【Spark】Spark任务调度相关知识
准备知识
要弄清楚Spark的任务调度流程,就必须要清楚RDD、Lineage、DAG和shuffle的相关知识,关于RDD和Lineage,我的这两天文章已经有过相关介绍,感兴趣可以去看一看
【Spark】RDD(Resilient Distributed Dataset)究竟是什么?
【Spark】RDD的依赖关系和缓存相关知识点接下来说一下DAG的生成和shuffle的过程
DAG
概述
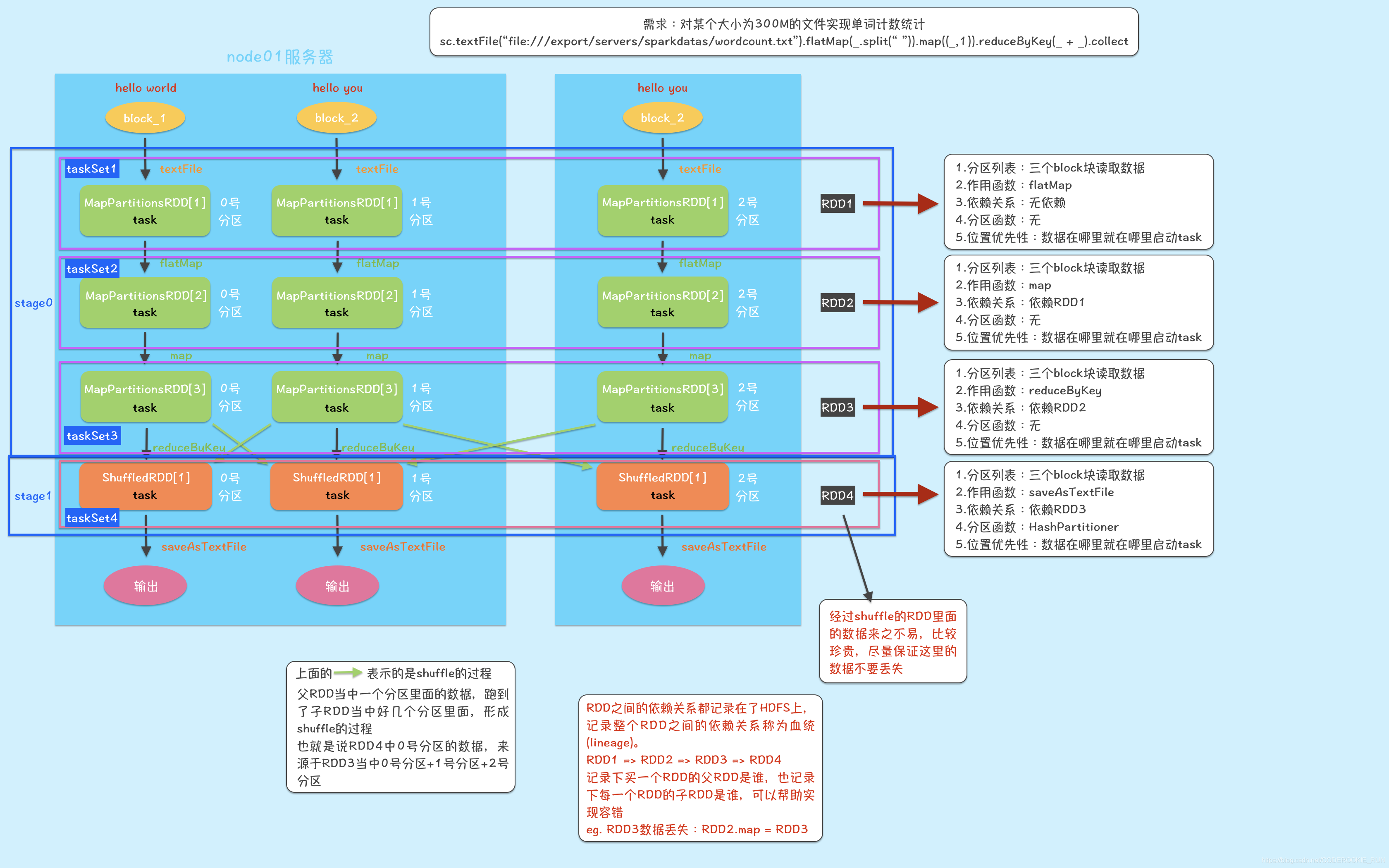
DAG(Directed Acyclic Graph),被称为有向无环图,就是有方向无闭环,是根据RDD之间的依赖关系,也即Lineage形成的。
DAG的生成就是为了划分stage,而stage的划分则是从上往下依次,遇到窄依赖便将其加入到当前stage当中,如果遇到宽依赖就重新开始一个stage,而区别宽窄依赖的依据就是是否发生了shuffle过程,那么stage划分的最终依据就是是否发生shuffle过程,正如下图所示
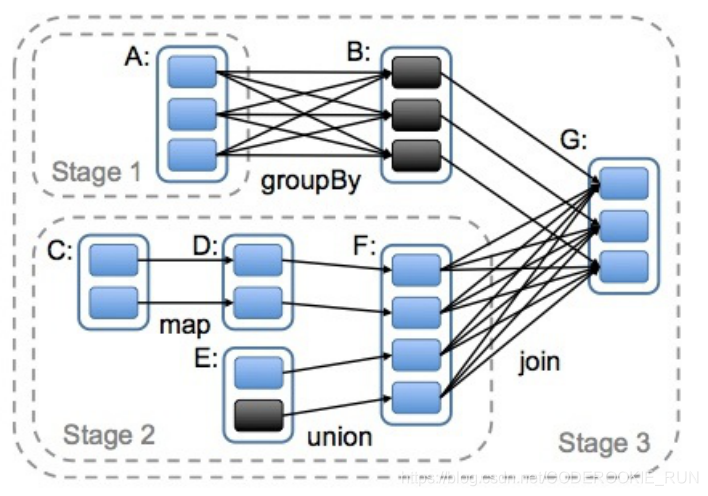
shuffle
概述
在Spark中,负责shuffle过程的执行、计算和处理的组件主要就是ShuffleManager。在Spark1.2版本前,默认的shuffle计算引擎是 HashShuffleManager,Spark1.2版本后,改成了 SortShuffleManager。
