【Java并发005】原理层面:volatile关键字全解析
一、前言
在Java 5之前,volatile是一个备受争议的关键字,因为在程序中使用它往往会导致出人意料的结果。
在Java 5之后,volatile关键字才得以重获生机。
volatile关键字虽然从字面上理解起来比较简单,但是要用好不是一件容易的事情。由于volatile关键字是与JMM(Java内存模型)有关的,因此在讲述volatile关键之前,我们先来了解一下与内存模型相关的概念和知识,然后分析了volatile关键字的实现原理,最后给出了几个使用volatile关键字的场景。
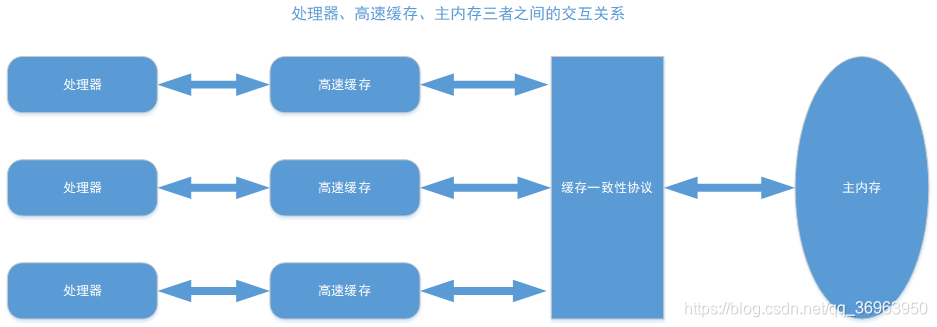
二、硬件层面解决缓存不一致的两种方法(总线上加lock锁+缓存一致性协议)
2.1 造成问题:缓存不一致
因为CPU和内存速度的剪刀差引入高速缓存:计算机在执行程序时,每条指令都是在CPU中执行的,而执行指令过程中,势必涉及到数据的读取和写入。由于程序运行过程中的临时数据是存放在主存(物理内存)当中的,这时就存在一个问题,由于CPU执行速度很快,而从内存读取数据和向内存写入数据的过程跟CPU执行指令的速度比起来要慢的多,因此如果任何时候对数据的操作都要通过和内存的交互来进行,会大大降低指令执行的速度。因此在CPU里面就有了高速缓存。
当程序在运行过程中,会将运算需要的数据从主存复制一份到CPU的高速缓存当中,那么CPU进行计算时就可以直接从它的高速缓存读取数据和向其中写入数据,当运算结束之后,再将高速缓存中的数据刷新到主存当中。举个简单的例子,比如下面的这段代码:
i = i + 1;步骤1:从主存当中读取i的值,然后复制一份到高速缓存当中;
步骤2:CPU执行指令对i进行加1操作;
步骤3:将数据写入高速缓存,最后将高速缓存中i最新的值刷新到主存当中。
这个代码在单线程中运行是没有任何问题的,但是在多线程中运行就会有问题了。在多核CPU中,每条线程可能运行于不同的CPU中,因此每个线程运行时有自己的高速缓存(对单核CPU来说,其实也会出现这种问题,只不过是以线程调度的形式来分别执行的)。本文我们以多核CPU为例。
比如同时有2个线程执行这段代码,假如初始时i的值为0,那么我们希望两个线程执行完之后i的值变为2。但是事实会是这样吗?
可能存在下面一种情况:初始时,两个线程分别读取i的值存入各自所在的CPU的高速缓存当中,然后线程1进行加1操作,然后把i的最新值1写入到内存。此时线程2的高速缓存当中i的值还是0,进行加1操作之后,i的值为1,然后线程2把i的值写入内存。
最终结果i的值是1,而不是2。这就是著名的缓存一致性问题。通常称这种被多个线程访问的变量为共享变量。
也就是说,如果一个变量在多个CPU中都存在缓存(一般在多线程编程时才会出现),那么就可能存在缓存不一致的问题。
2.2 解决方式:总线锁 + 缓存一致性
为了解决缓存不一致性问题,通常来说有以下2种解决方法:
(1)通过在总线加LOCK#锁的方式
(2)通过缓存一致性协议
这2种方式都是硬件层面上提供的方式。
2.2.1 总线锁,通过对总线加锁原子化这个
因为CPU和其他部件进行通信都是通过总线来进行的,如果对总线加LOCK#锁的话,也就是说阻塞了其他CPU对其他部件访问(如内存),从而使得只能有一个CPU能使用这个变量的内存。
整个流程:
- 写操作:当一个CPU在执行 i = i +1,如果在执行这段代码的过程中,在总线上发出了LCOK#锁的信号,不允许其他CPU操作,只有等该CPU执行完成这段代码之后,总线锁消失;
- 读操作:当其他CPU才能从变量i所在的内存读取变量,然后进行相应的操作,这样就解决了缓存不一致的问题。
关键:通过锁住总线,使该CPU原子化读写内存的操作,其他CPU无法打断。
缺点:由于在锁住总线期间,其他CPU无法访问内存,导致效率低下。
2.2.2 缓存一致性协议,通过缓存失效使其他CPU强制从主存中读取
所以就出现了缓存一致性协议。最出名的就是Intel 的MESI协议,MESI协议保证了每个缓存中使用的共享变量的副本是一致的。它核心的思想是:
- 写操作:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态;
- 读操作:当其他CPU需要读取刚刚写入的这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。
三、并发编程中的三个概念
在并发编程中,我们通常会遇到以下三个问题:原子性问题,可见性问题,有序性问题。我们先看具体看一下这三个概念:
3.1 原子性
3.1.1 原子性定义
原子性定义:即一个操作或者多个操作 要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
3.1.2 原子性举例
原子性举例:
并发编程中,假如为一个32位的变量赋值过程不具备原子性的话,会发生什么后果?
