Python 网络爬虫实战:爬取 B站《全职高手》20万条评论数据
本周我们的目标是:B站(哔哩哔哩弹幕网 https://www.bilibili.com )视频评论数据。
我们都知道,B站有很多号称“镇站之宝”的视频,拥有着数量极其恐怖的评论和弹幕。所以这次我们的目标就是,爬取B站视频的评论数据,分析其为何会深受大家喜爱。
首先去调研一下,B站评论数量最多的视频是哪一个。。。好在已经有大佬已经统计过了,我们来看一哈!
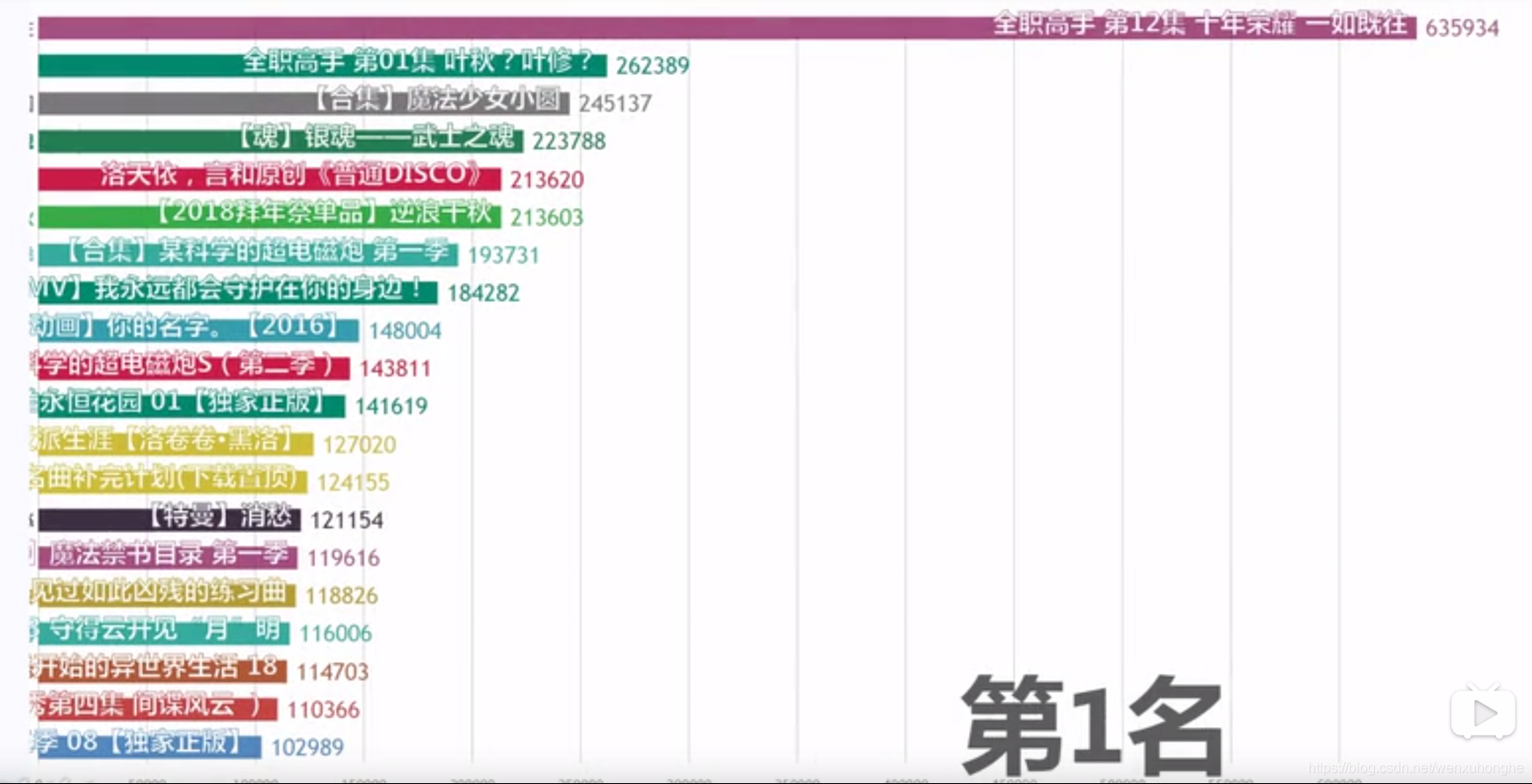 【B站大数据可视化】B站评论数最多的视频究竟是?来自 <https://www.bilibili.com/video/av34900167/>
【B站大数据可视化】B站评论数最多的视频究竟是?来自 <https://www.bilibili.com/video/av34900167/>嗯?《全职高手》,有点意思,第一集和最后一集分别占据了评论数量排行榜的第二名和第一名,远超了其他很多很火的番。那好,就拿它下手吧,看看它到底强在哪儿。
废话不多说,先去B站看看这部神剧到底有多好看 https://www.bilibili.com/bangumi/play/ep107656
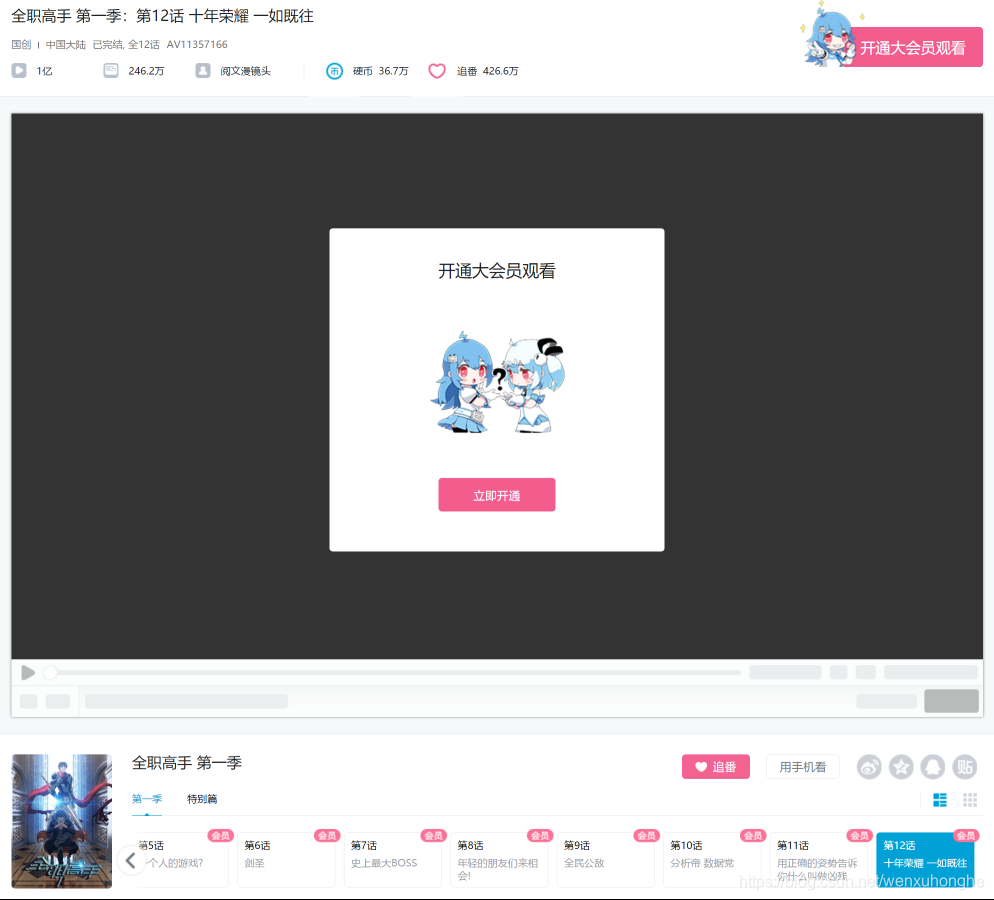
额,需要开通大会员才能观看。。。
好吧,不看就不看,不过好在虽然视频看不了,评论却是可以看的。
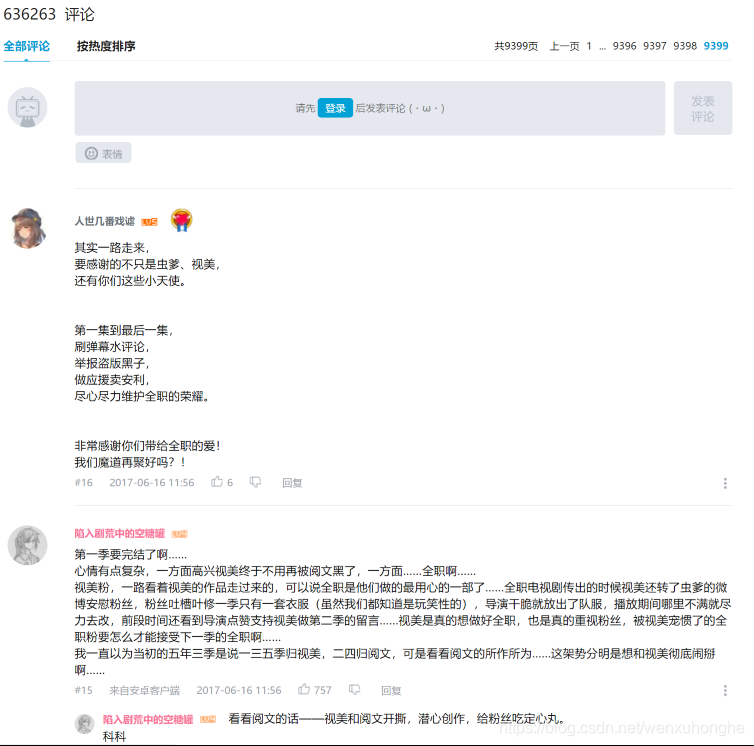
感受到它的恐怖了吗?63w6条的评论!9千多页!果然是不同凡响啊。
接下来,我们就开始编写爬虫,爬取这些数据吧。
使用爬虫爬取网页一般分为四个阶段:分析目标网页,获取网页内容,提取关键信息,输出保存。
1. 分析目标网页
首先观察评论区结构,发现评论区为鼠标点击翻页形式,共 9399 页,每一页有 20 条评论,每条评论中包含 用户名、评论内容、评论楼层、时间日期、点赞数等信息展示。
接着我们按 F12 召唤出开发者工具,切换到Network。然后用鼠标点击评论翻页,观察这个过程有什么变化,并以此来制定我们的爬取策略。
我们不难发现,整个过程中 URL 不变,说明评论区翻页不是通过 URL 控制。而在每翻一页的时候,网页会向服务器发出这样的请求(请看 Request URL)。
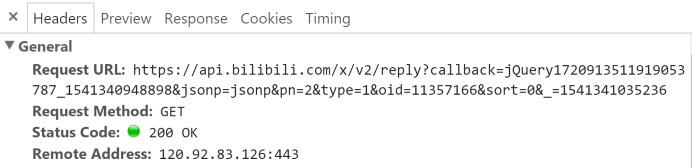
点击 Preview 栏,可以切换到预览页面,也就是说,可以看到这个请求返回的结果是什么。下面是该请求返回的 json 文件,包含了在 replies 里包含了本页的评论数据。在这个 json 文件里,我们可以发现,这里面包含了太多的信息,除了网页上展示的信息,还有很多没展示出来的信息也有,简直是挖到宝了。不过,我们这里用不到,通通忽略掉,只挑我们关注的部分就好了。

2. 获取网页内容
网页内容分析完毕,可以正式写代码爬了。
import requests def fetchURL(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:
url :目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
} try:
r = requests.get(url,headers=headers)
r.raise_for_status()
print(r.url)
return r.text
except requests.HTTPError as e:
print(e)
print("HTTPError")
except requests.RequestException as e:
print(e)
except:
print("Unknown Error !") if __name__ == '__main__':
url = 'https://api.bilibili.com/x/v2/reply?callback=jQuery172020326544171595695_1541502273311&jsonp=jsonp&pn=2&type=1&oid=11357166&sort=0&_=1541502312050'
html = fetchURL(url)
print(html)
![]()
不过,在运行过后,你会发现,403 错误,服务器拒绝了我们的访问。
运行结果:
403 Client Error: Forbidden for url: https://api.bilibili.com/x/v2/reply?callback=jQuery172020326544171595695_1541502273311&jsonp=jsonp&pn=2&type=1&oid=11357166&sort=0&_=1541502312050
HTTPError
None
![]()
同样的,这个请求放浏览器地址栏里面直接打开,会变403,什么也访问不到。

这是我们本次爬虫遇到的第一个坑。在浏览器中能正常返回响应,但是直接打开请求链接时,却会被服务器拒绝。(我第一反应是 cookie ,将浏览器中的 cookie 放入爬虫的请求头中,重新访问,发现没用),或许这也算是一个小的反爬虫机制吧。
网上查阅资料之后,我找到了解决的方法(虽然不了解原理),原请求的 URL 参数如下:
callback = jQuery1720913511919053787_1541340948898
jsonp = jsonp
pn = 2
type = 1
oid = 11357166&sort=0
_ = 1541341035236
![]()
其中,真正有用的参数只有三个:pn(页数),type(=1)和oid(视频id)。删除其余不必要的参数之后,用新整理出的url去访问,成功获取到评论数据。
https://api.bilibili.com/x/v2/reply?type=1&oid=11357166&pn=2
![]()

![]()
然后,在主函数中,通过写一个 for 循环,通过改变 pn 的值,获取每一页的评论数据。
if __name__ == '__main__':
for page in range(0,9400):