HashShuffleManager有一个重大弊端:会产生大量的中间磁盘文件,进而由大量的磁盘IO操作影响了性能。
SortShuffleManager
SortShuffleManager针对HashShuffleManager的弊端做了改进,设置了两种运行机制:普通运行机制和bypass运行机制。
当shuffle read task的数量小于等于spark.shuffle.sort.bypassMergeThreshold参数的值时(默认为200),就会启用bypass机制。
普通机制
数据会先写到内存大小为5M的缓存中,写满后溢写成为一个个的小文件,并同时进行排序,然后再分批写入到内存缓冲区,进一步写入到磁盘文件中,最后将磁盘文件进行合并,成为一个大文件,并创建对应的索引文件,等待接下来的线程拉取数据
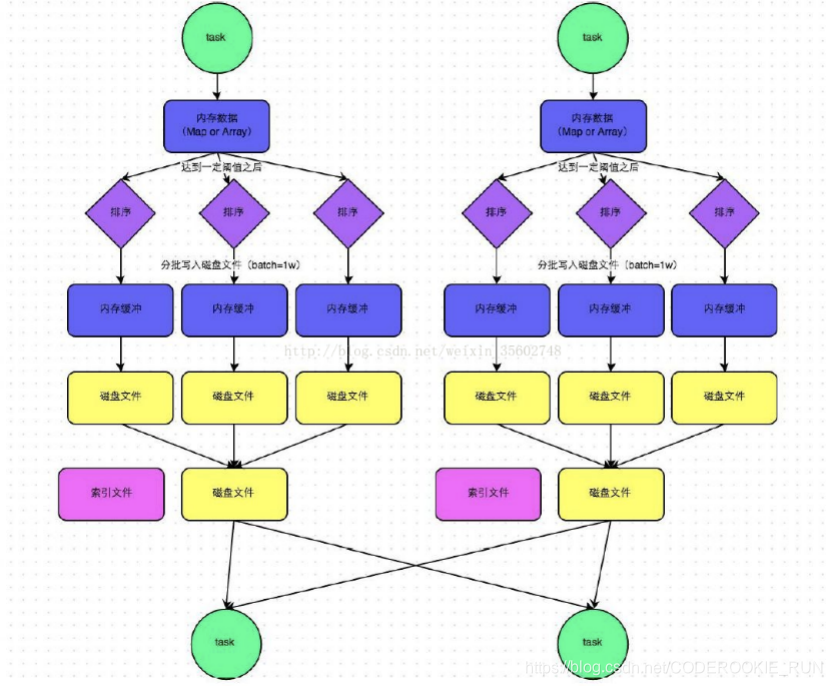
bypass机制
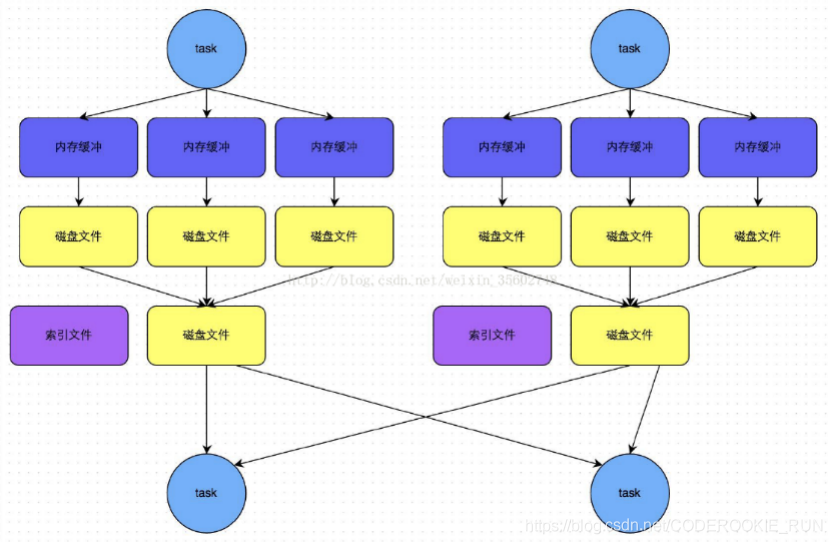
数据不需要经过溢写和排序,直接将数据写入到内存缓冲区,缓冲区写满后溢写到磁盘文件,所有的临时磁盘文件会合并成一个磁盘文件,并创建对应的索引文件,等待拉取
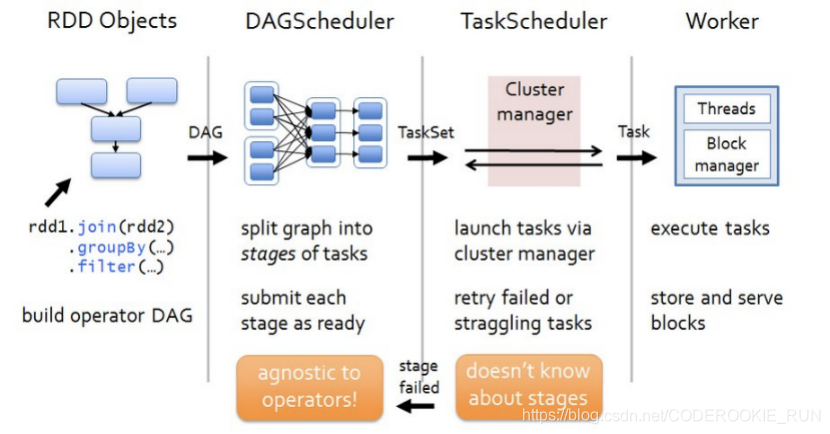
Spark任务调度
流程
一、客户端提交jar包,也就是一个Application
二、Spark会根据Application中的RDD依赖关系,也就是Lineage开始划分DAG
三、划分完成后DAG会被送到DAGScheduler
四、DAGScheduler会根据是否为宽依赖划分Stage,并进一步划分出一个个的taskSet
五、DAGScheduler将划分好的taskSet送到TaskScheduler
六、TaskScheduler接收成功后,会将taskSet划分成为一个个的task,并准备将task发送到Worker中的executor执行
七、与executor进行通信,开始执行task
前六步都是Spark-Driver负责,所以一般推荐使用Cluster模式,将Driver运行在Worker中
【Spark】Spark任务调度相关知识的更多相关文章
- Spark on Yarn年度知识整理
大数据体系结构: Spark简介 Spark是整个BDAS的核心组件,是一个大数据分布式编程框架,不仅实现了MapReduce的算子map 函数和reduce函数及计算模型,还提供更为丰富的算子,如f ...
- Spark的任务调度
本文尝试从源码层面梳理Spark在任务调度与资源分配上的做法. 先从Executor和SchedulerBackend说起.Executor是真正执行任务的进程,本身拥有若干cpu和内存,可以执行以线 ...
