入门大数据---HDFS-HA搭建
一.简述
上一篇了解了Zookeeper和HDFS的一些概念,今天就带大家从头到尾搭建一下,其中遇到的一些坑也顺便记录下。
1.1 搭建的拓扑图如下:

1.2 部署环境:Centos3.1,java1.8.0 ,Hadoop3.2,Zookeeper3.5.5
Linux环境搭建我这里就不介绍了,请自行百度(PS:需要注意的一点是,最后一步硬盘大小最好改大一些,比如60G)。
1.3 搭建Linux的时候可能会遇到这么几个问题:
首先安装系统的时候不要选择精简版,这样会有很多软件不全,尽量去选择全一些的版本,比如我选择的Infrastucture Server,然后全勾上了,这样虽然占用空间大了些,但是省去了后续安装很多组件的烦恼。
二.正文
小技巧:在搭建之前先说个小技巧,我们搭建的时候可以先在一台虚拟机上部署,然后通过克隆到其它机器,修改部分该修改的参数就行了,这样就方便了环境的频繁部署。
2.1 配置环境
2.1.1 设置固定ip
1.进入到 /etc/sysconfig/network-scripts
2.点击Vmware上面的编辑->虚拟网络编辑器 点开NAT设置,里面可以看到网关IP
3.编辑ifcfg配置文件,修改固定ip,网关地址,DNS映射,子网掩码等
vim ifcfg-eno16777736
TYPE=Ethernet
#标记显示固定ip
BOOTPROTO=static
DEFROUTE=yes
PEERDNS=yes
PEERROUTES=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_PEERDNS=yes
IPV6_PEERROUTES=yes
IPV6_FAILURE_FATAL=no
NAME=eno16777736
DEVICE=eno16777736
ONBOOT=yes
#ip地址,这个以tuge1举例,我设定的为100,后面的tuge2,tuge3,tuge4可以分别设置为101,102,103
IPADDR=192.168.40.100
#网关地址,这个根据上面第二步可以获得
GATEWAY=192.168.40.2
NETMASK=255.255.255.0
#DNS地址
DNS1=114.114.114.114
DNS2=8.8.8.8
4.重启服务:service network restart
2.1.2 配置hadoop环境
1.打开tuge1,在/opt/ 下面创建一个文件夹hadoop
cd /opt/
mkdir hadoop
2.进入到hadoop,在官网找到对应的hadoop版本进行下载,然后对文件进行解压
cd hadoop
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.2.0/hadoop-3.2.0.tar.gz
tar -xvf hadoop-3.2.0.tar.gz
2.1.3 配置java环境
3.然后回到/opt/下面创建一个java文件
cd /opt/
mkdir java
4.进入到java,通过ftp将jdk上传到此目录,并进行解压
cd java
tar -xvf jdk-8u221-linux-x64.tar.gz
2.1.4 配置Zookeeper环境
1.进入到 /opt/下面创建zookeeper文件夹
cd /opt/
mkdir zookeeper
2.进入到zookeeper文件夹,下载zookeeper,然后对文件进行解压
cd zookeeper
wget http://mirror.bit.edu.cn/apache/zookeeper/stable/apache-zookeeper-3.5.5-bin.tar.gz
tar -xvf apache-zookeeper-3.5.5-bin.tar.gz
2.1.5 将配置写入配置文件
打开/etc/profile 配置Hadoop和Java环境
vim /etc/profile
export JAVA_HOME=/opt/java/jdk1.8.0_221
export HADOOP_HDFS_HOME=/opt/hadoop/hadoop-3.2.0
export HADOOP_CONF_DIR=/opt/hadoop/hadoop-3.2.0/etc/hadoop
export HADOOP_HOME=/opt/hadoop/hadoop-3.2.0
export ZK_HOME=/opt/zookeeper/apache-zookeeper-3.5.5-bin
PATH=$JAVA_HOME/bin:$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$ZK_HOME/bin
CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar
export PATH CLASSPATH
配置好后,使用source /etc/profile 重新加载配置文件。
2.1.6 验证环境配置
java --version
hadoop version
10.将上面配置好的tuge1克隆到tuge2,tuge3,tuge4,并修改对应的ip为101,102,103
