:
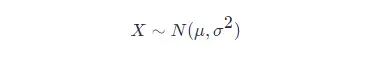
如果位置参数 μ=0μ=0,尺度参数 σ=1σ=1 时,则称为标准正态分布,记作:
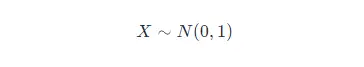
此时,概率密度函数公式简化为:
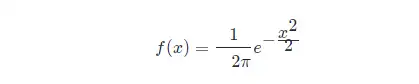
正太分布的数学期望值或期望值 μμ 等于位置参数,决定了分布的位置;其方差 σ2σ2 的开平方或标准差 σσ 等于尺度参数,决定了分布的幅度。正太分布的概率密度函数曲线呈钟形,常称之为钟形曲线,如下图所示:
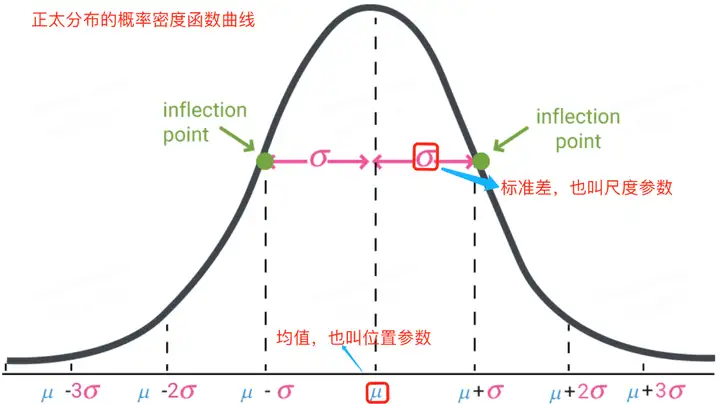
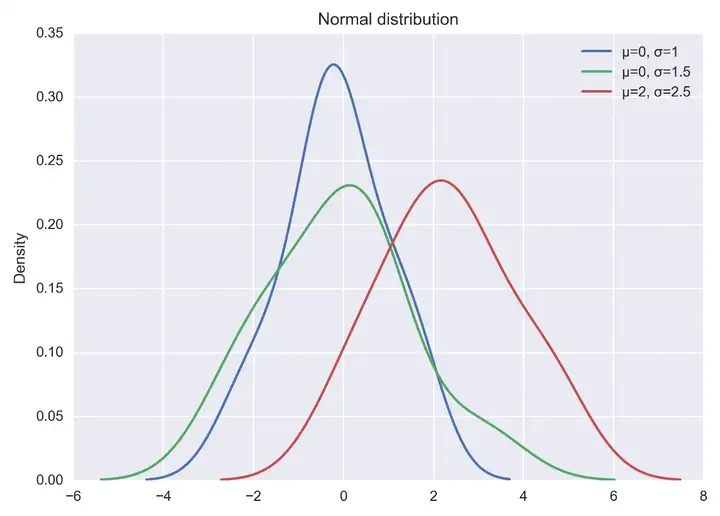
可视化正态分布,可直接通过 np.random.normal 函数生成指定均值和标准差的正态分布随机数,然后基于 matplotlib + seaborn 库 kdeplot函数绘制概率密度曲线。示例代码如下所示:
import seaborn as sns
x1 = np.random.normal(0, 1, 100)
x2 = np.random.normal(0, 1.5, 100)
x3 = np.random.normal(2, 1.5, 100)
plt.figure(dpi = 200)
sns.kdeplot(x1, label="μ=0, σ=1")
sns.kdeplot(x2, label="μ=0, σ=1.5")
sns.kdeplot(x3, label="μ=2, σ=2.5")
#显示图例
plt.legend()
#添加标题
plt.title("Normal distribution")
plt.show()
以上代码直接运行后,输出结果如下图:
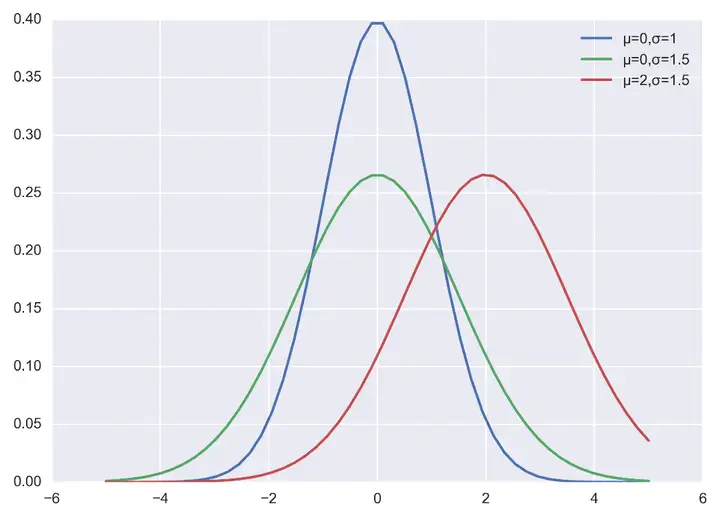
当然也可以自己实现正太分布的概率密度函数,代码和程序输出结果如下:
import numpy as np
import matplotlib.pyplot as plt
plt.figure(dpi = 200)
plt.style.use('seaborn-darkgrid') # 主题设置
def nd_func(x, sigma, mu):
"""自定义实现正太分布的概率密度函数
"""
a = - (x-mu)**2 / (2*sigma*sigma)
f = np.exp(a) / (sigma * np.sqrt(2*np.pi))
return f
if __name__ == '__main__':
x = np.linspace(-5, 5)
f = nd_fun(x, 1, 0)
p1, = plt.plot(x, f)
f = nd_fun(x, 1.5, 0)
p2, = plt.plot(x, f)