i = 9;假若一个线程执行到这个语句时,我暂且假设为一个32位的变量赋值包括两个过程:为低16位赋值,为高16位赋值。
那么就可能发生一种情况:当将低16位数值写入之后,突然被中断,而此时又有一个线程去读取i的值,那么读取到的就是错误的数据。
3.2 可见性
3.2.1 可见性定义
可见性定义:当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
3.2.2 可见性举例
举个简单的例子,看下面这段代码:
//线程1执行的代码
int i = 0;
i = 10;
//线程2执行的代码
j = i;假若执行线程1的是CPU1,执行线程2的是CPU2。由上面的分析可知,当线程1执行 i =10这句时,会先把i的初始值加载到CPU1的高速缓存中,然后赋值为10,那么在CPU1的高速缓存当中i的值变为10了,却没有立即写入到主存当中。
此时线程2执行 j = i,它会先去主存读取i的值并加载到CPU2的缓存当中,注意此时内存当中i的值还是0,那么就会使得j的值为0,而不是10.
这就是可见性问题,线程1对变量i修改了之后,线程2没有立即看到线程1修改的值。
3.3 有序性
3.3.1 有序性定义
有序性定义:即程序执行的顺序按照代码的先后顺序执行。
3.3.2 有序性举例(单线程下指令重排不会造成线程安全问题)
举个简单的例子,看下面这段代码:
int i = 0;
boolean flag = false;
i = 1; //语句1
flag = true; //语句2上面代码定义了一个int型变量,定义了一个boolean类型变量,然后分别对两个变量进行赋值操作。从代码顺序上看,语句1是在语句2前面的,那么JVM在真正执行这段代码的时候会保证语句1一定会在语句2前面执行吗?不一定,为什么呢?这里可能会发生指令重排序(Instruction Reorder)。
下面解释一下什么是指令重排序,一般来说,处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的。
比如上面的代码中,语句1和语句2谁先执行对最终的程序结果并没有影响,那么就有可能在执行过程中,语句2先执行而语句1后执行。
但是要注意,虽然处理器会对指令进行重排序,但是它会保证程序最终结果会和代码顺序执行结果相同,那么它靠什么保证的呢?再看下面一个例子:
int a = 10; //语句1
int r = 2; //语句2
a = a + 3; //语句3
r = a*a; //语句4这段代码有4个语句,那么可能的一个执行顺序是:语句2 语句1 语句3 语句4
问题:那么可不可能是这个执行顺序呢: 语句2 语句1 语句4 语句3
回答:不可能,因为处理器在进行重排序时是会考虑指令之间的数据依赖性,如果一个指令Instruction 2必须用到Instruction 1的结果,那么处理器会保证Instruction 1会在Instruction 2之前执行。
结论:单线程下,指令重排序会考虑数据依赖性,不会影响程序执行的结果。
3.3.3 有序性举例(多线程下指令重排会造成线程安全问题)
虽然重排序不会影响单个线程内程序执行的结果,但是多线程呢?下面看一个例子:
//线程1:
context = loadContext(); //语句1
inited = true; //语句2
//线程2:
while(!inited ){
sleep()
}
doSomethingwithconfig(context);上面代码中,由于语句1和语句2没有数据依赖性,因此可能会被重排序。假如发生了重排序,在线程1执行过程中先执行语句2,而此是线程2会以为初始化工作已经完成,那么就会跳出while循环,去执行doSomethingwithconfig(context)方法,而此时context并没有被初始化,就会导致程序出错。
从上面可以看出,指令重排序不会影响单个线程的执行,但是会影响到线程并发执行的正确性。
也就是说,要想并发程序正确地执行,必须要保证原子性、可见性以及有序性。只要有一个没有被保证,就有可能会导致程序运行不正确。
四、Java内存模型(synchronized和lock如何保证原子性、可见性、有序性)
一句话:JMM是Java并发在JVM层面的解释,即在JVM层面解释Java并发,其中包括 8个原子性操作和执行规则,还有 8个在保证有序性前提下的 Happens-Before 原则,都是要联系起来记忆的。
硬件层面,CPU通过缓存来访问主存;Java层面,Java线程/执行引擎 通过 工作内存来访问主存。
可见性,原子性,有序性都可以通过JMM来解释,可见性问题之所以出现是因为各个线程的工作内存之间不可见,原子性问题之所以出现是因为 Java/线程 通过工作内存读写主存的某段代码,存在被打断;有序性问题之所以存在是因为编译层面存在的指令重排。
硬件层面,可见性问题之所以出现是因为各个CPU缓存值之间不可见,原子性问题之所以出现是 操作系统 的分时CPU原则 使得某些临界资源(如内存、磁盘)无法原子化访问,有序性问题之所以出现是因为编译层面存在指令重排。
在Java虚拟机规范中试图定义一种Java内存模型(Java Memory Model,JMM)来屏蔽各个硬件平台和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的内存访问效果。那么Java内存模型规定了哪些东西呢,它定义了程序中变量的访问规则,往大一点说是定义了程序执行的次序。注意,为了获得较好的执行性能,Java内存模型并没有限制执行引擎使用处理器的寄存器或者高速缓存来提升指令执行速度,也没有限制编译器对指令进行重排序。也就是说,在java内存模型中,也会存在缓存一致性问题和指令重排序的问题。
Java内存模型规定所有的变量都是存在主存当中(类似于前面说的物理内存),每个线程都有自己的工作内存(类似于前面的高速缓存)。线程对变量的所有操作都必须在工作内存中进行,而不能直接对主存进行操作。并且每个线程不能访问其他线程的工作内存。
举个简单的例子:在java中,执行下面这个语句:
i = 10;执行线程必须先在自己的工作线程中对变量i所在的缓存行进行赋值操作,然后再写入主存当中。而不是直接将数值10写入主存当中。
那么Java语言 本身对 原子性、可见性以及有序性提供了哪些保证呢?
