百万年薪python之路 -- 并发编程之 协程
协程
一. 协程的引入
本节的主题是基于单线程来实现并发,即只用一个主线程(很明显可利用的cpu只有一个)情况下实现并发,为此我们需要先回顾下并发的本质:切换+保存状态
cpu正在运行一个任务,会在两种情况下切走去执行其他的任务(切换由操作系统强制控制),一种情况是该任务发生了阻塞,另外一种情况是该任务计算的时间过长或有一个优先级更高的程序替代了它
协程本质上就是一个线程,以前线程任务的切换是由操作系统控制的,遇到I/O自动切换,现在我们用协程的目的就是较少操作系统切换的开销(开关线程,创建寄存器、堆栈等,在他们之间进行切换等),在我们自己的程序里面来控制任务的切换。
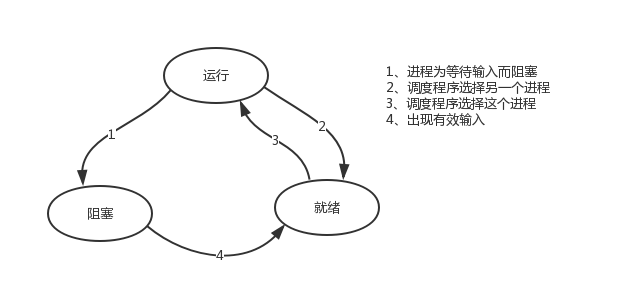
ps:在介绍进程理论时,提及进程的三种执行状态,而线程才是执行单位,所以也可以将上图理解为线程的三种状态
一:其中上图的第二种情况并不能提升效率,只是为了让cpu能够雨露均沾,实现看起来所有任务都被“同时”执行的效果,如果多个任务都是纯计算的,这种切换反而会降低效率。为此我们可以基于yield来验证。yield本身就是一种在单线程下可以保存任务运行状态的方法,我们来简单复习一下:
#1 yiled可以保存状态,yield的状态保存与操作系统的保存线程状态很像,但是yield是代码级别控制的,更轻量级
#2 send可以把一个函数的结果传给另外一个函数,以此实现单线程内程序之间的切换 通过yield实现任务切换+ 保护现场:
import time
def func1():
for i in range(11):
yield
print('这是我第%s次打印'%i)
time.sleep(1)
def func2():
g = func1()
next(g)
for k in range(10):
print(f'呵呵,我已经打印{k}次')
time.sleep(1)
next(g)
# 不写yield, 下面两个任务是执行完func1里面所有的程序才会执行func2里面的程序,
# 有了yield,我们实现了两个任务的切换+保持状态
func1()
func2()计算密集型 串行与协程的对比:
# 串行
import time
def task1():
res = 1
for i in range(1,100000):
res += i
def task2():
res = 1
for i in range(1,100000):
res -= i
start_time = time.time()
task1()
task2()
print(time.time()-start_time) # 0.011995553970336914# yield版的协程
import time
def task():
res = 1
for i in range(1,100000):
res += i
yield res
def task2():
g = task()
res = 1
for i in range(1,100000):
res -= i
next(g)
start = time.time()
task2()
print(time.time() - start) # 0.0239870548248291如果任务是计算密集型,串行会比协程快.