url = 'https://api.bilibili.com/x/v2/reply?type=1&oid=11357166&pn=' + str(page)
html = fetchURL(url)
3. 提取关键信息
通过 json 库对获取到的响应内容进行解析,然后提取我们需要的内容:楼层,用户名,性别,时间,评价,点赞数,回复数。
import json
import time def parserHtml(html):
'''
功能:根据参数 html 给定的内存型 HTML 文件,尝试解析其结构,获取所需内容
参数:
html:类似文件的内存 HTML 文本对象
'''
s = json.loads(html) for i in range(20):
comment = s['data']['replies'][i] # 楼层,用户名,性别,时间,评价,点赞数,回复数
floor = comment['floor']
username = comment['member']['uname']
sex = comment['member']['sex']
ctime = time.strftime("%Y-%m-%d %H:%M:%S",time.localtime(comment['ctime']))
content = comment['content']['message']
likes = comment['like']
rcounts = comment['rcount'] print('--'+str(floor) + ':' + username + '('+sex+')' + ':'+ctime)
print(content)
print('like : '+ str(likes) + ' ' + 'replies : ' + str(rcounts))
print(' ')
部分运行结果如下:--204187:day可可铃(保密):2018-11-05 18:16:22
太太又出本了,这次真的木钱了(´;ω;`)
like : 1 replies : 0 --204186:长夜未央233(女):2018-11-05 16:24:52
12区打卡
like : 2 replies : 0 --204185:果然还是人渣一枚(男):2018-11-05 13:48:09
貌似忘来了好几天
like : 1 replies : 1 --204183:day可可铃(保密):2018-11-05 13:12:38
要准备去学校了,万恶的期中考试( ´_ゝ`)
like : 2 replies : 0 --204182:拾秋以叶(保密):2018-11-05 12:04:19
11月5日打卡( ̄▽ ̄)
like : 1 replies : 0 --204181:芝米士哒(女):2018-11-05 07:53:43
这次是真的错过了一个亿[蛆音娘_扶额]
like : 2 replies : 1
4. 保存输出
我们把这些数据以 csv 的格式保存于本地,即完成了本次爬虫的全部任务。下面附上爬虫的全部代码。