4.1 原子性
在Java中,对基本数据类型的变量的读取和赋值操作是原子性操作,即这些操作是不可被中断的,要么执行,要么不执行。
上面一句话虽然看起来简单,但是理解起来并不是那么容易。看下面一个例子i:
请分析以下哪些操作是原子性操作:
x = 10; //语句1 一步操作
y = x; //语句2 两步操作 读取x:主内存->工作内存 写入y:工作内存->主内存
x++; //语句3 三步操作 读取 赋值assign 写入
x = x + 1; //语句4 三步操作咋一看,有些朋友可能会说上面的4个语句中的操作都是原子性操作。其实只有语句1是原子性操作,其他三个语句都不是原子性操作。
语句1是直接将数值10赋值给x,也就是说线程执行这个语句的会直接将数值10写入到工作内存中。
语句2实际上包含2个操作,它先要去读取x的值,再将x的值写入工作内存,虽然读取x的值以及 将x的值写入工作内存 这2个操作都是原子性操作,但是合起来就不是原子性操作了。
语句3 和语句4 ,x++和 x = x+1包括3个操作:读取x的值,进行加1操作,写入新的值。
所以上面4个语句只有语句1的操作具备原子性。
也就是说,只有简单的读取、赋值(而且必须是将数字赋值给某个变量,变量之间的相互赋值不是原子操作)才是原子操作。
只有读取和常量复制才是原子操作
变量赋值是两步操作,常量计算是两步操作。
变量计算是三步操作。
不过这里有一点需要注意:在32位平台下,对64位数据的读取和赋值是需要通过两个操作来完成的,即long类型和double类型,不能保证其原子性。但是好像在最新的JDK中,JVM已经保证对64位数据的读取和赋值也是原子性操作了。
从上面可以看出,Java内存模型只保证了基本读取和赋值是原子性操作,如果要实现更大范围操作的原子性,可以通过synchronized和Lock来实现。由于synchronized和Lock能够保证任一时刻只有一个线程执行该代码块,那么自然就不存在原子性问题了,从而保证了原子性。
问题:synchronized和Lock如何保证操作的原子性?
回答:synchronized和Lock通过保证任一时刻只有一个线程执行含有共享变量的代码块(对于没有 synchronized和Lock修饰的非同步方法、非同步代码块,不会阻塞的,它们与 synchronized和Lock无关),那么自然就不存在原子性问题了,从而保证了原子性。
4.2 可见性
对于可见性,Java提供了volatile关键字来保证可见性。
当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。
而普通的共享变量不能保证可见性,因为普通共享变量被修改之后,什么时候被写入主存是不确定的,当其他线程去读取时,此时内存中可能还是原来的旧值,因此无法保证可见性。
另外,通过synchronized和Lock也能够保证可见性,synchronized和Lock能保证同一时刻只有一个线程获取锁然后执行同步代码,并且在释放锁之前会将对变量的修改刷新到主存当中。因此可以保证可见性。
问题:synchronized和Lock如何保证操作的可见性?
回答:synchronized和Lock通过保证同一时刻只有一个线程获取锁然后执行同步代码(保证原子性),并且在释放锁之前会将对变量的修改刷新到主存当中(保证可见性),因此可以保证可见性。
4.3 有序性与指令重排序
金手指:指令重排序和happens-before原则/先行发生原则,只和有序性相关,与原子性、可见性无关。
在Java内存模型中,允许编译器和处理器对指令进行重排序,但是重排序过程不会影响到单线程程序的执行,却会影响到多线程并发执行的正确性。
在Java里面,可以通过volatile关键字来保证一定的“有序性”(具体原理在下一节讲述)。另外可以通过synchronized和Lock来保证有序性,很显然,synchronized和Lock保证每个时刻是有一个线程执行同步代码,相当于是让线程顺序执行同步代码,自然就保证了有序性。
问题:synchronized和Lock如何保证操作的有序性?
