3.使用Selenium模拟浏览器抓取淘宝商品美食信息
# 使用selenium+phantomJS模拟浏览器爬取淘宝商品信息
# 思路:
# 第一步:利用selenium驱动浏览器,搜索商品信息,得到商品列表
# 第二步:分析商品页数,驱动浏览器翻页,并得到商品信息
# 第三步:爬取商品信息
# 第四步:存储到mongodb from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from config import *
import re
browser = webdriver.PhantomJS(executable_path='/usr/bin/phantomjs',service_args=SERVICE_ARGS)
# 表示给browser浏览器一个10秒的加载时间
wait = WebDriverWait(browser,) # 使用webdriver打开chrome,打开淘宝页面,搜索美食关键字,返回总页数
def search():
print('正在搜索……')
try:
# 打开淘宝首页
browser.get('http://www.taobao.com') # 判断输入框是否已经加载
input = wait.until(
EC.presence_of_element_located((By.ID,'q'))
)
# < selenium.webdriver.remote.webelement.WebElement(session="d575fc60-91a9-11e8-917b-3dd730d5073d",element=":wdc:1532701944023") > # 判断搜索按钮是否可以进行点击操作
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm > div.search-button > button'))
) # 输入美食
input.send_keys(KEYWORD) # 点击搜索按钮
submit.click() # 使用css_selector找到显示总页面的元素
total = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total'))
)
return total.text
except TimeoutException:
print('超时')
return search() def main():
total = search()
print(total)
total = int(re.compile('(\d+)').search(total).group())
print(total) if __name__ == '__main__':
main()
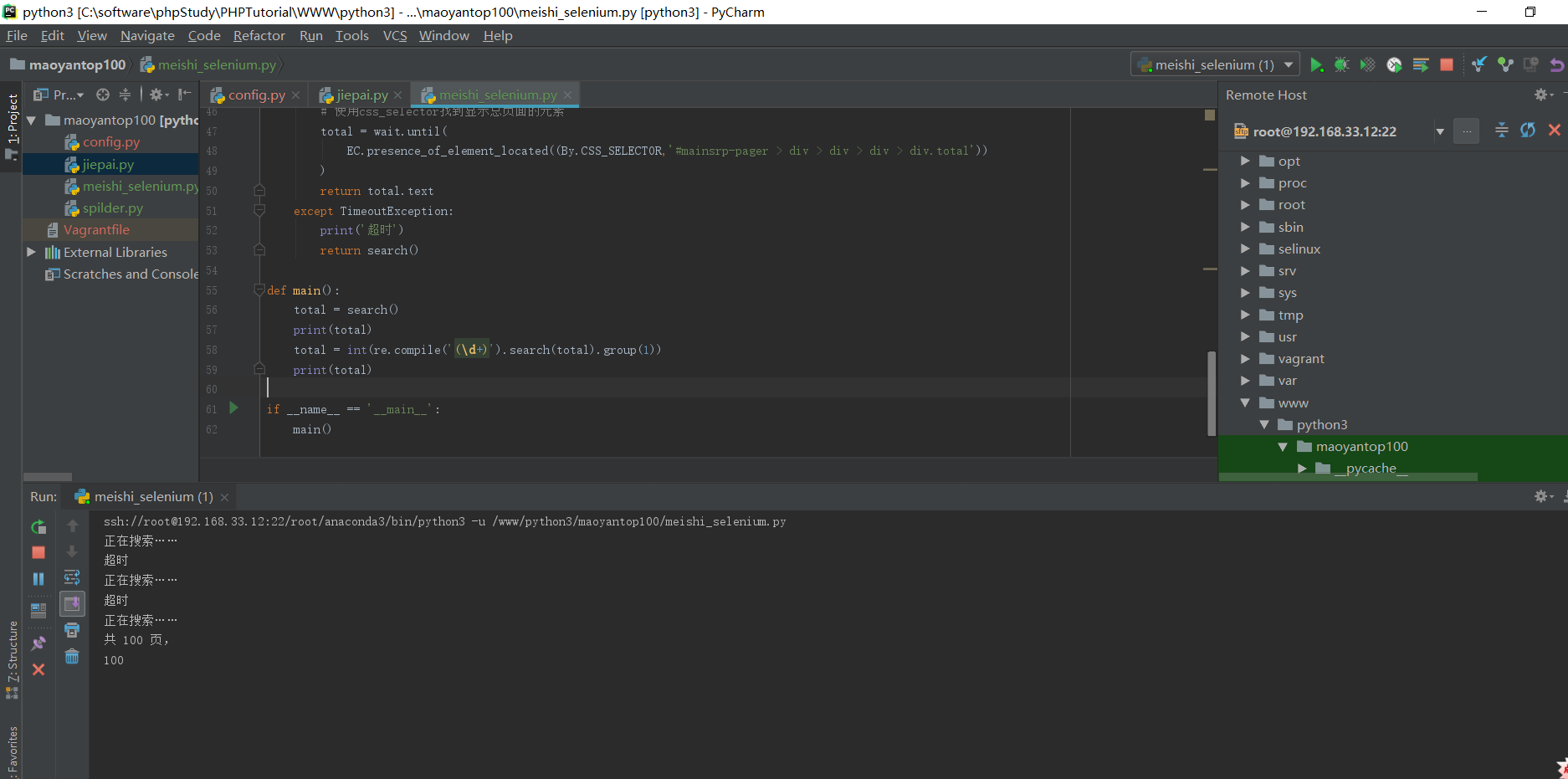
phantomJS爬数据比较慢,下面的测试结果,大概经过5分多钟才返回结果,正在搜索和超时提示返回比较慢
phantojs的其他配置方法:
