python运用 - log信息提取(知识: 遍历 | os )
运用到的python知识点:
excel相关:https://www.cnblogs.com/yaner2018/p/11269873.html
字典:
python字典的几种方式:
1)key值遍历
d = {'a': '', 'b': '', 'c': ''}
for k in d:
print(k+':'+d[k])
print('------------')
for k in d.keys():
print(k+':'+d[k])
key值遍历
a:1
b:2
c:3
------------
a:1
b:2
c:3
运行结果
for k in d: 与 for k in d.keys(): 完全等价
2)value遍历
d = {'a': '', 'b': '', 'c': ''}
for v in d.values():
print(v)
运行结果
1
2
3
value遍历
3)遍历字典项
d = {'a': '', 'b': '', 'c': ''}
for kv in d.items():
print(kv)
运行结果
('a', '')
('b', '')
('c', '')
字典项遍历
4)字典键、值 遍历
d = {'a': '', 'b': '', 'c': ''}
for (k,v) in d.items():
print(k,':',v)
print('----------')
for k,v in d.items():
print(k,':',v)
运行结果
a : 1
b : 2
c : 3
----------
a : 1
b : 2
c : 3
字典键、值遍历
for (k,v) in d.items(): 根据运行结果可见,k,v是否加括号是一样的
os模块:
os.getcwd():查看当前所在路径。
os.listdir(path):列举目录下的所有文件。返回的是列表类型
os.path.abspath(path):返回path的绝对路径。
os.path.split(path):将路径分解为(文件夹,文件名),返回的是元组类型
os.path.join(path1,path2,...):将path进行组合,若其中有绝对路径,则之前的path将被删除
os.path.dirname(path):返回path中的文件夹部分,结果不包含'\'
os.path.basename(path):返回path中的文件名
os.path.getmtime(path):文件或文件夹的最后修改时间,从新纪元到访问时的秒数
os.path.getatime(path):文件或文件夹的最后访问时间,从新纪元到访问时的秒数
os.path.getctime(path):文件或文件夹的创建时间,从新纪元到访问时的秒数
os.path.getsize(path):文件或文件夹的大小,若是文件夹返回0
os.path.exists(path):文件或文件夹是否存在,返回True 或 False
os.path.isfile(path):该目录是否为一个文件,返回True 或 False
os.path.isdir(path):该目录是否为一个文件夹,返回True 或 False
其他:
strip():去空格
split():分隔
slice:切片
def testpath():
print(__file__)#获取当前文件的全目录
print(sys.argv[0])#获取当前文件的全目录
print(os.curdir)#. print(os.getcwd())#获取当前工作目录路径
print(os.path.abspath('.')) #获取当前工作目录路径
print(os.path.abspath(os.curdir)) #获取当前工作目录路径 print(os.path.abspath('test.txt')) #获取当前目录文件下的工作目录路径 print(os.path.abspath('..')) #获取当前工作的父目录 !注意是父目录路径
#os.chdir(path) if __name__ == '__main__':
testpath() '''
F:\Android\workspace\Demo\src\Func.py
F:\Android\workspace\Demo\src\Func.py
.