有关Linux克隆自行百度
2.1.7 修改主机别名
vim /etc/hostname 修改为tuge1
PS:其它服务器照着配置即可
2.1.8 修改host文件添加映射别名
vim /etc/hosts 添加
192.168.40.100 tuge1
192.168.40.101 tuge2
192.168.40.102 tuge3
192.168.40.103 tuge4
2.2 搭建HDFS-Zookeeper
上面配置好环境后,接下来就是搭建HDFS了。这个可以参照官网一步一步来:
2.2.1 安装SSH:
yum install openssh-server
2.2.2 配置免密登陆
cd /.ssh
ssh-keygen -t rsa
ssh-copy-id localhost
(以上配置四台都执行,然后都能免密访问了)
在tuge1和tuge2服务器之间也设置互相免密,这样方便以后使用journalnode同步
另外把tuge1的密钥分发到tuge2,tuge3,tuge4上面,方便tuge1对所有机器的控制
2.2.3 配置namenode节点为tuge1,tuge2,并设置遇到故障自动切换
编辑hadoop配置文件:
cd /opt/hadoop/hadoop-3.2.0/etc/hadoop
vim hdfs-site.xml
---------------------------------------------
<configuration>
<property>
<!-- DataNode副本数,伪分布模式配置为1 -->
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
<!-- 启用webhdfs -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--指定hdfs的nameservice为mycluster,需要和core-site.xml中的保持一致
dfs.ha.namenodes.[nameservice id]为在nameservice中的每一个NameNode设置唯一标示符。
配置一个逗号分隔的NameNode ID列表。这将是被DataNode识别为所有的NameNode。
例如,如果使用"node1"作为nameservice ID,并且使用"nn1"和"nn2"作为NameNodes标示符
-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- tuge1下面有一个NameNode,tuge2下面有一个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>tuge1:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>tuge1:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>tuge2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>tuge2:50070</value>
</property>
<!-- 指定NameNode的edits元数据的共享存储位置。也就是JournalNode列表
该url的配置格式:qjournal://host1:port1;host2:port2;host3:port3/journalId
journalId推荐使用nameservice,默认端口号是:8485 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://tuge2:8485;tuge3:8485;tuge4:8485/mycluster</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop/hadoop-3.2.0/ha/jn</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 确定处于Active的Node -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id__rsa</value>
</property>
</configuration>
---------------------------------------------
cd /opt/hadoop
vim core.site.xml
-----------------------------------------
<configuration>
<property>
<!-- 元数据文件存放位置,真正使用的时候会被加载到内容中 -->
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoop-3.2.0/ha</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>tuge1:2181,tuge2:2181,tuge3:2181,tuge4:2181</value>
</property>
</configuration>