f = nd_fun(x, 1.5, 2)
p3, = plt.plot(x, f)
plt.legend([p1 ,p2, p3], ["μ=0,σ=1", "μ=0,σ=1.5", "μ=2,σ=1.5"])
plt.show()
二,背景
训练深度神经网络的复杂性在于,因为前面的层的参数会发生变化导致每层输入的分布在训练过程中会发生变化。这又导致模型需要需要较低的学习率和非常谨慎的参数初始化策略,从而减慢了训练速度,并且具有饱和非线性的模型训练起来也非常困难。
网络层输入数据分布发生变化的这种现象称为内部协变量转移,BN 就是来解决这个问题。
2.1,如何理解 Internal Covariate Shift
在深度神经网络训练的过程中,由于网络中参数变化而引起网络中间层数据分布发生变化的这一过程被称在论文中称之为内部协变量偏移(Internal Covariate Shift)。
那么,为什么网络中间层数据分布会发生变化呢?
在深度神经网络中,我们可以将每一层视为对输入的信号做了一次变换(暂时不考虑激活,因为激活函数不会改变输入数据的分布):
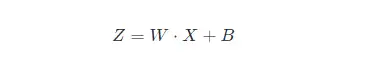
其中 WW 和 BB 是模型学习的参数,这个公式涵盖了全连接层和卷积层。
随着 SGD 算法更新参数,和网络的每一层的输入数据经过公式5的运算后,其 ZZ 的分布一直在变化,因此网络的每一层都需要不断适应新的分布,这一过程就被叫做 Internal Covariate Shift。
而深度神经网络训练的复杂性在于每层的输入受到前面所有层的参数的影响—因此当网络变得更深时,网络参数的微小变化就会被放大。
2.2,Internal Covariate Shift 带来的问题
- 网络层需要不断适应新的分布,导致网络学习速度的降低。
- 网络层输入数据容易陷入到非线性的饱和状态并减慢网络收敛,这个影响随着网络深度的增加而放大。
随着网络层的加深,后面网络输入 xx 越来越大,而如果我们又采用 Sigmoid 型激活函数,那么每层的输入很容易移动到非线性饱和区域,此时梯度会变得很小甚至接近于 00,导致参数的更新速度就会减慢,进而又会放慢网络的收敛速度。
饱和问题和由此产生的梯度消失通常通过使用修正线性单元激活(ReLU(x)=max(x,0)ReLU(x)=max(x,0)),更好的参数初始化方法和小的学习率来解决。然而,如果我们能保证非线性输入的分布在网络训练时保持更稳定,那么优化器将不太可能陷入饱和状态,进而训练也将加速。
2.3,减少 Internal Covariate Shift 的一些尝试
- 白化(Whitening): 即输入线性变换为具有零均值和单位方差,并去相关。
白化过程由于改变了网络每一层的分布,因而改变了网络层中本身数据的表达能力。底层网络学习到的参数信息会被白化操作丢失掉,而且白化计算成本也高。 - 标准化(normalization)