import requests
import json
import time def fetchURL(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:
url :目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
} try:
r = requests.get(url,headers=headers)
r.raise_for_status()
print(r.url)
return r.text
except requests.HTTPError as e:
print(e)
print("HTTPError")
except requests.RequestException as e:
print(e)
except:
print("Unknown Error !") def parserHtml(html):
'''
功能:根据参数 html 给定的内存型 HTML 文件,尝试解析其结构,获取所需内容
参数:
html:类似文件的内存 HTML 文本对象
'''
try:
s = json.loads(html)
except:
print('error') commentlist = []
hlist = [] hlist.append("序号")
hlist.append("名字")
hlist.append("性别")
hlist.append("时间")
hlist.append("评论")
hlist.append("点赞数")
hlist.append("回复数") #commentlist.append(hlist) # 楼层,用户名,性别,时间,评价,点赞数,回复数
for i in range(20):
comment = s['data']['replies'][i]
blist = [] floor = comment['floor']
username = comment['member']['uname']
sex = comment['member']['sex']
ctime = time.strftime("%Y-%m-%d %H:%M:%S",time.localtime(comment['ctime']))
content = comment['content']['message']
likes = comment['like']
rcounts = comment['rcount'] blist.append(floor)
blist.append(username)
blist.append(sex)
blist.append(ctime)
blist.append(content)
blist.append(likes)
blist.append(rcounts) commentlist.append(blist) writePage(commentlist)
print('---'*20) def writePage(urating):
'''