回答:synchronized和Lock保证每个时刻是有一个线程执行同步代码(保证原子性),其原子内部顺序执行,保证有序性,原子外部没有互斥资源,不需要保证有序性,所有保证了有序性。
附加:happens-before原则/先行发生原则:先天有序性
happens-before原则定义:JMM具备八个先天的“有序性”,即不需要通过任何手段就能够得到保证的有序性。
下面就来具体介绍下happens-before原则(先行发生原则):
- 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作;
- 锁定规则:一个unLock操作先行发生于后面对同一个锁额lock操作;
- volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作;
- 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C;
- 线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作;
- 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生;
- 线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行;
- 对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始。
这8条规则中,前4条规则是比较重要的,后4条规则都是显而易见的。
下面我们来解释一下前4条规则:
第一条规则:对于程序次序规则来说,我的理解就是一段程序代码的执行在单个线程中看起来是有序的。注意,虽然这条规则中提到“书写在前面的操作先行发生于书写在后面的操作”,这个应该是程序看起来执行的顺序是按照代码顺序执行的,因为虚拟机可能会对程序代码进行指令重排序。虽然进行重排序,但是最终执行的结果是与程序顺序执行的结果一致的,它只会对不存在数据依赖性的指令进行重排序。因此,在单个线程中,程序执行看起来是有序执行的,这一点要注意理解。事实上,这个规则是用来保证程序在单线程中执行结果的正确性,但无法保证程序在多线程中执行的正确性。
第二条规则也比较容易理解,也就是说无论在单线程中还是多线程中,同一个锁如果出于被锁定的状态,那么必须先对锁进行了释放操作,后面才能继续进行lock操作。
第三条规则是一条比较重要的规则,也是后文将要重点讲述的内容。直观地解释就是,如果一个线程先去写一个变量,然后一个线程去进行读取,那么写入操作肯定会先行发生于读操作。
第四条规则实际上就是体现happens-before原则具备传递性。
附加:如果两个操作的执行次序无法从happens-before原则推导出来,那么它们就不能保证它们的有序性,虚拟机可以随意地对它们进行重排序。
五、深入剖析volatile关键字
在前面讲述了很多东西,其实都是为讲述volatile关键字作铺垫,那么接下来我们就进入主题。
5.1 volatile关键字的两层语义
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
禁止指令重排序。
(1)volatile修饰的变量进行写操作,立即可见,从而保证可见性;(强制将对缓存的修改操作(即写操作)立即写入主存;如果是写操作,导致其他CPU中对应的缓存行无效,让其他CPU只能从主存中拿刚刚更新的,两个操作(立即写入主存和使其他CPU中对应的缓存行失效)保证可见性)
(2)第一层含义的不足,volatile修饰的变量进行读操作,是不可见的,所有CAS,从而不保证原子性
(3)volatile修饰的变量禁止指令重排序,它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成
(4)第二层含义的不足,语句3中包含volatile修饰的变量,但是语句1和语句2的顺序、语句4和语句5的顺序是不作任何保证的。
可见性只能保证每次读取的是最新的值,原子性保证
5.2 volatile修饰的变量保证可见性
本节stop = true; 中常量复制,是原子操作,只要保证可见性,所以正确。
下一节中自增操作是三步操作,所有要同时保证原子性和可见性,所以出错。
volatile修饰的变量进行写操作,立即可见,
先看一段代码,假如线程1先执行,线程2后执行:
//线程1
boolean stop = false;
while(!stop){
doSomething();
}
//线程2
stop = true; // 常量复制,是原子操作这段代码是很典型的一段代码,很多人在中断线程时可能都会采用这种标记办法。但是事实上,这段代码会完全运行正确么?即一定会将线程中断么?不一定,也许在大多数时候,这个代码能够把线程中断,但是也有可能会导致无法中断线程(虽然这个可能性很小,但是只要一旦发生这种情况就会造成死循环了)。
下面解释一下这段代码为何有可能导致无法中断线程。在前面已经解释过,每个线程在运行过程中都有自己的工作内存,那么线程1在运行的时候,会将stop变量的值拷贝一份放在自己的工作内存当中。
那么当线程2更改了stop变量的值之后,但是还没来得及写入主存当中,线程2转去做其他事情了,那么线程1由于不知道线程2对stop变量的更改,因此还会一直循环下去。
但是用volatile修饰之后就变得不一样了:
第一:使用volatile关键字会强制将修改的值立即写入主存;
第二:使用volatile关键字的话,当线程2进行修改时,会导致线程1的工作内存中缓存变量stop的缓存行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);
JVM层面(各个工作内存和主内存),线程中工作内存缓存行失效,只能到主存中拿;
硬件层面(各个CPU缓存和主内存),CPU中缓存行失效,只能到主存中拿。
第三:由于线程1的工作内存中缓存变量stop的缓存行无效,所以线程1再次读取变量stop的值时会去主存读取。
那么在线程2修改stop值时(当然这里包括2个操作,修改线程2工作内存中的值,然后将修改后的值写入内存),会使得线程1的工作内存中缓存变量stop的缓存行无效,然后线程1读取时,发现自己的缓存行无效,它会等待缓存行对应的主存地址被更新之后,然后去对应的主存读取最新的值。
那么线程1读取到的就是最新的正确的值。
5.3 volatile不能保证原子性
上一节stop = true; 中常量复制,是原子操作,只要保证可见性,所以正确。
本节中自增操作是三步操作,所有要同时保证原子性和可见性,所以出错。
从上面知道volatile关键字保证了操作的可见性,但是volatile能保证对变量的操作是原子性吗?
