MySQL实战45讲学习笔记:第三十八讲
一、本节内容
我在上一篇文章末尾留给你的问题是:两个 group by 语句都用了 order by null,为什么使用内存临时表得到的语句结果里,0 这个值在最后一行;而使用磁盘临时表得到的结果
里,0 这个值在第一行?
今天我们就来看看,出现这个问题的原因吧。
二、内存表的数据组织结构
1、两个查询结果 -0 的位置
为了便于分析,我来把这个问题简化一下,假设有以下的两张表 t1 和 t2,其中表 t1 使用Memory 引擎, 表 t2 使用 InnoDB 引擎。
create table t1(id int primary key, c int) engine=Memory;
create table t2(id int primary key, c int) engine=innodb;
insert into t1 values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(0,0);
insert into t2 values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(0,0);
然后,我分别执行 select * from t1 和 select * from t2。

图 1 两个查询结果 -0 的位置
可以看到,内存表 t1 的返回结果里面 0 在最后一行,而 InnoDB 表 t2 的返回结果里 0 在第一行。
出现这个区别的原因,要从这两个引擎的主键索引的组织方式说起。
2、表 t2 的数据组织
表 t2 用的是 InnoDB 引擎,它的主键索引 id 的组织方式,你已经很熟悉了:InnoDB 表的数据就放在主键索引树上,主键索引是 B+ 树。所以表 t2 的数据组织方式如下
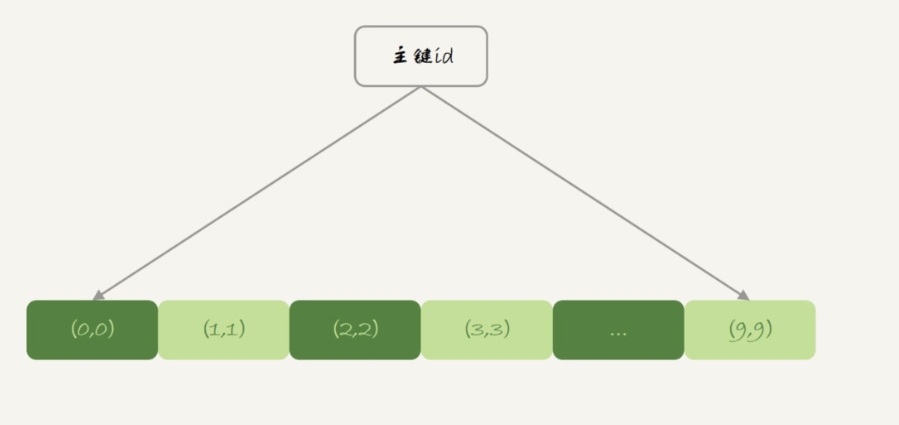
图 2 表 t2 的数据组织
主键索引上的值是有序存储的。在执行 select * 的时候,就会按照叶子节点从左到右扫描,所以得到的结果里,0 就出现在第一行。
3、表 t1 的数据组织
与 InnoDB 引擎不同,Memory 引擎的数据和索引是分开的。我们来看一下表 t1 中的数据内容。

图 3 表 t1 的数据组织
可以看到,内存表的数据部分以数组的方式单独存放,而主键 id 索引里,存的是每个数据的位置。主键 id 是 hash 索引,可以看到索引上的 key 并不是有序的。
在内存表 t1 中,当我执行 select * 的时候,走的是全表扫描,也就是顺序扫描这个数组。因此,0 就是最后一个被读到,并放入结果集的数据。
4、InnoDB 和 Memory 引擎的数据组织方式是不同的
可见,InnoDB 和 Memory 引擎的数据组织方式是不同的:
InnoDB 引擎把数据放在主键索引上,其他索引上保存的是主键 id。这种方式,我们称之为索引组织表(Index Organizied Table)。
而 Memory 引擎采用的是把数据单独存放,索引上保存数据位置的数据组织形式,我们称之为堆组织表(Heap Organizied Table)
从中我们可以看出,这两个引擎的一些典型不同:
1. InnoDB 表的数据总是有序存放的,而内存表的数据就是按照写入顺序存放的;
2. 当数据文件有空洞的时候,InnoDB 表在插入新数据的时候,为了保证数据有序性,只能在固定的位置写入新值,而内存表找到空位就可以插入新值;
3. 数据位置发生变化的时候,InnoDB 表只需要修改主键索引,而内存表需要修改所有索引;
4. InnoDB 表用主键索引查询时需要走一次索引查找,用普通索引查询的时候,需要走两
5. InnoDB 支持变长数据类型,不同记录的长度可能不同;内存表不支持 Blob 和 Text 字段,并且即使定义了 varchar(N),实际也当作 char(N),也就是固定长度字符串来存储,因此内存表的每行数据长度相同。
由于内存表的这些特性,每个数据行被删除以后,空出的这个位置都可以被接下来要插入的数据复用。比如,如果要在表 t1 中执行:
delete from t1 where id=5;
insert into t1 values(10,10);
select * from t1;
就会看到返回结果里,id=10 这一行出现在 id=4 之后,也就是原来 id=5 这行数据的位置。
需要指出的是,表 t1 的这个主键索引是哈希索引,因此如果执行范围查询,比如
select * from t1 where id<5;
是用不上主键索引的,需要走全表扫描。你可以借此再回顾下第 4 篇文章的内容。那如果要让内存表支持范围扫描,应该怎么办呢 ?