Function : To write the content of html into a local file
html : The response content
filename : the local filename to be used stored the response
''' import pandas as pd
dataframe = pd.DataFrame(urating)
dataframe.to_csv('Bilibili_comment5-1000条.csv', mode='a', index=False, sep=',', header=False) if __name__ == '__main__':
for page in range(0,9400):
url = 'https://api.bilibili.com/x/v2/reply?type=1&oid=11357166&pn=' + str(page)
html = fetchURL(url)
parserHtml(html) # 为了降低被封ip的风险,每爬20页便歇5秒。
if page%20 == 0:
time.sleep(5)
写在最后
在爬取过程中,还是遇到了很多的小坑的。
1. 请求的 url 不能直接用,需要对参数进行筛选整理后才能访问。
2. 爬取过程其实并不顺利,因为如果爬取期间如果有用户发表评论,则请求返回的响应会为空导致程序出错。所以在实际爬取过程中,记录爬取的位置,以便出错之后从该位置继续爬。(并且,挑选深夜一两点这种发帖人数少的时间段,可以极大程度的减少程序出错的机率)
3. 爬取到的数据有多处不一致,其实这个不算是坑,不过这里还是讲一下,免得产生困惑。
a. 就是评论区楼层只到了20多万,但是评论数量却有63万多条,这个不一致主要是由于B站的评论是可以回复的,回复的评论也会计算到总评论数里。我们这里只爬楼层的评论,而评论的回复则忽略,只统计回复数即可。
b. 评论区楼层在20万条左右,但是我们最后爬取下来的数据只有18万条左右,反复检查爬虫程序及原网站后发现,这个属于正常现象,因为有删评论的情况,评论删除之后,后面的楼层并不会重新排序,而是就这样把删掉的那层空下了。导致楼层数和评论数不一致。
如果文章中有哪里没有讲明白,或者讲解有误的地方,欢迎在评论区批评指正,或者扫描下面的二维码,加我微信,大家一起学习交流,共同进步。

Python 网络爬虫实战:爬取 B站《全职高手》20万条评论数据的更多相关文章
- python网络爬虫《爬取get请求的页面数据》
一.urllib库 urllib是python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在python3中的为urllib.request和urllib. ...
- python网络爬虫--简单爬取糗事百科
刚开始学习python爬虫,写了一个简单python程序爬取糗事百科. 具体步骤是这样的:首先查看糗事百科的url:http://www.qiushibaike.com/8hr/page/2/?s=4 ...
