【Python3爬虫】当爬虫碰到表单提交,有点意思
一、写在前面
我写爬虫已经写了一段时间了,对于那些使用GET请求或者POST请求的网页,爬取的时候都还算得心应手。不过最近遇到了一个有趣的网站,虽然爬取的难度不大,不过因为表单提交的存在,所以一开始还是有点摸不着头脑。至于最后怎么解决的,请慢慢往下看。
二、页面分析
这次爬取的网站是:https://www.ctic.org/crm?tdsourcetag=s_pctim_aiomsg,该网站提供了美国的一些农田管理的数据。要查看具体的数据,需要选择年份、单位、地区、作物种类等,如下图:
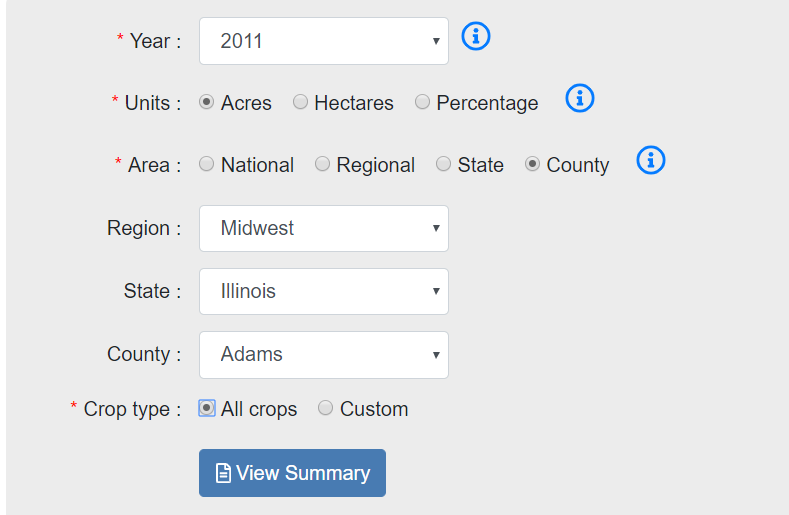
根据以往的经验,这种表单提交都是通过ajax来完成的,所以熟练地按F12打开开发者工具,选择XHR选项,然后点击“View Summary”,结果却什么都没有......
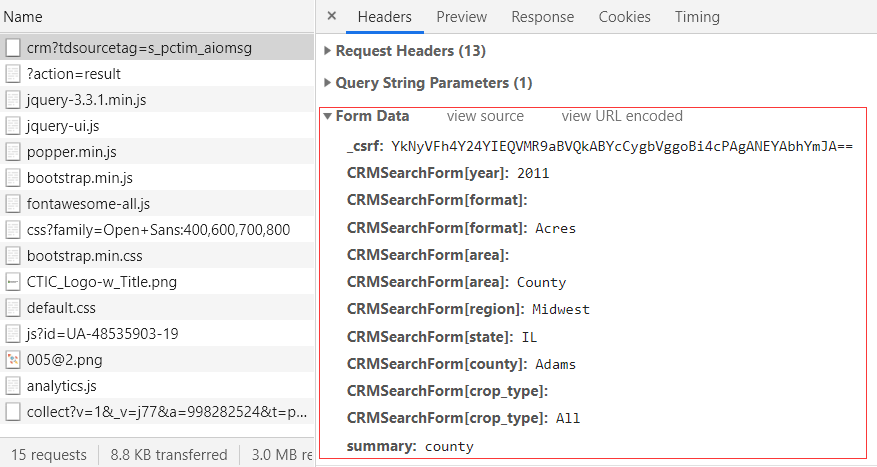
这是怎么回事?不急,切换到All看一下有没有什么可疑的东西。果然就找到了下面这个,可以看到在Form Data中包含了很多参数,而且可以很明显看出来是一些年份、地区等信息,这就是表单提交的内容:
可以注意到在这些参数中有一个_csrf,很明显是一个加密参数,那么要怎么得到这个参数呢?返回填写表单的网页,在开发者工具中切换到Elements,然后搜索_csrf看看,很快就找到了如下信息:

其余参数都是表单中所选择的内容,只要对应填写就行了。不过这个请求返回的状态码是302,为什么会是302呢?302状态码的使用场景是请求的资源暂时驻留在不同的URI下,因此还需要继续寻找。

通过进一步查找可知,最终的URL是:https://www.ctic.org/crm/?action=result。
三、主要步骤
1.爬取郡县信息
可以看到表单中包含了地区、州、郡县选项,在填写表单的时候,这一部分都是通过JS来实现的。打开开发者工具,然后在页面上点选County,选择Region和State,就能在开发者工具中找到相应的请求。主要有两个请求,如下:
https://www.ctic.org/admin/custom/crm/getstates/
https://www.ctic.org/admin/custom/crm/getcounties/
这两个请求返回的结果格式如下图:
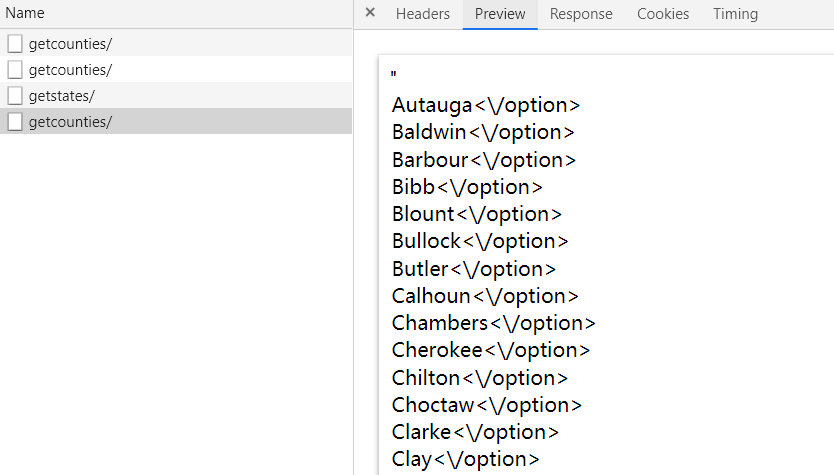
这里可以使用正则匹配,也可以使用lxml来解析,我选择使用后者。示例代码如下:
from lxml import etree html = '"<option value=\"Autauga\">Autauga<\/option><option value=\"Baldwin\">Baldwin<\/option><option value=\"Barbour\">Barbour<\/option><option value=\"Bibb\">Bibb<\/option><option value=\"Blount\">Blount<\/option><option value=\"Bullock\">Bullock<\/option><option value=\"Butler\">Butler<\/option><option value=\"Calhoun\">Calhoun<\/option><option value=\"Chambers\">Chambers<\/option><option value=\"Cherokee\">Cherokee<\/option><option value=\"Chilton\">Chilton<\/option><option value=\"Choctaw\">Choctaw<\/option><option value=\"Clarke\">Clarke<\/option><option value=\"Clay\">Clay<\/option><option value=\"Cleburne\">Cleburne<\/option><option value=\"Coffee\">Coffee<\/option><option value=\"Colbert\">Colbert<\/option><option value=\"Conecuh\">Conecuh<\/option><option value=\"Coosa\">Coosa<\/option><option value=\"Covington\">Covington<\/option><option value=\"Crenshaw\">Crenshaw<\/option><option