三、hash 索引和 B-Tree 索引
1、t1 的数据组织 -- 增加 B-Tree 索引
实际上,内存表也是支 B-Tree 索引的。在 id 列上创建一个 B-Tree 索引,SQL 语句可以这么写:
alter table t1 add index a_btree_index using btree (id);
这时,表 t1 的数据组织形式就变成了这样:
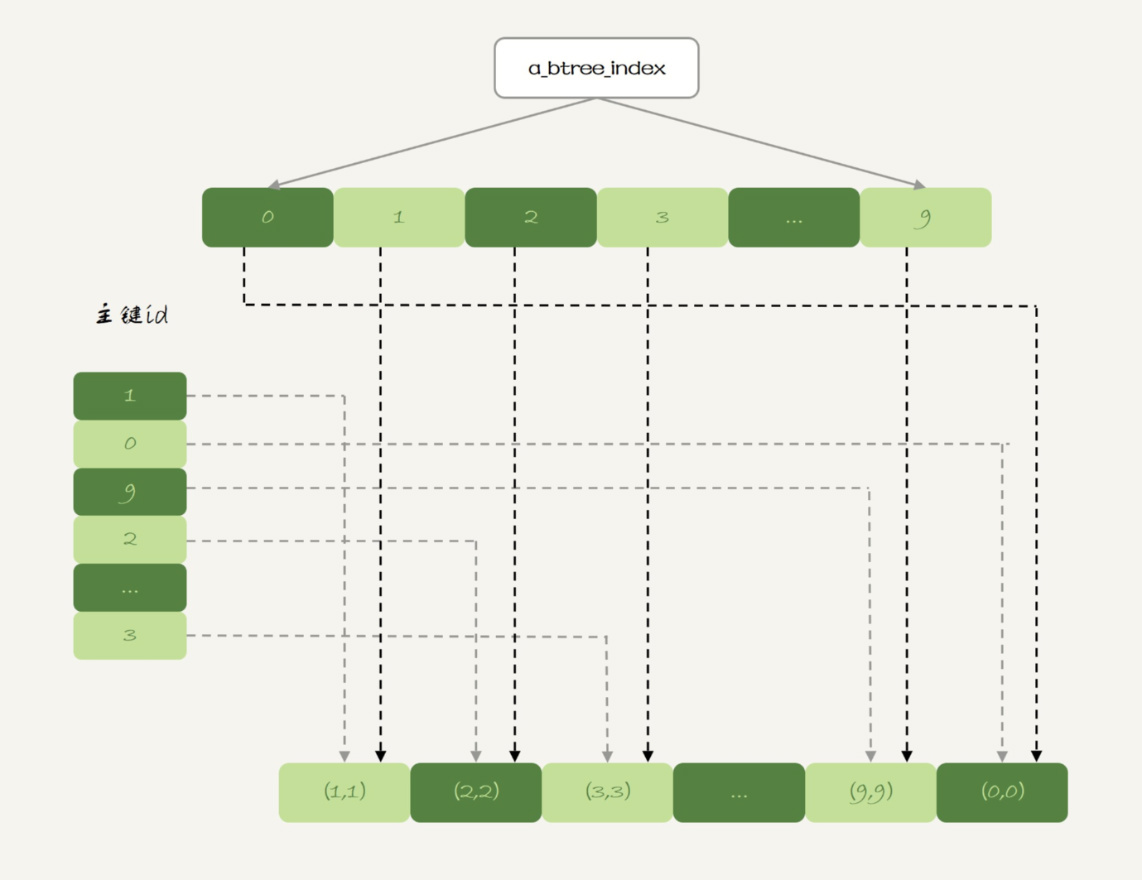
图 4 表 t1 的数据组织 -- 增加 B-Tree 索引
新增的这个 B-Tree 索引你看着就眼熟了,这跟 InnoDB 的 b+ 树索引组织形式类似。
2、B-Tree 和 hash 索引查询返回结果对比
作为对比,你可以看一下这下面这两个语句的输出:

图 5 使用 B-Tree 和 hash 索引查询返回结果对比
可以看到,执行 select * from t1 where id<5 的时候,优化器会选择 B-Tree 索引,所以返回结果是 0 到 4。 使用 force index 强行使用主键 id 这个索引,id=0 这一行就在结果集的最末尾了。
其实,一般在我们的印象中,内存表的优势是速度快,其中的一个原因就是 Memory 引擎支持 hash 索引。当然,更重要的原因是,内存表的所有数据都保存在内存,而内存的
读写速度总是比磁盘快。
但是,接下来我要跟你说明,为什么我不建议你在生产环境上使用内存表。这里的原因主要包括两个方面:
- 1. 锁粒度问题;
- 2. 数据持久化问题。
四、内存表的锁
我们先来说说内存表的锁粒度问题。
内存表不支持行锁,只支持表锁。因此,一张表只要有更新,就会堵住其他所有在这个表上的读写操作。
需要注意的是,这里的表锁跟之前我们介绍过的 MDL 锁不同,但都是表级的锁。接下来,我通过下面这个场景,跟你模拟一下内存表的表级锁。

图 6 内存表的表锁 -- 复现步骤
在这个执行序列里,session A 的 update 语句要执行 50 秒,在这个语句执行期间session B 的查询会进入锁等待状态。session C 的 show processlist 结果输出如下:

图 7 内存表的表锁 -- 结果
跟行锁比起来,表锁对并发访问的支持不够好。所以,内存表的锁粒度问题,决定了它在处理并发事务的时候,性能也不会太好。
五、数据持久性问题
接下来,我们再看看数据持久性的问题。
数据放在内存中,是内存表的优势,但也是一个劣势。因为,数据库重启的时候,所有的内存表都会被清空。
