带你了解极具弹性的Spark架构的原理
摘要:相比MapReduce僵化的Map与Reduce分阶段计算相比,Spark的计算框架更加富有弹性和灵活性,运行性能更佳。
本文分享自华为云社区《Spark架构原理》,作者:JavaEdge。
相比MapReduce僵化的Map与Reduce分阶段计算相比,Spark的计算框架更加富有弹性和灵活性,运行性能更佳。
Spark的计算阶段
- MapReduce一个应用一次只运行一个map和一个reduce
- Spark可根据应用的复杂度,分割成更多的计算阶段(stage),组成一个有向无环图DAG,Spark任务调度器可根据DAG的依赖关系执行计算阶段
逻辑回归机器学习性能Spark比MapReduce快100多倍。因为某些机器学习算法可能需要进行大量迭代计算,产生数万个计算阶段,这些计算阶段在一个应用中处理完成,而不是像MapReduce那样需要启动数万个应用,因此运行效率极高。
DAG,有向无环图,不同阶段的依赖关系是有向的,计算过程只能沿依赖关系方向执行,被依赖的阶段执行完成前,依赖的阶段不能开始执行。该依赖关系不能有环形依赖,否则就死循环。
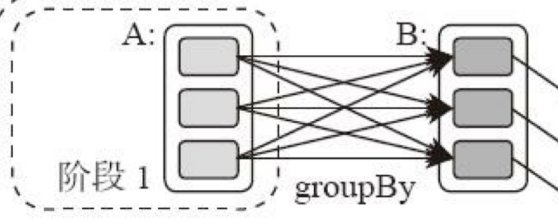
典型的Spark运行DAG的不同阶段:
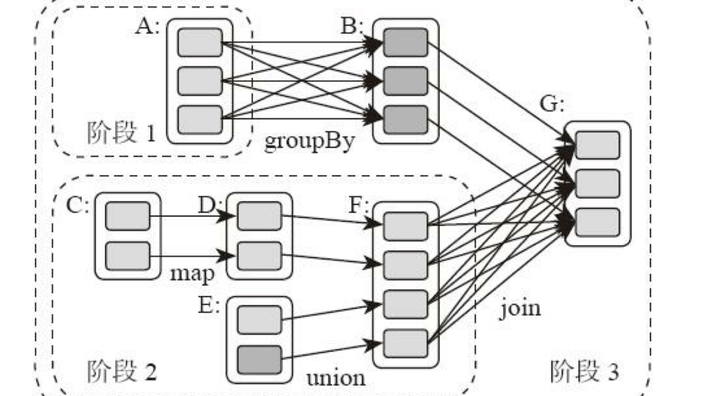
整个应用被切分成3个阶段,阶段3需要依赖阶段1、2,阶段1、2互不依赖。Spark执行调度时,先执行阶段1、2,完成后,再执行阶段3。对应Spark伪代码:
rddB = rddA.groupBy(key)
rddD = rddC.map(func)
rddF = rddD.union(rddE)
rddG = rddB.join(rddF)
所以Spark作业调度执行的核心是DAG,整个应用被切分成数个阶段,每个阶段的依赖关系也很清楚。根据每个阶段要处理的数据量生成任务集合(TaskSet),每个任务都分配一个任务进程去处理,Spark就实现了大数据的分布式计算。