下面看一个例子:
public class Test {
public volatile int inc = 0;
public void increase() {
inc++;
}
public static void main(String[] args) {
final Test test = new Test();
for(int i=0;i<10;i++){
new Thread(){
public void run() {
for(int j=0;j<1000;j++)
test.increase();
};
}.start();
}
while(Thread.activeCount()>1) //保证前面的线程都执行完
Thread.yield();
System.out.println(test.inc);
}
}大家想一下这段程序的输出结果是多少?也许有些朋友认为是10000。但是事实上运行它会发现每次运行结果都不一致,都是一个小于10000的数字。
可能有的朋友就会有疑问,不对啊,上面是对变量inc进行自增操作,由于volatile保证了可见性,那么在每个线程中对inc自增完之后,在其他线程中都能看到修改后的值啊,所以有10个线程分别进行了1000次操作,那么最终inc的值应该是1000*10=10000。
这里面就有一个误区了,volatile关键字能保证可见性没有错,但是上面的程序错在没能保证原子性。可见性只能保证每次读取的是最新的值,但是volatile没办法保证对变量的操作的原子性。
在前面已经提到过,自增操作是不具备原子性的,它包括读取变量的原始值、进行加1操作、写入工作内存。那么就是说自增操作的三个子操作可能会分割开执行,就有可能导致下面这种情况出现:
假如某个时刻变量inc的值为10,
线程1对变量进行自增操作,线程1先读取了变量inc的原始值(读取、累加、写入,线程1仅仅读取了),然后线程1被阻塞了;
然后线程2对变量进行自增操作,线程2也去读取变量inc的原始值,由于线程1只是对变量inc进行读取操作,而没有对变量进行修改操作,所以不会导致线程2的工作内存中缓存变量inc的缓存行无效,所以线程2会直接去主存读取inc的值,发现inc的值时10,然后进行加1操作,并把11写入工作内存,最后写入主存。
然后线程1接着进行加1操作,由于已经读取了inc的值,注意此时在线程1的工作内存中inc的值仍然为10,所以线程1对inc进行加1操作后inc的值为11,然后将11写入工作内存,最后写入主存。
那么两个线程分别进行了一次自增操作后,inc只增加了1。
解释到这里,可能有朋友会有疑问,不对啊,前面不是保证一个变量在修改volatile变量时,会让缓存行无效吗?然后其他线程去读就会读到新的值,对,这个没错。这个就是上面的happens-before规则中的volatile变量规则,但是要注意,线程1对变量进行读取操作之后,被阻塞了的话,并没有对inc值进行修改。然后虽然volatile能保证线程2对变量inc的值读取是从内存中读取的,但是线程1没有进行修改,所以线程2根本就不会看到修改的值。
根源就在这里,自增操作不是原子性操作,而且volatile也无法保证对变量的任何操作都是原子性的。
把上面的代码改成以下任何一种都可以达到效果(保证累加操作的一致性):
采用synchronized:
public class Test {
public int inc = 0;
public synchronized void increase() {
inc++;
}
public static void main(String[] args) {
final Test test = new Test();
for(int i=0;i<10;i++){
new Thread(){
public void run() {
for(int j=0;j<1000;j++)
test.increase();
};
}.start();
}
while(Thread.activeCount()>1) //保证前面的线程都执行完
Thread.yield();
System.out.println(test.inc);
}
}采用Lock:
public class Test {
public int inc = 0;
Lock lock = new ReentrantLock();
public void increase() {
lock.lock();
try {
inc++;
} finally{
lock.unlock();
}
}
public static void main(String[] args) {
final Test test = new Test();
for(int i=0;i<10;i++){
new Thread(){
public void run() {
for(int j=0;j<1000;j++)
test.increase();
};
}.start();
}
while(Thread.activeCount()>1) //保证前面的线程都执行完
Thread.yield();
System.out.println(test.inc);
}
}采用AtomicInteger:
public class Test {
public AtomicInteger inc = new AtomicInteger();
public void increase() {
inc.getAndIncrement();
}
public static void main(String[] args) {
final Test test = new Test();
for(int i=0;i<10;i++){
new Thread(){
public void run() {
for(int j=0;j<1000;j++)
test.increase();
};
}.start();
}
while(Thread.activeCount()>1) //保证前面的线程都执行完
Thread.yield();
System.out.println(test.inc);
}
}在java 1.5的java.util.concurrent.atomic包下提供了一些原子操作类,即对基本数据类型的 自增(加1操作),自减(减1操作)、以及加法操作(加一个数),减法操作(减一个数)进行了封装,保证这些操作是原子性操作。atomic是利用CAS来实现原子性操作的(Compare And Swap),CAS实际上是利用处理器提供的CMPXCHG指令实现的,而处理器执行CMPXCHG指令是一个原子性操作。
问题:atomic是利用CAS来实现原子性操作的(Compare And Swap)什么意思?