二:第一种情况的切换。在任务一遇到io情况下,切到任务二去执行,这样就可以利用任务一阻塞的时间完成任务二的计算,效率的提升就在于此。
import time
def func1():
while True:
print('func1')
yield
def func2():
g=func1()
for i in range(10000000):
next(g)
time.sleep(3)
print('func2')
start=time.time()
func2()
stop=time.time()
print(stop-start)
# yield不能检测IO阻塞,不能实现遇到IO自动切换.协程就是告诉Cpython解释器,你不是nb吗,不是搞了个GIL锁吗,那好,我就自己搞成一个线程让你去执行,省去你切换线程的时间,我自己切换比你切换要快很多,避免了很多的开销,对于单线程下,我们不可避免程序中出现io操作,但如果我们能在自己的程序中(即用户程序级别,而非操作系统级别)控制单线程下的多个任务能在一个任务遇到io阻塞时就切换到另外一个任务去计算,这样就保证了该线程能够最大限度地处于就绪态,即随时都可以被cpu执行的状态,相当于我们在用户程序级别将自己的io操作最大限度地隐藏起来,从而可以迷惑操作系统,让其看到:该线程好像是一直在计算,io比较少,从而更多的将cpu的执行权限分配给我们的线程。
协程的本质就是在单线程下,由用户自己控制一个任务遇到io阻塞了就切换另外一个任务去执行,以此来提升效率。为了实现它,我们需要找寻一种可以同时满足以下条件的解决方案:
#1. 可以控制多个任务之间的切换,切换之前将任务的状态保存下来,以便重新运行时,可以基于暂停的位置继续执行。
#2. 作为1的补充:可以检测io操作,在遇到io操作的情况下才发生切换二. 协程介绍
协程:是单线程下的并发,又称微线程,纤程。英文名Coroutine。一句话说明什么是线程:协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。
协程的定义: 在单线程下,由用户自己控制一个任务遇到io阻塞了就切换另外一个任务去执行,以此来提升效率。
协程和线程差异
在实现多任务时, 线程切换从系统层面远不止保存和恢复 CPU上下文这么简单。 操作系统为了程序运行的高效性每个线程都有自己缓存Cache等等数据,操作系统还会帮你做这些数据的恢复操作。 所以线程的切换非常耗性能。但是协程的切换只是单纯的操作CPU的上下文,所以一秒钟切换个上百万次系统都抗的住。
需要强调的是:
#1. python的线程属于内核级别的,即由操作系统控制调度(如单线程遇到io或执行时间过长就会被迫交出cpu执行权限,切换其他线程运行)
#2. 单线程内开启协程,一旦遇到io,就会从应用程序级别(而非操作系统)控制切换,以此来提升效率(!!!非io操作的切换与效率无关)对比操作系统控制线程的切换,用户在单线程内控制协程的切换
优点如下:
#1. 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级
#2. 单线程内就可以实现并发的效果,最大限度地利用cpu缺点如下:
#1. 协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程总结协程特点:
- 必须在只有一个单线程里实现并发
- 修改共享数据不需加锁
- 用户程序里自己保存多个控制流的上下文栈
三. Greenlet
如果我们在单个线程内有20个任务,要想实现在多个任务之间切换,使用yield生成器的方式过于麻烦(需要先得到初始化一次的生成器,然后再调用send。。。非常麻烦),而使用greenlet模块可以非常简单地实现这20个任务直接的切换
# 安装
一:
pip3 install greenlet
二:
PyCharm里settings-----> Project Interpreter-----> 右上角的加号+ ------> 搜索框里搜索# 真正的协程模块就是使用greenlet完成的切换
from greenlet import greenlet
def eat(name):
print(f"{name} eat 1") # 2
g2.switch('zdr') # 3
print(f'{name} eat 2') # 6
g2.switch() # 7
def play(name):
print(f'{name} play 1') # 4
g1.switch() # 5
print(f'{name} play 2') # 8
g1 = greenlet(eat)
g2 = greenlet(play)
g1.switch('zcy') # 可以在第一次switch时传入传输,以后就不需要 1单纯的切换(在没有io的情况下或者没有重复开辟内存空间的操作),反而会降低程序的执行速度
效率对比:
#顺序执行
import time
def f1():
res=1
for i in range(100000000):
res+=i
def f2():
res=1
for i in range(100000000):
res*=i
start=time.time()
f1()
f2()
stop=time.time()
print('run time is %s' %(stop-start)) #10.985628366470337
#切换
from greenlet import greenlet
import time
def f1():
res=1
for i in range(100000000):
res+=i
g2.switch()
def f2():
res=1
for i in range(100000000):
res*=i
g1.switch()
start=time.time()
g1=greenlet(f1)
g2=greenlet(f2)
g1.switch()
stop=time.time()
print('run time is %s' %(stop-start)) # 52.763017892837524
效率对比greenlet只是提供了一种比generator更加便捷的切换方式,当切到一个任务执行时如果遇到io,那就原地阻塞,仍然是没有解决遇到IO自动切换来提升效率的问题。