负责Spark应用DAG生成和管理的组件是DAGScheduler,DAGScheduler根据程序代码生成DAG,然后将程序分发到分布式计算集群,按计算阶段的先后关系调度执行。
那么Spark划分计算阶段的依据是什么呢?显然并不是RDD上的每个转换函数都会生成一个计算阶段,比如上面的例子有4个转换函数,但是只有3个阶段。
你可以再观察一下上面的DAG图,关于计算阶段的划分从图上就能看出规律,当RDD之间的转换连接线呈现多对多交叉连接的时候,就会产生新的阶段。一个RDD代表一个数据集,图中每个RDD里面都包含多个小块,每个小块代表RDD的一个分片。
一个数据集中的多个数据分片需要进行分区传输,写入到另一个数据集的不同分片中,这种数据分区交叉传输的操作,我们在MapReduce的运行过程中也看到过。
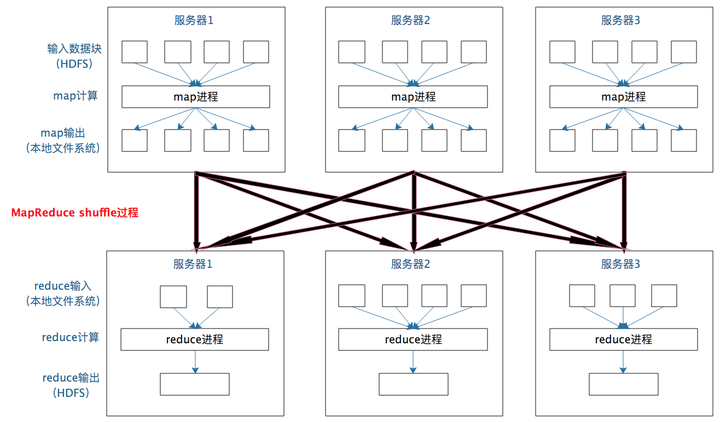
是的,这就是shuffle过程,Spark也需要通过shuffle将数据进行重新组合,相同Key的数据放在一起,进行聚合、关联等操作,因而每次shuffle都产生新的计算阶段。这也是为什么计算阶段会有依赖关系,它需要的数据来源于前面一个或多个计算阶段产生的数据,必须等待前面的阶段执行完毕才能进行shuffle,并得到数据。
计算阶段划分的依据是shuffle,不是转换函数的类型,有的函数有时有shuffle,有时没有。如上图例子中RDD B和RDD F进行join,得到RDD G,这里的RDD F需要进行shuffle,RDD B不需要。
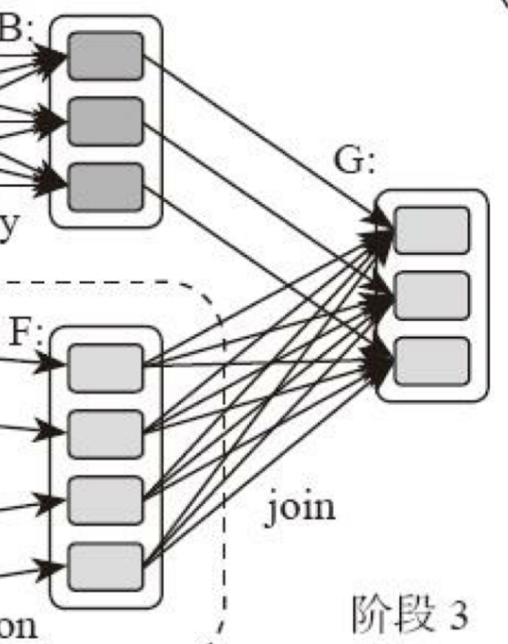
因为RDD B在前面一个阶段,阶段1的shuffle过程中,已进行了数据分区。分区数目和分区K不变,无需再shuffle:
- 这种无需进行shuffle的依赖,在Spark里称作窄依赖
- 需要进行shuffle的依赖,被称作宽依赖
类似MapReduce,shuffle对Spark也很重要,只有通过shuffle,相关数据才能互相计算。
既然都要shuffle,为何Spark就更高效?
