TensorFlow 实例一(一元线性回归)
使用TensorFlow进行算法设计与训练的核心步骤:
- 准备数据
- 构建模型
- 训练模型
- 进行预测
问题描述:
通过人工数据集,随机生成一个近似采样随机分布,使得w = 2.0 ,b= 1,并加入一个噪声,噪声的最大振幅是0.4
过程描述:
人工数据集生成
# 在JUpiter中,使用matplotlib 显示图像需要设置为 inline 模式,否则不会出现图像
%matplotlib inline import matplotlib.pyplot as plt #载入matplotlib
import numpy as np #载入numpy
import tensorflow as tf #载入TensorFlow # 设置随机数种子
np.random.seed()
#直接采用np 生成等差数列的方法,生成100个点,每一个点的取值在 -~ 1之间
x_data = np.linspace(-,,) # y = 2x + 噪声,其中,噪声的维度与x_data一致
y_data = * x_data + 1.0 +np.random.randn(*x_data.shape) * 0.4
#x_data.shape 是一个元组 * 加在变量前,拆分元组利用matplotlib画出生成结果
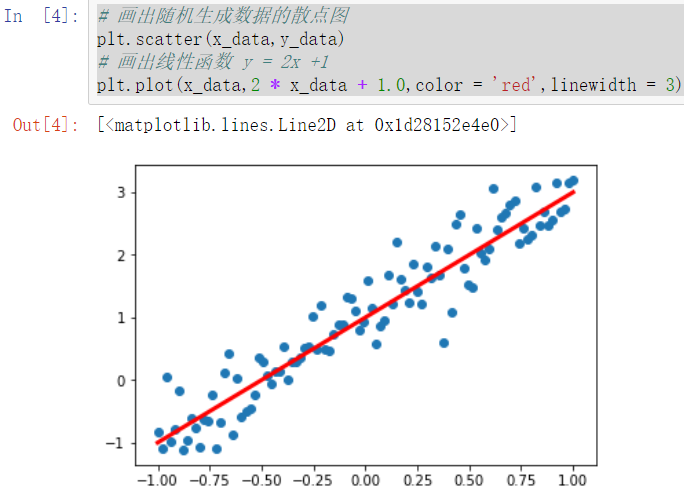
# 画出随机生成数据的散点图
plt.scatter(x_data,y_data) # 画出线性函数 y = 2x +
plt.plot(x_data, * x_data + 1.0,color = 'red',linewidth = )
构建模型
定义训练数据的占位符,x是特征值,y是标签:
定义模型函数:
x = tf.placeholder("float",name = "x")
y = tf.placeholder("float",name = "y")
def model(x,w,b):
return tf.multiply(x,w) + b创建变量:
TensorFlow变量的声明函数是tf.Variable
tf.Variable的作用是保存和更新参数
变量的初始值可以是随机数,常数,或者是通过其他的初始值计算得到的
#构建线性函数的斜率,变量w
w = tf.Variable(2.0,name = "w0")
#构建线性函数的截距,变量b
b = tf.Variable(0.0,name = "b0")
#pred是预测值,向前计算
pred = model(x,w,b)训练模型
设置训练参数:
# 迭代次数(训练次数)
train_epochs =
#学习率
learning_rate = 0.5定义损失函数:
损失函数用于描述预测值与真实值之间的误差,从而指导模型收敛方向
常见损失函数:均方差和交叉熵
# 采样均方差作为损失函数
loss_function = tf.reduce_mean(tf.square(y - pred))定义优化器:
定义优化器Optimizer,初始化一个 GradientDescentOptimizer
设置学习率和优化目标:最小化损失 (每次迭代优化w和b)
# 梯度下降优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function)创建会话:
声明会话:
sess = tf.Session()变量初始化:
在执行前,需将所有的变量初始化,通过 tf.global_variables_initializer() 实现对所有变量初始化
init = tf.global_variables_initializer()
sess.run(init)迭代训练
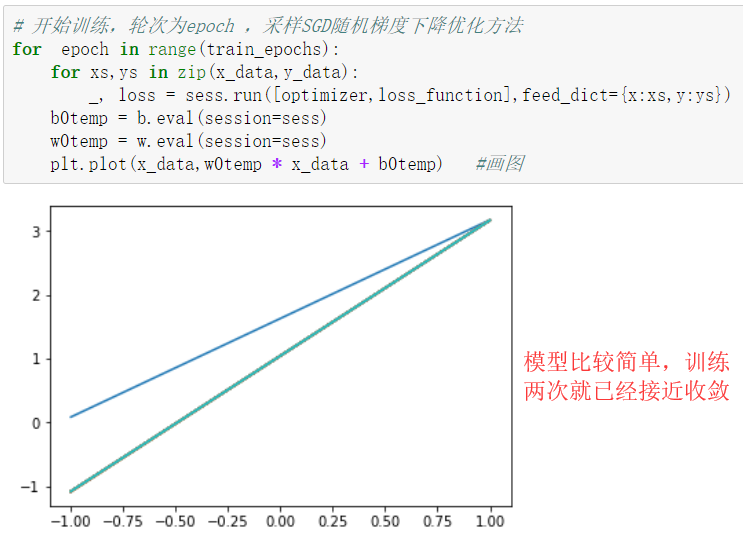
模型训练:设置迭代轮次,每次通过将样本逐个输入模型,进行梯度下降优化操作