Normalization 操作虽然缓解了 ICS 问题,让每一层网络的输入数据分布都变得稳定,但却导致了数据表达能力的缺失。
三,批量归一化(BN)
3.1,BN 的前向计算
论文中给出的 Batch Normalizing Transform 算法计算过程如下图所示。其中输入是一个考虑一个大小为 mm 的小批量数据 BB。

论文中的公式不太清晰,下面我给出更为清晰的 Batch Normalizing Transform 算法计算过程。
设 mm 表示 batch_size 的大小,nn 表示 features 数量,即样本特征值数量。在训练过程中,针对每一个 batch 数据,BN 过程进行的操作是,将这组数据 normalization,之后对其进行线性变换,具体算法步骤如下:
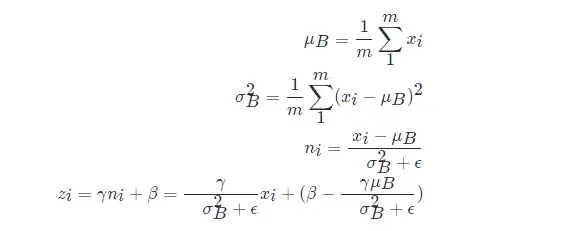
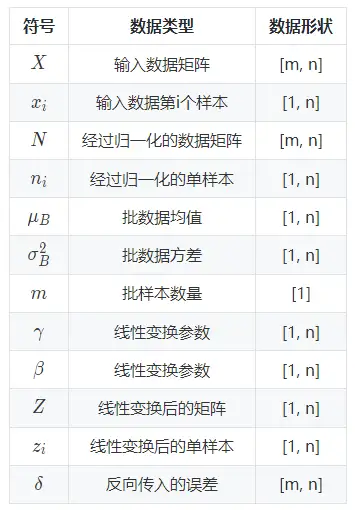
以上公式乘法都为元素乘,即 element wise 的乘法。其中,参数 γ,βγ,β 是训练出来的, ϵϵ 是为零防止 σB2σB2 为 00 ,加的一个很小的数值,通常为1e-5。公式各个符号解释如下:
其中:
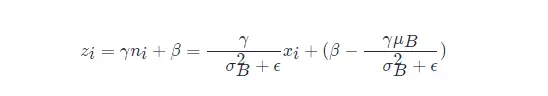
可以看出 BN 本质上是做线性变换。
3.2,BN 层如何工作
在论文中,训练一个带 BN 层的网络, BN 算法步骤如下图所示:

在训练期间,我们一次向网络提供一小批数据。在前向传播过程中,网络的每一层都处理该小批量数据。 BN 网络层按如下方式执行前向传播计算:
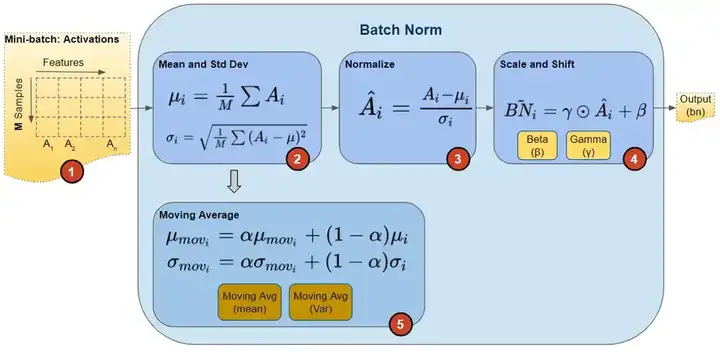
图片来源这里。
注意,图中计算均值与方差的无偏估计方法是吴恩达在 Coursera 上的 Deep Learning 课程上提出的方法:对 train 阶段每个 batch 计算的 mean/variance 采用指数加权平均来得到 test 阶段 mean/variance 的估计。
在训练期间,它只是计算此 EMA,但不对其执行任何操作。在训练结束时,它只是将该值保存为层状态的一部分,以供在推理阶段使用。
如下图可以展示BN 层的前向传播计算过程数据的 shape ,红色框出来的单个样本都指代单个矩阵,即运算都是在单个矩阵运算中计算的。
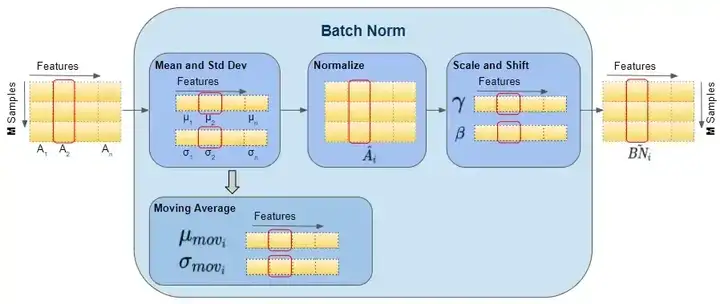
图片来源 这里。
BN 的反向传播过程中,会更新 BN 层中的所有 ββ 和 γγ 参数。
3.3,训练和推理式的 BN 层
批量归一化(batch normalization)的“批量”两个字,表示在模型的迭代训练过程中,BN 首先计算小批量( mini-batch,如 32)的均值和方差。但是,在推理过程中,我们只有一个样本,而不是一个小批量。在这种情况下,我们该如何获得均值和方差呢?