你可能会说,如果数据库异常重启,内存表被清空也就清空了,不会有什么问题啊。但是,在高可用架构下,内存表的这个特点简直可以当做 bug 来看待了。为什么这么说呢?
1、 M-S 基本架构
我们先看看 M-S 架构下,使用内存表存在的问题。
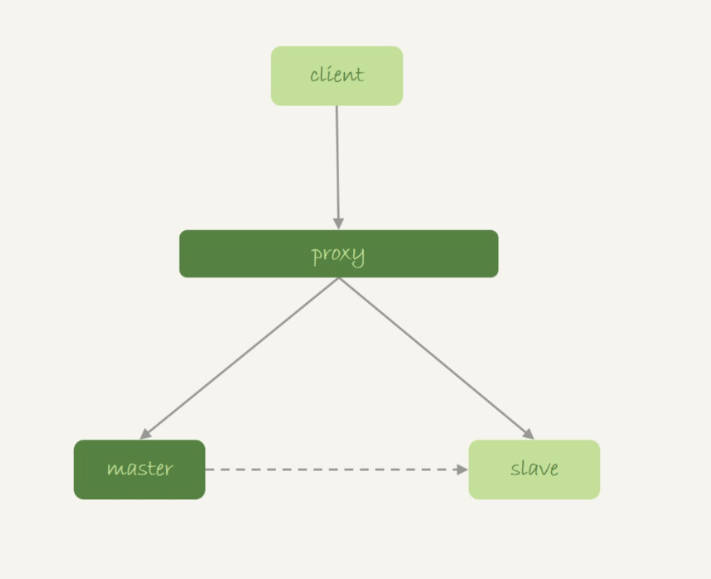
图 8 M-S 基本架构
我们来看一下下面这个时序:
1. 业务正常访问主库;
2. 备库硬件升级,备库重启,内存表 t1 内容被清空;
3. 备库重启后,客户端发送一条 update 语句,修改表 t1 的数据行,这时备库应用线程就会报错“找不到要更新的行”。
这样就会导致主备同步停止。当然,如果这时候发生主备切换的话,客户端会看到,表 t1的数据“丢失”了。
在图 8 中这种有 proxy 的架构里,大家默认主备切换的逻辑是由数据库系统自己维护的。这样对客户端来说,就是“网络断开,重连之后,发现内存表数据丢失了”。
你可能说这还好啊,毕竟主备发生切换,连接会断开,业务端能够感知到异常。
2、双 M 结构
但是,接下来内存表的这个特性就会让使用现象显得更“诡异”了。由于 MySQL 知道重启之后,内存表的数据会丢失。所以,担心主库重启之后,出现主备不一致,MySQL 在
实现上做了这样一件事儿:在数据库重启之后,往 binlog 里面写入一行 DELETE FROMt1。
如果你使用是如图 9 所示的双 M 结构的话:
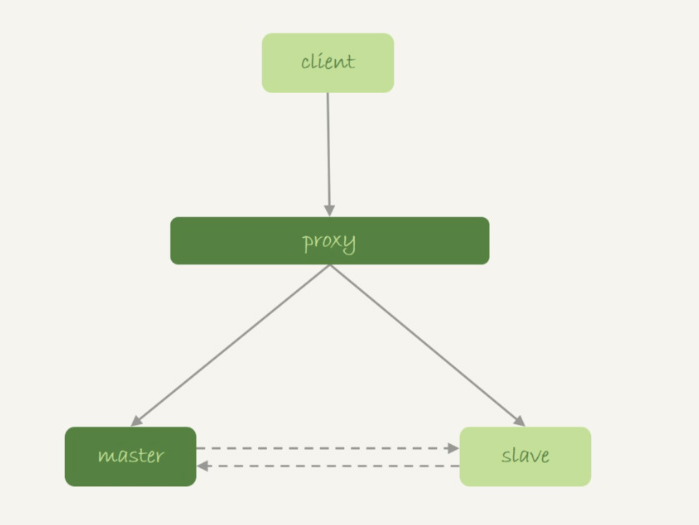
图 9 双 M 结构
在备库重启的时候,备库 binlog 里的 delete 语句就会传到主库,然后把主库内存表的内容删除。这样你在使用的时候就会发现,主库的内存表数据突然被清空了。
3、建议你把普通内存表都用 InnoDB 表来代替
基于上面的分析,你可以看到,内存表并不适合在生产环境上作为普通数据表使用。
有同学会说,但是内存表执行速度快呀。这个问题,其实你可以这么分析:
1. 如果你的表更新量大,那么并发度是一个很重要的参考指标,InnoDB 支持行锁,并发度比内存表好;
2. 能放到内存表的数据量都不大。如果你考虑的是读的性能,一个读 QPS 很高并且数据量不大的表,即使是使用 InnoDB,数据也是都会缓存在 InnoDB Buffer Pool 里的
因此,使用 InnoDB 表的读性能也不会差。
所以,我建议你把普通内存表都用 InnoDB 表来代替。但是,有一个场景却是例外的。