value=\"Cullman\">Cullman<\/option><option value=\"Dale\">Dale<\/option><option value=\"Dallas\">Dallas<\/option><option value=\"Dekalb\">Dekalb<\/option><option value=\"Elmore\">Elmore<\/option><option value=\"Escambia\">Escambia<\/option><option value=\"Etowah\">Etowah<\/option><option value=\"Fayette\">Fayette<\/option><option value=\"Franklin\">Franklin<\/option><option value=\"Geneva\">Geneva<\/option><option value=\"Greene\">Greene<\/option><option value=\"Hale\">Hale<\/option><option value=\"Henry\">Henry<\/option><option value=\"Houston\">Houston<\/option><option value=\"Jackson\">Jackson<\/option><option value=\"Jefferson\">Jefferson<\/option><option value=\"Lamar\">Lamar<\/option><option value=\"Lauderdale\">Lauderdale<\/option><option value=\"Lawrence\">Lawrence<\/option><option value=\"Lee\">Lee<\/option><option value=\"Limestone\">Limestone<\/option><option value=\"Lowndes\">Lowndes<\/option><option value=\"Macon\">Macon<\/option><option value=\"Madison\">Madison<\/option><option value=\"Marengo\">Marengo<\/option><option value=\"Marion\">Marion<\/option><option value=\"Marshall\">Marshall<\/option><option value=\"Mobile\">Mobile<\/option><option value=\"Monroe\">Monroe<\/option><option value=\"Montgomery\">Montgomery<\/option><option value=\"Morgan\">Morgan<\/option><option value=\"Perry\">Perry<\/option><option value=\"Pickens\">Pickens<\/option><option value=\"Pike\">Pike<\/option><option value=\"Randolph\">Randolph<\/option><option value=\"Russell\">Russell<\/option><option value=\"Shelby\">Shelby<\/option><option value=\"St Clair\">St Clair<\/option><option value=\"Sumter\">Sumter<\/option><option value=\"Talladega\">Talladega<\/option><option value=\"Tallapoosa\">Tallapoosa<\/option><option value=\"Tuscaloosa\">Tuscaloosa<\/option><option value=\"Walker\">Walker<\/option><option value=\"Washington\">Washington<\/option><option value=\"Wilcox\">Wilcox<\/option><option value=\"Winston\">Winston<\/option>"'
et = etree.HTML(html)
result = et.xpath('//option/text()')
result = [i.rstrip('"') for i in result]
print(result)