每次迭代后,绘制出模型曲线
# 开始训练,轮次为epoch ,采样SGD随机梯度下降优化方法
for epoch in range(train_epochs):
for xs,ys in zip(x_data,y_data):
_, loss = sess.run([optimizer,loss_function],feed_dict={x:xs,y:ys})
b0temp = b.eval(session=sess)
w0temp = w.eval(session=sess)
plt.plot(x_data,w0temp * x_data + b0temp) #画图
打印训练参数
print("w:",sess.run(w)) #w的值应该在2附近
print("b:",sess.run(b)) # b的值应该在1附近
结果可视化
plt.scatter(x_data,y_data,label = 'Original data')
plt.plot(x_data,x_data * sess.run(w) + sess.run(b),label = 'Fitted line',color = 'r',linewidth = )
plt.legend(loc = ) #通过参数loc指定图例位置
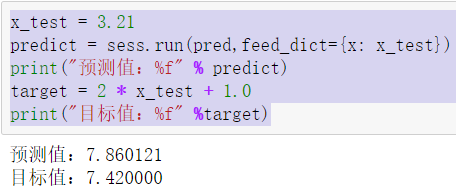
使用训练好的模型进行预测
x_test = 3.21
predict = sess.run(pred,feed_dict={x: x_test})
print("预测值:%f" % predict)
target = * x_test + 1.0
print("目标值:%f" %target)



过程补充
随机梯度下降:在梯度下降法中, 批量指的是用于在单次迭代中计算梯度的样本总数
假定批量是指整个数据集,数据集通常包含很大样本(数万甚至数千亿),
此外, 数据集通常包含多个特征。因此,一个批量可能相当巨大。如果是超
大批量,则单次迭代就可能要花费很长时间进行计算随机梯度下降法 ( SGD) 每次迭代只使用一个样本(批量大小为 1),如果
进行足够的迭代,SGD 也可以发挥作用。“随机”这一术语表示构成各个批
量的一个样本都是随机选择的小批量随机梯度下降法(量 小批量 SGD)是介于全批量迭代与 SGD 之间的折
衷方案。小批量通常包含 10-1000 个随机选择的样本。小批量 SGD 可以减
少 SGD 中的杂乱样本数量,但仍然比全批量更高效在训练中显示损失值:# 在JUpiter中,使用matplotlib 显示图像需要设置为 inline 模式,否则不会出现图像
%matplotlib inline
import matplotlib.pyplot as plt #载入matplotlib
import numpy as np #载入numpy
import tensorflow as tf #载入TensorFlow
# 设置随机数种子
np.random.seed()
#直接采用np 生成等差数列的方法,生成100个点,每一个点的取值在 -~ 1之间
x_data = np.linspace(-,,)
# y = 2x + 噪声,其中,噪声的维度与x_data一致
y_data = * x_data + 1.0 +np.random.randn(*x_data.shape) * 0.4 # 画出随机生成数据的散点图
plt.scatter(x_data,y_data)
# 画出线性函数 y = 2x +
plt.plot(x_data, * x_data + 1.0,color = 'red',linewidth = ) x = tf.placeholder("float",name = "x")
y = tf.placeholder("float",name = "y")
def model(x,w,b):