4、内存表的应用场景
这个场景就是,我们在第 35 和 36 篇说到的用户临时表。在数据量可控,不会耗费过多内存的情况下,你可以考虑使用内存表。
内存临时表刚好可以无视内存表的两个不足,主要是下面的三个原因:
1. 临时表不会被其他线程访问,没有并发性的问题;
2. 临时表重启后也是需要删除的,清空数据这个问题不存在;
3. 备库的临时表也不会影响主库的用户线程。
现在,我们回过头再看一下第 35 篇 join 语句优化的例子,当时我建议的是创建一个InnoDB 临时表,使用的语句序列是:
create temporary table temp_t(id int primary key, a int, b int, index(b))engine=innodb;
insert into temp_t select * from t2 where b>=1 and b<=2000;
select * from t1 join temp_t on (t1.b=temp_t.b);
4、使用内存临时表的执行效果
了解了内存表的特性,你就知道了, 其实这里使用内存临时表的效果更好,原因有三个:
1. 相比于 InnoDB 表,使用内存表不需要写磁盘,往表 temp_t 的写数据的速度更快;
2. 索引 b 使用 hash 索引,查找的速度比 B-Tree 索引快;
3. 临时表数据只有 2000 行,占用的内存有限。
因此,你可以对第 35 篇文章的语句序列做一个改写,将临时表 t1 改成内存临时表,并且在字段 b 上创建一个 hash 索引。
create temporary table temp_t(id int primary key, a int, b int, index (b))engine=memory;
insert into temp_t select * from t2 where b>=1 and b<=2000;
select * from t1 join temp_t on (t1.b=temp_t.b);
图 10 使用内存临时表的执行效果
可以看到,不论是导入数据的时间,还是执行 join 的时间,使用内存临时表的速度都比使用 InnoDB 临时表要更快一些。
六、小结
今天这篇文章,我从“要不要使用内存表”这个问题展开,和你介绍了 Memory 引擎的几个特性。
可以看到,由于重启会丢数据,如果一个备库重启,会导致主备同步线程停止;如果主库跟这个备库是双 M 架构,还可能导致主库的内存表数据被删掉。