F:\Android\workspace\Demo\src
F:\Android\workspace\Demo\src
F:\Android\workspace\Demo\src
F:\Android\workspace\Demo\src\test.txt
F:\Android\workspace\Demo '''
Func.py
-----------------------------------------------------------------------
案列:
log:
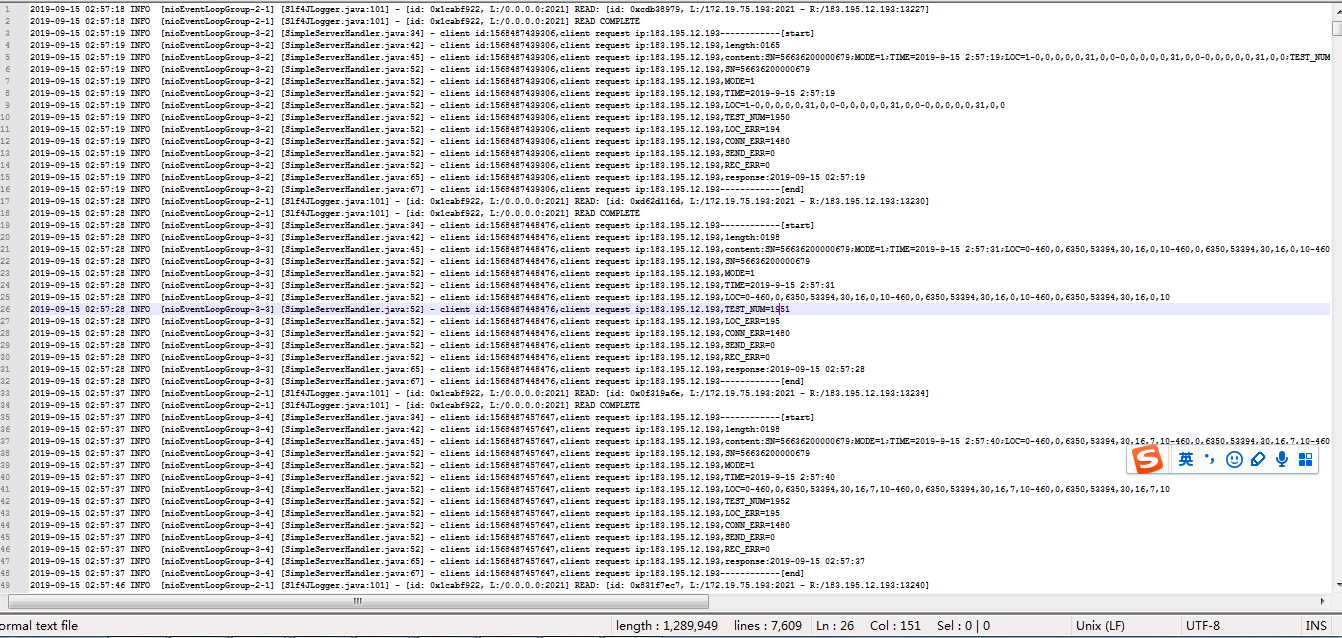
从以上大篇幅的log中提取出如下信息:
sn,mode,time 相同的只统计一次,loc统计不重复的位置
content:SN=56636200000686;MODE=0;TIME=2019-9-18 8:58:39;LOC=0-460,0,6338,20935,8,31,0,24-460,0,6338,20935,8,31,0,24-460,0,6338,20935,8,31,0,24;TEST_NUM=248;LOC_ERR=26;CONN_ERR=10;SEND_ERR=2;REC_ERR=0
#coding=utf-8
'''
Created on 2019年9月17日 @author: yanerfree
'''
import re
import xlrd
from xlutils.copy import copy
import os
#import shutil class recorder():
def __init__(self,sn,mode,dat):
self.sn = sn
self.mode = mode
self.dat = dat#日期
self.loc = []
self.test_num = 0
self.loc_err = 0
self.conn_err = 0
self.send_err = 0
self.rec_err = 0 def updateInfo(self,str):
print('------更新条目信息------')
pattern_2 = re.compile('content:SN=(.*?);MODE=(.*?);TIME=(.*?) .*?LOC=(.*?);TEST_NUM=(.*?);LOC_ERR=(.*?);CONN_ERR=(.*?);SEND_ERR=(.*?);REC_ERR=(\d*)' ,re.S)
res = re.findall(pattern_2, str)[0]
print('res:',res)
#将loc不同的收集起来
loclist = res[3].split(',')
loc34 = '['+loclist[2]+','+loclist[3]+']'
print('loc34:',loc34)
if loc34 not in self.loc:
#print('loc34:',loc34)
self.loc.append(loc34) if int(res[4]) > self.test_num:#此处必须将字符类型转换成整数类型进行比较
self.test_num = int(res[4])
self.loc_err = int(res[5])
self.conn_err = int(res[6])
self.send_err = int(res[7])
self.rec_err = int(res[8]) def setInfo(self,str):
print('创建新条目:',str)
pattern_2 = re.compile('content:SN=(.*?);MODE=(.*?);TIME=(.*?) .*?LOC=(.*?);TEST_NUM=(.*?);LOC_ERR=(.*?);CONN_ERR=(.*?);SEND_ERR=(.*?);REC_ERR=(\d*)' ,re.S)
res = re.findall(pattern_2, str)[0]
loclist = res[3].split(',')
print('loclist:',loclist)
loc34 = '['+loclist[2]+','+loclist[3]+']'
print('loc34:',loc34)
self.loc= [loc34]
self.test_num = int(res[4])
self.loc_err = int(res[5])
self.conn_err = int(res[6])
self.send_err = int(res[7])
self.rec_err = int(res[8]) def washdata(filepath,pattern):
f = open(filepath,'r',encoding='utf-8')
cls_dic = {}#class对象 line = f.readline().strip()#去空格、换行
while line:
#print('line:',line)
res=re.findall(pattern,line)
#print('res:',res)
#print('len(res):',len(res)) if len(res) == 1:
info_list = re.findall(pattern_1,res[0])[0]
print('info_list:',info_list)
sn = info_list[0]
mode = info_list[1]
