Uncovering thousands of new peptides with sequence-mask-search hybrid de novo peptide sequencing framework (使用序列掩码搜索结合肽段从头测序框架发现了数千个新肽段)-解读人:刘佳维
期刊名:Molecular & Cellular Proteomics
发表时间:(2019年12月)
IF:4.828
单位:
- 朱拉隆功大学
- 费城威斯塔研究所
物种:人
技术:de novo从头测序,深度学习
一、 概述:
该研究开发了一种基于深度学习的肽段从头测序框架SMSNet,在保持良好的识别覆盖率的同时,氨基酸准确度能达到95%以上。SMSNet揭示了超过10000个以前未分类的人类白细胞抗原(HLA)和磷酸肽,并结合数据库搜索方法,将肽鉴定的覆盖范围扩大了近30%。
二、 研究背景:
基于质谱的蛋白质组学数据的典型分析方法数据库搜索方法仅识别在参考数据库中存在的氨基酸序列,限制了发现新的肽的可能性,例如那些含有未经特征化突变的肽,或者那些起源于rna和蛋白质的意外加工的肽。相反,从头测序方法直接从观察到的质谱中确定氨基酸序列,但有时精度较低。尽管近年来已经证明了深度学习可以有效地应用于从头测序问题,但从头测序方法和数据库搜索方法在识别肽的准确性和数量方面仍存在巨大的性能差距。这一限制的关键部分在于质谱谱图是有噪声的,有时会缺乏关键信息。如何解决这一问题是提升从头测序方法的关键所在。
三、实验设计:

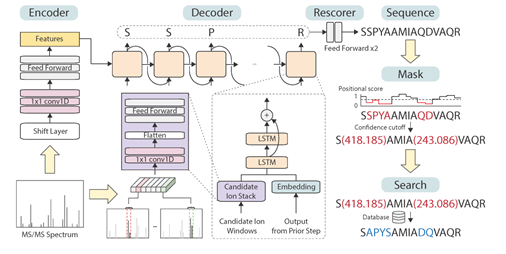
SMSNet序列掩码搜索框架
四、研究成果:
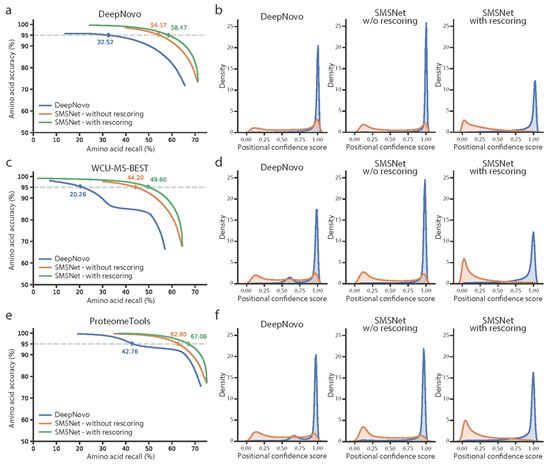
1、与目前最新的de novo测序软件DeepNoVo相比,SMSNet的性能要更好一些。由于DeepNovo没有后处理功能,为了保证比较的公平,分别展示了SMSNet在重新评分和不重新评分的情况下的性能。在下图中:
a,在由DeepNovo的作者整理的数据集上评估SMSNet和DeepNovo的氨基酸水平性能。图中标示了在5%氨基酸错误发现率下的相应召回率。
b,直方图展示了在由DeepNovo的作者整理的数据集上进行评估时,SMSNet和DeepNovo产生的置信度得分的分布。
c-d,在本文的WCU-MS-BEST数据集上进行了类似a-b的评估。
e-f,在蛋白质组学数据库获得的合成肽的高质量MS/MS谱数据集上进行了类似a-b的评估。
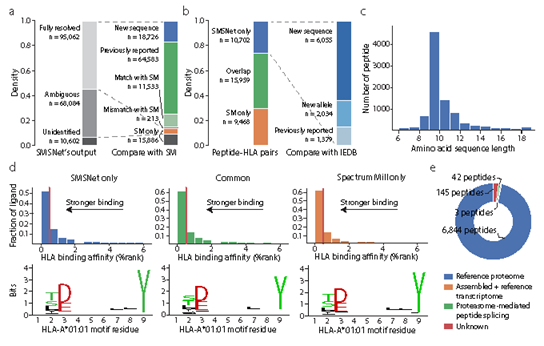
2、使用SMSNet发现了大量新的HLA抗原。在下图中:
a,使用堆叠条形图展示了由SMSNet识别的MS/MS光谱的数量以及SMSNet与先前使用Spectrum Mill软件进行MS/MS数据解释的研究之间的重叠。
b,使用堆叠条形图展示了由SMSNet识别的peptide-HLA对与免疫表位数据库(IEDB)之间的重叠。在10702个新鉴定的peptide-HLA对中,有7034种不同的肽。
c,新鉴定到的7034种肽的长度分布。
d,使用直方图和序列logos,比较了仅由SMSNet(左)、SMSNet+先前研究(中)和仅由先前研究(右)识别的peptide-HLA对之间预测的结合亲和力与核心序列motifs。
e,使用饼图展示了新鉴定的7034种肽的来源。
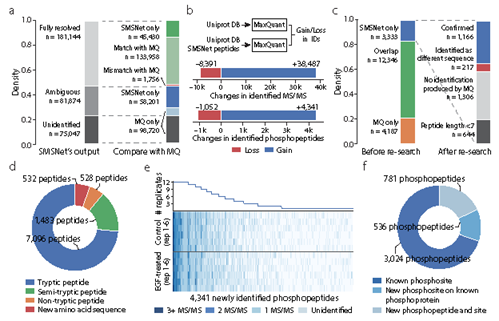