# 引入配置对象DesiredCapabilities
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities dcap = dict(DesiredCapabilities.PHANTOMJS)
# 从USER_AGENTS列表中随机选一个浏览器头,伪装浏览器
dcap["phantomjs.page.settings.userAgent"] = USER_AGENTS
# 不载入图片,爬页面速度会快很多
dcap["phantomjs.page.settings.loadImages"] = False
# 设置代理
service_args = ['--disk-cache=true','--load-images=false']
# 打开带配置信息的phantomJS浏览器
browser = webdriver.PhantomJS(executable_path='/usr/bin/phantomjs', desired_capabilities=dcap, service_args=service_args)
# 隐式等待5秒,可以自己调节
browser.implicitly_wait()
# 设置10秒页面超时返回,类似于requests.get()的timeout选项,driver.get()没有timeout选项
# 以前遇到过driver.get(url)一直不返回,但也不报错的问题,这时程序会卡住,设置超时选项能解决这个问题。
browser.set_page_load_timeout()
# 设置10秒脚本超时时间
browser.set_script_timeout()
完整代码
# 使用selenium+phantomJS模拟浏览器爬取淘宝商品信息
# 思路:
# 第一步:利用selenium驱动浏览器,搜索商品信息,得到商品列表
# 第二步:分析商品页数,驱动浏览器翻页,并得到商品信息
# 第三步:爬取商品信息
# 第四步:存储到mongodb
from selenium import webdriver
from config import *
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
import re
from pyquery import PyQuery as pq
import pymongo # client = pymongo.MongoClient(MONGO_URL)
client = pymongo.MongoClient(host='192.168.33.12', port=)
db = client[MONGO_DB_SELENIUM] browser = webdriver.PhantomJS(executable_path=EXECUTABLE_PATH,service_args=SERVICE_ARGS)
browser.set_window_size(, ) # 表示给browser浏览器一个10秒的加载时间
