实践1使用XGB实现酒店信息消歧
XGB算法是决策树衍生出来的一种算法
场景:酒店的业务人员希望我们能够提供一个算法服务去为酒店信息做一个自动化的匹配,以通过算法的手段,找到那些确定相同的酒店和确定不同的酒店
以下代码为部分
理解业务
项目背景
当用户在马蜂窝打开一家选中的酒店时,不同供应商提供的预订信息会形成一个聚合列表准确地展示给用户。这样做首先避免同样的信息多次展示给用户影响体验,更重要的是帮助用户进行全网酒店实时比价,快速找到性价比最高的供应商,完成消费决策。
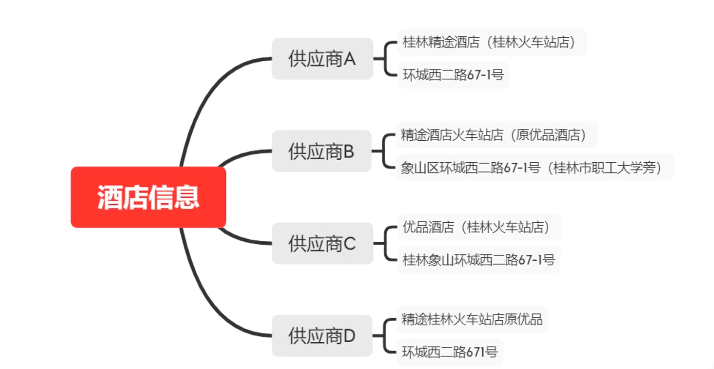
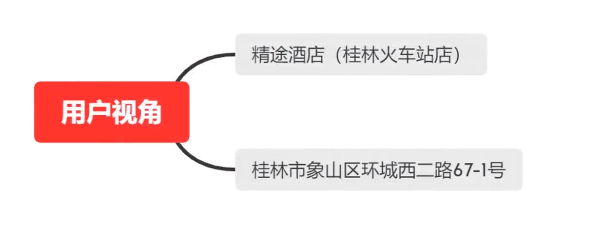
问题: 数据属性不同(比如酒店名有的是中文,有的英文,有的中英)、数据形态不同(比如有的是日语、韩语)、
数据量大,全部对比不现实、
消歧错误带来的风险
算法解决方案:
1.提供一个算法服务以计算两条数据是否属于同一家酒店
2.目标设定为提升运营效率,通过算法与运营人员的结合实现业务目标
3.计划先对中文的内容进行处理,而对其他语言暂时不做处理
准备数据与模型训练
#过滤掉最后面的英文字符,并进行数字转换(转换成阿拉伯数字),大小写转换(转成小写)
def ch2num(self,s)
s = list(s)
num = ['零','一','二','三','四','五','六','七','八','九']
ch_num = ['零','壹','贰','叁','肆','伍','陆','柒','捌','玖']
i,last,flag = len(s)-1,len(s),True
while i > -1:
if s[i] >= u'\u4e00' and s[i] <= u'\u9fa5' and flag:
last = i+1
flag = False
else:
if s[i] in num:
s[i] = num.index(s[i])
elif s[i] in ch_num:
s[i] = ch_num.index(s[i])
i -= 1
return ".join(str(it) for it in s[:last]).lower()
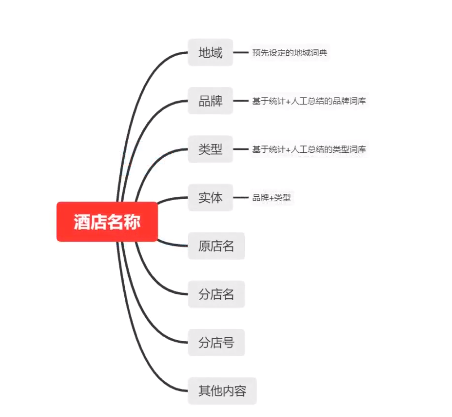
名称分词

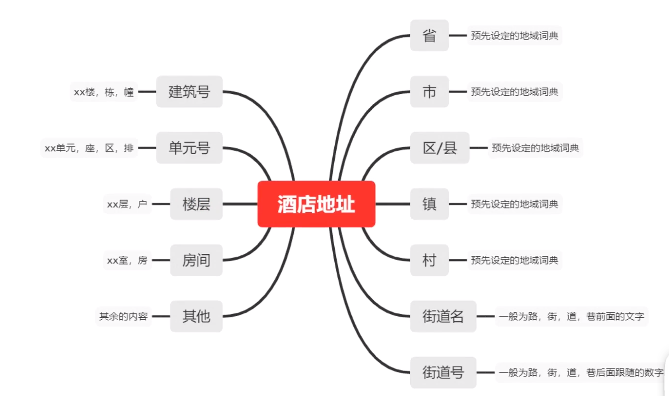
地址分词
#三种距离计算方法
#计算Levenshtein距离
def levenshtein_vec(self,item1,item2):
vec = []
dist = Levenshtein()
for i in range(len(item1)):
vec.append(dist.distance(item1[i],item2[i]))
return vec #jarowinkler距离
def jarowinkler_vec(self,item1,item2):
vec = []
dist = jaroWinkler()
for i in range(len(item1)):
vec.append(dist.similarity(item1[i],item2[i]))
return vec #qgram距离
def qgram_vec(self,item1,item2):
vec = []
dist = QGram(len(item1) if len(item1) <= len(item2) else len(item2))