3、使用SMSNet提高了人类磷蛋白组鉴定的覆盖率。在下图中:
a,使用堆叠条形图展示了由SMSNet识别的MS/MS光谱的数量以及SMSNet与先前研究之间的重叠。
b,将SMSNet的鉴定结果加入到人类蛋白质组数据库中并用MaxQuant重新分析后,所鉴定到的MS/MS谱和磷酸肽的数量的增加和减少。
c,使用堆积条形图展示了由MaxQuant和SMSNet识别的磷酸肽数量,以及通过MaxQuant重新分析SMSNet结果从而识别到的新磷酸肽的数量。
d,饼图展示了通过将SMSNet的鉴定使用MaxQuant重新分析新鉴定到的肽的组成。这包括先前研究未鉴定的所有MS/MS光谱中的磷酸肽和非磷酸肽鉴定。
e,使用热图和线性图展示了4341个新鉴定的磷酸肽在使用MaxQuant对6个对照组和6个表皮生长因子处理的实验组进行重分析后的重现性。热图中的每一行对应一个质谱实验。
f,使用饼图展示了新鉴定的磷酸肽与PhosphoSitePlus数据库中已知的磷酸蛋白和磷酸位点之间的重叠。一个已识别的磷酸肽只有在数据库中报告了该肽上所有已识别的磷酸化位点时才被算作“Known phosphosites”。
五、文章亮点(结论讨论):本文开发的SMSNet结合了基于机器学习的现代方法和序列标记方法的优点,前者能够确定整个氨基酸序列,后者使用序列中置信度高的部分作为种子从数据库中检索完整序列,大大提升了从头测序方法的准确率。因此,SMSNet有望在新抗原发现、抗体测序和非模式生物的特征等蛋白质组学和肽组学的研究中有良好的表现。
阅读人:刘佳维
Uncovering thousands of new peptides with sequence-mask-search hybrid de novo peptide sequencing framework (使用序列掩码搜索结合肽段从头测序框架发现了数千个新肽段)-解读人:刘佳维的更多相关文章
- Mol Cell Proteomics. | Prediction of LC-MS/MS properties of peptides from sequence by deep learning (通过深度学习技术根据肽段序列预测其LC-MS/MS谱特征) (解读人:梅占龙)
通过深度学习技术根据肽段序列预测其LC-MS/MS谱特征 解读人:梅占龙 质谱平台 文献名:Prediction of LC-MS/MS properties of peptides from se ...
- 解读人:陈秋实,SP2: Rapid and Automatable Contaminant Removal from Peptide Samples for Proteomic Analyses(标准操作流程2:如何在蛋白质组学分析中快速和自动的去除肽段样品中的污染物)
发表时间:2019年4月 IF:3.950 单位: 威斯康星医学院生物化学系 威斯康星医学院生物医学质谱研究中心 物种:人(人体肾脏细胞和蛋白) 技术:肽段清理 一. 概述:(用精炼的语言描述文章的整 ...
- Analysis of endogenous peptides released from osteoarthritic cartilage unravels novel pathogenic markers (解读人:李琼)
文献名:Analysis of endogenous peptides released from osteoarthritic cartilage unravels novel pathogenic ...