上面这个图,是协程真正的意义,虽然没有规避固有的I/O时间,但是我们使用这个时间来做别的事情了,一般在工作中我们都是进程+线程+协程的方式来实现并发,以达到最好的并发效果,如果是4核的cpu,一般起5个进程,每个进程中20个线程(5倍cpu数量),每个线程可以起500个协程,大规模爬取页面的时候,等待网络延迟的时间的时候,我们就可以用协程去实现并发。 并发数量 = 5 * 20 * 500 = 50000个并发,这是一般一个4cpu的机器最大的并发数。nginx在负载均衡的时候最大承载量就是5w个
单线程里的这20个任务的代码通常会既有计算操作又有阻塞操作,我们完全可以在执行任务1时遇到阻塞,就利用阻塞的时间去执行任务2。。。。如此,才能提高效率,这就用到了Gevent模块
四. gevent简介
# 安装
一:
pip3 install gevent
二:
PyCharm里settings-----> Project Interpreter-----> 右上角的加号+ ------> 搜索框里搜索Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
#用法
g1=gevent.spawn(func,1,2,3,x=4,y=5)创建一个协程对象g1,spawn括号内第一个参数是函数名,如eat,后面可以有多个参数,可以是位置实参或关键字实参,都是传给函数eat的,spawn是异步提交任务
g2=gevent.spawn(func2)
g1.join() #等待g1结束
g2.join() #等待g2结束 有人测试的时候会发现,不写第二个join也能执行g2,是的,协程帮你切换执行了,但是你会发现,如果g2里面的任务执行的时间长,但是不写join的话,就不会执行完等到g2剩下的任务了
#或者上述两步合作一步:gevent.joinall([g1,g2])
g1.value#拿到func1的返回值 遇到IO阻塞时会自动切换任务
import gevent
def eat(name):
print('%s eat 1' %name)
gevent.sleep(2)
print('%s eat 2' %name)
def play(name):
print('%s play 1' %name)
gevent.sleep(1)
print('%s play 2' %name)
g1=gevent.spawn(eat,'egon')
g2=gevent.spawn(play,name='egon')
g1.join()
g2.join()
#或者gevent.joinall([g1,g2])
print('主')
遇到I/O切换上例gevent.sleep(2)模拟的是gevent可以识别的io阻塞,
而time.sleep(2)或其他的阻塞,gevent是不能直接识别的需要用下面一行代码,打补丁,就可以识别了
from gevent import monkey;monkey.patch_all()必须放到被打补丁者的前面,如time,socket模块之前
或者我们干脆记忆成:要用gevent,需要将from gevent import monkey;monkey.patch_all()放到文件的开头
from gevent import monkey;monkey.patch_all() #必须写在最上面,这句话后面的所有阻塞全部能够识别了
import gevent #直接导入即可
import time
def eat():
#print()
print('eat food 1')
time.sleep(2) #加上mokey就能够识别到time模块的sleep了
print('eat food 2')
def play():
print('play 1')
time.sleep(1) #来回切换,直到一个I/O的时间结束,这里都是我们个gevent做得,不再是控制不了的操作系统了。
print('play 2')
g1=gevent.spawn(eat)
g2=gevent.spawn(play_phone)
gevent.joinall([g1,g2])
print('主')我们可以用threading.current_thread().getName()来查看每个g1和g2,查看的结果为DummyThread-n,即假线程,虚拟线程,其实都在一个线程里面
进程线程的任务切换是由操作系统自行切换的,你自己不能控制
协程是通过自己的程序(代码)来进行切换的,自己能够控制,只有遇到协程模块能够识别的IO操作的时候,程序才会进行任务切换,实现并发效果,如果所有程序都没有IO操作,那么就基本属于串行执行了。
五 Gevent之同步与异步
from gevent import spawn,joinall,monkey;monkey.patch_all()
import time
def task(pid):
"""
Some non-deterministic task
"""
time.sleep(0.5)
print('Task %s done' % pid)
def synchronous():
for i in range(10):
task(i)
def asynchronous():
g_l=[spawn(task,i) for i in range(10)]
joinall(g_l)
if __name__ == '__main__':
print('Synchronous:')
synchronous()
print('Asynchronous:')
asynchronous()
#上面程序的重要部分是将task函数封装到Greenlet内部线程的gevent.spawn。 初始化的greenlet列表存放在数组threads中,此数组被传给gevent.joinall 函数,后者阻塞当前流程,并执行所有给定的greenlet。执行流程只会在 所有greenlet执行完后才会继续向下走。
协程:同步异步对比
六 Gevent之应用举例一
from gevent import monkey;monkey.patch_all()
import gevent
import requests
import time
def get_page(url):
print('GET: %s' %url)
response=requests.get(url)
