Keras入门——(3)生成式对抗网络GAN
导入 matplotlib 模块:
import matplotlib
查看自己版本所支持的backends:
print(matplotlib.rcsetup.all_backends)
返回信息:
['GTK3Agg', 'GTK3Cairo', 'MacOSX', 'nbAgg', 'Qt4Agg', 'Qt4Cairo', 'Qt5Agg', 'Qt5Cairo', 'TkAgg', 'TkCairo', 'WebAgg', 'WX', 'WXAgg', 'WXCairo', 'agg', 'cairo', 'pdf', 'pgf', 'ps', 'svg', 'template']
查看当前工作的matplotlibrc文件是哪个:
print(matplotlib.matplotlib_fname())
返回信息:
D:\ProgramData\Anaconda2\lib\site-packages\matplotlib\mpl-data\matplotlibrc
打开 matplotlibrc 查看相应内容:

将 backend 修改为 TkAgg:

执行如下代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from keras.models import Model
from keras.layers import Dense, Activation, Input, Reshape
from keras.layers import Conv1D, Flatten, Dropout
from keras.optimizers import SGD, Adam
def sample_data(n_samples=10000, x_vals=np.arange(0, 5, .1), max_offset=100, mul_range=[1, 2]):
vectors = []
for i in range(n_samples):
offset = np.random.random() * max_offset
mul = mul_range[0] + np.random.random() * (mul_range[1] - mul_range[0])
vectors.append(
np.sin(offset + x_vals * mul) / 2 + .5
)
return np.array(vectors)
ax = pd.DataFrame(np.transpose(sample_data(5))).plot()
plt.show()
生成图像:
执行代码:
def get_generative(G_in, dense_dim=200, out_dim=50, lr=1e-3):
x = Dense(dense_dim)(G_in)
x = Activation('tanh')(x)
G_out = Dense(out_dim, activation='tanh')(x)
G = Model(G_in, G_out)
opt = SGD(lr=lr)
G.compile(loss='binary_crossentropy', optimizer=opt)
return G, G_out
G_in = Input(shape=[10])
G, G_out = get_generative(G_in)
G.summary()
生成图像:

执行代码:
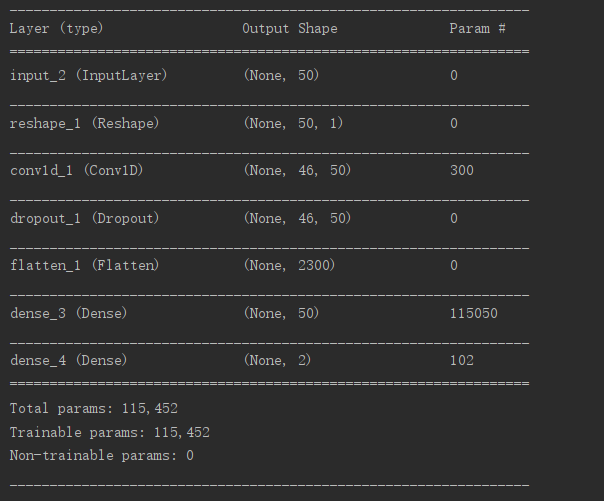
def get_discriminative(D_in, lr=1e-3, drate=.25, n_channels=50, conv_sz=5, leak=.2):
x = Reshape((-1, 1))(D_in)
x = Conv1D(n_channels, conv_sz, activation='relu')(x)
x = Dropout(drate)(x)
x = Flatten()(x)
x = Dense(n_channels)(x)
D_out = Dense(2, activation='sigmoid')(x)
D = Model(D_in, D_out)
dopt = Adam(lr=lr)
D.compile(loss='binary_crossentropy', optimizer=dopt)
return D, D_out
D_in = Input(shape=[50])
D, D_out = get_discriminative(D_in)
D.summary()
生成图像:
执行代码:
def set_trainability(model, trainable=False):
model.trainable = trainable
for layer in model.layers:
layer.trainable = trainable
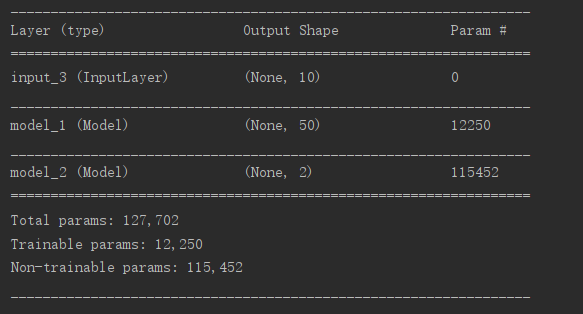
def make_gan(GAN_in, G, D):
set_trainability(D, False)
x = G(GAN_in)
GAN_out = D(x)
GAN = Model(GAN_in, GAN_out)
GAN.compile(loss='binary_crossentropy', optimizer=G.optimizer)
return GAN, GAN_out
GAN_in = Input([10])
GAN, GAN_out = make_gan(GAN_in, G, D)
GAN.summary()
生成图像:
执行代码:
def sample_data_and_gen(G, noise_dim=10, n_samples=10000):
XT = sample_data(n_samples=n_samples)
XN_noise = np.random.uniform(0, 1, size=[n_samples, noise_dim])
XN = G.predict(XN_noise)
X = np.concatenate((XT, XN))
y = np.zeros((2*n_samples, 2))
y[:n_samples, 1] = 1
y[n_samples:, 0] = 1
return X, y
def pretrain(G, D, noise_dim=10, n_samples=10000, batch_size=32):
X, y = sample_data_and_gen(G, n_samples=n_samples, noise_dim=noise_dim)
set_trainability(D, True)
D.fit(X, y, epochs=1, batch_size=batch_size)
