Norm比较
目录
Introduction
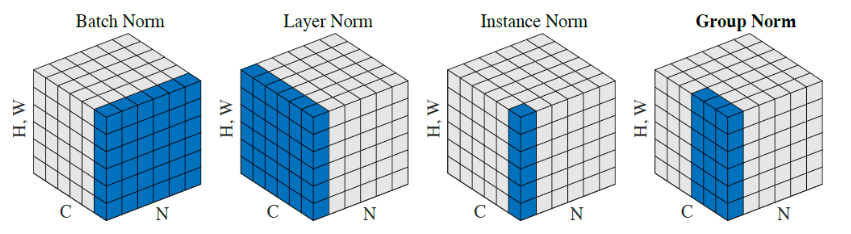
输入图像shape记为[N, C, H, W]
Batch Norm是在batch上,对NHW做归一化,就是对每个单一通道输入进行归一化,这样做对小batchsize效果不好;
Layer Norm在通道方向上,对CHW归一化,就是对每个深度上的输入进行归一化,主要对RNN作用明显;
Instance Norm在图像像素上,对HW做归一化,对一个图像的长宽即对一个像素进行归一化,用在风格化迁移;
Group Norm将channel分组,有点类似于LN,只是GN把channel也进行了划分,细化,然后再做归一化;
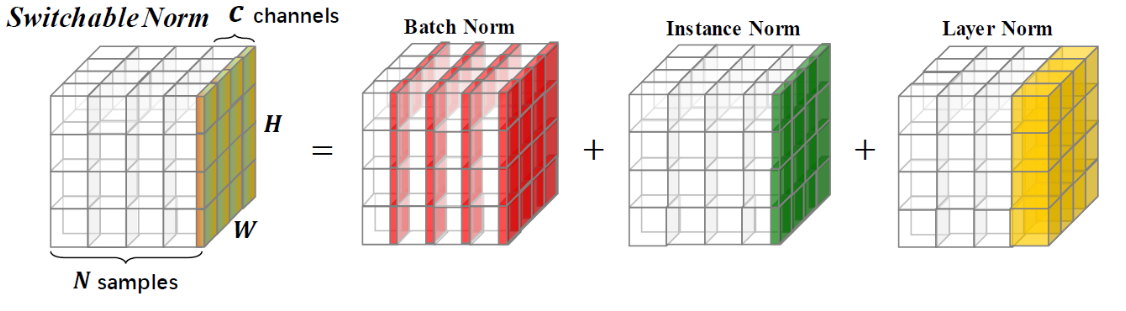
Switchable Norm是将BN、LN、IN结合,赋予权重,让网络自己去学习归一化层应该使用什么方法
BN
我们在对数据训练之前会对数据集进行归一化,归一化的目的归一化的目的就是使得预处理的数据被限定在一定的范围内(比如[0,1]或者[-1,1]),从而消除奇异样本数据导致的不良影响。虽然输入层的数据,已经归一化,后面网络每一层的输入数据的分布一直在发生变化,前面层训练参数的更新将导致后面层输入数据分布的变化,必然会引起后面每一层输入数据分布的改变。而且,网络前面几层微小的改变,后面几层就会逐步把这种改变累积放大。训练过程中网络中间层数据分布的改变称之为:"Internal Covariate Shift"。BN的提出,就是要解决在训练过程中,中间层数据分布发生改变的情况。所以就引入了BN的概念,来消除这种影响。所以在每次传入网络的数据每一层的网络都进行一次BN,将数据拉回正态分布,这样做使得数据分布一致且避免了梯度消失。
此外,internal corvariate shift和covariate shift是两回事,前者是网络内部,后者是针对输入数据,比如我们在训练数据前做归一化等预处理操作。需要注意的是在使用小batch-size时BN会破坏性能,当具有分布极不平衡二分类任务时也会出现不好的结果。因为如果小的batch-size归一化的原因,使得原本的数据的均值和方差偏离原始数据,均值和方差不足以代替整个数据分布。分布不均的分类任务也会出现这种情况!