回答:
5.4 volatile能保证有序性吗?合理地使用volatile可以保证有序性
在前面提到volatile关键字能禁止指令重排序,所以volatile能在一定程度上保证有序性。
volatile关键字禁止指令重排序有两层意思:
1)在程序执行时,当程序执行到volatile变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对后面的操作可见;在其后面的操作肯定还没有进行;
2)在指令优化时,不能将在对volatile变量访问的语句放在其后面执行,也不能把volatile变量后面的语句放到其前面执行。
两个不同的,第一条指明程序执行的情况,第二条指明指令优化不能违反第一条所保证的,只能指令优化被volatile变量分隔的。
可能上面说的比较绕,举个简单的例子:
//x、y为非volatile变量
//flag为volatile变量
x = 2; //语句1
y = 0; //语句2
flag = true; //语句3
x = 4; //语句4
y = -1; //语句5由于flag变量为volatile变量,那么在进行指令重排序的过程的时候,不会将语句3放到语句1、语句2前面,也不会讲语句3放到语句4、语句5后面。但是要注意语句1和语句2的顺序、语句4和语句5的顺序是不作任何保证的。
并且volatile关键字能保证,执行到语句3时,语句1和语句2必定是执行完毕了的,且语句1和语句2的执行结果对语句3、语句4、语句5是可见的。
那么我们回到前面举的一个例子:
//线程1:
context = loadContext(); //语句1
inited = true; //语句2
//线程2:
while(!inited ){
sleep()
}
doSomethingwithconfig(context);前面举这个例子的时候,提到有可能语句2会在语句1之前执行,那么久可能导致context还没被初始化,而线程2中就使用未初始化的context去进行操作,导致程序出错。
这里如果用volatile关键字对inited变量进行修饰,就不会出现这种问题了,因为当执行到语句2时,必定能保证context已经初始化完毕。
5.5 volatile底层原理:volatile底层是如何保证可见性和有序性的?lock前缀指令
前面讲述了源于volatile关键字的一些使用,下面我们来探讨一下volatile到底如何保证可见性和禁止指令重排序的。
下面这段话摘自《深入理解Java虚拟机》:
“观察加入volatile关键字和没有加入volatile关键字时所生成的汇编代码发现,加入volatile关键字时,会多出一个lock前缀指令”
lock前缀指令实际上相当于一个内存屏障(也成内存栅栏),内存屏障会提供3个功能:
1)它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;(保证有序性)
2)它会强制将对缓存的修改操作(即写操作)立即写入主存;(保证可见性)
3)如果是写操作,它会导致其他CPU中对应的缓存行无效。(保证可见性)
六、使用volatile关键字的场景(voliatile代替synchronized,弥补原子性)
synchronized关键字是防止多个线程同时执行一段代码,那么就会很影响程序执行效率,而volatile关键字在某些情况下性能要优于synchronized,但是要注意volatile关键字是无法替代synchronized关键字的,因为volatile关键字无法保证操作的原子性。通常来说,使用volatile必须具备以下2个条件:
- 对volatile变量的写操作不依赖于当前值
- 该volatile变量没有包含在具有其他变量的不变式中
金手指:这两个条件是对程序员写程序的时候的要求
实际上,这些条件表明,可以被写入 volatile 变量的这些有效值独立于任何程序的状态,包括变量的当前状态。
事实上,我的理解就是上面的2个条件需要保证操作是原子性操作,才能保证使用volatile关键字的程序在并发时能够正确执行。
下面列举几个Java中使用volatile的几个场景。
- 状态标记量(程序员使用状态标记量来保证volatile的两个性质,状态标志量是常量赋值,唯二的两个原子操作是读取和常量赋值,所以只有保证可见性和有序性即可,所以可以使用volatile代替synchronized关键字)
volatile boolean flag = false; // 从三个性质上来说,flag 是volatile 变量,是状态标记量,常量赋值保证原子性
// 从两个条件上来说,无论是flag=false这一句,还是下面的flag=true那句
// 第一,这里对volatile变量的写操作不依赖于当前值
// 第二,volatile变量没有包含在具有其他变量的不变式中
while(!flag){
doSomething();
}
public void setFlag() {
flag = true;
}volatile boolean inited = false; // 从三个性质上来说,inited 是volatile 变量,是状态标记量,常量赋值保证原子性
// 从两个条件上来说,无论是inited =false这一句,还是下面的inited =true那句
// 第一,这里对volatile变量的写操作不依赖于当前值
// 第二,volatile变量没有包含在具有其他变量的不变式中
//线程1:
context = loadContext();
inited = true;
//线程2:
while(!inited ){
sleep()
}
doSomethingwithconfig(context);- double check(程序员使用两次检测来保证volatile的两个性质)
class Singleton{
private volatile static Singleton instance = null;
//从三个性质上来说, instance 是 volatile 变量,唯二赋值第一个是这里赋值常量null,原子操作一定没问题
// 第二个操作是双层if中的new Singleton(),虽然不是原子操作,但是双层if保证不会让其他线程进来,保证不会有其他打断这个new Singleton()操作
// 从两个条件上来说,无论是instance = null和instance = new Singleton()这一句
// 第一,这里对volatile变量的写操作不依赖于当前值
// 第二,volatile变量没有包含在具有其他变量的不变式中
private Singleton() {
}
public static Singleton getInstance() {
if(instance==null) {
synchronized (Singleton.class) {
if(instance==null)
instance = new Singleton();
}
}
return instance;
}
}七、面试金手指
7.1 synchronized/lock如何实现原子性、有序性、可见性
synchronized和Lock如何保证操作的原子性?