pretrain(G, D)
返回信息:
Epoch 1/1 32/20000 [..............................] - ETA: 6:42 - loss: 0.7347 288/20000 [..............................] - ETA: 47s - loss: 0.4808 544/20000 [..............................] - ETA: 26s - loss: 0.3318 800/20000 [>.............................] - ETA: 19s - loss: 0.2359 1056/20000 [>.............................] - ETA: 15s - loss: 0.1805 1312/20000 [>.............................] - ETA: 12s - loss: 0.1459 1568/20000 [=>............................] - ETA: 11s - loss: 0.1223 1824/20000 [=>............................] - ETA: 10s - loss: 0.1053 2048/20000 [==>...........................] - ETA: 9s - loss: 0.0938 2272/20000 [==>...........................] - ETA: 8s - loss: 0.0847 2528/20000 [==>...........................] - ETA: 8s - loss: 0.0761 2784/20000 [===>..........................] - ETA: 7s - loss: 0.0692 3040/20000 [===>..........................] - ETA: 7s - loss: 0.0634 3296/20000 [===>..........................] - ETA: 6s - loss: 0.0585 3552/20000 [====>.........................] - ETA: 6s - loss: 0.0543 3808/20000 [====>.........................] - ETA: 6s - loss: 0.0507 4064/20000 [=====>........................] - ETA: 5s - loss: 0.0475 4352/20000 [=====>........................] - ETA: 5s - loss: 0.0444 4608/20000 [=====>........................] - ETA: 5s - loss: 0.0420 4864/20000 [======>.......................] - ETA: 5s - loss: 0.0398 5120/20000 [======>.......................] - ETA: 4s - loss: 0.0378 5376/20000 [=======>......................] - ETA: 4s - loss: 0.0360 5632/20000 [=======>......................] - ETA: 4s - loss: 0.0344 5888/20000 [=======>......................] - ETA: 4s - loss: 0.0329 6144/20000 [========>.....................] - ETA: 4s - loss: 0.0315 6400/20000 [========>.....................] - ETA: 4s - loss: 0.0303 6656/20000 [========>.....................] - ETA: 4s - loss: 0.0291 6880/20000 [=========>....................] - ETA: 3s - loss: 0.0282 7136/20000 [=========>....................] - ETA: 3s - loss: 0.0272 7392/20000 [==========>...................] - ETA: 3s - loss: 0.0262 7648/20000 [==========>...................] - ETA: 3s - loss: 0.0254 7904/20000 [==========>...................] - ETA: 3s - loss: 0.0246 8160/20000 [===========>..................] - ETA: 3s - loss: 0.0238 8416/20000 [===========>..................] - ETA: 3s - loss: 0.0231 8672/20000 [============>.................] - ETA: 3s - loss: 0.0224 8928/20000 [============>.................] - ETA: 3s - loss: 0.0218 9184/20000 [============>.................] - ETA: 2s - loss: 0.0212 9440/20000 [=============>................] - ETA: 2s - loss: 0.0206 9696/20000 [=============>................] - ETA: 2s - loss: 0.0200 9952/20000 [=============>................] - ETA: 2s - loss: 0.0195 10208/20000 [==============>...............] - ETA: 2s - loss: 0.0190 10464/20000 [==============>...............] - ETA: 2s - loss: 0.0186 10720/20000 [===============>..............] - ETA: 