因此,在生产上,我不建议你使用普通内存表。
如果你是 DBA,可以在建表的审核系统中增加这类规则,要求业务改用 InnoDB 表。我们在文中也分析了,其实 InnoDB 表性能还不错,而且数据安全也有保障。而内存表由于不
支持行锁,更新语句会阻塞查询,性能也未必就如想象中那么好。
基于内存表的特性,我们还分析了它的一个适用场景,就是内存临时表。内存表支持 hash索引,这个特性利用起来,对复杂查询的加速效果还是很不错的。
最后,我给你留一个问题吧。
假设你刚刚接手的一个数据库上,真的发现了一个内存表。备库重启之后肯定是会导致备库的内存表数据被清空,进而导致主备同步停止。这时,最好的做法是将它修改成
InnoDB 引擎表
假设当时的业务场景暂时不允许你修改引擎,你可以加上什么自动化逻辑,来避免主备同步停止呢?
你可以把你的思考和分析写在评论区,我会在下一篇文章的末尾跟你讨论这个问题。感谢你的收听,也欢迎你把这篇文章分享给更多的朋友一起阅读。
七、上期问题时间
今天文章的正文内容,已经回答了我们上期的问题,这里就不再赘述了。
评论区留言点赞板
@老杨同志、@poppy、@长杰 这三位同学给出了正确答案,春节期间还持续保持跟进学习,给你们点赞。
MySQL实战45讲学习笔记:第三十八讲的更多相关文章
- MySQL实战45讲学习笔记:第十八讲
一.引子 在 MySQL 中,有很多看上去逻辑相同,但性能却差异巨大的 SQL 语句.对这些语句使用不当的话,就会不经意间导致整个数据库的压力变大. 我今天挑选了三个这样的案例和你分享.希望再遇到相似 ...
- MySQL实战45讲学习笔记:第二十八讲
一.读写分离架构 在上一篇文章中,我和你介绍了一主多从的结构以及切换流程.今天我们就继续聊聊一主多从架构的应用场景:读写分离,以及怎么处理主备延迟导致的读写分离问题. 我们在上一篇文章中提到的一主多从 ...
- MySQL实战45讲学习笔记:第二十四讲
一.引子 在前面的文章中,我不止一次地和你提到了 binlog,大家知道 binlog 可以用来归档,也可以用来做主备同步,但它的内容是什么样的呢?为什么备库执行了 binlog 就可以跟主库保持一致 ...
- Dynamic CRM 2013学习笔记(三十八)流程1 - 操作(action)开发与配置详解
CRM 2013 里流程有4个类别:操作(action).业务流程(business process flow).对话(dialog)和工作流(workflow).它们都是从 setting –> ...
