sparkSql使用hive数据源
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.5</version>
<scope>test</scope>
</dependency> <!-- https://mvnrepository.com/artifact/oracle/ojdbc6 -->
<dependency>
<groupId>com.oracle</groupId>
<artifactId>ojdbc6</artifactId>
<version>11.2.0.3</version>
</dependency> <!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency> <!-- https://mvnrepository.com/artifact/com.alibaba/druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>${druid.version}</version>
</dependency> <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.verson}</version>
</dependency> <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.verson}</version>
<scope>provided</scope>
</dependency> <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.verson}</version>
</dependency> <dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.verson}</version>
</dependency>
2.代码
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.hive.HiveContext
object HiveDataSource extends App {
val config = new SparkConf().setAppName("HiveDataSource").setMaster("local")
val sc = new SparkContext(config)
val sqlContext = new HiveContext(sc)
sqlContext.sql("drop table if exists default.student_infos")
sqlContext.sql("create table if not exists default.student_infos (name string,age int) row format delimited fields terminated by ',' stored as textfile")
sqlContext.sql("load data inpath '/tmp/student_infos.txt' into table default.student_infos")
// 用同样的方式,给student_scores导入数据
sqlContext.sql("DROP TABLE IF EXISTS default.student_scores")
sqlContext.sql("create table if not exists default.student_scores (name string,score int) row format delimited fields terminated by ',' stored as textfile")
sqlContext.sql("load data inpath '/tmp/student_scores.txt' into table default.student_scores")
// 关联两张表执行查询,查询成绩大于80分的学生
val goodStudentDf = sqlContext.sql("select t1.name,t1.age,t2.score from default.student_infos t1 join default.student_scores t2 on t1.name = t2.name")
goodStudentDf.show()
}
/home/hadoop/app/spark/bin/spark-submit \
--class com.dsj361.HiveDataSource \
--master local[*] \
--num-executors 2 \
--driver-memory 1000m \
--executor-memory 1000m \
--executor-cores 2 \
/home/hadoop/sparksqlapp/jar/sparkSqlStudy.jar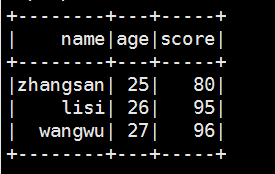
<wiz_tmp_tag id="wiz-table-range-border" contenteditable="false" style="display: none;">
附件列表
sparkSql使用hive数据源的更多相关文章
- SparkSQL与Hive on Spark的比较
简要介绍了SparkSQL与Hive on Spark的区别与联系 一.关于Spark 简介 在Hadoop的整个生态系统中,Spark和MapReduce在同一个层级,即主要解决分布式计算框架的问题 ...
- SparkSQL与Hive on Spark
SparkSQL与Hive on Spark的比较 简要介绍了SparkSQL与Hive on Spark的区别与联系 一.关于Spark 简介 在Hadoop的整个生态系统中,Spark和MapR ...
- SparkSQL和hive on Spark
SparkSQL简介 SparkSQL的前身是Shark,给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,hive应运而生,它是当时唯一运行在Hadoop上的SQL-on-h ...
- SparkSQL访问Hive源,MySQL源
SparkSQL访问Hive源,MySQL源 一.SparkSQL访问Hive源 软件环境 SparkSQL命令行模式可以直接连接Hive的 Java程序SparkSQL连接Hive 二.SparkS ...
- SparkSQL读取Hive中的数据
由于我Spark采用的是Cloudera公司的CDH,并且安装的时候是在线自动安装和部署的集群.最近在学习SparkSQL,看到SparkSQL on HIVE.下面主要是介绍一下如何通过SparkS ...
- 关于sparksql操作hive,读取本地csv文件并以parquet的形式装入hive中
说明:spark版本:2.2.0 hive版本:1.2.1 需求: 有本地csv格式的一个文件,格式为${当天日期}visit.txt,例如20180707visit.txt,现在需要将其通过spar ...
- spark on yarn模式下配置spark-sql访问hive元数据
spark on yarn模式下配置spark-sql访问hive元数据 目的:在spark on yarn模式下,执行spark-sql访问hive的元数据.并对比一下spark-sql 和hive ...
- sparksql 操作hive
写在前面:hive的版本是1.2.1spark的版本是1.6.x http://spark.apache.org/docs/1.6.1/sql-programming-guide.html#hive- ...
- 【完美解决】Spark-SQL、Hive多 Metastore、多后端、多库
[完美解决]Spark-SQL.Hive多 Metastore.多后端.多库 [完美解决]Spark-SQL.Hive多 Metastore.多后端.多库 SparkSQL 支持同时连接多种 Meta ...
随机推荐
- CodeForces 29D Ant on the Tree
洛谷题目页面传送门 & CodeForces题目页面传送门 题意见洛谷里的翻译. 这题有\(\bm3\)种解法,但只有一种是正解(这不是废话嘛). 方法\(\bm1\):最近公共祖先LCA(正 ...
- VSCode 使用Settings Sync同步配置(最新版教程,非常简单)
VSCode 使用Settings Sync同步配置(最新版教程,非常简单) 之前无意中听到有人说,vsCode最大的缺点就是每次换个电脑或者临时去个新环境,就要配置一下各种插件,好不麻烦,以至于面试 ...
- word编辑visio文件
Word文档中插入visio文件并编辑: (1)插入->对象->对象->选择“visio文件”,此种方式可插入visio文件的全部. (2)直接打开visio文件->ctrl+ ...
- idea + springboot 的java后台服务器通过小米推送
public class XiaomiPush { // 1.小米推送(我只推送Android且只应用regId发起推送,所以下面只有推送Android的代码 private static final ...
- Python学习 之 Python入门
第二章 Python入门 2.1 环境安装 2.1.1 下载解释器: py2.7.16 (2020年官方不再维护) py3.6.8 (推荐安装) 1.下载解释器一定去官网下载,https://www. ...
- 纯 Python 实现的 Google 批量翻译
测试通过时间:2019-8-20 参阅:C#实现谷歌翻译API.Python之Google翻译爬虫 首先声明,没有什么不良动机,因为经常会用 translate.google.cn,就想着用 Pyth ...
- python所有的标准异常类:
异常名称 描述 BaseException 所有异常的基类 SystemExit 解释器请求退出 KeyboardInterrupt 用户中断执行(通常是输入^C) Exception 常规错误的基类 ...
- 面试中常用的六种排序算法及其Java实现
常见排序算法的时间复杂度以及稳定性: 1 public class Sort { public static void main(String[] args){ int[] nums=new int[ ...
- 80后,天才程序员, Facebook 第一任 CTO,看看开挂的人生到底有多变态?
鸡仔说:今天介绍一位天才程序员--亚当·德安格洛(Adam D'Angelo),他被<财富>杂志誉为"科技界最聪明的人之一",大学去了被誉为"天才" ...
- Liunx学习总结(七)--系统状态查看和统计
sar命令 sar 是一个非常强大的性能分析工具,它可以获取系统的 cpu/等待队列/磁盘IO/内存/网络等性能指标.功能多的必然结果是选项多,应用复杂,但只要知道一些常用的选项足以. 语法 sar ...