2s - loss: 0.0181 10976/20000 [===============>..............] - ETA: 2s - loss: 0.0177 11232/20000 [===============>..............] - ETA: 2s - loss: 0.0173 11488/20000 [================>.............] - ETA: 2s - loss: 0.0169 11712/20000 [================>.............] - ETA: 2s - loss: 0.0166 11968/20000 [================>.............] - ETA: 2s - loss: 0.0163 12224/20000 [=================>............] - ETA: 2s - loss: 0.0159 12480/20000 [=================>............] - ETA: 1s - loss: 0.0156 12736/20000 [==================>...........] - ETA: 1s - loss: 0.0153 12992/20000 [==================>...........] - ETA: 1s - loss: 0.0150 13248/20000 [==================>...........] - ETA: 1s - loss: 0.0147 13504/20000 [===================>..........] - ETA: 1s - loss: 0.0144 13760/20000 [===================>..........] - ETA: 1s - loss: 0.0141 14016/20000 [====================>.........] - ETA: 1s - loss: 0.0139 14272/20000 [====================>.........] - ETA: 1s - loss: 0.0136 14528/20000 [====================>.........] - ETA: 1s - loss: 0.0134 14784/20000 [=====================>........] - ETA: 1s - loss: 0.0132 15040/20000 [=====================>........] - ETA: 1s - loss: 0.0129 15296/20000 [=====================>........] - ETA: 1s - loss: 0.0127 15552/20000 [======================>.......] - ETA: 1s - loss: 0.0125 15808/20000 [======================>.......] - ETA: 1s - loss: 0.0123 16064/20000 [=======================>......] - ETA: 0s - loss: 0.0121 16320/20000 [=======================>......] - ETA: 0s - loss: 0.0119 16576/20000 [=======================>......] - ETA: 0s - loss: 0.0118 16832/20000 [========================>.....] - ETA: 0s - loss: 0.0116 17088/20000 [========================>.....] - ETA: 0s - loss: 0.0114 17344/20000 [=========================>....] - ETA: 0s - loss: 0.0112 17600/20000 [=========================>....] - ETA: 0s - loss: 0.0111 17856/20000 [=========================>....] - ETA: 0s - loss: 0.0109 18144/20000 [==========================>...] - ETA: 0s - loss: 0.0107 18400/20000 [==========================>...] - ETA: 0s - loss: 0.0106 18656/20000 [==========================>...] - ETA: 0s - loss: 0.0104 18912/20000 [===========================>..] - ETA: 0s - loss: 0.0103 19168/20000 [===========================>..] - ETA: 0s - loss: 0.0102 19456/20000 [============================>.] - ETA: 0s - loss: 0.0100 19712/20000 [============================>.] - ETA: 0s - loss: 0.0099 19968/20000 [============================>.] - ETA: 0s - loss: 0.0098 20000/20000 [==============================] - 5s 236us/step - loss: 0.0097
引入模块:
from tqdm import tqdm_notebook as tqdm
执行代码:
def sample_noise(G, noise_dim=10, n_samples=10000):
X = np.random.uniform(0, 1, size=[n_samples, noise_dim])
y = np.zeros((n_samples, 2))
y[:, 1] = 1
return X, y
def train(GAN, G, D, epochs=200, n_samples=10000, noise_dim=10, batch_size=32, verbose=False, v_freq=50):
d_loss = []
g_loss = []