BN实际使用时需要计算并且保存某一层神经网络batch的均值和方差等统计信息,对于对一个固定深度的前向神经网络(DNN,CNN)使用BN,很方便;但对于RNN来说,sequence的长度是不一致的,换句话说RNN的深度不是固定的,不同的time-step需要保存不同的statics特征,可能存在一个特殊sequence比其他sequence长很多,这样training时,计算很麻烦。
Batch Norm可谓深度学习中非常重要的技术,不仅可以使训练更深的网络变容易,加速收敛,还有一定正则化的效果,可以防止模型过拟合。在很多基于CNN的分类任务中,被大量使用。
但我最近在图像超分辨率和图像生成方面做了一些实践,发现在这类任务中,Batch Norm的表现并不好,加入了Batch Norm,反而使得训练速度缓慢,不稳定,甚至最后发散。
以下是我对这一现象的个人看法,并不严格,还需继续检验。
首先,以图像超分辨率来说,网络输出的图像在色彩、对比度、亮度上要求和输入一致,改变的仅仅是分辨率和一些细节,而Batch Norm,对图像来说类似于一种对比度的拉伸,任何图像经过Batch Norm后,其色彩的分布都会被归一化,也就是说,它破坏了图像原本的对比度信息,所以Batch Norm的加入反而影响了网络输出的质量。虽然Batch Norm中的scale和shift参数可以抵消归一化的效果,但这样就增加了训练的难度和时间,还不如直接不用。不过有一类网络结构可以用,那就是残差网络(Residual Net),但也仅仅是在residual block当中使用,比如SRResNet,就是一个用于图像超分辨率的残差网络。为什么这类网络可以使用Batch Norm呢?我个人理解是,因为图像的对比度信息可以通过skip connection直接传递,所以也就不必担心Batch Norm的破坏了。
基于这种想法,也可以从另外一种角度解释Batch Norm为何在图像分类任务上如此有效。图像分类不需要保留图像的对比度信息,利用图像的结构信息就可以完成分类,所以,将图像都通过Batch Norm进行归一化,反而降低了训练难度,甚至一些不明显的结构,在Batch Norm后也会被凸显出来(对比度被拉开了)。
而对于照片风格转移,为何可以用Batch Norm呢?原因在于,风格化后的图像,其色彩、对比度、亮度均和原图像无关,而只与风格图像有关,原图像只有结构信息被表现到了最后生成的图像中。因此,在照片风格转移的网络中使用Batch Norm或者Instance Norm也就不奇怪了,而且,Instance Norm是比Batch Norm更直接的对单幅图像进行的归一化操作,连scale和shift都没有。
说得更广泛一些,Batch Norm会忽略图像像素(或者特征)之间的绝对差异(因为均值归零,方差归一),而只考虑相对差异,所以在不需要绝对差异的任务中(比如分类),有锦上添花的效果。而对于图像超分辨率这种需要利用绝对差异的任务,Batch Norm只会添乱。
LN
与BN不同的是,LN对每一层的所有神经元进行归一化,与BN不同的是:
LN中同层神经元输入拥有相同的均值和方差,不同的输入样本有不同的均值和方差;
BN中则针对不同神经元输入计算均值和方差,同一个batch中的输入拥有相同的均值和方差。
LN不依赖于batch的大小和输入sequence的深度,因此可以用于batchsize为1和RNN中对边长的输入sequence的normalize操作。
一般情况,LN常常用于RNN网络!
IN
BN注重对每一个batch进行归一化,保证数据分布的一致,因为判别模型中的结果取决与数据的整体分布。在图像风格中,生成结果主要依赖某个图像实例,所以此时对整个batch归一化不适合了,需要对但像素进行归一化,可以加速模型的收敛,并且保持每个图像实例之间的独立性!
GN
主要是针对Batch Normalization对小batchsize效果差,GN将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值,这样与batchsize无关,不受其约束。
SN
- 归一化虽然提高模型泛化能力,然而归一化层的操作是人工设计的。在实际应用中,解决不同的问题原则上需要设计不同的归一化操作,并没有一个通用的归一化方法能够解决所有应用问题;
- 一个深度神经网络往往包含几十个归一化层,通常这些归一化层都使用同样的归一化操作,因为手工为每一个归一化层设计操作需要进行大量的实验。
因此作者提出自适配归一化方法——Switchable Normalization(SN)来解决上述问题。与强化学习不同,SN使用可微分学习,为一个深度网络中的每一个归一化层确定合适的归一化操作。
Conclusion
Norm比较的更多相关文章
- norm函数的作用,matlab
格式:n=norm(A,p)功能:norm函数可计算几种不同类型的返回A中最大一列和,即max(sum(abs(A))) 2 返回A的最大奇异值,和n=norm(A)用法一样 inf 返回A中最大一行 ...
- MATLAB 中NORM运用
格式:n=norm(A,p)功能:norm函数可计算几种不同类型的矩阵范数,根据p的不同可得到不同的范数 以下是Matlab中help norm 的解释 NORM Matrix or vector ...