synchronized和Lock通过保证任一时刻只有一个线程执行含有共享变量的代码块(对于没有 synchronized和Lock修饰的非同步方法、非同步代码块,不会阻塞的,它们与 synchronized和Lock无关),那么自然就不存在原子性问题了,从而保证了原子性。
synchronized和Lock如何保证操作的可见性?
synchronized和Lock通过保证同一时刻只有一个线程获取锁然后执行同步代码(保证原子性),并且在释放锁之前会将对变量的修改刷新到主存当中(保证可见性),因此可以保证可见性。
synchronized和Lock如何保证操作的有序性?
synchronized和Lock保证每个时刻是有一个线程执行同步代码(保证原子性),其原子内部顺序执行,保证有序性,原子外部没有互斥资源,不需要保证有序性,所有保证了有序性。
7.2 哪些是原子操作,哪些是非原子操作?
只有读取和常量复制才是原子操作
变量赋值是两步操作,常量计算是两步操作。
变量计算是三步操作。
7.3 有序性中的 happen-before 先行发生原则?
Java内存模型具备一些先天的“有序性”,即不需要通过任何手段就能够得到保证的有序性,这个通常也称为happens-before原则。
如果两个操作执行次序可以使用happens-before推导出来,则先后顺序确定,虚拟机无法对其重排序。
如果两个操作的执行次序无法从happens-before原则推导出来,那么它们就不能保证它们的有序性,虚拟机可以随意地对它们进行重排序。
下面就来具体介绍下happens-before原则(先行发生原则):
(1)程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作;
(2)锁定规则:一个unLock操作先行发生于后面对同一个锁额lock操作;
(3)volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作;
(4)传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C;
(5)线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作;
(6)线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生;
(7)线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行;
(8)对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始。
这8条规则中,前4条规则是比较重要的,后4条规则都是显而易见的。
下面我们来解释一下前4条规则:
第一条规则:对于程序次序规则来说,我的理解就是一段程序代码的执行在单个线程中看起来是有序的。注意,虽然这条规则中提到“书写在前面的操作先行发生于书写在后面的操作”,这个应该是程序看起来执行的顺序是按照代码顺序执行的,因为虚拟机可能会对程序代码进行指令重排序。虽然进行重排序,但是最终执行的结果是与程序顺序执行的结果一致的,它只会对不存在数据依赖性的指令进行重排序。因此,在单个线程中,程序执行看起来是有序执行的,这一点要注意理解。事实上,这个规则是用来保证程序在单线程中执行结果的正确性,但无法保证程序在多线程中执行的正确性。
第二条规则也比较容易理解,也就是说无论在单线程中还是多线程中,同一个锁如果出于被锁定的状态,那么必须先对锁进行了释放操作,后面才能继续进行lock操作。
第三条规则是一条比较重要的规则,也是后文将要重点讲述的内容。直观地解释就是,如果一个线程先去写一个变量,然后一个线程去进行读取,那么写入操作肯定会先行发生于读操作。
第四条规则实际上就是体现happens-before原则具备传递性。
7.4 volatile保证可见性、有序性、不保证原子性?
(1)volatile修饰的变量进行写操作,立即可见,从而保证可见性;(强制将对缓存的修改操作(即写操作)立即写入主存;如果是写操作,导致其他CPU中对应的缓存行无效,让其他CPU只能从主存中拿刚刚更新的,两个操作(立即写入主存和使其他CPU中对应的缓存行失效)保证可见性)
JVM层面,线程中工作内存缓存行失效,只能到主存中拿;
硬件层面,CPU中缓存行失效,只能到主存中拿。
(2)第一层含义的不足,volatile修饰的变量进行读操作,是不可见的,是不更新的
(3)volatile修饰的变量禁止指令重排序,它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成
1)在程序执行时,当程序执行到volatile变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对后面的操作可见;在其后面的操作肯定还没有进行;
2)在指令优化时,不能将在对volatile变量访问的语句放在其后面执行,也不能把volatile变量后面的语句放到其前面执行。
两个不同的,第一条指明程序执行的情况,第二条指明指令优化不能违反第一条所保证的,只能指令优化被volatile变量分隔的。
(4)第二层含义的不足,语句3中包含volatile修饰的变量,但是语句1和语句2的顺序、语句4和语句5的顺序是不作任何保证的。
可见性只能保证每次读取的是最新的值,原子性保证操作不被打断。
比如 stop = true; 中常量复制,是原子操作,只要保证可见性,所以正确。
又如 自增操作是三步操作,所有要同时保证原子性和可见性,所以出错。
7.5 volatile底层原理:volatile底层是如何保证可见性和有序性的?
lock前缀指令
7.6 如何弥补volatile关键字的不足?
1)对volatile变量的写操作不依赖于当前值
2)该volatile变量没有包含在具有其他变量的不变式中
举例:标记位和单例模式双层检测
八、小结
volidate关键字,完成了。
天天打码,天天进步!!!