dat = info_list[2]
flag = 0#该对象是否已经创建,1是已创建,直接更新信息即可
for key,cls in cls_dic.items():
if cls.dat == dat and cls.sn == sn and cls.mode == mode:
cls.updateInfo(res[0])
flag = 1
if flag == 0:
#新建一个class
cls_name = 'record'+str(len(cls_dic))
cls_dic[cls_name] = recorder(sn,mode,dat)
cls_dic[cls_name].setInfo(res[0]) line = f.readline() f.close()
return cls_dic #对单个文件操作
def writetoexcel(cls_dic,savefilename):
print('------将数据写到excel中------')
#遍历cls_dic
workbook1 = xlrd.open_workbook(savefilename)
rows = workbook1.sheet_by_index(0).nrows
workbook2 = copy(workbook1)#拷贝一份原来的excel
#根据名字获取指定sheet页
sheet=workbook2.get_sheet('Sheet1')
row = rows
print('excel中已有数据%d行'%rows) for k,c in cls_dic.items():
sheet.write(row, 0, c.dat)
sheet.write(row, 1, c.sn)
sheet.write(row, 2, c.mode)
sheet.write(row, 3, c.loc)
sheet.write(row, 4, c.test_num)
sheet.write(row, 5, c.loc_err)
sheet.write(row, 6, c.conn_err)
sheet.write(row, 7, c.send_err)
sheet.write(row, 8, c.rec_err) row += 1 workbook2.save(savefilename) #对多个文件操作
def traverse(filepath,savefilename):
list = os.listdir(filepath)
for i in range(0,len(list)):
#print list[i]
tmp_path = os.path.join(filepath,list[i])
#print tmp_path
if os.path.isfile(tmp_path):
if tmp_path[-4:] == ".txt":
print('需要抓取信息的文件为 :',tmp_path)
cls_dic = washdata(tmp_path,pattern)
writetoexcel(cls_dic,savefilename)
else:
traverse(tmp_path,savefilename) savefilename = './result.xls'
pattern = re.compile('(content:SN=.*?;REC_ERR=\d*)' ,re.S)
pattern_1 = re.compile('content:SN=(.*?);MODE=(.*?);TIME=(.*?) .*?LOC=(.*?);TEST_NUM=(.*?);LOC_ERR=(.*?);CONN_ERR=(.*?);SEND_ERR=(.*?);REC_ERR=(\d*)' ,re.S) if __name__ == '__main__':
'''
#suite for single file
cls_dic = washdata(filepath,pattern)
writetoexcel(cls_dic,savefilename)
'''
#suite for more than one file
filepath = r'F:\02_testcase\log_P6_test'
savefilename = './result.xls'
traverse(filepath,savefilename) print('------End------')
extractInfo
上一版存在的问题:sn,mode,time 相同的只统计一次,但是代码每次遍历一个文件就创建一个dic保存信息并写入到excel中,那么同样的sn,mode,time在多个文件中出现的话,就会存在统计了多次的情况
所以升级版主要为解决上述问题,并引入logging模块,将log打印到文件中便于查看,控制台打印的log有限
#coding=utf-8
'''
Created on 2019年9月19日 @author: yanerfree 该版本对前一版升级,修复不同文件中的sn,mode,dat相同的情况下,收集了多个条目,应该是统计到一个条目中
所以此次通过全局变量dic保存需要的信息,将所有的文件遍历完之后,再写入到excel中 '''
import re
import xlrd
from xlutils.copy import copy
import os
from log_config import *
#import shutil class recorder():
def __init__(self,sn,mode,dat):