e_range = range(epochs)
if verbose:
e_range = tqdm(e_range)
for epoch in e_range:
X, y = sample_data_and_gen(G, n_samples=n_samples, noise_dim=noise_dim)
set_trainability(D, True)
d_loss.append(D.train_on_batch(X, y))
X, y = sample_noise(G, n_samples=n_samples, noise_dim=noise_dim)
set_trainability(D, False)
g_loss.append(GAN.train_on_batch(X, y))
if verbose and (epoch + 1) % v_freq == 0:
print("Epoch #{}: Generative Loss: {}, Discriminative Loss: {}".format(epoch + 1, g_loss[-1], d_loss[-1]))
return d_loss, g_loss
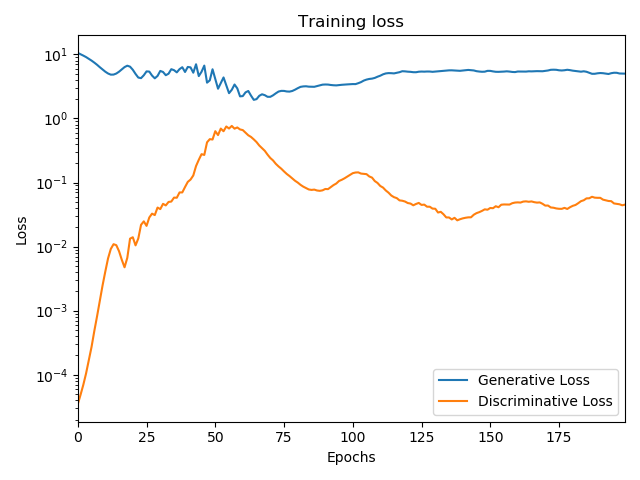
d_loss, g_loss = train(GAN, G, D, verbose=True)
返回信息:
HBox(children=(IntProgress(value=0, max=200), HTML(value=''))) Epoch #50: Generative Loss: 5.842154026031494, Discriminative Loss: 0.4683375060558319 Epoch #100: Generative Loss: 3.4111320972442627, Discriminative Loss: 0.13123030960559845 Epoch #150: Generative Loss: 5.5205817222595215, Discriminative Loss: 0.03762095794081688 Epoch #200: Generative Loss: 4.994686603546143, Discriminative Loss: 0.045186348259449005
执行代码:
ax = pd.DataFrame(
{
'Generative Loss': g_loss,
'Discriminative Loss': d_loss,
}
).plot(title='Training loss', logy=True)
ax.set_xlabel("Epochs")
ax.set_ylabel("Loss")
plt.show()
生成图像:
执行代码:
N_VIEWED_SAMPLES = 2 data_and_gen, _ = sample_data_and_gen(G, n_samples=N_VIEWED_SAMPLES) pd.DataFrame(np.transpose(data_and_gen[N_VIEWED_SAMPLES:])).plot() plt.show()
生成图像:
执行代码:
N_VIEWED_SAMPLES = 2 data_and_gen, _ = sample_data_and_gen(G, n_samples=N_VIEWED_SAMPLES) pd.DataFrame(np.transpose(data_and_gen[N_VIEWED_SAMPLES:])).rolling(5).mean()[5:].plot() plt.show()
生成图像:
完整代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from keras.models import Model
from keras.layers import Dense, Activation, Input, Reshape
from keras.layers import Conv1D, Flatten, Dropout
from keras.optimizers import SGD, Adam
from tqdm import tqdm_notebook as tqdm
#sec
def sample_data(n_samples=10000, x_vals=np.arange(0, 5, .1), max_offset=100, mul_range=[1, 2]):
vectors = []
for i in range(n_samples):
offset = np.random.random() * max_offset
mul = mul_range[0] + np.random.random() * (mul_range[1] - mul_range[0])
vectors.append(
np.sin(offset + x_vals * mul) / 2 + .5
)
return np.array(vectors)
ax = pd.DataFrame(np.transpose(sample_data(5))).plot()
plt.show()
#sec
def get_generative(G_in, dense_dim=200, out_dim=50, lr=1e-3):
x = Dense(dense_dim)(G_in)
x = Activation('tanh')(x)
G_out = Dense(out_dim, activation='tanh')(x)
G = Model(G_in, G_out)
opt = SGD(lr=lr)
G.compile(loss='binary_crossentropy', optimizer=opt)
return G, G_out
G_in = Input(shape=[10])
G, G_out = get_generative(G_in)
G.summary()
#sec
def get_discriminative(D_in, lr=1e-3, drate=.25, n_channels=50, conv_sz=5, leak=.2):
x = Reshape((-1, 1))(D_in)
x = Conv1D(n_channels, conv_sz, activation='relu')(x)
x = Dropout(drate)(x)
x = Flatten()(x)
x = Dense(n_channels)(x)
D_out = Dense(2, activation='sigmoid')(x)
D = Model(D_in, D_out)
dopt = Adam(lr=lr)
D.compile(loss='binary_crossentropy', optimizer=dopt)