第一种方法是,使用的均值和方差数据是在训练过程中样本值的平均,即:
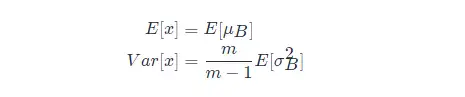
这种做法会把所有训练批次的 μμ 和 σσ 都保存下来,然后在最后训练完成时(或做测试时)做下平均。
第二种方法是使用类似动量的方法,训练时,加权平均每个批次的值,权值 αα 可以为0.9:
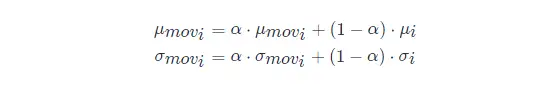
推理或测试时,直接使用模型文件中保存的 μmoviμmovi 和 σmoviσmovi 的值即可。
3.4,实验
BN 在 ImageNet 分类数据集上实验结果是 SOTA 的,如下表所示:
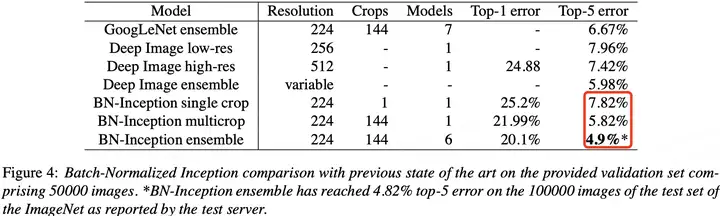
3.5,BN 层的优点
- BN 使得网络中每层输入数据的分布相对稳定,加速模型训练和收敛速度。
- 批标准化可以提高学习率。在传统的深度网络中,学习率过高可能会导致梯度爆炸或梯度消失,以及陷入差的局部最小值。批标准化有助于解决这些问题。通过标准化整个网络的激活值,它可以防止层参数的微小变化随着数据在深度网络中的传播而放大。例如,这使 sigmoid 非线性更容易保持在它们的非饱和状态,这对训练深度 sigmoid 网络至关重要,但在传统上很难实现。
- BN 允许网络使用饱和非线性激活函数(如 sigmoid,tanh 等)进行训练,其能缓解梯度消失问题。
- 不需要 dropout 和 LRN(Local Response Normalization)层来实现正则化。批标准化提供了类似丢弃的正则化收益,因为通过实验可以观察到训练样本的激活受到同一小批量样例随机选择的影响。
- 减少对参数初始化方法的依赖。
参考资料
- 维基百科-正态分布
- Batch Norm Explained Visually — How it works, and why neural networks need it
- 15.5 批量归一化的原理
- Batch Normalization原理与实战
详解神经网络基础部件BN层的更多相关文章
- 神经网络基础部件-BN层详解
一,数学基础 1.1,概率密度函数 1.2,正态分布 二,背景 2.1,如何理解 Internal Covariate Shift 2.2,Internal Covariate Shift 带来的问题 ...
- Andrej Karpathy | 详解神经网络和反向传播(基于 micrograd)
只要你懂 Python,大概记得高中学过的求导知识,看完这个视频你还不理解反向传播和神经网络核心要点的话,那我就吃鞋:D Andrej Karpathy,前特斯拉 AI 高级总监.曾设计并担任斯坦福深 ...
- TCP/IP详解与OSI七层模型
TCP/IP协议 包含了一系列构成互联网基础的网络协议,是Internet的核心协议.基于TCP/IP的参考模型将协议分成四个层次,它们分别是链路层.网络层.传输层和应用层.下图表示TCP/IP模型与 ...
- tcp/ip详解 卷1 -- 链路层
以太网 以太网指数字设备公司,英特尔公司,Xeror公司在 1982年联合公布的一个标准, 是当前 TCP/IP 采用的主要局域网技术. 以太网采用 CSMA/CD 的媒体接入方法, 即 带冲突检测的 ...