------------------------------------------
PS:不要忘了,在一台机器上配置即可,然后分发到其它机器就行了
2.2.4 指定DataNode在tuge3和tuge4上
cd /opt/hadoop/hadoop-3.2.0/etc/hadoop
在workers文件里面指定DataNode
vim workers
------------------------
tuge3
tuge4
--------------------------
PS:弄完了分发到其它机器即可
2.2.5 指定zookeeper在tuge1,tuge2,tuge3和tuge4上
cd /opt/zookeeper/apache-zookeeper-3.5.5-bin/conf
将zoo_sample.cfg复制一份重命名为zoo.cfg
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
-------------------------------------
dataDir=/opt/zookeeper/apache-zookeeper-3.5.5-bin/zkData
server.1=tuge1:2888:3888
server.2=tuge2:2888:3888
server.3=tuge3:2888:3888
server.4=tuge4:2888:3888
------------------------------------
PS:弄完了,进行分发
2.2.6 创建myid文件,指定每台机器的zookeeper ID
cd /opt/zookeeper/apache-zookeeper-3.5.5-bin/
mkdir zkData --其它服务器也相应创建下
touch myid
vim myid --如果是tuge1就写1,tuge2就写2
---------------------------
1
---------------
PS:分发myid到其它机器,并修改数字
2.2.7 格式化NameNode
在格式化之间,要先开启journalnode
hadoop-daemon.sh start journalnode
查看防火墙状态: systemctl status firewalld.service
执行关闭命令: systemctl stop firewalld.service
再次执行查看防火墙命令:systemctl status firewalld.service
执行开机禁用防火墙自启命令 : systemctl disable firewalld.service
做完以上步骤后在以下文件添加点内容:
在start-dfs.sh和stop-dfs.sh文件里面添加
---------------------------------------------
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
在$HADOOP_HOME/etc/hadoop/hadoop-env.sh下面添加
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export JAVA_HOME=/opt/java/jdk1.8.0_221-----------------------------------------------
添加完后分发。
然后选择任意一台NameNode开始格式化
hdfs namenode -format
格式化完成后,在另一台同步元数据
hdfs namenode -bootstrapStandby
2.2.8 格式化Zookeeper
首先启动Zookeeper (下面两个命令tuge1,tuge2,tuge3,tuge4都执行一遍)
cd /opt/zookeeper/apache-zookeeper-3.5.5-bin/bin
./zkServer.sh start
查看Zookeeper启动状态
./zkServer.sh status
使用jps查看所有java进程
开始格式化
hdfs zkfc -formatZK
好了,经过无数采坑,按照上面步骤终于搭建完了,最终贴下效果图:
运行命令:
cd /opt/hadoop/hadoop-3.2.0/sbin
./start-dfs.sh
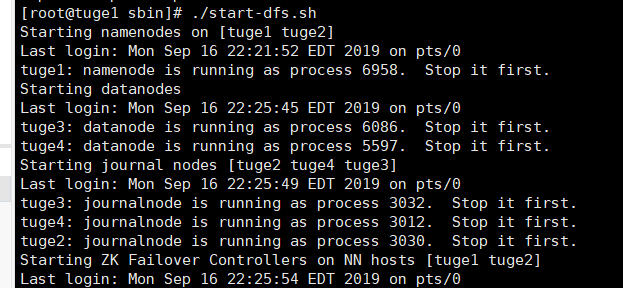
浏览效果:
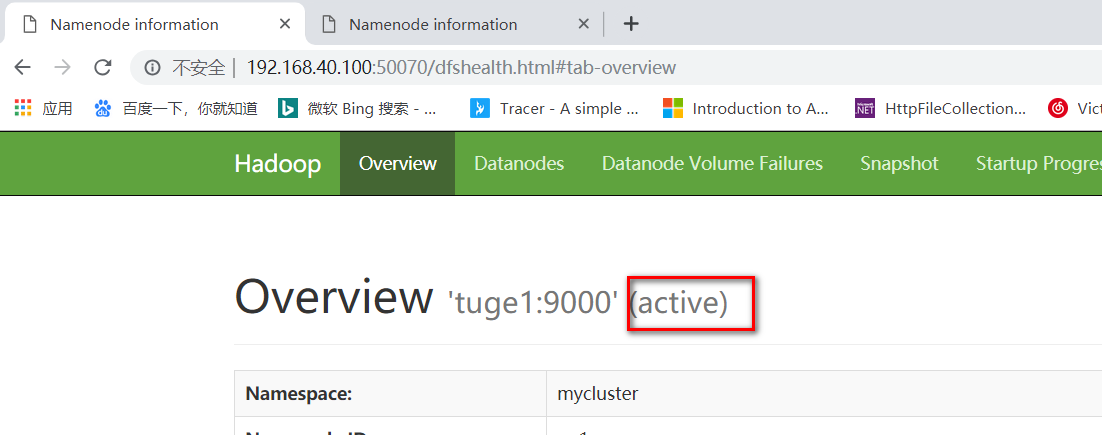
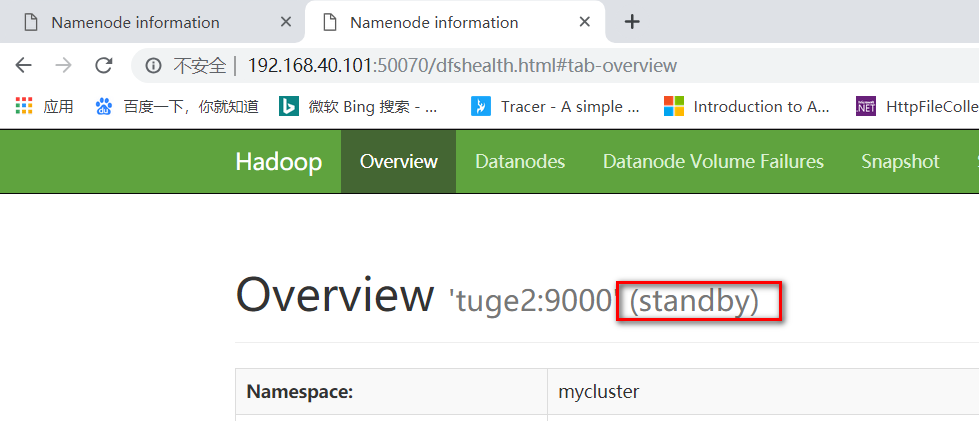
学习官网: http://hadoop.apache.org/
入门大数据---HDFS-HA搭建的更多相关文章
- 入门大数据---HDFS,Zookeeper,ZookeeperFailOverController(简称:ZKFC),JournalNode是什么?
HDFS介绍: 简述: Hadoop Distributed File System(HDFS)是一种分布式文件系统,设计用于在商用硬件上运行.它与现有的分布式文件系统有许多相似之处.但是,与其他分布 ...