wait = WebDriverWait(browser,) # 使用webdriver打开chrome,打开淘宝页面,搜索美食关键字,返回总页数
def search():
print('正在搜索……')
try:
# 打开淘宝首页
browser.get('http://www.taobao.com') # 判断输入框是否已经加载
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#q'))
) # 判断搜索按钮是否可以进行点击操作
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm > div.search-button > button'))
) # 输入美食
input.send_keys(KEYWORD_SELENIUM) # 点击搜索按钮
submit.click() # 使用css_selector找到显示总页面的元素
total = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total'))
) # 获取商品信息
get_products() return total.text
except TimeoutException:
print('超时')
return search() # 跳转到下一页
def next_page(page_number):
try:
# 输入要跳转的页数
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > input"))
) # 确认进行跳转
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit"))
) input.clear()
input.send_keys(page_number)
submit.click() # 判断当前的页数与网页的高亮显示是否对应得上
wait.until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > ul > li.item.active > span"), str(page_number))
) # 获取商品信息
get_products()
except TimeoutException:
next_page(page_number) # 获取商品信息
def get_products():
# 判断商品是否加载成功
wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-itemlist .items .item"))
) # 获取页面信息
html = browser.page_source
# 使用PyQuery来解析html
doc = pq(html)
items = doc("#mainsrp-itemlist .items .item").items()