self.sn = sn
self.mode = mode
self.dat = dat#日期
self.loc = []
self.test_num = 0
self.loc_err = 0
self.net_err = 0
self.conn_err = 0
self.send_err = 0
self.rec_err = 0
self.signal = [] def updateInfo(self,str):
logger.info('------更新条目信息------')
logger.info('更新条目:%s'%str)
res = re.findall(pattern_1, str)[0]
logger.info('res:')
logger.info(res)
#将loc不同的收集起来
loclist = res[3].split('-')[1].split(',')
loc234 = '['+loclist[1]+','+loclist[2]+','+loclist[3]+']'
#print('loc234:',loc234)
if loc234 not in self.loc:
#print('loc34:',loc34)
self.loc.append(loc234)
if (res[10]+',') not in self.signal:
self.signal.append(res[10]+',') if int(res[4]) > self.test_num:#此处必须将字符类型转换成整数类型进行比较
self.test_num = int(res[4])
self.loc_err = int(res[5])
self.net_err = int(res[6])
self.conn_err = int(res[7])
self.send_err = int(res[8])
self.rec_err = int(res[9]) def setInfo(self,str):
logger.info('创建新条目:%s'%str)
res = re.findall(pattern_1, str)[0]
loclist = res[3].split('-')[1].split(',')
loc234 = '['+loclist[1]+','+loclist[2]+','+loclist[3]+']'
logger.info('loc234:%s'%loc234)
self.loc.append(loc234) self.test_num = int(res[4])
self.loc_err = int(res[5])
self.net_err = int(res[6])
self.conn_err = int(res[7])
self.send_err = int(res[8])
self.rec_err = int(res[9])
self.signal = [res[10]+','] def washdata(filepath,pattern,dic):
f = open(filepath,'r',encoding='utf-8')
cls_dic = dic#class对象
logger.warning(cls_dic)
line = f.readline().strip()#去空格、换行
while line:
#print('line:',line)
res=re.findall(pattern,line)
#print('res:',res)
#print('len(res):',len(res)) if len(res) == 1:
info_list = re.findall(pattern_1,res[0])[0]
logger.info('info_list:')
logger.info(info_list)
sn = info_list[0]
mode = info_list[1]
dat = info_list[2]
flag = 0#该对象是否已经创建,1是已创建,直接更新信息即可
for key,cls in cls_dic.items():
if cls.dat == dat and cls.sn == sn and cls.mode == mode:
cls.updateInfo(res[0])
flag = 1
if flag == 0:
#新建一个class
cls_name = 'record'+str(len(cls_dic))
cls_dic[cls_name] = recorder(sn,mode,dat)
cls_dic[cls_name].setInfo(res[0]) line = f.readline() f.close()
return cls_dic #对单个文件操作
def writetoexcel(cls_dic,savefilename):
logger.info('------将数据写到excel中------')
#遍历cls_dic
workbook1 = xlrd.open_workbook(savefilename)
rows = workbook1.sheet_by_index(0).nrows
workbook2 = copy(workbook1)#拷贝一份原来的excel
#根据名字获取指定sheet页
sheet=workbook2.get_sheet('Sheet1')
#获取sheet页的行数(和列数)
#rows = sheet.nrows
#rows = sheet.get_nrows
row = rows