- 入门大数据---通过Yarn搭建MapReduce和应用实例
上一篇中我们了解了MapReduce和Yarn的基本概念,接下来带领大家搭建下Mapreduce-HA的框架. 结构图如下: 开始搭建: 一.配置环境 注:可以现在一台计算机上进行配置,然后分发给其它 ...
- 入门大数据---Hive的搭建
本博客主要介绍Hive和MySql的搭建: 学习视频一天就讲完了,我看完了自己搭建MySql遇到了一堆坑,然后花了快两天才解决完,终于把MySql搭建好了.然后又去搭建Hive,又遇到了很多坑,就这 ...
- 入门大数据---Kafka的搭建与应用
前言 上一章介绍了Kafka是什么,这章就讲讲怎么搭建以及如何使用. 快速开始 Step 1:Download the code Download the 2.4.1 release and un-t ...
- 入门大数据---基于Zookeeper搭建Kafka高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本 Zooke ...
- 入门大数据---基于Zookeeper搭建Spark高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- 入门大数据---Flume的搭建
一.下载并解压到指定目录 崇尚授人以渔的思想,我说给大家怎么下载就行了,就不直接放连接了,大家可以直接输入官网地址 http://flume.apache.org ,一般在官网的上方或者左边都会有Do ...
- Ambari——大数据平台的搭建利器之进阶篇
前言 本文适合已经初步了解 Ambari 的读者.对 Ambari 的基础知识,以及 Ambari 的安装步骤还不清楚的读者,可以先阅读基础篇文章<Ambari——大数据平台的搭建利器>. ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- 大数据-hdfs技术
hadoop 理论基础:GFS----HDFS:MapReduce---MapReduce:BigTable----HBase 项目网址:http://hadoop.apache.org/ 下载路径: ...
随机推荐
- Jupyternotebook添加c++核心支持的配置过程
一.环境:虚拟机:(1)系统:centos7.5_1804(64bit)版本(2)软件环境:git.python3.5.3.Jupyter4.4.0二.下载安装脚本:资源及安装说明:https://g ...
- JAVASE(十一) 高级类特性: abstract 、模板模式、interface、内部类、枚举、注解
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 1.关键字 abstract 1.1.abstract可以修饰:类,方法 1.2.abstract修饰方 ...
- 数据库之 MySQL --- 下载、安装 及 概述(一)
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 一 . MySql数据库的安装 1.图解MySQL程序结构 2.双击运行安装程序:以Win32位为例 ...
- PriorityBlockingQueue 和 Executors.newCachedThreadPool()
1.PriorityBlockingQueue里面存储的对象必须是实现Comparable接口. 2.队列通过这个接口的compare方法确定对象的优先级priority. 规则是:当前和其他对象比较 ...
- Java实现k个数乘(cheng)(自然数的k乘积问题)
k个数乘(cheng) 题目描述 桐桐想把一个自然数N分解成K个大于l的自然数相乘的形式,要求这K个数按从小到大排列,而且除了第K个数之外,前面(K-l)个数是N分解出来的最小自然数.例如:N=24, ...
- 第四届蓝桥杯JavaB组省赛真题
解题代码部分来自网友,如果有不对的地方,欢迎各位大佬评论 题目1.世纪末星期 题目描述 曾有邪教称1999年12月31日是世界末日.当然该谣言已经不攻自破. 还有人称今后的某个世纪末的12月31日,如 ...
- (九)DVWA之SQL Injection--SQLMap&Fiddler测试(High)
一.测试需求分析 测试对象:DVWA漏洞系统--SQL Injection模块--ID提交功能 防御等级:High 测试目标:判断被测模块是否存在SQL注入漏洞,漏洞是否可利用,若可以则检测出对应的数 ...
- 温故知新-多线程-forkjoin、CountDownLatch、CyclicBarrier、Semaphore用法
Posted by 微博@Yangsc_o 原创文章,版权声明:自由转载-非商用-非衍生-保持署名 | Creative Commons BY-NC-ND 3.0 文章目录 摘要 forkjoin C ...
- 在MyEclipse中设置jdk
在MyEclipse中设置jdk的三处地方:1 选中项目右键菜单properties -->java Compiler 2 windows菜单中Preferences-->myeclips ...
- 03-Python基础2
本节内容 1. 函数基本语法及特性 2. 参数与局部变量 3. 返回值 嵌套函数 4.递归 5.匿名函数 6.函数式编程介绍 7.高阶函数 8.内置函数 温故知新 1. 集合 主要作用: 去重 关系测 ...