本质上看,Spark算是一种MapReduce计算模型的不同实现。Hadoop MapReduce简单粗暴根据shuffle将大数据计算分成Map、Reduce两阶段就完事。但Spark更细,将前一个的Reduce和后一个的Map连接,当作一个阶段持续计算,形成一个更优雅、高效地计算模型,其本质依然是Map、Reduce。但这种多个计算阶段依赖执行的方案可有效减少对HDFS的访问,减少作业的调度执行次数,因此执行速度更快。
不同于Hadoop MapReduce主要使用磁盘存储shuffle过程中的数据,Spark优先使用内存进行数据存储,包括RDD数据。除非内存不够用,否则尽可能使用内存, 这也是Spark性能比Hadoop高的原因。
Spark作业管理
Spark里面的RDD函数有两种:
- 转换函数,调用以后得到的还是一个RDD,RDD的计算逻辑主要通过转换函数完成
- action函数,调用以后不再返回RDD。比如count()函数,返回RDD中数据的元素个数;saveAsTextFile(path),将RDD数据存储到path路径下。Spark的DAGScheduler在遇到shuffle的时候,会生成一个计算阶段,在遇到action函数的时候,会生成一个作业(job)
RDD里面的每个数据分片,Spark都会创建一个计算任务去处理,所以一个计算阶段含多个计算任务(task)。
作业、计算阶段、任务的依赖和时间先后关系:
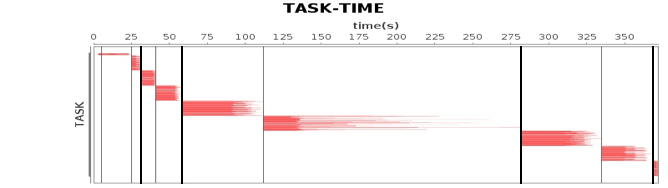
横轴时间,纵轴任务。两条粗黑线之间是一个作业,两条细线之间是一个计算阶段。一个作业至少包含一个计算阶段。水平方向红色的线是任务,每个阶段由很多个任务组成,这些任务组成一个任务集合。
DAGScheduler根据代码生成DAG图后,Spark任务调度就以任务为单位进行分配,将任务分配到分布式集群的不同机器上执行。
Spark执行流程
Spark支持Standalone、Yarn、Mesos、K8s等多种部署方案,原理类似,仅是不同组件的角色命名不同。
Spark cluster components:
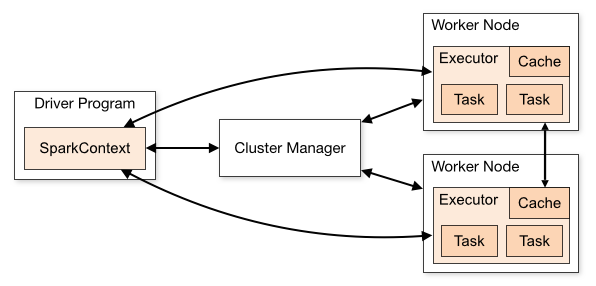
首先,Spark应用程序启动在自己的JVM进程里(Driver进程),启动后调用SparkContext初始化执行配置和输入数据。SparkContext启动DAGScheduler构造执行的DAG图,切分成最小的执行单位-计算任务。
然后,Driver向Cluster Manager请求计算资源,用于DAG的分布式计算。Cluster Manager收到请求后,将Driver的主机地址等信息通知给集群的所有计算节点Worker。
Worker收到信息后,根据Driver的主机地址,跟Driver通信并注册,然后根据自己的空闲资源向Driver通报自己可以领用的任务数。Driver根据DAG图开始向注册的Worker分配任务。
Worker收到任务后,启动Executor进程执行任务。Executor先检查自己是否有Driver的执行代码,若无,从Driver下载执行代码,通过Java反射加载后开始执行。
总结
相比 Mapreduce,Spark的主要特性:
- RDD编程模型更简单
- DAG切分的多阶段计算过程更快
- 使用内存存储中间计算结果更高效
Spark在2012年开始流行,那时内存容量提升和成本降低已经比MapReduce出现的十年前强了一个数量级,Spark优先使用内存的条件已经成熟。
参考
带你了解极具弹性的Spark架构的原理的更多相关文章
- Spark架构与原理这一篇就够了
一.基本介绍 是什么? 快速,通用,可扩展的分布式计算引擎. 弹性分布式数据集RDD RDD(Resilient Distributed Dataset)弹性分布式数据集,是Spark中最基本的数据( ...
- 8款极具表现力的jQuery/CSS3网页菜单
上一篇我向大家分享了7款效果震憾的HTML5应用组件,今天主要来分享一下CSS3网页菜单,因为在一个网站中,菜单起着举足轻重的作用,所以作为WEB开发人员,我们有必要将网站的菜单设计得尽量完美,下面向 ...