return D, D_out
D_in = Input(shape=[50])
D, D_out = get_discriminative(D_in)
D.summary()
#sec
def set_trainability(model, trainable=False):
model.trainable = trainable
for layer in model.layers:
layer.trainable = trainable
def make_gan(GAN_in, G, D):
set_trainability(D, False)
x = G(GAN_in)
GAN_out = D(x)
GAN = Model(GAN_in, GAN_out)
GAN.compile(loss='binary_crossentropy', optimizer=G.optimizer)
return GAN, GAN_out
GAN_in = Input([10])
GAN, GAN_out = make_gan(GAN_in, G, D)
GAN.summary()
#sec
def sample_data_and_gen(G, noise_dim=10, n_samples=10000):
XT = sample_data(n_samples=n_samples)
XN_noise = np.random.uniform(0, 1, size=[n_samples, noise_dim])
XN = G.predict(XN_noise)
X = np.concatenate((XT, XN))
y = np.zeros((2*n_samples, 2))
y[:n_samples, 1] = 1
y[n_samples:, 0] = 1
return X, y
def pretrain(G, D, noise_dim=10, n_samples=10000, batch_size=32):
X, y = sample_data_and_gen(G, n_samples=n_samples, noise_dim=noise_dim)
set_trainability(D, True)
D.fit(X, y, epochs=1, batch_size=batch_size)
pretrain(G, D)
#sec
def sample_noise(G, noise_dim=10, n_samples=10000):
X = np.random.uniform(0, 1, size=[n_samples, noise_dim])
y = np.zeros((n_samples, 2))
y[:, 1] = 1
return X, y
def train(GAN, G, D, epochs=200, n_samples=10000, noise_dim=10, batch_size=32, verbose=False, v_freq=50):
d_loss = []
g_loss = []
e_range = range(epochs)
if verbose:
e_range = tqdm(e_range)
for epoch in e_range:
X, y = sample_data_and_gen(G, n_samples=n_samples, noise_dim=noise_dim)
set_trainability(D, True)
d_loss.append(D.train_on_batch(X, y))
X, y = sample_noise(G, n_samples=n_samples, noise_dim=noise_dim)
set_trainability(D, False)
g_loss.append(GAN.train_on_batch(X, y))
if verbose and (epoch + 1) % v_freq == 0:
print("Epoch #{}: Generative Loss: {}, Discriminative Loss: {}".format(epoch + 1, g_loss[-1], d_loss[-1]))
return d_loss, g_loss
d_loss, g_loss = train(GAN, G, D, verbose=True)
#sec
ax = pd.DataFrame(
{
'Generative Loss': g_loss,
'Discriminative Loss': d_loss,
}
).plot(title='Training loss', logy=True)
ax.set_xlabel("Epochs")
ax.set_ylabel("Loss")
plt.show()
#sec
N_VIEWED_SAMPLES = 2
data_and_gen, _ = sample_data_and_gen(G, n_samples=N_VIEWED_SAMPLES)
pd.DataFrame(np.transpose(data_and_gen[N_VIEWED_SAMPLES:])).plot()
plt.show()
#sec
N_VIEWED_SAMPLES = 2
data_and_gen, _ = sample_data_and_gen(G, n_samples=N_VIEWED_SAMPLES)
pd.DataFrame(np.transpose(data_and_gen[N_VIEWED_SAMPLES:])).rolling(5).mean()[5:].plot()
plt.show()
参考:
https://blog.csdn.net/tanmx219/article/details/88074600
https://blog.csdn.net/xqf1528399071/article/details/53385593
Keras入门——(3)生成式对抗网络GAN的更多相关文章
- 生成式对抗网络GAN 的研究进展与展望
生成式对抗网络GAN的研究进展与展望.pdf 摘要: 生成式对抗网络GAN (Generative adversarial networks) 目前已经成为人工智能学界一个热门的研究方向. GAN的基 ...
- 【CV论文阅读】生成式对抗网络GAN
生成式对抗网络GAN 1. 基本GAN 在论文<Generative Adversarial Nets>提出的GAN是最原始的框架,可以看成极大极小博弈的过程,因此称为“对抗网络”.一般 ...
- 生成式对抗网络(GAN)实战——书法字体生成练习赛
https://www.tinymind.cn/competitions/ai 生成式对抗网络(GAN)是近年来大热的深度学习模型. 目前GAN最常使用的场景就是图像生成,作为一种优秀的生成式模型,G ...