上面代码输出的结果为:
['Autauga', 'Baldwin', 'Barbour', 'Bibb', 'Blount', 'Bullock', 'Butler', 'Calhoun', 'Chambers', 'Cherokee', 'Chilton', 'Choctaw', 'Clarke', 'Clay', 'Cleburne', 'Coffee', 'Colbert', 'Conecuh', 'Coosa', 'Covington', 'Crenshaw', 'Cullman', 'Dale', 'Dallas', 'Dekalb', 'Elmore', 'Escambia', 'Etowah', 'Fayette', 'Franklin', 'Geneva', 'Greene', 'Hale', 'Henry', 'Houston', 'Jackson', 'Jefferson', 'Lamar', 'Lauderdale', 'Lawrence', 'Lee', 'Limestone', 'Lowndes', 'Macon', 'Madison', 'Marengo', 'Marion', 'Marshall', 'Mobile', 'Monroe', 'Montgomery', 'Morgan', 'Perry', 'Pickens', 'Pike', 'Randolph', 'Russell', 'Shelby', 'St Clair', 'Sumter', 'Talladega', 'Tallapoosa', 'Tuscaloosa', 'Walker', 'Washington', 'Wilcox', 'Winston']
获取所有郡县信息的思路为分别选择四个地区,然后遍历每个地区下面的州,再遍历每个州所包含的郡县,最终得到所有郡县信息。
2.爬取农田数据
在得到郡县信息之后,就可以构造获取农田数据的请求所需要的参数了。在获取农田数据之前,需要向服务器发送一个提交表单的请求,不然是得不到数据的。在我测试的时候,发送提交表单的请求的时候,返回的状态码并不是302,不过这并不影响之后的操作,所以可以忽略掉。
需要注意的是,参数中是有一个年份信息的,前面我一直是默认用的2011,不过要爬取更多信息的话,还需要改变这个年份信息。而通过选择页面元素可以知道,这个网站提供了16个年份的农田数据信息,这16个年份为:
[1989,1990,1991,1992,1993,1994,1995,1996,1997,1998,2002,2004,2006,2007,2008,2011]
得到这些年份信息之后,就可以和前面的郡县信息进行排列组合得到所有提交表单的请求所需要的参数。说道排列组合,一般会用for循环来实现,不过这里推荐一种方法,就是使用itertools.product,使用示例如下:
from itertools import product a = [1, 2, 3]
b = [2, 4]
result = product(a, b)
for i in result:
print(i, end=" ") # (1, 2) (1, 4) (2, 2) (2, 4) (3, 2) (3, 4)
下面是农田数据的部分截图,其中包含了很多种类的作物,还有对应的耕地面积信息,不过在这个表中有些我们不需要的信息,比如耕地面积总量信息,还有空白行,这都是干扰数据,在解析的时候要清洗掉。
解析农田数据部分的代码如下:
et = etree.HTML(html)
crop_list = et.xpath('//*[@id="crm_results_eight"]/tbody/tr/td[1]/text()') # 作物名称
area_list = et.xpath('//*[@id="crm_results_eight"]/tbody/tr/td[2]/text()') # 耕地面积
conservation_list = et.xpath('//*[@id="crm_results_eight"]/tbody/tr/td[6]/text()') # 受保护耕地面积
crop_list = crop_list[:-3]
area_list = area_list[:-3]
conservation_list = conservation_list[:-3]
完整代码已上传到GitHub!
【Python3爬虫】当爬虫碰到表单提交,有点意思的更多相关文章
- 结合API Gateway和Lambda实现登录时的重定向和表单提交请求(Python3实现)
1. 创建Lambda函数,代码如下: from urllib import parse def lambda_handler(event, context): body = event['body' ...