- (转)几种范数的解释 l0-Norm, l1-Norm, l2-Norm, … , l-infinity Norm
几种范数的解释 l0-Norm, l1-Norm, l2-Norm, - , l-infinity Norm from Rorasa's blog l0-Norm, l1-Norm, l2-Norm, ...
- p范数(p norm)
先回顾一下范数的定义(en.wikipedia.org/wiki/Norm_(mathematics)): Given a vector space V over a subfield F of th ...
- norm函数
如果A为向量 norm(A,p) 返回向量A的p范数. norm(A) 返回向量A的2范数,即等价于norm(A,2).
- matlab norm的使用
格式:n=norm(A,p)功能:norm函数可计算几种不同类型的矩阵范数,根据p的不同可得到不同的范数 以下是Matlab中help norm 的解释 NORM Matrix or vector n ...
- matlab norm 范式
格式:n=norm(A,p) 功能:norm函数可计算几种不同类型的矩阵范数,根据p的不同可得到不同的范数 p 返回值 1 返回A中最大一列和,即max(sum(abs(A))) 2 返回A的 ...
- Matlab norm 用法小记
Matlab norm 用法小记 matlab norm (a) 用法以及实例 norm(A,p)当A是向量时norm(A,p) Returns sum(abs(A).^p)^(1/p), for ...
- matlab中norm与svd函数用法
格式:n=norm(A,p) 功能:norm函数可计算几种不同类型的矩阵范数,根据p的不同可得到不同的范数 以下是Matlab中help norm 的解释: NORM Matrix or vector ...
- Norm 数据库操作竟然可以如此简单
github地址,https://github.com/xcr1234/norm/欢迎各位大神fork&交流! Norm Norm是一套微型的JAVA数据库ORM库,提供了简单高效的 API, ...
随机推荐
- 腾讯,华为,阿里…7家Java后端面试经验大公开!
感觉面试还是主要围绕简历来问的,所以不熟悉的东西最好不要随便写上去.项目和基础都很重要,整体的基础知识的框架可以参考GitHub 上 CYC2018的博客,分类很全,但是深入的学习还是要自己去看书,写 ...
- 表空间相关SQL
--查表空间使用率情况(含临时表空间)SELECT D.TABLESPACE_NAME "Name", D.STATUS "Status", TO_CHAR(N ...
- USB OTG ID 检测原理【转】
OTG 检测的原理是: USB OTG标准在完全兼容USB2.0标准的基础上,增添了电源管理(节省功耗)功能,它允许设备既可作为主机,也可作为外设操作(两用OTG).USB OTG技术可实现没有主机时 ...
- Spring学习的第二天
第二天总共学习了以下内容: spring中的ioc常用注解: 案例使用xml方式和注解方式实现单表的CRUD操作(但还是需要xml配置文件,并不是纯注解的配置): 改造基于注解的Ioc案例,使用纯注解 ...
- docx和doc的区别
docx和doc这两者间就相差一个字母x,可就是这一个简简单单的x有时候也会引申出很多的问题,比如这个案例,在一次研究生期末考试的考查课上,老师要求每个人事先结合自己的思路以及该课程,写一篇报告总结, ...
- Django生命周期
以下信息是个人理解所得,如要转载,请注明转载处! 生命周期?很多人会问生命周期是什么?Django也有生命周期吗?他就是一个框架呀. 我们先来说一说一个西瓜的生命周期,一个西瓜刚开始只是一个种子,种到 ...
- laravel实现多模块
一.这里使用Caffienate Modules 网址:modules maintained by caffeinated 二.根据自己的版本选择包的版本 三.在项目composer.json文件中加 ...
- SpringSession header/cookie/attribute存放 session id
SpringSession header/cookie/attribute存放 SessionID(死磕) 疯狂创客圈 Java 高并发[ 亿级流量聊天室实战]实战系列 [博客园总入口 ] 架构师成长 ...
- C语言程序设计100例之(16):巧解算式
例16 巧解算式 问题描述 在1.2.3.4.5.6.7.8.9.10个数中间加上加号或减号,使得到的表达式的值为自然数N,如果中间没有符号,则认为前后为一个数,如1 2 3认为是一百二十三(123 ...
- 软件测试价值提升之路- 第二章"价值实现的起点"读书笔记
价值实现的起点 2.1 打破常规 打破哪些已经不适应现在软件开发需要的“准则”,明确需要在什么样的环境下.瞄准什么目标来实现测试的价值 找风险:研发内部测试 测试最基础的是找bug,但需要根据风险找最 ...