if response.status_code == 200:
print('%d bytes received from %s' %(len(response.text),url))
start_time=time.time()
gevent.joinall([
gevent.spawn(get_page,'https://www.python.org/'),
gevent.spawn(get_page,'https://www.yahoo.com/'),
gevent.spawn(get_page,'https://github.com/'),
])
stop_time=time.time()
print('run time is %s' %(stop_time-start_time))
协程应用:爬虫
将上面的程序最后加上一段串行的代码看看效率:如果你的程序不需要太高的效率,那就不用什么并发啊协程啊之类的东西。
print('--------------------------------')
s = time.time()
requests.get('https://www.python.org/')
requests.get('https://www.yahoo.com/')
requests.get('https://github.com/')
t = time.time()
print('串行时间>>',t-s)
七 Gevent之应用举例二
通过gevent实现单线程下的socket并发(from gevent import monkey;monkey.patch_all()一定要放到导入socket模块之前,否则gevent无法识别socket的阻塞)
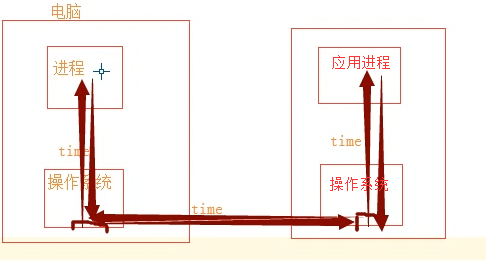
一个网络请求里面经过多个时间延迟time
服务端:
from gevent import monkey;monkey.patch_all()
from socket import *
import gevent
#如果不想用money.patch_all()打补丁,可以用gevent自带的socket
# from gevent import socket
# s=socket.socket()
def server(server_ip,port):
s=socket(AF_INET,SOCK_STREAM)
s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
s.bind((server_ip,port))
s.listen(5)
while True:
conn,addr=s.accept()
gevent.spawn(talk,conn,addr)
def talk(conn,addr):
try:
while True:
res=conn.recv(1024)
print('client %s:%s msg: %s' %(addr[0],addr[1],res))
conn.send(res.upper())
except Exception as e:
print(e)
finally:
conn.close()
if __name__ == '__main__':
server('127.0.0.1',8080)
服务端 客户端:
from socket import *
client=socket(AF_INET,SOCK_STREAM)
client.connect(('127.0.0.1',8080))
while True:
msg=input('>>: ').strip()
if not msg:continue
client.send(msg.encode('utf-8'))
msg=client.recv(1024)
多线程并发多个客户端,去请求上面的服务端是没问题的
from threading import Thread
from socket import *
import threading
def client(server_ip,port):
c=socket(AF_INET,SOCK_STREAM) #套接字对象一定要加到函数内,即局部名称空间内,放在函数外则被所有线程共享,则大家公用一个套接字对象,那么客户端端口永远一样了
c.connect((server_ip,port))
count=0
while True:
c.send(('%s say hello %s' %(threading.current_thread().getName(),count)).encode('utf-8'))
msg=c.recv(1024)
print(msg.decode('utf-8'))
count+=1
if __name__ == '__main__':
for i in range(500):
t=Thread(target=client,args=('127.0.0.1',8080))
t.start()
多线程并发多个客户端,去请求上面的服务端是没问题的百万年薪python之路 -- 并发编程之 协程的更多相关文章
- 百万年薪python之路 -- 并发编程之 多进程 一
并发编程之 多进程 一. multiprocessing模块介绍 python中的多线程无法利用多核优势,如果想要充分地使用多核CPU的资源(os.cpu_count()查看),在python中大 ...
- 百万年薪python之路 -- 并发编程之 多线程 二
1. 死锁现象与递归锁 进程也有死锁与递归锁,进程的死锁和递归锁与线程的死锁递归锁同理. 所谓死锁: 是指两个或两个以上的进程或线程在执行过程中,因为争夺资源而造成的一种互相等待的现象,在无外力的作用 ...
- 百万年薪python之路 -- 并发编程之 多线程 三
1. 阻塞,非阻塞,同步,异步 进程运行的三个状态: 运行,就绪,阻塞. 从执行的角度: 阻塞: 进程运行时,遇到IO了,进程挂起,CPU被切走. 非阻塞: 进程没有遇到IO 当进程遇到IO, ...
- 百万年薪python之路 -- 并发编程之 多线程 一
多线程 1.进程: 生产者消费者模型 一种编程思想,模型,设计模式,理论等等,都是交给你一种编程的方法,以后遇到类似的情况,套用即可 生产者与消费者模型的三要素: 生产者:产生数据的 消费者:接收数据 ...