- Python网络爬虫 | Scrapy爬取妹子图网站全站照片
根据现有的知识,写了一个下载妹子图(meizitu.com)Scrapy脚本,把全站两万多张照片下载到了本地. 网站的分析 网页的网址分析 打开网站,发现网页的网址都是以 http://www.mei ...
- Python网络爬虫_爬取Ajax动态加载和翻页时url不变的网页
1 . 什么是 AJAX ? AJAX = 异步 JavaScript 和 XML. AJAX 是一种用于创建快速动态网页的技术. 通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新 ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- python网络爬虫实战PDF高清完整版免费下载|百度云盘|Python基础教程免费电子书
点击获取提取码:vg1y python网络爬虫实战帮助读者学习Python并开发出符合自己要求的网络爬虫.网络爬虫,又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取互联网信息的程序或者脚 ...
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- 第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解 封装模块 #!/usr/bin/env python # -*- coding: utf- ...
- 关于Python网络爬虫实战笔记③
Python网络爬虫实战笔记③如何下载韩寒博客文章 Python网络爬虫实战笔记③如何下载韩寒博客文章 target:下载全部的文章 1. 博客列表页面规则 也就是, http://blog.sina ...
随机推荐
- [Objective-C] 021 KVC、KVO
写过C#的都知道C#通过反射读写一个对象的属性特别方便,可以利用字符串的方式去动态控制一个对象.其实在ObjC中,我们可以更高级点,根本不必进行任何操作就可以进行属性的动态读写,这种方式就是Key V ...
- 微信小程序支付(企业支付给用户零钱)
内容摘要:本案例客户端支付方式为微信小程序支付(JSAPI).商户运营一段时间后,在微信商户平台开通企业支付服务后,即可调用微信支付提供的企业付款接口将佣金等金额通过微信零钱返现给C端用户零钱. 服务 ...
- sqlmap中文手册
Sqlmap中文手册 -Darren制作 零.前言 Sqlmap是十分著名的.自动化的SQL注入工具.为了较为系统地学习Sqlmap,我决定翻译一遍Sqlmap的用户手册,于是便有了此文.由于我英语 ...
- 【HIVE】(2)分区表、二级分区、动态分区、分桶、抽样
分区表: 建表语句中添加:partitioned by (col1 string, col2 string) create table emp_pt(id int, name string, job ...
- Java实现 LeetCode 212 单词搜索 II(二)
212. 单词搜索 II 给定一个二维网格 board 和一个字典中的单词列表 words,找出所有同时在二维网格和字典中出现的单词. 单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中&quo ...
- Java实现 蓝桥杯VIP 算法提高 贪吃的大嘴
算法提高 贪吃的大嘴 时间限制:1.0s 内存限制:256.0MB 问题描述 有一只特别贪吃的大嘴,她很喜欢吃一种小蛋糕,而每一个小蛋糕有一个美味度,而大嘴是很傲娇的,一定要吃美味度和刚好为m的小蛋糕 ...
- Java实现 洛谷 P1280 尼克的任务
import java.util.Scanner; public class Main { public static class edg{ private int to; private int n ...
- java实现第六届蓝桥杯循环节长度
循环节长度 两个整数做除法,有时会产生循环小数,其循环部分称为:循环节. 比如,11/13=6=>0.846153846153..... 其循环节为[846153] 共有6位. 下面的方法,可以 ...
- Linux RPM命令查询
查看包是否安装 rpm -q 包名,其中,-q 表示查询 rpm -qa 表示查询所有已经安装的rpm包,a 表示所有 查询软件包详细信息 rpm -qi 包名,其中,-i 表示查询软件信息,-p 表 ...
- App自动化测试框架学习探索--从零开始设计
App自动化测试框架学习探索--从零开始设计---持续更新中,敬请关注 1 批量执行app自动化测试使用多线程设计思路: 1)并发级别选择用methods 2)采用@Test多线程,数据提供类dp单线 ...