- MySQL实战45讲学习笔记:第二十六讲
一.引子 在上一篇文章中,我和你介绍了几种可能导致备库延迟的原因.你会发现,这些场景里,不论是偶发性的查询压力,还是备份,对备库延迟的影响一般是分钟级的,而且在备库恢复正常以后都能够追上来. 但是,如 ...
- MySQL实战45讲学习笔记:第十二讲
一.引子 平时的工作中,不知道你有没有遇到过这样的场景,一条 SQL 语句,正常执行的时候特别快,但是有时也不知道怎么回事,它就会变得特别慢,并且这样的场景很难复现,它不只随机,而且持续时间还很短. ...
- MySQL实战45讲学习笔记:第十六讲
一.今日内容概要 在你开发应用的时候,一定会经常碰到需要根据指定的字段排序来显示结果的需求.还是以我们前面举例用过的市民表为例,假设你要查询城市是“杭州”的所有人名字,并且按照姓名排序返回前 1000 ...
- MySQL实战45讲学习笔记:第二十二讲
一.引子 不知道你在实际运维过程中有没有碰到这样的情景:业务高峰期,生产环境的 MySQL 压力太大,没法正常响应,需要短期内.临时性地提升一些性能. 我以前做业务护航的时候,就偶尔会碰上这种场景.用 ...
- MySQL实战45讲学习笔记:第二十九讲
一.引子 我在第25和27篇文章中,和你介绍了主备切换流程.通过这些内容的讲解,你应该已经很清楚了:在一主一备的双 M 架构里,主备切换只需要把客户端流量切到备库:而在一主多从架构里,主备切换除了要把 ...
- MySQL实战45讲学习笔记:第十四讲
一.引子 在开发系统的时候,你可能经常需要计算一个表的行数,比如一个交易系统的所有变更记录总数.这时候你可能会想,一条 select count(*) from t 语句不就解决了吗? 但是,你会发现 ...
随机推荐
- antd配置config-overrides.js文件
下载antd 包 npm install antd 下载依赖包(定义组件按需求打包) npm install react-app-rewired customize-cra babel-plugin- ...
- linux--新装机图形化界面遇到的问题
1 许可证信息 q 退出 c 继续 r 刷新 按以下顺序正确输入即可: 1 ------ 2 ----- q ----- yes
- 怎么在ubuntu下安装使用pycharm
1.安装jdk 先下载jdk: https://pan.baidu.com/s/1o7MqvKA 解压到本地: 方法一:直接点击右键,点“提取此文件 方法二:使用命令行sudo tar -zxvf j ...
- tensorflow2.0安装
版本: python3.5 Anaconda 4.2.0 tensorflow2.0 cpu版本 1.安装命令 pip3 install tensorflow==2.0.0.0a0 -i https: ...
- virtualbox FAIL(0x80004005) VirtualBox VT-x is not available (VERR_VMX_NO_VMX)
virtualbox启动虚拟机报错: FAIL(0x80004005) VirtualBox VT-x is not available (VERR_VMX_NO_VMX),无法创建新任务 这是win ...
- vscode开发微信小程序使用less(插件Easy WXLESS)
1.搜索按照Easy WXLESS 2.在文件中加入下面的一行代码:就会在同级目录下同步代码到.wss // out: index.wxss 更多的写法可以查官网:https://marketplac ...
- PELT算法
参考:http://www.wowotech.net/process_management/PELT.html 本文是对https://lwn.net/Articles/531853/的翻译 mark ...
- ABAP对象-面向对象(转)
转自:https://www.jianshu.com/p/f847c8f71438 1 面向对象基础 不多赘述何为对象与类.简单回顾一下在面向对象特性. 封装 限定内部资源的可见性 多态 相同名称的方 ...
- 机器学习常见的几种评价指标:精确率(Precision)、召回率(Recall)、F值(F-measure)、ROC曲线、AUC、准确率(Accuracy)
原文链接:https://blog.csdn.net/weixin_42518879/article/details/83959319 主要内容:机器学习中常见的几种评价指标,它们各自的含义和计算(注 ...
- Python制作动态二维码只需要一行代码!炒鸡简单!
分享一个比较有意思的项目,只需要一行Python代码就可以快捷方便生成普通二维码.艺术二维码(黑白/彩色)和动态GIF二维码. 用法比较简单,直接通过pip安装即可. pip3 install myq ...