- 百万年薪python之路 -- 并发编程之 多进程二
1. 僵尸进程和孤儿进程 基于unix的环境(linux,macOS) 主进程需要等待子进程结束之后,主进程才结束 主进程时刻检测子进程的运行状态,当子进程结束之后,一段时间之内,将子进程进行回收. ...
- python并发编程之协程知识点
由线程遗留下的问题:GIL导致多个线程不能真正的并行,CPython中多个线程不能并行 单线程实现并发:切换+保存状态 第一种方法:使用yield,yield可以保存状态.yield的状态保存与操作系 ...
- python全栈开发从入门到放弃之socket并发编程之协程
一.为什么会有协程 本节的主题是基于单线程来实现并发,即只用一个主线程(很明显可利用的cpu只有一个)情况下实现并发,为此我们需要先回顾下并发的本质:切换+保存状态 cpu正在运行一个任务,会在两种情 ...
- 32 python 并发编程之协程
一 引子 本节的主题是基于单线程来实现并发,即只用一个主线程(很明显可利用的cpu只有一个)情况下实现并发,为此我们需要先回顾下并发的本质:切换+保存状态 cpu正在运行一个任务,会在两种情况下切走去 ...
- 四 python并发编程之协程
一 引子 本节的主题是基于单线程来实现并发,即只用一个主线程(很明显可利用的cpu只有一个)情况下实现并发,为此我们需要先回顾下并发的本质:切换+保存状态 cpu正在运行一个任务,会在两种情况下切走去 ...
随机推荐
- java数据结构——数组(Array)
数据结构+算法是我们学习道路上的重中之重,让我们一起进步,一起感受代码之美! /** * 让我们从最基本的数据结构——数组开始吧 * 增.删.改.查.插.显示 */ public class Seql ...
- CSS从大图中抠图然后显示其中的一部分
相信大家在使用css时会遇到一个情况吧 就是一张大图片里面什么都有 各种图标都有 然而自己就是不太会使用其中的小图标 这是我最近的一次学习 首先上图 这么大一张图片 那么这么使其只显示一部分 并且为我 ...
- 深度汉化GCompris-qt,免费的幼儿识字软件
1 需求 因为有个小孩上幼儿园了,想开始教他一些汉语拼音和基本的汉字,但通过一书本和卡片又有些枯燥乏味,于上就上网搜索一些辅助认字的应用,还购买了悟空识字APP,在用的过程中发现他设置了很严格的关卡, ...
- 深入理解什么是Java泛型?泛型怎么使用?【纯转】
本篇文章给大家带来的内容是介绍深入理解什么是Java泛型?泛型怎么使用?有一定的参考价值,有需要的朋友可以参考一下,希望对你们有所助. 一.什么是泛型 “泛型” 意味着编写的代码可以被不同类型的对象所 ...
- 一台机器上搭建多个redis实例的配置文件修改部分
1.单个redis服务搭建请参考:redis服务搭建 2.一台Redis服务器,分成多个节点,每个节点分配一个端口(6380,6381…),默认端口是6379. 每个节点对应一个Redis配置文件,如 ...
- 阿里云服务器ecs配置之安装redis服务
一.介绍 Redis是当前比较热门的NOSQL系统之一,它是一个key-value存储系统.和Memcache类似,但很大程度补偿了Memcache的不足,它支持存储的value类型相对更多,包括st ...
- centos7 远程连接其他服务器mysql
在本地远程连接 在终端输入: mysql -h 服务器ip地址 -P 端口 -u 用户名 -p 然后输入密码即可.
- 【ASP.NET基础--MVC】MVC视图基础语法学习
初步接触.net MVC的视图语法,很多东西都不太熟悉,感觉跟之前的aspx以及html都有一些区别,最近看别人的代码,一边看一边研究,现把学到的东西在这里记录一下,以便日后翻阅. 第一部分:基础知识 ...
- Jquery Ztree异步加载树
1. 下载jquery的JS文件/ztree的CSS文件和JS文件 https://jquery.com/download/ https://gitee.com/zTree/zTree_v3/tree ...
- 你的环境有问题吧?--byte数组转字符串的疑惑
1. 故事背景 小T是个测试MM,小C是个程序猿,今天早上他们又为一个bug吵架了. 小T:“这个显示是bug,在我的浏览器上显示不正确” 小C:“这个bug我不认,在我的电脑上显示正常,是你的环境有 ...