return tf.multiply(x,w) + b #构建线性函数的斜率,变量w
w = tf.Variable(2.0,name = "w0")
#构建线性函数的截距,变量b
b = tf.Variable(0.0,name = "b0")
#pred是预测值,向前计算
pred = model(x,w,b) # 迭代次数(训练次数)
train_epochs =
#学习率
learning_rate = 0.5
# 采样均方差作为损失函数
loss_function = tf.reduce_mean(tf.square(y - pred)) # 梯度下降优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function)
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init) 43 # 开始训练,轮数为epoch,采用SGD随机梯度下降优化方法
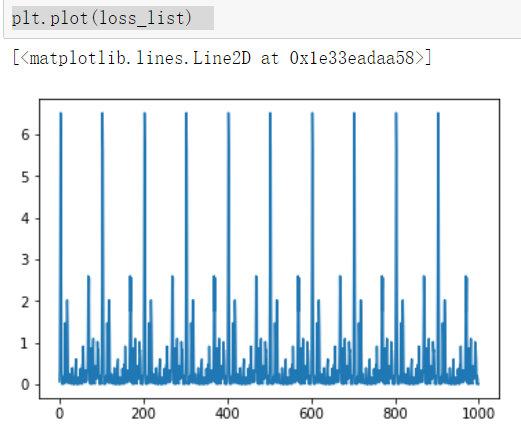
44 step = 0 # 记录训练步数
45 loss_list = [] #用于保存loss值的列表
46 display_step = 10
47 for epoch in range(train_epochs):
48 for xs,ys in zip(x_data,y_data):
49 _,loss = sess.run([optimizer,loss_function],feed_dict={x:xs,y:ys})
50 #显示损失值
51 #display_step :控制报告的粒度
52 #例如:若display_step = 2,则将每训练2个样本输出依次损失粒度,与超参数不同,修改display_step 不会改变模型学习的规律
53 loss_list.append(loss)
54 step = step + 1
55 if step % display_step == 0:
56 print("训练次数:",'%02d' % (epoch + 1),"步数:%03d"%(step),"损失:","{:.9f}".format(loss))
57 b0temp = b.eval(session = sess)
58 w0temp = w.eval(session = sess)
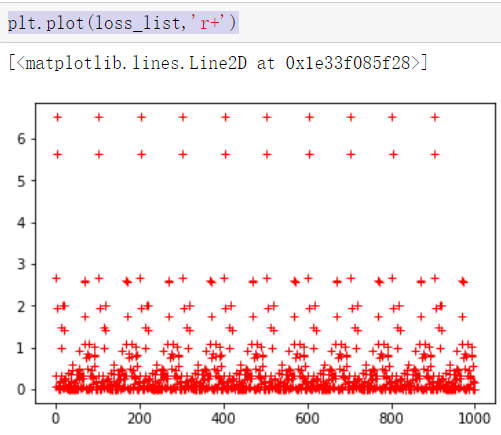
59 plt.plot(x_data,w0temp * x_data +b0temp) #画图 plt.plot(loss_list) #图像化显示损失值plt.plot(loss_list,'r+') #图像化显示损失值
TensorFlow 实例一(一元线性回归)的更多相关文章
- (第一章第六部分)TensorFlow框架之实现线性回归小案例
系列博客链接: (一)TensorFlow框架介绍:https://www.cnblogs.com/kongweisi/p/11038395.html (二)TensorFlow框架之图与Tensor ...
- 回归分析法&一元线性回归操作和解释
用Excel做回归分析的详细步骤 一.什么是回归分析法 "回归分析"是解析"注目变量"和"因于变量"并明确两者关系的统计方法.此时,我们把因 ...
- R语言解读一元线性回归模型
转载自:http://blog.fens.me/r-linear-regression/ 前言 在我们的日常生活中,存在大量的具有相关性的事件,比如大气压和海拔高度,海拔越高大气压强越小:人的身高和体 ...
- 一元线性回归模型与最小二乘法及其C++实现
原文:http://blog.csdn.net/qll125596718/article/details/8248249 监督学习中,如果预测的变量是离散的,我们称其为分类(如决策树,支持向量机等), ...