for i in range(len(item1)):
vec.append(dist.distance(item1[i],item2[i]))
return vec #经纬度距离相对特殊,使用haversine距离 专门处理经纬度与物理计算的
def haversine(self,item1,item2): #[经度1,纬度1],[经度2,纬度2](十进制度数)
'''
Calculate the great circle distance between two points on the earth(specified in decimal degree)
'''
#将十进制度数转化为弧度
lon1,lat1,lon2,lat2 = map(radians,[float(item1[0]),float(item1[1]),float(item2[0]),float(item2[1])]) #haveeersin公式
dlon = lon2 -lon1
dlat = lat2 - lat1
a = sin(dlat/2)**2 + cos(lat1)*cos(lat2)*sin(dlon/2)**2
c = 2asin(sqrt(a))
r = 6371 #地球半径,单位为公里
return [c*r*1000]
模型训练与评估
import xgboost as xgb
model = xgb.XGBClassifier(nthread=-1,max_depth=6,
n_estimators=30,learning_rate=0.01,colsample_bytree=.9,
gamma=1,reg_alpha=4,objective='binary:logistic',eta=0.2,silent=1,subsample=0.8).fit(X_train,Y_train)
fileObject = open('xgb_hotelmatch.pkl','wb') #保存模型
pick.dump(model,fileObject,protocol=4)
fileObject.close() #模型预测与混淆矩阵获取
prediction = model.predict(X_test)
cm = confusion_matrix(Y_test,prediction)
根据给出的“是”和“否”的概率值区间来判断是否足够置信
1.对于置信结果直接进入到合并或新增环节
2.对于不那么置信,仍然进入到人工审核环节进行二次校验
实践1使用XGB实现酒店信息消歧的更多相关文章
- 利用 pyspider 框架抓取猫途鹰酒店信息
利用框架 pyspider 能实现快速抓取网页信息,而且代码简洁,抓取速度也不错. 环境:macOS:Python 版本:Python3. 1.首先,安装 pyspider 框架,使用pip3一键安装 ...
- Python 爬取美团酒店信息
事由:近期和朋友聊天,聊到黄山酒店事情,需要了解一下黄山的酒店情况,然后就想着用python 爬一些数据出来,做个参考 主要思路:通过查找,基本思路清晰,目标明确,仅仅爬取美团莫一地区的酒店信息,不过 ...
- python爬取酒店信息练习
爬取酒店信息,首先知道要用到那些库.本次使用request库区获取网页,使用bs4来解析网页,使用selenium来进行模拟浏览. 本次要爬取的美团网的蚌埠酒店信息及其评价.爬取的网址为“http:/ ...