【Java并发005】原理层面:volatile关键字全解析的更多相关文章
- Java并发编程之三:volatile关键字解析 转载
目录: <Java并发编程之三:volatile关键字解析 转载> <Synchronized之一:基本使用> volatile这个关键字可能很多朋友都听说过,或许也都用过 ...
- Java并发编程学习:volatile关键字解析
转载:https://www.cnblogs.com/dolphin0520/p/3920373.html 写的非常棒,好东西要分享一下 Java并发编程:volatile关键字解析 volatile ...
- 并发系列2:Java并发的基石,volatile关键字、synchronized关键字、乐观锁CAS操作
由并发大师Doug Lea操刀的并发包Concurrent是并发编程的重要包,而并发包的基石又是volatile关键字.synchronized关键字.乐观锁CAS操作这些基础.因此了解他们的原理对我 ...
- Java并发编程(二):volatile关键字
volatile是Java虚拟机提供的轻量级的同步机制.volatile关键字有如下两个作用,一句话概括就是内存可见性和禁止重排序. 1)保证被volatile修饰的共享变量对所有线程总是可见的,也就 ...
- 全面理解Java内存模型(JMM)及volatile关键字(转载)
关联文章: 深入理解Java类型信息(Class对象)与反射机制 深入理解Java枚举类型(enum) 深入理解Java注解类型(@Annotation) 深入理解Java类加载器(ClassLoad ...
- 全面理解Java内存模型(JMM)及volatile关键字(转)
原文地址:全面理解Java内存模型(JMM)及volatile关键字 关联文章: 深入理解Java类型信息(Class对象)与反射机制 深入理解Java枚举类型(enum) 深入理解Java注解类型( ...
- 深入理解Java内存模型JMM与volatile关键字
深入理解Java内存模型JMM与volatile关键字 多核并发缓存架构 Java内存模型 Java线程内存模型跟CPU缓存模型类似,是基于CPU缓存模型来建立的,Java线程内存模型是标准化的,屏蔽 ...
- JAVA多线程学习- 三:volatile关键字
Java的volatile关键字在JDK源码中经常出现,但是对它的认识只是停留在共享变量上,今天来谈谈volatile关键字. volatile,从字面上说是易变的.不稳定的,事实上,也确实如此,这个 ...
- Java并发编程原理与实战五:创建线程的多种方式
一.继承Thread类 public class Demo1 extends Thread { public Demo1(String name) { super(name); } @Override ...
- Java并发编程之验证volatile不能保证原子性
Java并发编程之验证volatile不能保证原子性 通过系列文章的学习,凯哥已经介绍了volatile的三大特性.1:保证可见性 2:不保证原子性 3:保证顺序.那么怎么来验证可见性呢?本文凯哥(凯 ...
随机推荐
- 手写tomcat——编写一个提供servlet能力的 http服务器
点击查看代码 package com.grady.diytomcat; import com.grady.diytomcat.handler.RequestHandler; import org.do ...
- 【读书笔记】C#高级编程 第二十章 诊断
(一)诊断概述 名称空间System.Diagnostics提供了用于跟踪.事件日志.性能测量以及代码协定的类.System.Diagnostics.Contracts名称空间中的类可以定义前提条件. ...
- PostgreSQL逻辑复制解密
在数字化时代的今天,我们都认同数据会创造价值.为了最大化数据的价值,我们不停的建立着数据迁移的管道,从同构到异构,从关系型到非关系型,从云下到云上,从数仓到数据湖,试图在各种场景挖掘数据的价值.而在这 ...
- kratos v2版本命令行工具使用
使用 下载 go install github.com/go-kratos/kratos/cmd/kratos/v2@latest 查看是否安装成功 kratos -v kratos version ...
- 怎样编写正确、高效的 Dockerfile
基础镜像 FROM 基础镜像 基础镜像的选择非常关键: 如果关注的是镜像的安全和大小,那么一般会选择 Alpine: 如果关注的是应用的运行稳定性,那么可能会选择 Ubuntu.Debian.Cent ...
- Kubernetes里的Service是如何工作的
Service是Kubernetes接入层的一种抽象资源,它为我们提供了一种固定的.统一的访问接口地址和负载均衡能力,这时可能会想到,当时使用docker-compose的时候,不存在Service概 ...
- 一个 dubbo 和 springboot 的兼容性问题
背景介绍 最近把dubbo的版本从2.7.3升级到2.7.15时,遇到一个报错 No application config found or it's not a valid config! ,对应的 ...
- 关于Jenkins-Item-Office 365 Connector-下的多选框的参数定义
在Jenkins的Item中Office 365 Connector下,我们有时会使用到,多选框(复选框),目的是可选择多个多个条目赋值给指定的变量 然后在Build Triggers中可以进行引用, ...
- Hive 自定义UDF操作步骤
Hive 自定义UDF操作步骤 需要自定义类,然后继承UDF 然后在方法envluate()方法里面实现具体的业务逻辑,打包上传到linux(以免出错打包成RunningJar) 一.创建临时函数 ( ...
- MybatisPlus生成主键策略方法
MybatisPlus生成主键策略方法 全局id生成策略[因为是全局id所以不推荐] SpringBoot集成Mybatis-Plus 在yaml配置文件中添加MP配置 mybatis-plus: g ...