[YOLO]《You Only Look Once: Unified, Real-Time Object Detection》笔记
一、简单介绍
目标检测(Objection Detection)算是计算机视觉任务中比较常见的一个任务,该任务主要是对图像中特定的目标进行定位,通常是由一个矩形框来框出目标。
在深度学习CNN之前,传统的做法一般是借助图像处理技术提取图像中目标的特征(如最常见的SIFT、LBP、HOG等),然后采用机器学习的方法(如SVM等)来训练识别,在实现上通常是采用不同尺度的矩形窗口在图像上滑动提取特征在进行识别(有点像是小尺寸图像分类识别的意思)。
在深度学习和CNN爆红之后,很多研究者就开始用用CNN来做目标检测,比较早期的有OverFeat、R-CNN系列,R-CNN系列是一个比较有名的系列,但是方法上属于二阶检测算法,实现上还是比较麻烦且速度不够快。
所以就出现了一阶检测算法,比较早期且有名的就是SSD、YOLO等。YOLO现在也是一个系列,目前已经有v1、v2(又叫YOLO9000)、v3、TinyYOLO等。最近因为做了一些目标检测的工作,所以先看了YOLO v1的论文。
YOLO是一个可以实现CNN端到端(end-to-end)的一阶目标检测算法,直接采用CNN对输入的图像进行特征提取,之后根据提取到的CNN特征对目标检测框的坐标和大小等信息进行回归预测,也就是说将目标检测转换为一个回归问题来处理。

二、设计思路
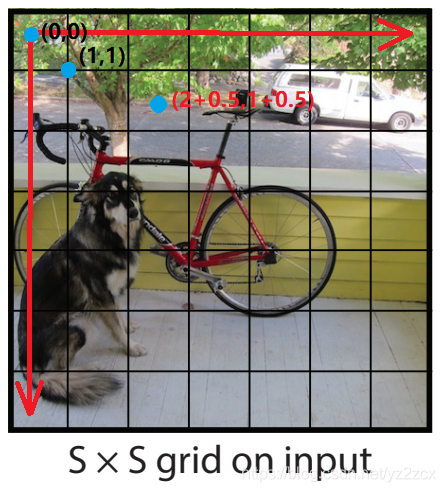
在YOLO的网络结构上,其主干网络还是采用了非常常见的CNN结构,也是常见的卷积层操作、池化层下采样等,但是YOLO最后的全连接层输出的是一个三维的张量,之所以这样做,是因为在YOLO中,对图像进行了一个硬划分,也就是将图像人为地划分为S×S个大小一致的网格(也就是论文中的grid cell),如下图:

但是这种划分是对最后输出的特征图进行划分,所以可以看到在YOLOv1的网络结构中,最后一层全连接层的特征图分辨率为S×S。
所以,将图像划分为S×S个网格之后,每个网格都要预测B个边界框(bounding box)以及每个边界框的置信度,置信度反映了两个问题:
- 模型对于当前网格预测出来的这个边界框,其是否包含有目标;
- 这个边界框有多准确。
所以,在论文中,置信度的定义公式为:
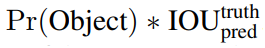
其中
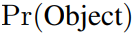
表示当前边界框包含目标的概率,
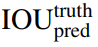
表示边界框与标签之间的交并比,也就是说置信度表示的是:
- 如果当前的网格中不包含目标,那么置信度就等于0;
- 如果当前网格中包含目标,那么置信度就应该是边界框与标签之间的交并比;
以上是边界框的置信度的定义,那么,边界框在网络中是如何定义的?YOLO的输出层每个边界框定义为四个信息:边界中心点的坐标(x,y)、边界框的宽高(w,h),其中中心点坐标是相对于当前网格偏移量归一化到[0,1]之间,边界框的宽高则是相对于整幅图像的宽高归一化到[0,1]之间,因此每个边界框包含的信息有五个:x、y、w、h、confidence。