for item in items:
product = {
# 去掉价格中的换行符
"price": item.find(".price").text().replace("\n", ""),
"image": item.find(".pic .img").attr("src"),
"name": item.find(".title").text(),
"location": item.find(".location").text(),
"shop": item.find(".shop").text(),
}
"""
需要保存的商品信息:
()商品的图片
()商品的价格
()商品的名字
()商品来源
()商品店铺
"""
# print(product)
# {'price': '¥32.80',
# 'image': '//g-search1.alicdn.com/img/bao/uploaded/i4/imgextra/i4/95948676/TB2IdzpcnnI8KJjSszbXXb4KFXa_!!0-saturn_solar.jpg_230x230.jpg',
# 'name': '南萃坊流心蛋黄饼20个800克传统糕点办公室网红零食小吃美食整箱', 'location': '浙江 杭州', 'shop': '南萃坊旗舰店'} save_products(product)
# print("=" * )
# == == == == == == == == == == == == == == == # 将商品的信息存储到MongoDB数据库、txt文件中
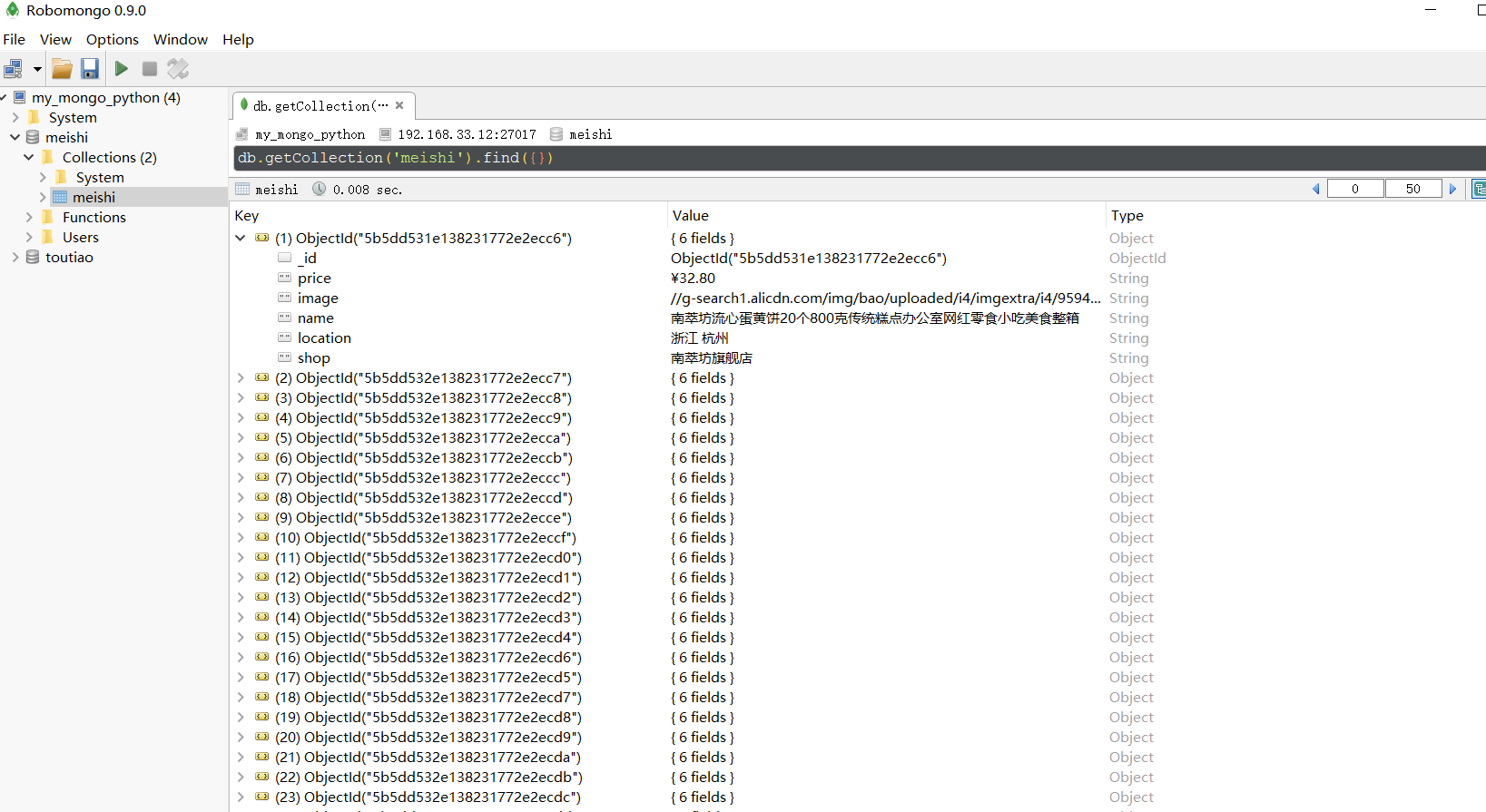
def save_products(result):
try:
# 尝试将结果集插入到数据库中
if db[MONGO_TABLE_SELENIUM].insert(result):
print("存储到MongoDB数据库成功!", result)
# 存储到MongoDB数据库成功! {'price': '¥33.00',
# 'image': '//g-search1.alicdn.com/img/bao/uploaded/i4/i2/110202222/TB2k.9bhcj_B1NjSZFHXXaDWpXa_!!110202222.jpg_230x230.jpg',
# 'name': '陕西特产红星软香酥小吃美食零食礼包早餐糕点豆沙西安网红千层饼', 'location': '陕西 咸阳', 'shop': '红星软香酥专卖',
# '_id': ObjectId('5b5dd570e138231772e2ef5d')}
# == == == == == == == == == == == == == == ==
# {'price': '¥24.90',
# 'image': '//g-search1.alicdn.com/img/bao/uploaded/i4/imgextra/i1/13621870/TB2V3LhX56guuRjy1XdXXaAwpXa_!!0-saturn_solar.jpg_230x230.jpg',