- R语言 一元线性回归
#一元线性回归的基本步骤#1.载入数据 给出散点图 x<-c(0.10,0.11,0.12,0.13,0.14,0.15,0.16,0.17,0.18,0.20,0.21,0.23) y< ...
- machine learning 之 导论 一元线性回归
整理自Andrew Ng 的 machine learnig 课程 week1. 目录: 什么是机器学习 监督学习 非监督学习 一元线性回归 模型表示 损失函数 梯度下降算法 1.什么是机器学习 Ar ...
- (转)干货|这篇TensorFlow实例教程文章告诉你GANs为何引爆机器学习?(附源码)
干货|这篇TensorFlow实例教程文章告诉你GANs为何引爆机器学习?(附源码) 该博客来源自:https://mp.weixin.qq.com/s?__biz=MzA4NzE1NzYyMw==& ...
- R语言做一元线性回归
只有两个变量,做相关性分析,先来个一元线性回归吧 因为未处理的x,y相关性不显著,于是用了ln(1+x)函数做了个处理(发现大家喜欢用ln,log,lg,指数函数做处理),处理完以后貌似就显著了..虽 ...
- Python实现——一元线性回归(梯度下降法)
2019/3/25 一元线性回归--梯度下降/最小二乘法_又名:一两位小数点的悲剧_ 感觉这个才是真正的重头戏,毕竟前两者都是更倾向于直接使用公式,而不是让计算机一步步去接近真相,而这个梯度下降就不一 ...
- 梯度下降法及一元线性回归的python实现
梯度下降法及一元线性回归的python实现 一.梯度下降法形象解释 设想我们处在一座山的半山腰的位置,现在我们需要找到一条最快的下山路径,请问应该怎么走?根据生活经验,我们会用一种十分贪心的策略,即在 ...
随机推荐
- 前端第四篇---前端基础之jQuery
前端第四篇---前端基础之jQuery 一.jQuery介绍 二.jQuery对象 三.jQuery基础语法 四.事件 五.动画效果 六.补充each 一.jQuery简介 1.jQuery介绍 jQ ...
- Vuex基本介绍
1.什么是Vuex Vuex是一个专为vue.js应用程序开发的状态管理模式. 状态管理:data里面的变量都是vue的状态. 2.为什么要用Vuex 当我们构建一个中大型的单页面应用程序时,Vuex ...
- V-Distpicker不能完整显示内容
V-Distpicker插件在列表中,或者在dialog中只显示了第一次的内容,第二次就开始报错.这个和前篇中的地图问题其实如出一辙. 解决办法,重加载,局部刷新. <el-form-item ...
- 【pwnable.kr】 flag
pwnable从入门到放弃 第四题 Download : http://pwnable.kr/bin/flag 下载下来的二进制文件,对着它一脸懵逼,题目中说是逆向题,这我哪会啊... 用ida打开看 ...
- JS ~ Promise.reject()
概述: Promise.reject(reason)方法返回一个带有拒绝原因reason参数的Promise对象. 语法 Promise.reject(reason); reason : 表示Pro ...
- QF中间件
QF中间件使用说明 QF中间件是在2020年春节期间出现新型冠状病毒感染的肺炎疫情不敢外出,闲来无事编写的.编程是业余爱好,平时编程只会拖控件,中间件可能存在未知Bug,这个版本也只 ...
- SQL中的LEFT/RIGHT/SUBSTRING函数
语法: LEFT(field,length) RIGHT(field,length)SUBSTRING(field,start,length) LEFT/RIGHT函数返回field最左边/最右边的l ...
- n以内的素数
/* 问题描述: 质数又称素数.一个大于1的自然数,除了1和它自身外, 不能被其他自然数整除的数叫做质数: 问题分析: 素数只能被1和自身整除的数.判断一个数是不是素数, 是用2和这个数之间的所有的数 ...
- 201809-1 卖菜 Java
思路: 需要两个数组,一个保存原始数据 import java.util.Scanner; public class Main { public static void main(String[] a ...
- Python __name__="__main__"的作用
该语句加在模块的最后,可以让这个模块,即可以被别人import,又可以直接运行. fibo.py文件: def fibo(): pass # fibo函数的内容 if __name__==" ...