关于x、y、w、h四个变量,在训练和预测的过程中是要归一化到[0,1]之间的,具体的归一化的计算论文中没有给出来,但是看了很多论文和一些实现的代码,我大概推测其计算如下:
首先,因为YOLO将图像划分为S×S,所以每个网格的宽高为:
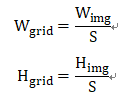
所以,标记的原始坐标转换为:
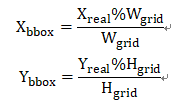
标记的宽高的转换为:
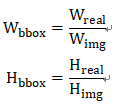
前面只是包含了边界框的信息,但是不包含边界框中的目标的类别信息,因此YOLO的输出中除了上述五个信息之外,还包含了一个概率信息,也就是当前网格属于哪个目标的概率,目标类的概率标签采用的是one-hot编码,所以有多少类就有对应的多少个概率标签。比如,采用VOC数据集的时候包含20类,那么YOLO的输出中就应该包含有20个类分别对应的概率,记作:
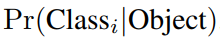
也就是说,不管每个网格预测多少个边界框,都是预测每个网格属于每个类别的概率。所以,如果我们的数据集中有20类,那么每个网格就会预测对应的20个概率。

所以,对于YOLO的输出,每个网格预测的数据维度是:
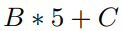
所以整体输出是
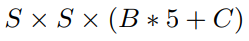
YOLO目标检测的算法模型对于目标的检测流程如下图所示。比如,YOLO使用了PASCAL VOC数据集进行预测,将图像划分为7×7个网格,每个网格预测2个边界框,总共包含20个目标类别,所以YOLOv1的输出数据大小为:7×7×2×5+20。

三、网络结构
YOLO的网络设计借鉴了GoogLeNet,采用了24层卷积层来提取特征,最后采用两层全连接层来输出,同时大量采用了1×1的卷积来减少参数,同时还设计了简化的Fast YOLO,Fast YOLO则是采用了9层卷积层+两层全连接层。网络结构下图所示:

四、模型训练
在模型的训练上,首先是使用上图所示的网络的前20层,后连接一层均值池化层和全连接层在ImageNet数据集上进行训练了大约一周时间,在ImageNet2012的验证集上达到了top5大约88%的准确率。采用Darknet框架来训练。
之后将分类网络转换为目标检测网络,论文提到有相关研究《Object detection networks on convolutional feature maps》认为增加卷积层和全连接层有利于提高性能,因此将前20层保留,后连接4层卷积层和2层全连接层,这六层的参数采用了随机初始化,同时为了更好提高细粒度检测,将网络的输入图像的分辨率从224*224提高到了448*448。
在网络中,对于中间的卷积层之后采用了leaky ReLU激活函数:

而最后一层的激活函数则是直接采用线性激活函数,优化算法上则是直接采用了优化平方和误差。优化平方和误差是因为相对比较简单,容易优化。但是这样的话定位误差和分类误差的权重是一样的,这样可能实际效果不理想,而且图像中可能存在大量网格是没有目标的,也容易引起网络不稳定,同时对于大的边界框和小的边界框的误差权重也是一直的,但是大边界框对误差的容忍度应该要更大。
所以针对上述问题,YOLO提出了几点做法:提高边界框坐标的误差权重,降低无目标网格置信度误差权重,因此引入λcoord和λnoobj,并分别设置为λcoord=5,λnoobj=0.5;对边界框宽高的误差改为宽高的平方根的误差,最终YOLO的损失函数定义为:

其中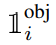 表示目标有出现在第i个网格中,
表示目标有出现在第i个网格中,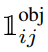 表示第i个网格中的第j个边界框。
表示第i个网格中的第j个边界框。
最后,网络输出的特征在损失函数上的对应关系如下图所示。

标签的转换
在标记目标的时候,一般是只给出了目标边界框的坐标信息和类别信息,但是YOLO的最后输出的是一个S×S×B×5+C的张量,在计算损失的时候也需要标签是与之对应的形式。论文中也没有给出具体的转换方法,但是看了一些博客和源码,大概推测做法如下:
- 初始化一个大小为S×S×B×5+C的标签张量,并初始化为全0;
- 根据标记的bounding box的坐标信息计算bbox的中心落在哪个网格中,则该网格中的该边界框的置信度就标记为1,同时根据坐标、宽高的转换公式计算边界框的坐标和宽高的数值信息,而该类在当前网格中的概率也标记为1。
目标检测
训练好的网络输出是一个S×S×B×5+C的标签张量,该张量实际上就包含了S×S×B个边界框,但是并不是所有边界框都是有用信息或者正确的边界,因此需要筛选。
首先是论文中提到测试阶段会计算每个边界框的class-specific confidence scores,这个分数的计算公式如下:

这个公式表达的是当前这个网格中对于特定类别的置信度,可以认为是当前网格属于某个类的置信度有多大,如果当前没有目标落在这个网格中,那么这个值就应该是0,如果有,那么是可以计算落在这个网格中的目标属于某个类的置信度。
计算了class-specific confidence scores之后,会采用非极大值抑制Non-maximal suppression来筛选出最终的检测结果。
NMS的筛选原则为:对于某个类,将置信度最大的边界框box1作为该类的第一个检测框,将与box1的IoU大于一定的值边界框去掉;接着从剩下的边界框中找到置信度最大的作为检测框box2,同样将与box2的IoU大于一定的值边界框去掉,重复操作直到所有检测框都筛选完。
如何采用NMS来筛选最终的检测结果,论文中没有详细说明,不过看了一些博客,好像有两种做法:
1、第一种做法是,前面计算好class-specific confidence scores之后,就按照其中最大的置信度分数对应的类别作为当前这个边界框的类别预测;设定好一个置信度阈值,将置信度低于阈值的边界框都去掉;接着采用NMS来筛选,但是有个问题是,如果某两个类的置信度最大的边界框是同一个,那这个边界框属于哪个类呢?有两种做法:第一种是每个类单独做NMS,那么就有可能同个边界框会属于两个类或更多;第二种做法是每个边界框都做NMS,不管类是哪个,先选出置信度最大的那个bbox1,然后剩下的边界框中与bbox1重叠率大于一定值的就去掉,重复上述操作,这种做法就建立在不同目标不可能在同个边界框中出现的前提上。
2、第二种做法是,设定好阈值,对于置信度小于阈值的边界框就将置信度设置为0;之后分类别对置信度进行NMS,将被剔除的边界框的置信度设为0;最后对所有置信度不为0的边界框取概率最大的类作为其预测的类,如下图所示,图像来自参考的博客。

这一部分其实对于具体的操作我还不是很确定,所以暂时就这么记录吧。
算法对比
在VOC2007数据集上与几种目标检测算法的对比:

与Fast R-CNN的错误分析对比:

可以看到,总体上还是不如Fast RCNN的,但是YOLO背景的误检会好一点。
性能
优势:快。算法为一阶检测算法,整体而言,相对简单,检测速度快,对背景的误检低,泛化能力好;
不足:每个网格只能检测两个边界框,且每个网格只属于一个类;对小目标的检测性能差,特别是两个目标靠的比较近的时候;定位可能不准确;
参考博客:
[1] 论文:https://arxiv.org/pdf/1506.02640.pdf
[2]官网:https://github.com/pjreddie/darknet
[3] 开源代码:https://github.com/hizhangp/yolo_tensorflow
[4]开源代码2:https://github.com/gliese581gg/YOLO_tensorflow
[5]博客:https://zhuanlan.zhihu.com/p/24916786
[6] 博客:https://blog.csdn.net/m0_37192554/article/details/81092514
[7] 博客:https://blog.csdn.net/c20081052/article/details/8023601
高台不见凤凰游,浩浩长江入海流。
舞罢青蛾同去国,战残白骨尚盈丘。
风摇落日催行棹,潮卷新沙换故洲。
结绮临春无处觅,年年荒草向人愁。
--宋 郭祥正 《凤凰台次李太白韵》
[YOLO]《You Only Look Once: Unified, Real-Time Object Detection》笔记的更多相关文章
- 深度学习论文翻译解析(一):YOLOv3: An Incremental Improvement
论文标题: YOLOv3: An Incremental Improvement 论文作者: Joseph Redmon Ali Farhadi YOLO官网:YOLO: Real-Time Obje ...
- [YOLO]《YOLOv3: An Incremental Improvement》笔记
相比较于前两篇论文,个人感觉YOLO3作者有点来搞笑的!!!虽然加了一些新的点子进来,但是,论文的开头是这样的: 简单理解就是作者花了很多时间玩Twitter去了,所以没有做啥研究!!!! 然后: 你 ...
- 论文阅读笔记三十二:YOLOv3: An Incremental Improvement
论文源址:https://pjreddie.com/media/files/papers/YOLOv3.pdf 代码:https://github.com/qqwweee/keras-yolo3 摘要 ...
- 目标检测(七)YOLOv3: An Incremental Improvement
项目地址 Abstract 该技术报告主要介绍了作者对 YOLOv1 的一系列改进措施(注意:不是对YOLOv2,但是借鉴了YOLOv2中的部分改进措施).虽然改进后的网络较YOLOv1大一些,但是检 ...
- 目标检测:YOLO(v1 to v3)——学习笔记
前段时间看了YOLO的论文,打算用YOLO模型做一个迁移学习,看看能不能用于项目中去.但在实践过程中感觉到对于YOLO的一些细节和技巧还是没有很好的理解,现学习其他人的博客总结(所有参考连接都附于最后 ...
- 从YOLOv1到YOLOv3,目标检测的进化之路
https://blog.csdn.net/guleileo/article/details/80581858 本文来自 CSDN 网站,作者 EasonApp. 作者专栏: http://dwz.c ...
- YOLO v1到YOLO v4(下)
YOLO v1到YOLO v4(下) Faster YOLO使用的是GoogleLeNet,比VGG-16快,YOLO完成一次前向过程只用8.52 billion 运算,而VGG-16要30.69bi ...
- 检测算法简介及其原理——fast R-CNN,faster R-CNN,YOLO,SSD,YOLOv2,YOLOv3
1 引言 深度学习目前已经应用到了各个领域,应用场景大体分为三类:物体识别,目标检测,自然语言处理.本文着重与分析目标检测领域的深度学习方法,对其中的经典模型框架进行深入分析. 目标检测可以理解为是物 ...
- AI佳作解读系列(二)——目标检测AI算法集杂谈:R-CNN,faster R-CNN,yolo,SSD,yoloV2,yoloV3
1 引言 深度学习目前已经应用到了各个领域,应用场景大体分为三类:物体识别,目标检测,自然语言处理.本文着重与分析目标检测领域的深度学习方法,对其中的经典模型框架进行深入分析. 目标检测可以理解为是物 ...
- 论文笔记:目标检测算法(R-CNN,Fast R-CNN,Faster R-CNN,FPN,YOLOv1-v3)
R-CNN(Region-based CNN) motivation:之前的视觉任务大多数考虑使用SIFT和HOG特征,而近年来CNN和ImageNet的出现使得图像分类问题取得重大突破,那么这方面的 ...
随机推荐
- sqlalchemy 连接mysql8.0报 RuntimeError: cryptograpy si requeired for sha256_password 错误
cryptography is required for sha256_password or caching_sha2_password 需要cryptography模块的支持才能连接需要sha25 ...
- JAVA项目开发之文档篇
转自链接:https://blog.csdn.net/Zonzereal/article/details/76704455
- 「TJOI2013」最长上升子序列
「TJOI2013」最长上升子序列 传送门 这个 \(\text{DP}\) 应该都会撒: \[dp_i = \max_{j < i,a_j < a_i}\left\{dp_j\right ...
- 解决新建maven工程没有web.xml的问题
首先确定创建maven工程时选择的打包方式为 war 创建后如图所示没有web.xml文件以及相关文件夹,错误信息:缺少web.xml文件 解决方法: 右击maven项目,找到ProjectFacet ...
- Android_实验小心得_持续补充中......
1.LineLayout布局控件宽度百分比显示 其中,宽度百分比 = 控件权重 / 所在parent中所有控件权重和 <LinearLayout android:layout_width=&qu ...
- 第1节 storm编程:7、并行度分析以及如何解决线程安全问题
storm其实就是一个多进程与多线程的框架 开多个进程:分配到的资源更多 开多个线程:执行的速度更快 设置进程个数以及线程个数 ==================================== ...
- day13-Python运维开发基础(递归与尾递归)
递归与尾递归 # ### 递归函数 """ 递归函数: 自己调用自己的函数 递:去 归:回 有去有回是递归 """ # 简单递归 def d ...
- 五、生产者消费者模型_ThreadLocal
1.生产者消费者模型作用和示例如下:1)通过平衡生产者的生产能力和消费者的消费能力来提升整个系统的运行效率 ,这是生产者消费者模型最重要的作用2)解耦,这是生产者消费者模型附带的作用,解耦意味着生产者 ...
- scikit_learn (sklearn)库中NearestNeighbors(最近邻)函数的各参数说明
NearestNeighbors(n_neighbors=5, radius=1.0, algorithm='auto', leaf_size=30, metric='minkowski', p=2, ...
- 51nod 1445:变色DNA 最短路变形
1445 变色DNA 题目来源: TopCoder 基准时间限制:1 秒 空间限制:131072 KB 分值: 40 难度:4级算法题 收藏 关注 有一只特别的狼,它在每个夜晚会进行变色,研究发现 ...