# 'name': '卜珂椰丝球椰蓉球美食早餐糕点心好吃的点心休闲零食品批发店小吃', 'location': '江苏 苏州', 'shop': '卜珂巧克力旗舰店'}
# 存储到MongoDB数据库成功! {'price': '¥24.90',
# 'image': '//g-search1.alicdn.com/img/bao/uploaded/i4/imgextra/i1/13621870/TB2V3LhX56guuRjy1XdXXaAwpXa_!!0-saturn_solar.jpg_230x230.jpg',
# 'name': '卜珂椰丝球椰蓉球美食早餐糕点心好吃的点心休闲零食品批发店小吃', 'location': '江苏 苏州', 'shop': '卜珂巧克力旗舰店',
# '_id': ObjectId('5b5dd575e138231772e2ef5e')}
# == == == == == == == == == == == == == == ==
# 将结果集存储到txt文件中
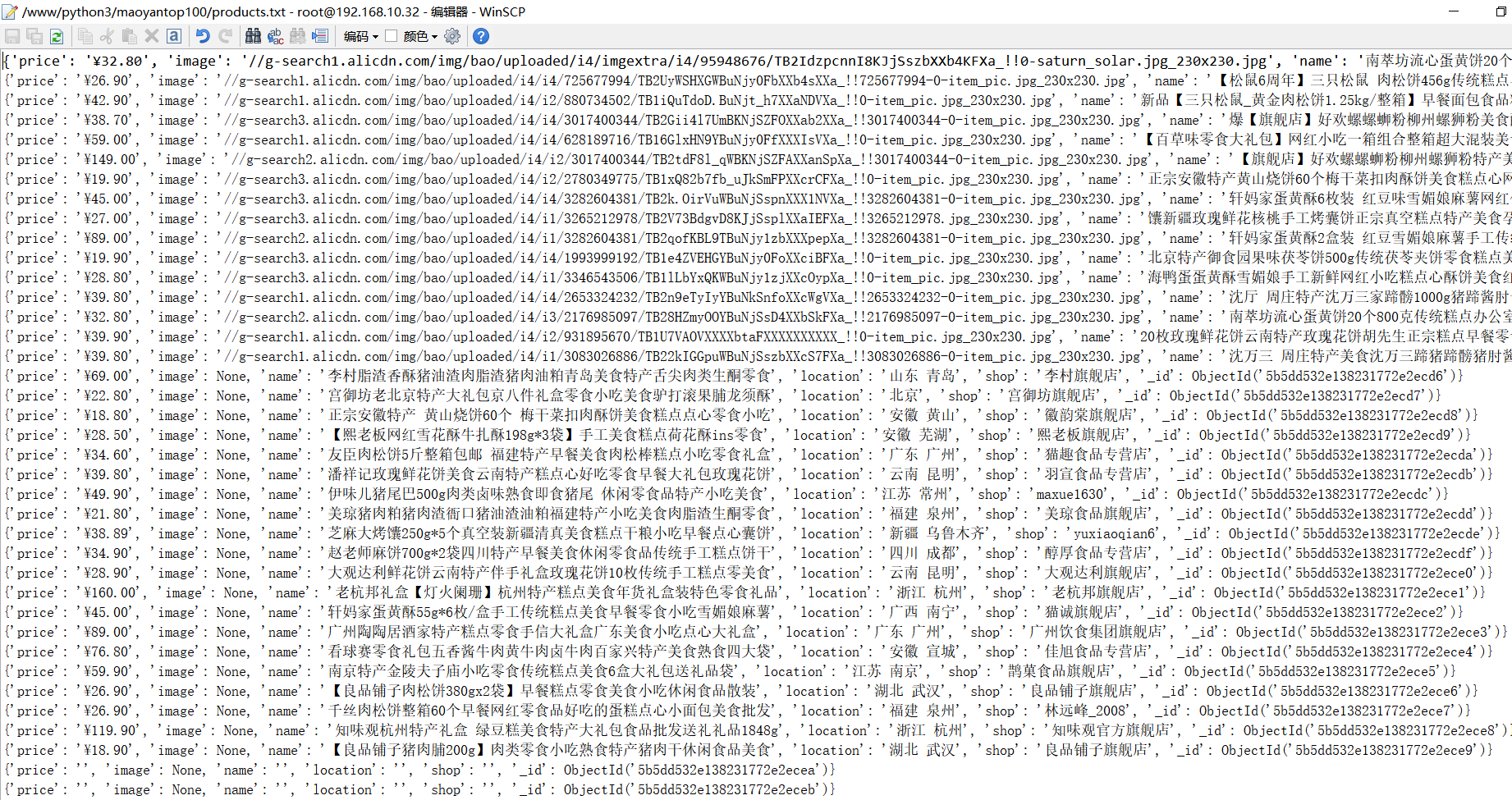
if result:
with open("products.txt", "a", encoding="utf-8") as f:
f.write(str(result) + "\n")
f.close()
except Exception:
print("存储失败!", result) def main():
try:
total = search()
# print(total)
total = int(re.compile('(\d+)').search(total).group())
# print(total) for i in range(, total + ):
next_page(i)
except Exception:
print("出错啦!")
finally:
browser.close() # 最后一定都要关闭浏览器 if __name__ == '__main__':
main()

参考博文:
Selenium分手PhantomJS
盘点selenium phantomJS使用的坑
3.使用Selenium模拟浏览器抓取淘宝商品美食信息的更多相关文章
- Python爬虫学习==>第十二章:使用 Selenium 模拟浏览器抓取淘宝商品美食信息
学习目的: selenium目前版本已经到了3代目,你想加薪,就跟面试官扯这个,你赢了,工资就到位了,加上一个脚本的应用,结局你懂的 正式步骤 需求背景:抓取淘宝美食 Step1:流程分析 搜索关键字 ...
- 16-使用Selenium模拟浏览器抓取淘宝商品美食信息
淘宝由于含有很多请求参数和加密参数,如果直接分析ajax会非常繁琐,selenium自动化测试工具可以驱动浏览器自动完成一些操作,如模拟点击.输入.下拉等,这样我们只需要关心操作而不需要关心后台发生了 ...
