0 Spark完成WordCount操作
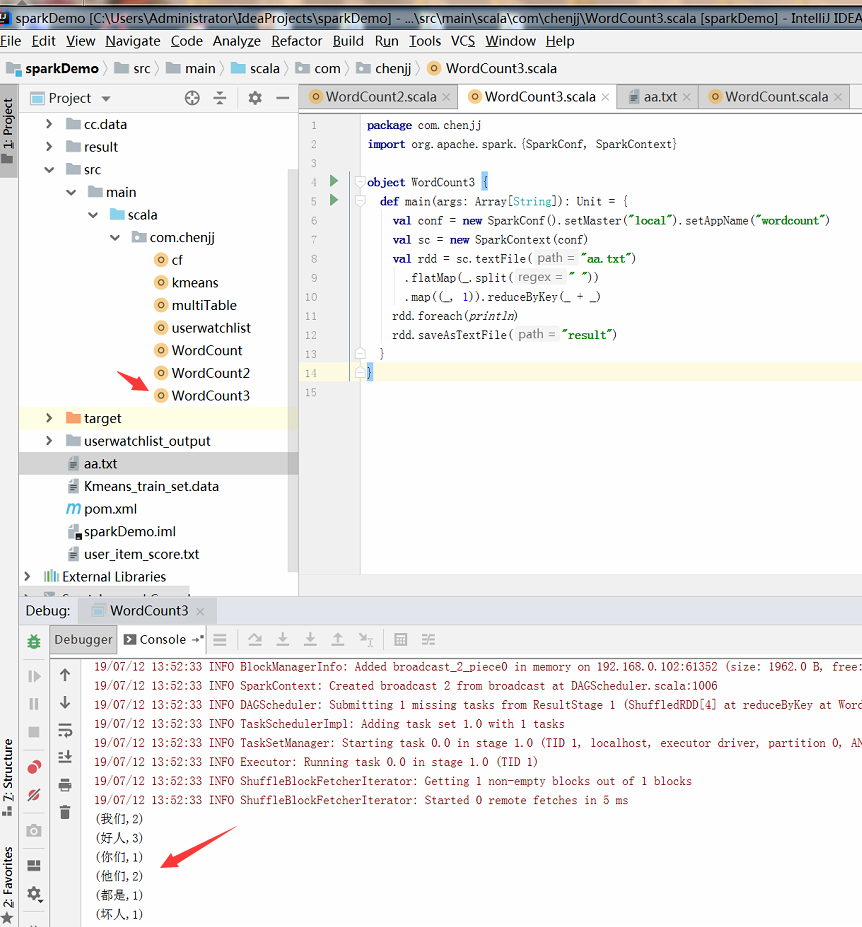
先看下结果:
pom.xml:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.chenjj</groupId>
<artifactId>sparkDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<spark.version>2.2.0</spark.version>
</properties> <repositories>
<repository>
<id>nexus-aliyun</id>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</repository>
</repositories> <dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core_2.10 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.10</artifactId>
<version>1.6.0</version>
</dependency>
</dependencies> <build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.3</version>
<configuration>
<classifier>dist</classifier>
<appendAssemblyId>true</appendAssemblyId>
<descriptorRefs>
<descriptor>jar-with-dependencies</descriptor>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
1、项目目录下新建aa.txt文件
我们 都是 好人
我们 好人 你们 他们
好人 坏人 他们
2、scala版本---WordCount3.scala
package com.chenjj
import org.apache.spark.{SparkConf, SparkContext} object WordCount3 {
def main(args: Array[String]): Unit = {
//conf 可以设置SparkApplication 的名称,设置Spark 运行的模式
val conf = new SparkConf().setMaster("local").setAppName("wordcount")
//SparkContext 是通往spark 集群的唯一通道
val sc = new SparkContext(conf)
val rdd = sc.textFile("aa.txt")
.flatMap(_.split(" "))
.map((_, 1)).reduceByKey(_ + _)
rdd.foreach(println)
rdd.saveAsTextFile("result")
}
}
3、运行结果:

0 Spark完成WordCount操作的更多相关文章
- 在IDEA中编写Spark的WordCount程序
1:spark shell仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在IDE中编制程序,然后打成jar包,然后提交到集群,最常用的是创建一个Maven项目,利用Maven来管理jar包 ...