- 9款极具创意的HTML5/CSS3进度条动画(免积分下载)
尊重原创,原文地址:http://www.cnblogs.com/html5tricks/p/3622918.html 免积分打包下载地址:http://download.csdn.net/detai ...
- 9款极具创意的HTML5/CSS3进度条动画
今天我们要分享9款极具创意的HTML5/CSS3进度条动画,这些进度条也许可以帮你增强用户交互和提高用户体验,喜欢的朋友就收藏了吧. 1.HTML5/CSS3图片加载进度条 可切换多主题 今天要分享的 ...
- jQuery+css3实现极具创意的罗盘旋转时钟效果源码
效果 HTML代码 <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> < ...
- Spark 架构
本文转之Pivotal的一个工程师的博客.觉得极好. 作者本人经常在StackOverflow上回答一个关系Spark架构的问题,发现整个互联网都没有一篇文章能对Spark总体架构进行很好的描述, ...
- Spark(一): 基本架构及原理
Apache Spark是一个围绕速度.易用性和复杂分析构建的大数据处理框架,最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一,与Hadoop和St ...
- 4.Apache Spark的工作原理
Apache Spark的工作原理 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark ...
- [Spark性能调优] 第一章:性能调优的本质、Spark资源使用原理和调优要点分析
本課主題 大数据性能调优的本质 Spark 性能调优要点分析 Spark 资源使用原理流程 Spark 资源调优最佳实战 Spark 更高性能的算子 引言 我们谈大数据性能调优,到底在谈什么,它的本质 ...
随机推荐
- 【Python 第1课】安装
在Windows系统上安装Python的方法还算简单,比平常装个软件稍稍麻烦一点.进入Python的官方下载页面Python.org/download,你会看到一堆下载链接.我们就选"Pyt ...
- 如何选择 Linux 操作系统版本?
一般来讲,桌面用户首选 Ubuntu :服务器首选 RHEL 或 CentOS ,两者中首选 CentOS .根据具体要求:· 安全性要求较高,则选择 Debian 或者 FreeBSD .· 需要使 ...
- Spring Boot 自动配置原理是什么?
注解 @EnableAutoConfiguration, @Configuration, @ConditionalOnClass 就是自动配置的核心,首先它得是一个配置文件,其次根据类路径下是否有这个 ...
- 使用 rabbitmq 的场景?
(1)服务间异步通信 (2)顺序消费 (3)定时任务 (4)请求削峰
- @Param注解和@Mapper注解
@Param 1.如果dao方法中只有一个参数,入参可以为#{0}或者#{任意单词},也可以使用@Param指定参数名称,sql中就只能#{指定名称}获取参数 public List<Regio ...
- 学习openldap02
III (二十二)OpenLDAP 目录服务: 目录是一类为了浏览和搜索数据而设计的特殊的数据库,目录服务是按照树状形式存储信息,目录包含基于属性的描述性信息,并且支持高级的过滤功能,如microso ...
- My模板设计模式
模板模式 目标: 第一个设计模式:模板模式 步骤: 第一个设计模式:模板模式 讲解: 我们现在使用抽象类设计一个模板模式的应用, 例如在小学的时候,我们经常写作文,通常都是有模板可以套用的. 假如我现 ...
- 攻防世界supersqli
supersqli 补充知识点 rename 命令格式: rename table 原表名 to 新表名 例如,在表myclass名字更改为youclass: mysql>rename tabl ...
- Demo示例——Bundle打包和加载
Unity游戏里面的场景.模型.图片等资源,是如何管理和加载的? 这就是本文要讲的资源管理方式--bundle打包和加载. 图片 Unity游戏资源管理有很多方式: (1)简单游戏比如demo,可以直 ...
- C++ | 虚函数初探
虚函数 虚函数 是在基类中使用关键字 virtual 声明的函数.在派生类中重新定义基类中定义的虚函数时,会告诉编译器不要静态链接到该函数. 我们想要的是在程序中任意点可以根据所调用的对象类型来选择调 ...