- 用python模拟登录(解析cookie + 解析html + 表单提交 + 验证码识别 + excel读写 + 发送邮件)
老婆大人每个月都要上一个网站上去查数据,然后做报表. 为了减轻老婆大人的工作压力,所以我决定做个小程序,减轻我老婆的工作量. 准备工作 1.tesseract-ocr 这个工具用来识别验证码,非常好用 ...
- scrapy formRequest 表单提交
scrapy.FormRequest 主要用于提交表单数据 先来看一下源码 参数: formdata (dict or iterable of tuples) – is a dictionary ( ...
- 阻止form表单提交的问题
阻止form表单提交这种场景可能在生活中,我们经常碰到,而在我们第一印象里面可能我们用return false 去阻止表单默认行为. 但是,有中情况我们用return false 不能阻止表单提交 & ...
- CodeIgniter典型的表单提交验证代码
view内容: <?php echo form_open('user/reg'); ?> <h5>用户名</h5> <input type="tex ...
- form表单提交数据编码方式和tomcat接受数据解码方式的思考
http://blog.sina.com.cn/s/blog_95c8f1ac010198j2.html *********************************************** ...
- Django框架之第二篇--app注册、静态文件配置、form表单提交、pycharm连接数据库、django使用mysql数据库、表字段的增删改查、表数据的增删改查
本节知识点大致为:静态文件配置.form表单提交数据后端如何获取.request方法.pycharm连接数据库,django使用mysql数据库.表字段的增删改查.表数据的增删改查 一.创建app,创 ...
- from表单提交数据之后,后台对象接受不到值
如果SSH框架下,前段页面通过from表单提交数据之后,在后台对象显示空值,也就是接收不到值得情况下.首先保证前段输入框有值,这个可以在提交的时候用jQuery的id或者name选择器alert弹出测 ...
- 不使用Ajax,如何实现表单提交不刷新页面
不使用Ajax,如何实现表单提交不刷新页面? 目前,我想到的是使用<iframe>,如果有其他的方式,后续再补. 举个栗子: 在表单上传文件的时候必须设置enctype="mul ...
随机推荐
- RocketMQ 可视化环境搭建和基础代码使用
RocketMQ 是一款分布式消息中间件,最初是由阿里巴巴消息中间件团队研发并大规模应用于生产系统,满足线上海量消息堆积的需求, 在 2016 年底捐赠给 Apache 开源基金会成为孵化项目,经过不 ...
- 【转载】BIO、NIO、AIO
请看原文,排版更佳>转载请注明出处:http://blog.csdn.net/anxpp/article/details/51512200,谢谢! 本文会从传统的BIO到NIO再到AIO自浅至深 ...
- idea创建类报错
创建类报错: 在idea.exe.vmoptions 或 idea64.exe.vmoptions中加入配置 -Djdk.util.zip.ensureTrailingSlash=false jar包 ...
- webpack打包工具的初级使用方法
这里下载的是webpack的3.8.1版本(新版更新的使用有些问题) 什么是webpack? 他是一个前端资源加载或打包工具,. 资源: img css json等. 下载的话 用 npm webpa ...
- Dungeon Master POJ - 2251(bfs)
对于3维的,可以用结构体来储存,详细见下列代码. 样例可以过,不过能不能ac还不知道,疑似poj炸了, #include<iostream> #include<cstdio> ...
- 使用 cxf的程序 在win10 测试部署时报空指针异常
2018-11-08 15:50:55.072 DEBUG 21524 --- [nio-8080-exec-1] o.s.b.w.s.f.OrderedRequestContextFilter : ...
- Input标签中Type的类型及详细用法
Input表示Form表单中的一种输入对象,其又随Type类型的不同而分文本输入框,密码输入框,单选/复选框,提交/重置按钮等,下面一一介绍.1,type=text输入类型是text,这是我们见的最多 ...
- python数据库-MySQL查询基本操作(50)
一.条件查询 1.使用where子句对表中的数据筛选,结果为true的行会出现在结果集中 select * from 表名 where 条件; 2.比较运算符 等于= 大于> 大于等于>= ...
- java日期在今天的基础上加一个月。并计算时间相差天数
Calendar calendar = Calendar.getInstance(); calendar.setTime(date); calendar.add(Calendar.MONTH, 1); ...
- 音频编辑器 OcenAudio v3.1.9.0 绿色便携版
下载地址:点我 基本介绍 ocenaudio是一款跨平台的,易于使用的,快速的,功能强大的,好用的音频编辑软件.该软件支持Virtual Studio Technology插件,美观.统一的跨平台界面 ...