- Spark内核-任务调度机制
作者:十一喵先森 链接:https://juejin.im/post/5e1c414fe51d451cad4111d1 来源:掘金 著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. ...
- Spark-读写HBase,SparkStreaming操作,Spark的HBase相关操作
Spark-读写HBase,SparkStreaming操作,Spark的HBase相关操作 1.sparkstreaming实时写入Hbase(saveAsNewAPIHadoopDataset方法 ...
- 分布式计算框架-Spark(spark环境搭建、生态环境、运行架构)
Spark涉及的几个概念:RDD:Resilient Distributed Dataset(弹性分布数据集).DAG:Direct Acyclic Graph(有向无环图).SparkContext ...
- [spark] spark 特性、简介、下载
[简介] 官网:http://spark.apache.org/ 推荐学习博客:http://dblab.xmu.edu.cn/blog/spark/ spark是一个采用Scala语言进行开发,更快 ...
- PySpark SQL 相关知识介绍
title: PySpark SQL 相关知识介绍 summary: 关键词:大数据 Hadoop Hive Pig Kafka Spark PySpark SQL 集群管理器 PostgreSQL ...
- 【Python五篇慢慢弹(5)】类的继承案例解析,python相关知识延伸
类的继承案例解析,python相关知识延伸 作者:白宁超 2016年10月10日22:36:57 摘要:继<快速上手学python>一文之后,笔者又将python官方文档认真学习下.官方给 ...
- 移动WEB像素相关知识
了解移动web像素的知识,主要是为了切图时心中有数.本文主要围绕一个问题:怎样根据设备厂商提供的屏幕尺寸和物理像素得到我们切图需要的逻辑像素?围绕这个问题以iphone5为例讲解涉及到的web像素相关 ...
随机推荐
- 今天我们来讨论一下CSS3属性中的transition属性;
transition属性是CSS3属性:顾名思义英文为过渡的意思:主要有四个值与其一一对应:分别是property(CSS属性名称),duration过渡的时长,timimg-function转速曲线 ...
- [PHP] 调用微博API 发微博OAuth2.0
在实际测试中出现很多问题, 第一就是按照文档调用ACCESS_TOKEN的时候费老劲啦,因为是编辑线上的,有好多中文空格,没有看出来!整了好久! 第二个就是在调用api发微博的时候出现乱码!必须把发送 ...
- 让所有网站都提供API的Python库:Toapi
这是一个让所有网站都提供API的Python库.以前,我们爬取数据,然后把数据存起来,再创造一个api服务以便其他人可以访问.为此,我们还要定期更新我们的数据.这个库让这一切变得容易起来.你要做的就是 ...
- .NET Core 3 WPF MVVM框架 Prism系列文章索引
.NET Core 3 WPF MVVM框架 Prism系列之数据绑定 .NET Core 3 WPF MVVM框架 Prism系列之命令 .NET Core 3 WPF MVVM框架 Prism系列 ...
- 想学习CTF的一定要看这篇,让你学习效率提升80%
在学习CTF过程中你是否遇到这样的情况: 下定决心想要学习CTF,不知道从哪里开始? 找了一堆CTF相关的知识学习,但是知识点太凌乱,没有统一明确的学习路径. 又或者理论学习完,没有相应的实操环境? ...
- python 携程asyncio 实现高并发示例2
https://www.bilibili.com/video/BV1g7411k7MD?from=search&seid=13649975876676293013 import asyncio ...
- 【vue】nextTick源码解析
1.整体入手 阅读代码和画画是一样的,忌讳一开始就从细节下手(比如一行一行读),我们先将细节代码折叠起来,整体观察nextTick源码的几大块. 折叠后代码如下图 整体观察代码结构 上图中,可以看到: ...
- 如何让ThreadPoolExecutor更早地创建非核心线程
最近在项目中遇到一个需要用线程池来处理任务的需求,于是我用ThreadPoolExecutor来实现,但是在实现过程中我发现提交大量任务时它的处理逻辑是这样的(提交任务还有一个submit方法内部也调 ...
- 上传文件的input问题以及FormData特性
1.input中除了type="file"还要加上name="file",否则$_FILES为空,input的name值就是为了区分每一个input的 2.va ...
- HTTP 1.1, 返回值100.
HTTP 1.1支持只发送header信息(不带任何body信息),如果服务器认为客户端有权限请求服务器,则返回100,否则返回401.客户端如果接受到100,才开始把请求body发送到服务器. 这样 ...