logger.info('excel中已有数据%d行'%rows) logger.info('cls_dic:%s'%cls_dic)
for k,c in cls_dic.items():
sheet.write(row, 0, c.dat)
sheet.write(row, 1, c.sn)
sheet.write(row, 2, c.mode)
sheet.write(row, 3, c.loc)
#sheet.write(row, 4, c.locAddress)
sheet.write(row, 4, c.test_num)
sheet.write(row, 5, c.loc_err)
sheet.write(row, 6, c.net_err)
sheet.write(row, 7, c.conn_err)
sheet.write(row, 8, c.send_err)
sheet.write(row, 9, c.rec_err)
sheet.write(row, 10, c.signal) row += 1
logger.info('向excel中写入%d条数据'%(row-rows)) workbook2.save(savefilename) #对多个文件操作,并将需要关注的数据提取到dic中
def traverse(filepath,dic):
logger.warning('遍历文件夹,dic:%s'%dic)
logger.warning('len(dic):%d'%len(dic))
list = os.listdir(filepath)
for i in range(0,len(list)):
logger.info(list[i])
tmp_path = os.path.join(filepath,list[i])
#print tmp_path
if os.path.isfile(tmp_path):
if tmp_path[-4:] == ".txt":
logger.info('需要抓取信息的文件为 :%s'%tmp_path)
logger.warning('更新or新增条目%s'%dic)
logger.warning('len(dic):%d'%len(dic))
dic = washdata(tmp_path,pattern,dic)
else:
traverse(tmp_path,dic) return dic
#writetoexcel(cls_dic,savefilename) #pattern = re.compile('(content:SN=.*?;REC_ERR=\d*)' ,re.S)
#增加了2个字段信息
pattern = re.compile('(content:SN=.*?;SIGNAL=.\d)' ,re.S)
pattern_1 = re.compile('content:SN=(.*?);MODE=(.*?);TIME=(.*?) .*?LOC=(.*?);TEST_NUM=(.*?);LOC_ERR=(.*?);NET_ERR=(.*?);CONN_ERR=(.*?);SEND_ERR=(.*?);REC_ERR=(\d*);SIGNAL=(.\d)' ,re.S) if __name__ == '__main__':
'''
#suite for single file
cls_dic = washdata(filepath,pattern)
writetoexcel(cls_dic,savefilename)
''' #suite for more than one file
filepath = r'E:\05_Test\P6\wifi&2G\log'
savefilename = r'E:\05_Test\P6\wifi&2G\result\20190920_result.xls'
dic = {}
cls_dic = traverse(filepath,dic)
writetoexcel(cls_dic,savefilename) logger.info('------End------')
demo_ex
python运用 - log信息提取(知识: 遍历 | os )的更多相关文章
- 搜索引擎如何检索结果:Python和spaCy信息提取简介
概览 像Google这样的搜索引擎如何理解我们的查询并提供相关结果? 了解信息提取的概念 我们将使用流行的spaCy库在Python中进行信息提取 介绍 作为一个数据科学家,在日常工作中,我严重依赖搜 ...
- Python全栈--7模块--random os sys time datetime hashlib pickle json requests xml
模块分为三种: 自定义模块 内置模块 开源模块 一.安装第三方模块 # python 安装第三方模块 # 加入环境变量 : 右键计算机---属性---高级设置---环境变量---path--分号+py ...
- Python中元组相关知识
下面给大家介绍以下元组的相关知识: ·元组可以看成是一个不可更改的list 1.元组的创建 # 创建空元祖 t = () print(type(t)) # 创建只有一个值的元组 # 观察可知元组中如果 ...
- 『Python基础-1 』 编程语言Python的基础背景知识
#『Python基础-1 』 编程语言Python的基础背景知识 目录: 1.编程语言 1.1 什么是编程语言 1.2 编程语言的种类 1.3 常见的编程语言 1.4 编译型语言和解释型语言的对比 2 ...