- Mybatis详解系列(一)--持久层框架解决了什么及如何使用Mybatis
简介 Mybatis 是一个持久层框架,它对 JDBC 进行了高级封装,使我们的代码中不会出现任何的 JDBC 代码,另外,它还通过 xml 或注解的方式将 sql 从 DAO/Repository ...
- DeepLearning tutorial(3)MLP多层感知机原理简介+代码详解
本文介绍多层感知机算法,特别是详细解读其代码实现,基于python theano,代码来自:Multilayer Perceptron,如果你想详细了解多层感知机算法,可以参考:UFLDL教程,或者参 ...
- 理论经典:TCP协议的3次握手与4次挥手过程详解
1.前言 尽管TCP和UDP都使用相同的网络层(IP),TCP却向应用层提供与UDP完全不同的服务.TCP提供一种面向连接的.可靠的字节流服务. 面向连接意味着两个使用TCP的应用(通常是一个客户和一 ...
- TCP、UDP详解与抓包工具使用
参考:https://www.cnblogs.com/HPAHPA/p/7737641.html TCP.UDP详解 1.传输层存在的必要性 由于网络层的分组传输是不可靠的,无法了解数据到达终点的时间 ...
- Mybatis源码详解系列(四)--你不知道的Mybatis用法和细节
简介 这是 Mybatis 系列博客的第四篇,我本来打算详细讲解 mybatis 的配置.映射器.动态 sql 等,但Mybatis官方中文文档对这部分内容的介绍已经足够详细了,有需要的可以直接参考. ...
- Java源码详解系列(十)--全面分析mybatis的使用、源码和代码生成器(总计5篇博客)
简介 Mybatis 是一个持久层框架,它对 JDBC 进行了高级封装,使我们的代码中不会出现任何的 JDBC 代码,另外,它还通过 xml 或注解的方式将 sql 从 DAO/Repository ...
随机推荐
- nvm下升级npm版本
1 3445 error path C:\Users\xxx\AppData\Roaming\nvm\v12.18.3\npm.cmd 2 3446 error Refusing to delete ...
- Day36:List详解
List 1.1 概述 List为Collection的子接口,代表的一组任意对象,有序,有下标.元素可以重复. 1.2 方法 方法名 说明 void add(int index,Object o) ...
- webShell攻击及防御
最近公司项目也是经常被同行攻击,经过排查,基本定位都是挂马脚本导致,所以针对webShell攻击做一下记录. 首先简单说下 什么是webShell? 利用文件上传,上传了非法可以执行代码到服务器,然后 ...
- .Net执行SQL/存储过程之易用轻量工具
支持.Net/.Net Core/.Net Framework,可以部署在Docker, Windows, Linux, Mac. 由于该工具近来被广东省数个公司2B项目采用,且表现稳定,得到良好验证 ...
- 简单体验一个高性能,简单,轻量的ORM库- Dapper (无依赖其它库,非常方便高效)
步骤1)引入该ORM库. 使用Nuget搜索"Dapper"安装或者直接从github上下载源码 (https://github.com/StackExchange/Dapper ...
- C#开发的磁吸屏幕类库 - 开源研究系列文章
上次写了一个关于线程池的博文,里面讲到了关于磁吸屏幕的类库,今天就把这个类库进行下讲解. 一. 类库目录: 类库的目录见下图,主要定义了Win32的一些API,以及一些API使用到的常量和结 ...
- [R语言] ggplot2入门笔记4—前50个ggplot2可视化效果
文章目录 通用教程简介(Introduction To ggplot2) 4 ggplot2入门笔记4-前50个ggplot2可视化效果 1 相关性(Correlation) 1.1 散点图(Scat ...
- HBase详解(02) - HBase-2.0.5安装
HBase详解(02) - HBase-2.0.5安装 HBase安装环境准备 Zookeeper安装 Zookeeper安装参考<Zookeeper详解(02) - zookeeper安装部署 ...
- 基于docker容器的MySQL主从设置及efcore读写分离
1.基于docker部署MySQL,设置主从 本操作基于已经拉取的镜像(docker pull mysql) 创建一主一从两个数据库容器 docker run -d -p 3307:3306 -e M ...
- 可持久化并查集学习笔记 | 题解P3402 可持久化并查集
简要题意 你需要维护一个并查集,支持版本回退,查连通性,合并两个点. 特别的,没进行一次操作都要新建一个版本. 前置知识 可持久化数组,如果您不会,出门左转 [模板]可持久化线段树 1(可持久化数组) ...