- Journal of Proteome Research | SAAVpedia: identification, functional annotation, and retrieval of single amino acid variants for proteogenomic interpretation | SAAV的识别、功能注释和检索 | (解读人:徐洪凯)
文献名:SAAVpedia: identification, functional annotation, and retrieval of single amino acid variants fo ...
- 解读人:刘杰,Targeted Quantitative Kinome Analysis Identifies PRPS2 as a Promoter for Colorectal Cancer Metastasis(PRM-磷酸化激酶定量发现结肠癌转移促进因子-PRPS2)
关键词:PRM,kinase,colorectal cancer, metastasis, PRPS2 来自加州大学河滨分校的Yinsheng Wang教授应用PRM技术筛选出介导结肠癌细胞转移促进因 ...
- Sample Preparation by Easy Extraction and Digestion (SPEED) - A Universal, Rapid, and Detergent-free Protocol for Proteomics based on Acid Extraction(一种使用强酸的蛋白质提取方法SPEED,普适,快速,无需去垢剂)-解读人:李思奇
期刊名:Mol Cell Proteomics 发表时间:(2019年12月) IF:4.828 单位:德国Robert Koch 研究所 物种:多种 技术:新蛋白提取和酶解方法 一. 概述: 本文设 ...
- Journal of Proteome Research | An automated ‘cells-to-peptides’ sample preparation workflow for high-throughput, quantitative proteomic assays of microbes (解读人:陈浩)
文献名:An automated ‘cells-to-peptides’ sample preparation workflow for high-throughput, quantitative p ...
- Fast and accurate bacterial species identification in urine specimens using LC-MS/MS mass spectrometry and machine learning (解读人:闫克强)
文献名:Fast and accurate bacterial species identification in urine specimens using LC-MS/MS mass spectr ...
- Multi-batch TMT reveals false positives, batch effects and missing values(解读人:胡丹丹)
文献名:Multi-batch TMT reveals false positives, batch effects and missing values (多批次TMT定量方法中对假阳性率,批次效应 ...
随机推荐
- concurrent包分析之Executor框架
文章目录 线程生命周期的开销:线程比较少的情况使用new Thread(task)无多大影响,但是如果涉及到线程比较多的情况,应用的性能就会受到影响,如果jdbc创建连接一样,new Thead创建线 ...
- 仿豆瓣首页弹性滑动控件|Axlchen's blog
逛豆瓣的时候看到了这样的控件,觉得挺有趣,遂模仿之 先看看原版的效果 再看看模仿的效果 分析 控件结构分析 由于*ScrollView只能有一个child view,所以整个child view的结构 ...
- Hi3518_SDK
第一章 Hi3518_SDK_Vx.x.x.x版本升级操作说明 如果您是首次安装本SDK,请直接参看第2章. 第二章 首次安装SDK 1.Hi3518 SDK包位置 在"Hi3518_V10 ...
- rpmbuild 实践
安装 rpmbuild 1 # yum install -y rpm-build 查看 rpmbuild 相关的宏和参数 12345678 # rpmbuild --showrc | grep --c ...
- string类中getline函数的应用
*/ * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:text.cpp * 作者:常轩 * 微信公众号:Worldhe ...
- flask 参数校验
校验参数是否存在,不存在返回400 @app.route('/check',methods=['POST']) def check(): values = request.get_json() req ...
- dns原理介绍及实践问题总结
1 问题引入: a) 域名劫持: dns过程中某个环节被攻击/篡改,导致dns结果为劫持者的服务器.例如竞争对手将你方的app下载地址篡改为他方的app下载地址. b) 对现网用户进行监控时,发现个别 ...
- SpringBoot&Shiro实现用户认证
SpringBoot&Shiro实现用户认证 实现思路 思路:实现认证功能主要可以归纳为3点 1.定义一个ShiroConfig配置类,配置 SecurityManager Bean , Se ...
- 07.深入浅出 Spring Boot - 数据访问之Mybatis(附代码下载)
MyBatis 在Spring Boot应用非常广,非常强大的一个半自动的ORM框架. 代码下载:https://github.com/Jackson0714/study-spring-boot.gi ...
- SpringBoot图文教程11—从此不写mapper文件「SpringBoot集成MybatisPlus」
有天上飞的概念,就要有落地的实现 概念十遍不如代码一遍,朋友,希望你把文中所有的代码案例都敲一遍 先赞后看,养成习惯 SpringBoot 图文教程系列文章目录 SpringBoot图文教程1「概念+ ...