- Python之log的处理方式
配置文件: #! /usr/bin/env python # -*- coding: utf-8 -*- """ logging配置 """ ...
- python小技巧 小知识
python小技巧 小知识 python系统变量(修改调用shell命令路径)或用户空间说明 20150418 python调用系统命令,报找不到.怎么办? 类似执行shell的: [ -f /etc ...
- 提问式复习:图文回顾 redo log 相关知识
原文链接:提问式复习:图文回顾 redo log 相关知识 1.如何提升 redo日志 的写性能? 为了保证 redo日志 不丢失,会在磁盘中开辟一块空间将日志保存起来.但是这样会有一个问题,磁盘的读 ...
- Python常用模块(time, datetime, random, os, sys, hashlib)
time模块 在Python中,通常有这几种方式来表示时间: 时间戳(timestamp) : 通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量.我们运 ...
- python面试必问 知识整理
一 数据类型 1 数字 整型与浮点型 #整型int 作用:年纪,等级,身份证号,qq号等整型数字相关 定义: age=10 #本质age=int(10) #浮点型float 作用:薪资,身高, ...
随机推荐
- MongoDB学习(三)
MongoDB条件操作符 $gt > 大于 $lt < 小于 $gte >= 大于等于 $lte <= 小于等于 $ne != 不等于 条件操作符可用于查询语句中, ...
- 数学--数论--POJ281(线性同余方程)
埃琳娜(Elina)正在阅读刘如家(Rujia Liu)写的书,其中介绍了一种表达非负整数的奇怪方法.方式描述如下: 选择k个不同的正整数a 1,a 2,-,a k.对于一些非负米,把它由每一个我(1 ...
- C++ 模板(template) 的定义
定义: 模板(template)是实现代码重用机制的一种工具,它可以实现类型参数化,把类型定义为参数(模板元编程),从而实现了真正的代码可重用性. 模板是用来批量生成功能和形式都几乎相同的代码的.编译 ...
- Windows+Ubuntu双系统 ,Ubuntu安装
这篇只是简单记录自己在Win10下另安装Ubuntu系统. 不是教程,因为不会. 推荐一个教程:https://blog.csdn.net/weixin_37029453/article/detail ...
- 题解 bzoj 4398福慧双修(二进制分组)
二进制分组,算个小技巧 bzoj 4398福慧双修 给一张图,同一条边不同方向权值不同,一条边只能走一次,求从1号点出发再回到1号点的最短路 一开始没注意一条边只能走一次这个限制,打了个从一号点相邻节 ...
- 【K8S】K8S 1.18.2安装dashboard(基于kubernetes-dashboard 2.0.0版本)
[K8S]K8S 1.18.2安装dashboard(基于kubernetes-dashboard 2.0.0版本) 写在前面 K8S集群部署成功了,如何对集群进行可视化管理呢?别着急,接下来,我们一 ...
- Unity 游戏框架搭建 2019 (四十四、四十五) 关于知识库的小结&独立的方法和独立的类
在上一篇,我们完成了一个定时功能,并且接触了 Action 和委托.lambda 表达式这些概念. 到目前为止,我们的库作为知识收录这个功能来说,已经非常好用了,由于使用了 partial 关键字,所 ...
- C. Cave Painting(最小公倍数的应用)
\(\color{Red}{网上的题解都是投机取巧啊,虽然也没错}\) \(Ⅰ.先说一下投机取巧的方法\) \(自己写几个例子会发现k很小的时候满足条件的n就变得很大\) \(所以我们直接暴力从1判断 ...
- C - Ordering Pizza CodeForces - 867C 贪心 经典
C - Ordering Pizza CodeForces - 867C C - Ordering Pizza 这个是最难的,一个贪心,很经典,但是我不会,早训结束看了题解才知道怎么贪心的. 这个是先 ...
- while持续输入的几种常用使用方法
while(scanf("%d,&n")!=EOF) 如果n被成功读入,则返回值为1, 如果n未被成功读入,则返回值为0, 如果遇到错误或遇到end of file,返回值 ...