- 使用requests、BeautifulSoup、线程池爬取艺龙酒店信息并保存到Excel中
import requests import time, random, csv from fake_useragent import UserAgent from bs4 import Beauti ...
- C++模板”>>”编译问题与词法消歧设计
在编译理论中,通常将编译过程抽象为5个主要阶段:词法分析(Lexical Analysis),语法分析(Parsing),语义分析(Semantic Analysis),优化(Optimization ...
- 学习笔记CB008:词义消歧、有监督、无监督、语义角色标注、信息检索、TF-IDF、隐含语义索引模型
词义消歧,句子.篇章语义理解基础,必须解决.语言都有大量多种含义词汇.词义消歧,可通过机器学习方法解决.词义消歧有监督机器学习分类算法,判断词义所属分类.词义消歧无监督机器学习聚类算法,把词义聚成多类 ...
- 基于TF-IDF值的汉语语义消歧算法
RT,学校课题需要233,没了 话说,窝直接做个链接的集合好了,方便以后查找 特征值提取之 -- TF-IDF值的简单介绍 汉语语义消歧之 -- 句子相似度 汉语语义消歧之 -- 词义消歧简介 c++ ...
- python网络爬虫(12)去哪网酒店信息爬取
目的意义 爬取某地的酒店价格信息,示例使用selenium在Firefox中的使用. 来源 少部分来源于书.python爬虫开发与项目实战 构造 本次使用简易的方案,模拟浏览器访问,然后输入字段,查找 ...
- 使用requests、re、BeautifulSoup、线程池爬取携程酒店信息并保存到Excel中
import requests import json import re import csv import threadpool import time, random from bs4 impo ...
随机推荐
- RPC原理及RPC实例分析(转)
出处:https://my.oschina.net/hosee/blog/711632 在学校期间大家都写过不少程序,比如写个hello world服务类,然后本地调用下,如下所示.这些程序的特点是服 ...
- java-swing-事件监听-焦点监听器
感谢大佬:https://blog.csdn.net/weixin_44512194/article/details/93377551 开始不知道焦点是啥,其实就是打字的时候,这个一闪一闪的竖线. 与 ...
- element select失效问题 , vue刷新的两种方式
changeSelect: function () { this.$forceUpdate(); }, 编辑一条记录,给select 赋值后就不动了, 原因是复制后组件需要刷新一下, 不然不能触发事件 ...
- UIKit坐标系
在UIKit中,坐标系的原点(0,0)在左上角,x值向右正向延伸,y值向下正向延伸
- Javascript 生成全局唯一标识符 (GUID,UUID)
全局唯一标识符(GUID,Globally Unique Identifier)也称作 UUID(Universally Unique IDentifier) . GUID是一种由算法生成的二进制长度 ...
- idea运行Tomcat的servlet程序时报500错误解决方法
今天在测试使用Tomcat运行servlet小程序时,在传递参数时,出现了如上错误. 开始我以为是配置出了问题,就把项目删除了又建立了一遍,结果亦然. 经过仔细排查,发现问题,先说明问题原因:idea ...
- 神奇小证明之——世界上只有5个正多面体+构造x3=2a3
今天我彻底放飞自我了...作业还没写完...但就是要总结一些好玩的小性质...谁给我的勇气呢?
- 《PHP程序员面试笔试宝典》——如何准备集体面试?
本文摘自<PHP程序员面试笔试宝典>. PHP面试技巧分享,PHP面试题,PHP宝典尽在"琉忆编程库". 集体面试也被称为群面.无领导小组面试.由于计算机发展至今,软件 ...
- C1 能力认证——Web进阶
C1 能力认证--Web进阶 DOM节点操作-上 名称 描述 getElementById() 获取带有指定id的节点 getElementsByTagName() 获取带有指定标签名的节点集合 qu ...
- uniapp 微信发送订阅消息
这篇主要针对小程序进行演示,既然是发送消息,那么就有三个问题.发送什么内容,给谁发送,怎么发送!往下一条一条解决. 发送什么消息内容 - 通过微信公众号平台 选择对应的消息模板 选择以后在我的模板里面 ...