- 【神经网络与深度学习】生成式对抗网络GAN研究进展(五)——Deep Convolutional Generative Adversarial Nerworks,DCGAN
[前言] 本文首先介绍生成式模型,然后着重梳理生成式模型(Generative Models)中生成对抗网络(Generative Adversarial Network)的研究与发展.作者 ...
- 不要怂,就是GAN (生成式对抗网络) (一)
前面我们用 TensorFlow 写了简单的 cifar10 分类的代码,得到还不错的结果,下面我们来研究一下生成式对抗网络 GAN,并且用 TensorFlow 代码实现. 自从 Ian Goodf ...
- 不要怂,就是GAN (生成式对抗网络) (一): GAN 简介
前面我们用 TensorFlow 写了简单的 cifar10 分类的代码,得到还不错的结果,下面我们来研究一下生成式对抗网络 GAN,并且用 TensorFlow 代码实现. 自从 Ian Goodf ...
- 生成式对抗网络(GAN)学习笔记
图像识别和自然语言处理是目前应用极为广泛的AI技术,这些技术不管是速度还是准确度都已经达到了相当的高度,具体应用例如智能手机的人脸解锁.内置的语音助手.这些技术的实现和发展都离不开神经网络,可是传统的 ...
- AI 生成式对抗网络(GAN)
生成式对抗网络(Generative Adversarial Network,简称GAN),主要由两部分构成:生成模型G和判别模型D.训练GAN就是两种模型的对抗过程. 生成模型:利用任意噪音(ran ...
- GAN生成式对抗网络(四)——SRGAN超高分辨率图片重构
论文pdf 地址:https://arxiv.org/pdf/1609.04802v1.pdf 我的实际效果 清晰度距离我的期待有距离. 颜色上面存在差距. 解决想法 增加一个颜色判别器.将颜色值反馈 ...
随机推荐
- IMDB-TOP_250-爬虫
这个小学期Python大作业搞了个获取IMDB TOP 250电影全部信息的爬虫.第二次写爬虫,比在暑假集训时写的熟练多了.欢迎大家评论. ''' ************************** ...
- (一)tensorflow-gpu2.0学习笔记之开篇(cpu和gpu计算速度比较)
摘要: 1.以动态图形式计算一个简单的加法 2.cpu和gpu计算力比较(包括如何指定cpu和gpu) 3.关于gpu版本的tensorflow安装问题,可以参考另一篇博文:https://www.c ...
- SpringBoot 配置 Redis 多缓存名(不同缓存名缓存失效时间不同)
import com.google.common.collect.ImmutableMap; import org.springframework.cache.CacheManager; import ...
- [CISCN2019 华北赛区 Day1 Web1]Dropbox
0x01 前言 通常我们在利用反序列化漏洞的时候,只能将序列化后的字符串传入unserialize(),随着代码安全性越来越高,利用难度也越来越大.但在不久前的Black Hat上,安全研究员Sam ...
- 「题解」Just A String
目录 题目 原题目 简易题意 思路及分析 代码 题目 原题目 点这里 简易题意 现定义一个合法的字符串满足将其打散并任意组合之后能够形成回文串. 给你 \(m\) 种字母,问随机构成长度为 \(n\) ...
- PyQt5单元格操作大全
1.显示二维列表数据(QTableView)控件 '''显示二维列表数据(QTableView)控件数据源model需要创建一个QTableView实例和一个数据源model,然后将其两者关联 MVC ...
- Educational Codeforces Round 82 B. National Project
Your company was appointed to lay new asphalt on the highway of length nn. You know that every day y ...
- vs2008每次build都会重新编译链接 && 项目已经过期
转自:http://blog.csdn.net/movezzzz/article/details/6816605 无外乎两种情况: 1.时间问题,所创建的文件的时间比如是:2011-09-22 09: ...
- proto school tutorial: blog: lesson 1
https://proto.school/#/blog/01 我们现在希望:把一个post 和他的作者联系起来. 从之前的教程here中,你可以知道, 一个cid 就是代表一个link 比如: { l ...
- linux动态监控dstat&&glances&&psutil&&bottle
安装dstat yum install dstat 安装glances yum install python-devel pip install glances 如果我们安装了 Bottle 这个 w ...