- 使用Selenium模拟浏览器抓取淘宝商品美食信息
代码: import re from selenium import webdriver from selenium.webdriver.common.by import By from seleni ...
- 爬虫实战--使用Selenium模拟浏览器抓取淘宝商品美食信息
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.common.exce ...
- 使用selenium模拟浏览器抓取淘宝信息
通过Selenium模拟浏览器抓取淘宝商品美食信息,并存储到MongoDB数据库中. from selenium import webdriver from selenium.common.excep ...
- Selenium模拟浏览器抓取淘宝美食信息
前言: 无意中在网上发现了静觅大神(崔老师),又无意中发现自己硬盘里有静觅大神录制的视频,于是乎看了其中一个,可以说是非常牛逼了,让我这个用urllib,requests用了那么久的小白,体会到sel ...
- Selenium+Chrome/phantomJS模拟浏览器爬取淘宝商品信息
#使用selenium+Carome/phantomJS模拟浏览器爬取淘宝商品信息 # 思路: # 第一步:利用selenium驱动浏览器,搜索商品信息,得到商品列表 # 第二步:分析商品页数,驱动浏 ...
- 关于爬虫的日常复习(10)—— 实战:使用selenium模拟浏览器爬取淘宝美食
- Python开发爬虫之动态网页抓取篇:爬取博客评论数据——通过Selenium模拟浏览器抓取
区别于上篇动态网页抓取,这里介绍另一种方法,即使用浏览器渲染引擎.直接用浏览器在显示网页时解析 HTML.应用 CSS 样式并执行 JavaScript 的语句. 这个方法在爬虫过程中会打开一个浏览器 ...
随机推荐
- 吴裕雄 PYTHON 神经网络——TENSORFLOW 双隐藏层自编码器设计处理MNIST手写数字数据集并使用TENSORBORD描绘神经网络数据2
import os import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data os.envi ...
- 吴裕雄 python 神经网络——TensorFlow图片预处理调整图片
import numpy as np import tensorflow as tf import matplotlib.pyplot as plt def distort_color(image, ...
- contextField 键盘只允许输入数字和小数点,并且现在小数点后位数
- (BOOL)textField:(UITextField *)textField shouldChangeCharactersInRange:(NSRange)range replacementS ...
- C语言:使用递归解决汉诺塔问题。
//汉诺塔:汉诺塔(又称河内塔)问题是源于印度一个古老传说的益智玩具.大梵天创造世界的时候做了三根金刚石柱子,在一根柱子上从下往上按照大小顺序摞着64片黄金圆盘.大梵天命令婆罗门把圆盘从下面开始按大小 ...
- Linux - 常用GUI软件
1. gdebi -- 可以代替Ubuntu software安装软件 2. System monitor -- 监控流量 3. uget -- 下载软件 4. Okular -- pdf reade ...
- 校准产品质量,把控出海航向,腾讯WeTest《2019中国移动游戏质量白皮书》正式开放预约
作者:wetest小编 商业转载请联系腾讯WeTest获得授权,非商业转载请注明出处. 原文链接:https://wetest.qq.com/lab/view/483.html 每当步入一个新的年份, ...
- selenium+python+unittest实现自动化测试(入门篇)
本文主要讲解关于selenium自动化测试框架的入门知识点,教大家如何搭建selenium自动化测试环境,如何用selenium+python+unittest实现web页面的自动化测试,先来看看se ...
- vmware虚拟机linux添加硬盘后先分区再格式化操作方法
先在虚拟机里填加硬盘,如图. 进入linux后台,df-l ,没有显示sdc盘,更切换的是,在fdisk中,却有sdc 看fdisk -l,确实有sdc. 说明sdc还没有分区,也没有格式化,也没有挂 ...
- python 语法-参数注释
python 语法-参数注释 最近碰到的这样的代码: def func(a:"shuoming") -> int: print("函数已运行.") fun ...
- Jmeter_Http默认请求值
1.线程组->配置原件->Http请求默认值 2.作用:几个Http 请求参数都是重复的数据 3.优先级:Http请求默认值和单个Http请求数值,使用单个Http请求数值为主 举例如下: ...