- 编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本]
编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本] 1. 开发环境 Jdk 1.7.0_72 Maven 3.2.1 Scala 2.10.6 Spark 1.6 ...
- 1.spark的wordcount解析
一.Eclipse(scala IDE)开发local和cluster (一). 配置开发环境 要在本地安装好java和scala. 由于spark1.6需要scala 2.10.X版本的.推荐 2 ...
- [转] 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? [sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需 ...
- 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需要 ...
- spark 对hbase 操作
本文将分两部分介绍,第一部分讲解使用 HBase 新版 API 进行 CRUD 基本操作:第二部分讲解如何将 Spark 内的 RDDs 写入 HBase 的表中,反之,HBase 中的表又是如何以 ...
- .Net for Spark 实现 WordCount 应用及调试入坑详解
.Net for Spark 实现WordCount应用及调试入坑详解 1. 概述 iNeuOS云端操作系统现在具备物联网.视图业务建模.机器学习的功能,但是缺少一个计算平台产品.最近在调研使用 ...
- spark shuffle写操作三部曲之UnsafeShuffleWriter
前言 在前两篇文章 spark shuffle的写操作之准备工作 中引出了spark shuffle的三种实现,spark shuffle写操作三部曲之BypassMergeSortShuffleWr ...
- spark shuffle写操作之SortShuffleWriter
提出问题 1. spark shuffle的预聚合操作是如何做的,其中底层的数据结构是什么?在数据写入到内存中有预聚合,在读溢出文件合并到最终的文件时是否也有预聚合操作? 2. shuffle数据的排 ...
随机推荐
- Nodejs操作MySQL - 增删改查
先安装npm模块项目 npm init 安装mysql npm install mysql --save Nodejs 连接msyql // 导入mysql const mysql = require ...
- ABP开发框架前后端开发系列---(7)系统审计日志和登录日志的管理
我们了解ABP框架内部自动记录审计日志和登录日志的,但是这些信息只是在相关的内部接口里面进行记录,并没有一个管理界面供我们了解,但是其系统数据库记录了这些数据信息,我们可以为它们设计一个查看和导出这些 ...
- 简单看看java之枚举
枚举类这个类用的比较少,对这个不怎么熟悉,最近看源码刚好可以好好了解一下,那么,枚举Enum是什么呢?在jdk中,Enum是一个抽象类下图所示,这就说明这个类是不能进行实例化的,那么我们应该怎么使用呢 ...
- Python自学day-10
一.多进程 程序中, 大量的计算占用CPU资源,而IO操作不占CPU资源.当程序需要进行大量计算时,Python采用多线程运行的速度不一定比单线程快多少.但是当程序是IO密集型的,那就应该使用多线程来 ...
- HTML连载19-子元素选择器&交集选择器
一.子元素选择器 1.定义:找到指定标签中所有特定的直接子元素,然后设置属性 2.格式: 标签名称一>标签名称2{ 属性:值: } 3.释义:先找到叫做“标签名称1”的标签,然后在这个标签中查找 ...
- NumPy基础操作
NumPy基础操作(1) (注:记得在文件开头导入import numpy as np) 目录: 数组的创建 强制类型转换与切片 布尔型索引 结语 数组的创建 相关函数 np.array(), np. ...
- Java连载3-编译与运行阶段详解&JRE,JDK,JVM关系
·一. 1.JDK下载地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk12-downloads-5295953.html ...
- HashMap原理(二) 扩容机制及存取原理
我们在上一个章节<HashMap原理(一) 概念和底层架构>中讲解了HashMap的存储数据结构以及常用的概念及变量,包括capacity容量,threshold变量和loadFactor ...
- HDU 5792:World is Exploding(树状数组求逆序对)
http://acm.hdu.edu.cn/showproblem.php?pid=5792 World is Exploding Problem Description Given a sequ ...
- Win10自动更新关闭方法
一.为什么很多人会选择禁用Win10自动更新? 1.win10自动更新定义: Win 10的自动更新功能,即 Windows Update.这项功能本意是为一些软件.漏洞等提供更新服务.一般来说,只要 ...